前言

2022年,Python更是超越Java一跃成为编程语言的No.1。
Python现在非常火,语法简单而且功能强大,很多同学都想学Python!
所以小编准备了全套Python学习教程,无私分享,文末领取!
Python是一门编程语言,一门技术,一个生产力工具。只要你能掌握生产工具,就能赚钱,也许能像那位知乎大神一样躺赚200万,即便不能,至少赚个外快是没有问题的!

Python爬虫爬取基金股票并处理
在Python中常用的爬虫工具有BeautifulSoup、lxml和pyquery,仅需要几句简单的代码即可获得需要爬取的内容。
BeautifulSoup
从HTML或XML文件中提取数据的Python库;
lxml
采用XPath语法,XPath是一种专门对xml文档进行操作的语言;
pyquery
是python仿jquery的实现,与jquery的语法基本一致。
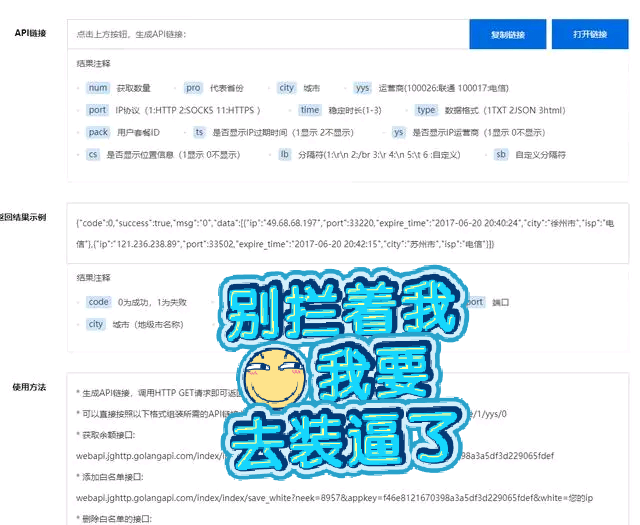
Python设置http代理
高强度、高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封。(如何设置代理,详见置顶)
用代理IP不仅可以隐藏自身IP,还可以防止自身IP被封锁。极光HTTP代理拥有海量IP,不仅使用方便快捷,更安全可靠。
代码实现
def core():
global go_on
while go_on == 0:
print " ---"
keyID = str(raw_input(unicode('>输入股票代码 >>>> ','utf-8').encode('gbk')))
main(keyID)
exit()
else:
pass
def spider(base_path,keyID):
data_years = []
try:
url1 = 'http://basic.10jqka.com.cn/api/stock/export.php?export=main&type=year&code={}'.format(keyID)
url2 = 'http://basic.10jqka.com.cn/api/stock/export.php?export=debt&type=year&code={}'.format(keyID)
url3 = 'http://basic.10jqka.com.cn/api/stock/export.php?export=cash&type=year&code={}'.format(keyID)
url4 = 'http://www.dashiyetouzi.com/tools/get_financial_report_data_v2.php'
request_data = {
'stock_id':keyID,
'report_form':'netease_lrb_info',
'report_year':'5',
'report_type':'Annual'
}
url5 = 'http://quotes.money.163.com/service/zycwzb_{}.html?type=year&part=ylnl'.format(keyID)
url6 = 'http://quotes.money.163.com/service/zycwzb_{}.html?type=year&part=cznl'.format(keyID)
url7 = 'http://quotes.money.163.com/service/zycwzb_{}.html?type=year&part=yynl'.format(keyID)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
}
response1 = requests.get(url1, headers=headers).content
file(base_path+'main.xls',response1)
response2 = requests.get(url2, headers=headers).content
file(base_path+'debt.xls',response2)
response3 = requests.get(url3, headers=headers).content
file(base_path+'cash.xls',response3)
response4 = requests.post(url4, headers=headers ,data=request_data).content
result4 = json.loads(response4,encoding = 'utf-8')
response5 = requests.get(url5, headers=headers).content#修改三项费用率计算方式,直接加总,不直接获取
file(base_path+'ylnl.csv',response5)
response6 = requests.get(url6, headers=headers).content
