GET&POST请求一般格式
爬取Github数据
GET&POST请求一般格式
很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”。任何的网络通信归根结底,就是服务端跟客户端的一次socket通信。发送一个socket请求给服务端,服务端作出响应返回socket给客户端。
在此,就不详细介绍HTTP请求头,网上的大牛博客多的很,这里针对请求头跟请求体,稍微了解下一般规律,只是为了爬虫准备基础。
HTTP请求
既然万物皆socket,那么不论客户端还是服务端拿到的一定是一段socket,说白了就是一串字符串。那么请求头与请求体,或者响应头与响应体是如何解析出来的呢?
这里,先查看下google的network内的请求信息:
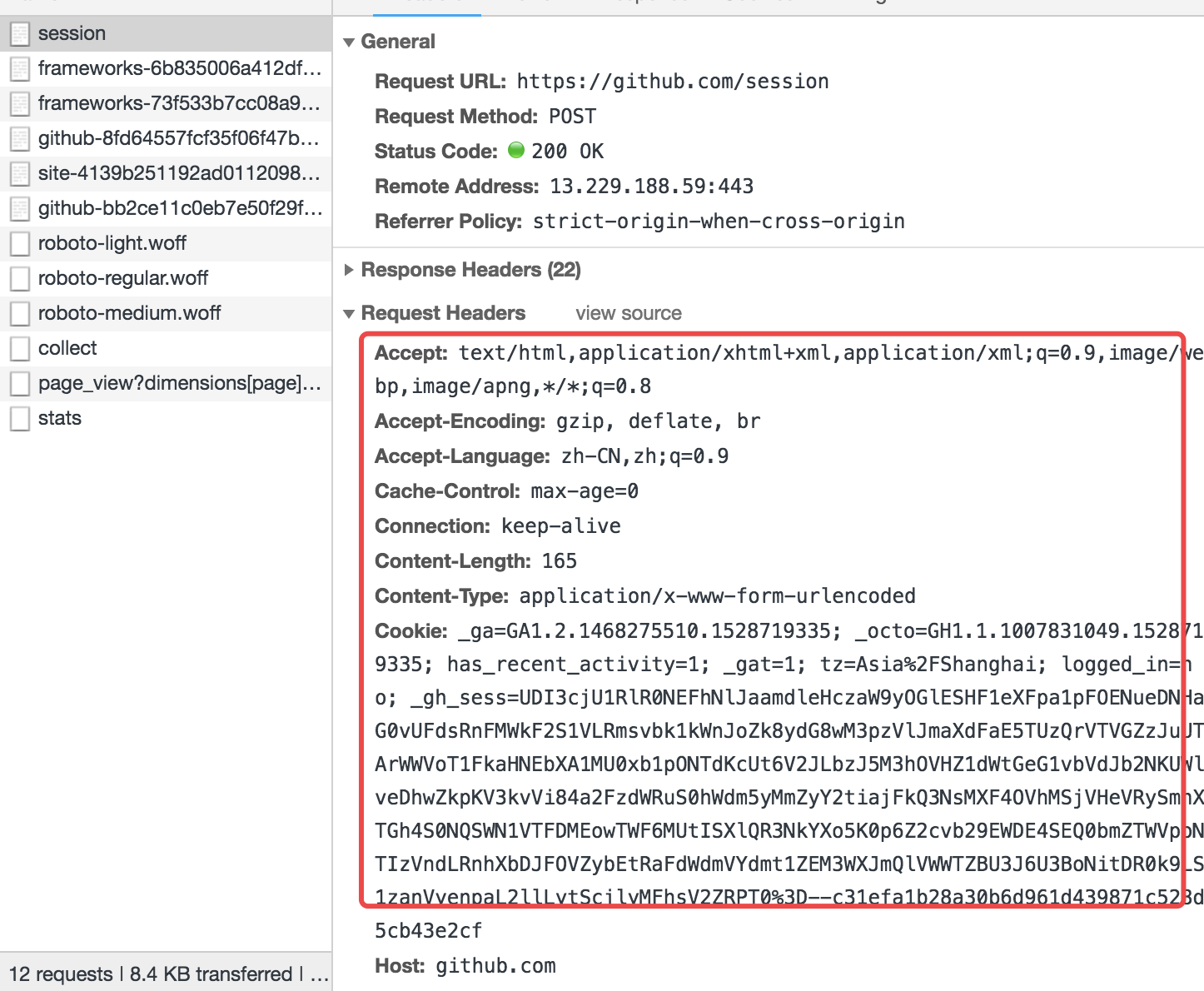
无论是请求还是响应都是特别规整的数据。
在Http请求中,请求头跟请求体之间是通过/r/n/r/n分割开的。
请求头内容Accept-Encoding: gzip, deflate, br/r/nContent-Type: application/x-www-form-urlencoded/r/n......./r/n/r/n请求体
如上的一串字符串、会根据/r/n/r/n解析出来请求头跟请求体,然后根据/r/n来换行。
响应体也是一样的套路。
唯一需要特殊提醒的是:
*************************************响应*************************************
普通:
响应头:
content-encoding:utf8
....