file(base_path+'cznl.csv',response6)
response7 = requests.get(url7, headers=headers).content
file(base_path+'yynl.csv',response7)
readbook1 = xlrd.open_workbook(base_path+'main.xls',formatting_info=True)
readsheet1 = readbook1.sheet_by_index(0)
readbook2 = xlrd.open_workbook(base_path+'debt.xls',formatting_info=True)
readsheet2 = readbook2.sheet_by_index(0)
readbook3 = xlrd.open_workbook(base_path+'cash.xls',formatting_info=True)
readsheet3 = readbook3.sheet_by_index(0)
for year_index in range(1,6):
data1 = readsheet1.col_values(year_index)
data2 = readsheet2.col_values(year_index)
data3 = readsheet3.col_values(year_index)
data4 = result4['percent'][year_index-1]
#data5 = csv_read(base_path+'ylnl.csv',16,year_index)
#data6 = csv_read(base_path+'cznl.csv',5,year_index)
#data7 = csv_read(base_path+'yynl.csv',15,year_index)
data5 = csv_read2(base_path+'ylnl.csv',16,year_index)
data6 = csv_read2(base_path+'cznl.csv',5,year_index)
data7 = csv_read2(base_path+'yynl.csv',15,year_index)
try:
jisuan0=float(data4[22])+float(data4[23])+float(data4[24])
except:
jisuan0='n/a'
try:
jisuan1=data2[23]/data2[51]
except:
jisuan1='n/a'
try:
jisuan2=data2[5]/data1[7]
except:
jisuan2='n/a'
try:
jisuan3=(data2[27]+data2[28])/data2[43]
except:
jisuan3='n/a'
try:
jisuan4=data2[16]/data2[23]
except:
jisuan4='n/a'
try:
jisuan5=data2[9]/data1[7]
except:
jisuan5='n/a'
try:
jisuan6=data3[8]/data1[5]
except:
jisuan6='n/a'
try:
jisuan7=data3[8]-data3[11]
except:
jisuan7='n/a'
data_final =[
data1[1],
round(data1[7]/100000000,2),#1
data1[8],#2
data1[16],#3
data5[13],#4
data4[22],#5
data4[23],#6
data4[24],#7
round(data1[5]/100000000,2),#8
data1[6],#9
data1[10],#10
data1[18],#11
data7[5],#12
round(jisuan1,2),
round(data2[23]/100000000,2),#14
data6[4],#15
round(data2[51]/100000000,2),#16
data6[3],#17
data1[12],#18
round(data2[5]/100000000,2),#19
round(jisuan2,2),
round(data2[27]/100000000,2),#21
round(data2[28]/100000000,2),#22
round(data2[43]/100000000,2),#23
round(jisuan3,2),
round(data2[16]/100000000,2),#25
round(jisuan4,2),
round(data2[9]/100000000,2),#27
round(jisuan5,2),
round(data3[11]/100000000,2),#29
round(data3[8]/100000000,2),#30
round(jisuan6,2),
round(jisuan7/100000000,2)
]
print ' '+str(data1[1])+' -> done'
data_years.append(data_final)
save_items_to_xls(base_path,data_years,33,keyID)
print '--- finished! now you can check the folder ---'
except Exception,e:
print 'traceback.print_exc():'; traceback.print_exc()
print ' wrong...'
print
def save_items_to_xls(path,items,num,keyID):
global sheetCol
sheetCol = 1
style1 = xlwt.XFStyle()
alignment = xlwt.Alignment()
alignment.horz = xlwt.Alignment.HORZ_RIGHT
style1.alignment = alignment
itembook = xlwt.Workbook(encoding = 'utf8')
itemsheet = itembook.add_sheet('items',cell_overwrite_ok=True)
itemsheet.col(0).width = 256*20
titles = [keyID,u'营业收入',u'营收增幅',u'毛利率',u'三项费用率',u'销售费用率',u'管理费用率',u'财务费用率',u'扣非净利润',u'扣非净利润增幅',u'ROE',u'净利润率',u'总周转率',u'财务杠杆',u'总资产',u'总资产增长率',u'净资产',u'净资产增长率',u'资产负债率',u'应收账款',u'应收账款占营业收入',u'应付账款',u'预收账款',u'总负债',u'无息负债占比总负债',u'固定资产',u'固定资产占比总资产',u'存货',u'存货占比营业收入',u'购置固定资产现金支出',u'经营性现金流净额',u'经营性现金流净额/扣非净利润',u'自由现金流']
for i in xrange(33):
itemsheet.write(i, 0, titles[i])
for y in xrange(0,len(items)):
itemsheet.col(sheetCol).width = 256*20
for x in range(0,num):
itemsheet.write(x, sheetCol,items[y][x],style1)
sheetCol = sheetCol+1
itembook.save(path+str(keyID)+'-financeData.xls')
time.sleep(2)
有了爬虫利器后我们再也不用写复杂的正则表达式了。对于静态网页的爬取,没有什么技术上的难点,每位读者都可以去尝试获取自己想要的数据。
读者福利:知道你对Python感兴趣,便为你准备了这套python学习资料,
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
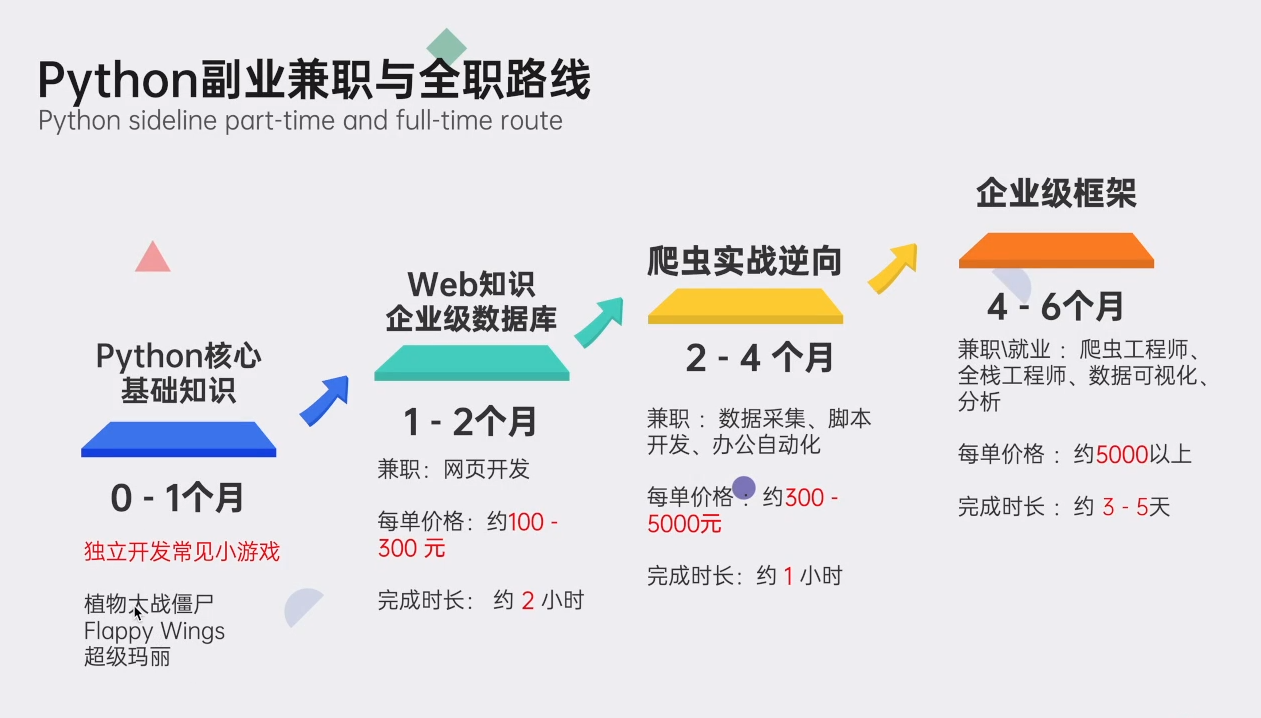
包括:Python永久使用安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
????Python学习路线汇总????
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)

????Python必备开发工具????
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
????Python学习视频600合集????
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
????实战案例????
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
????100道Python练习题????
检查学习结果。
????面试刷题????
资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取

好文推荐
了解python的前景:https://blog.csdn.net/weixin_49895216/article/details/127186741
了解python能做什么:https://blog.csdn.net/weixin_49895216/article/details/127124870
最后
以上就是健康墨镜最近收集整理的关于0基础学Python爬虫2个月怎么赚钱?了解一下前言零基础Python学习资源介绍资料领取好文推荐的全部内容,更多相关0基础学Python爬虫2个月怎么赚钱内容请搜索靠谱客的其他文章。








发表评论 取消回复