响应体:
.....重定向:
响应头:
status code
location:http://www.baidu.com
**************************************************************************
重定向只有响应头,里面又一个状态码(具体忘了是多少),还有一个location,是指向重定向网址的。
关于GET请求
Get请求只有请求头。
GitHub自动登录爬取
看到这份需求的第一步,需要先打开github的登陆页面测试下登陆:
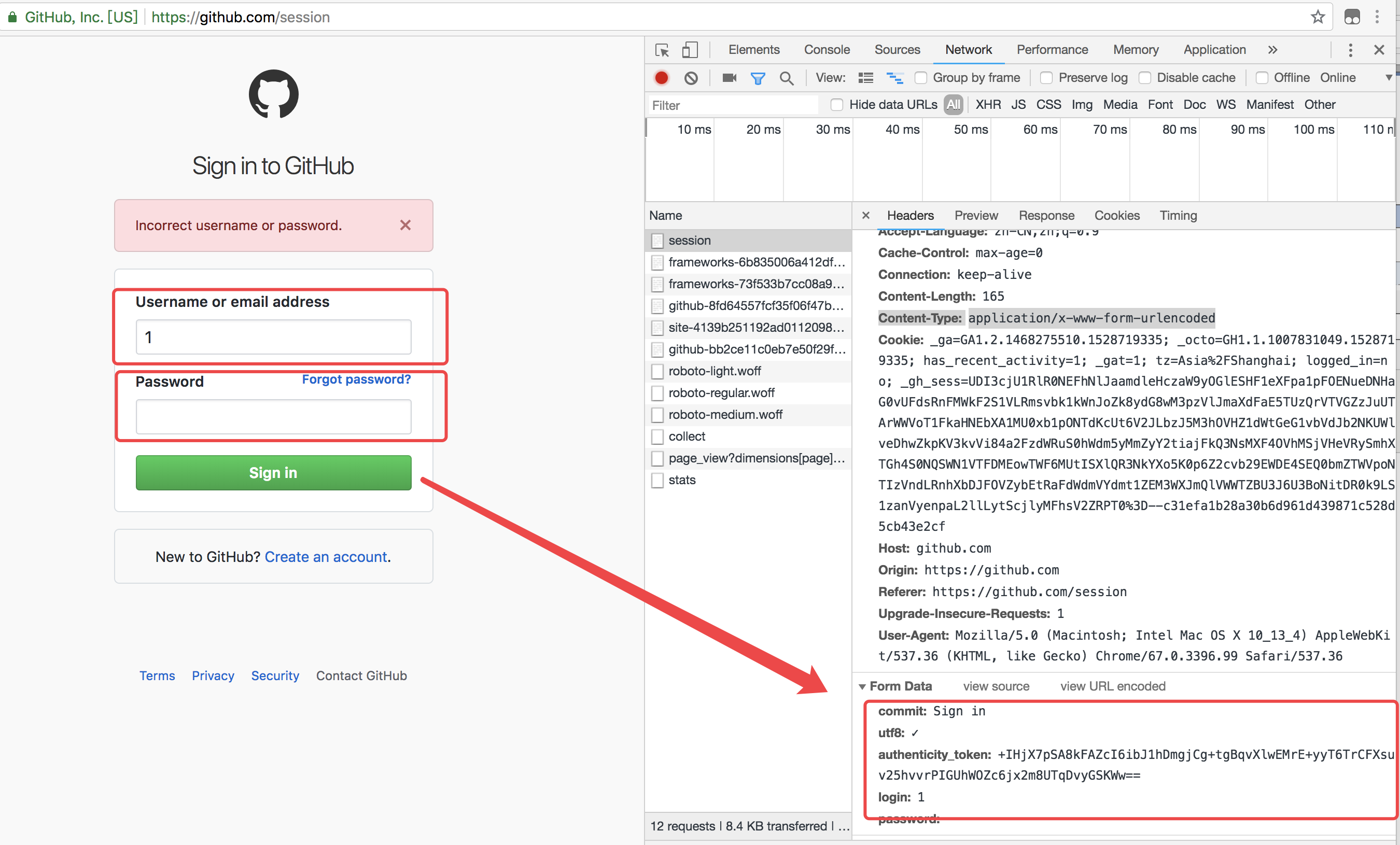
上面的图片,随便输入了账号密码测试,发现了两点
1、账号密码验证是form提交
2、熟悉的字眼token
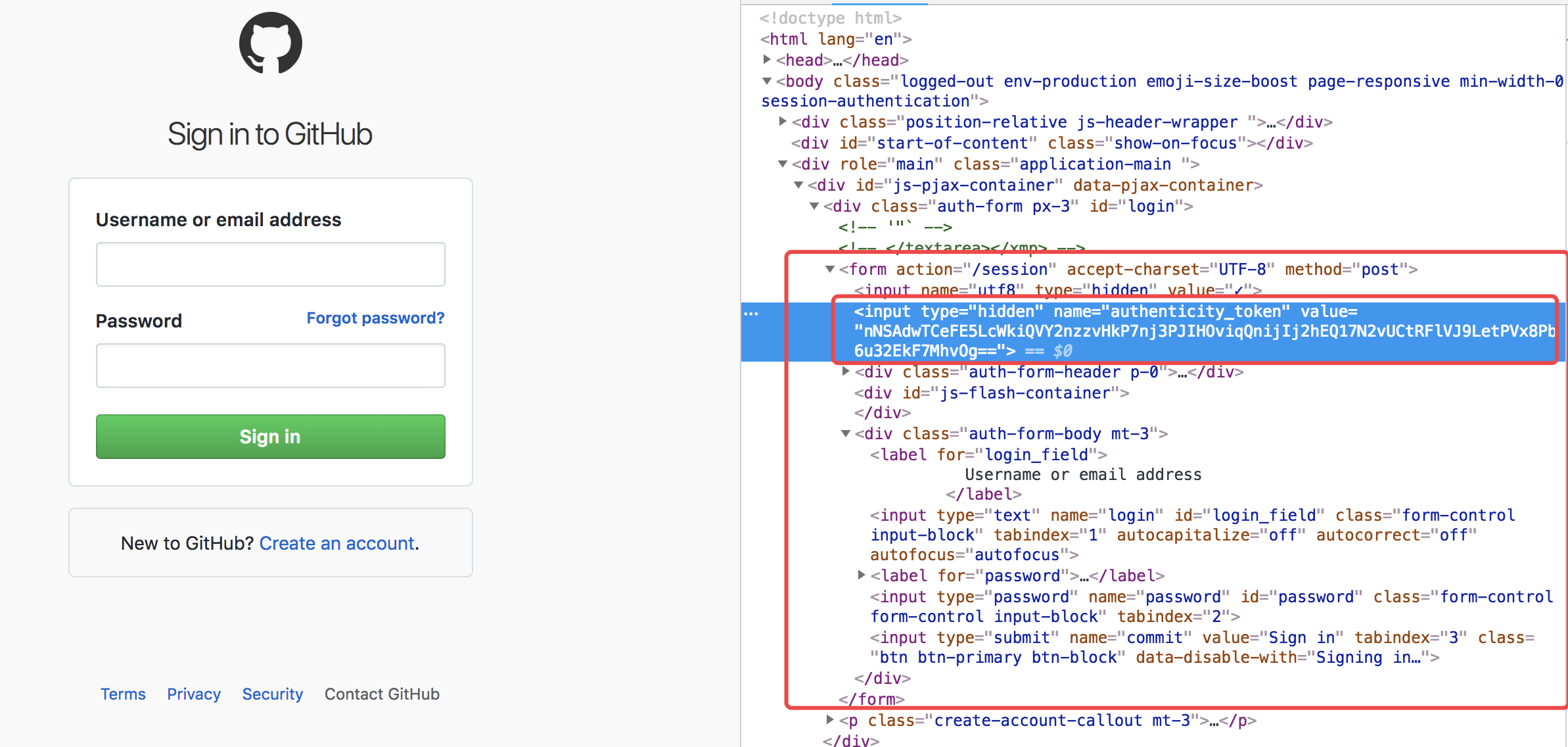
如果是从django看过来的小伙伴一定会会心一笑、懂了。所以,自动登录爬取数据的一般流程如下:
1、发送get请求,先获取到token值
2、发送post请求,进行登陆验证
3、带着cookie肆意妄为
代码如下:
importrequests
from bs4 importBeautifulSoup
# 第一步:发送第一次请求,获取csrftoken
r1 =requests.get(
url='https://github.com/login')
bs1 = BeautifulSoup(r1.text, 'html.parser') # 对获取到的文本对象解析获取token值
obj_token =bs1.find(
name='input',
attrs={'name': 'authenticity_token'}
)
# token = obj_token.attrs.get('value') # 获取token值的两种方式
token = obj_token.get('value')
print(token)
# 第二步:发送post请求,携带用户名密码并伪造请求头
r2 =requests.post(
url='https://github.com/session',
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': token,
'login': 'wuzdandz@qq.com',
'password': 'jiao88'}
)
r2_cookie =r2.cookies.get_dict()
print(r2_cookie)
print(r2.text)
# 因为是form data提交所以网页是走的重定向,获取状态码&location
# 1、根据状态码;2、根据错误提示
# 第三步:访问个人页面,携带cookie
r3 =requests.get(
url='https://github.com/settings/repositories',
cookies=r2_cookie
)
print(r3.text)
测试结果:
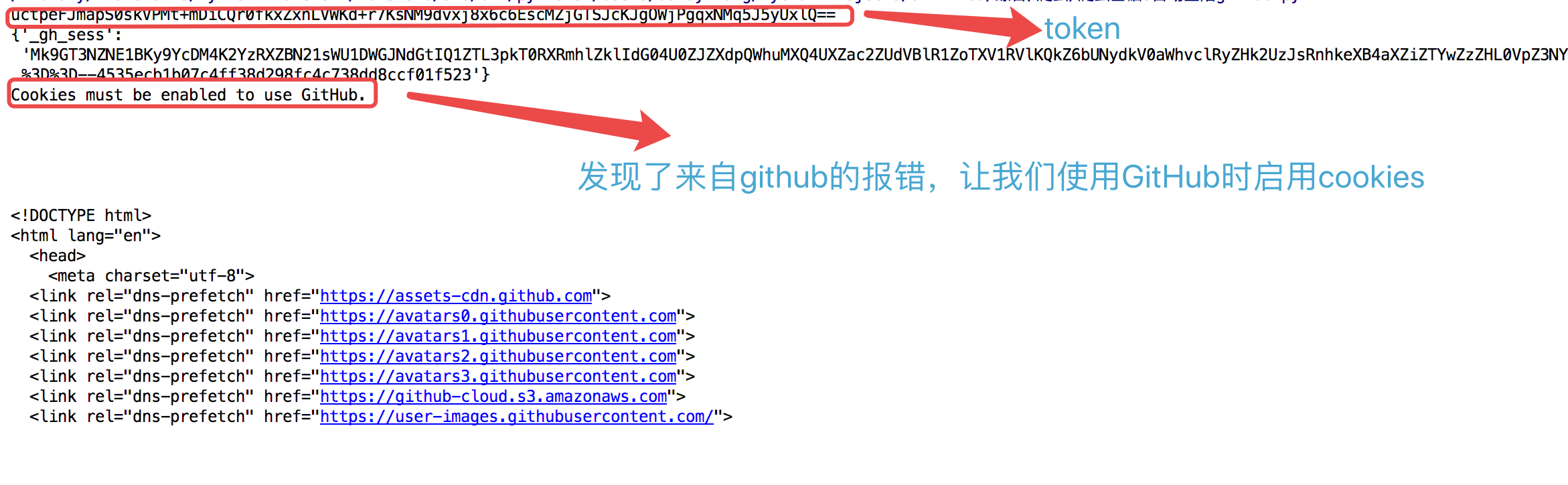
此时,github已经提示需要开启cookies。再来查看一次network:
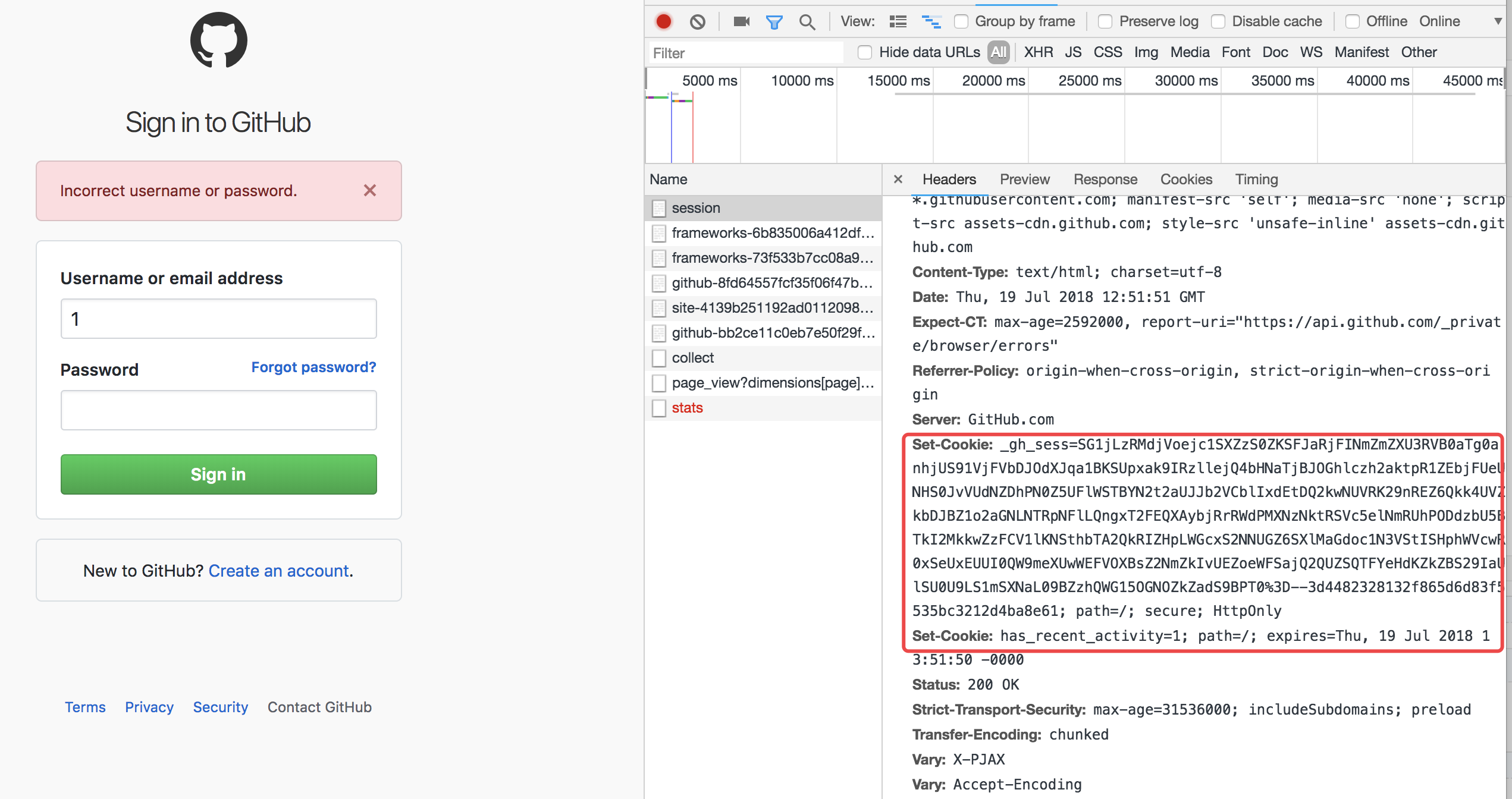
发现第一次响应头就带着cookie了。所以一般流程应该改成:
1、发送get请求,先获取到token值和cookie
2、发送post请求,带入账号名密码,cookies进行登陆验证
3、带着cookie肆意妄为
修改下代码:
importrequests
from bs4 importBeautifulSoup
# 第一步:发送第一次请求,获取csrftoken
r1 =requests.get(
url='https://github.com/login')
bs1 = BeautifulSoup(r1.text, 'html.parser')
obj_token =bs1.find(
name='input',
attrs={'name': 'authenticity_token'}
)
# token = obj_token.attrs.get('value')
token = obj_token.get('value')
r1_cookie = r1.cookies.get_dict() # 获取第一次cookie值、格式化成字典
print(r1_cookie)
# 第二步:发送post请求,携带用户名密码并伪造请求头
r2 =requests.post(
url='https://github.com/session',
data={
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': token,
'login': 'wuzdandz@qq.com',
'password': 'jiao88'},
cookies=r1_cookie # 带入第一次的cookie做验证
)
r2_cookie =r2.cookies.get_dict()
print(r2_cookie)
r1_cookie.update(r2_cookie) # 更新到第一次response的cookie字典里
print(r1_cookie)
# 因为是form data提交所以网页是走的重定向,获取状态码&location
# 1、根据状态码;2、根据错误提示
# 第三步:访问个人页面,携带cookie
r3 =requests.get(
url='https://github.com/settings/repositories',
cookies=r1_cookie # 带入cookie肆意妄为
)
print(r3.text)
结果:
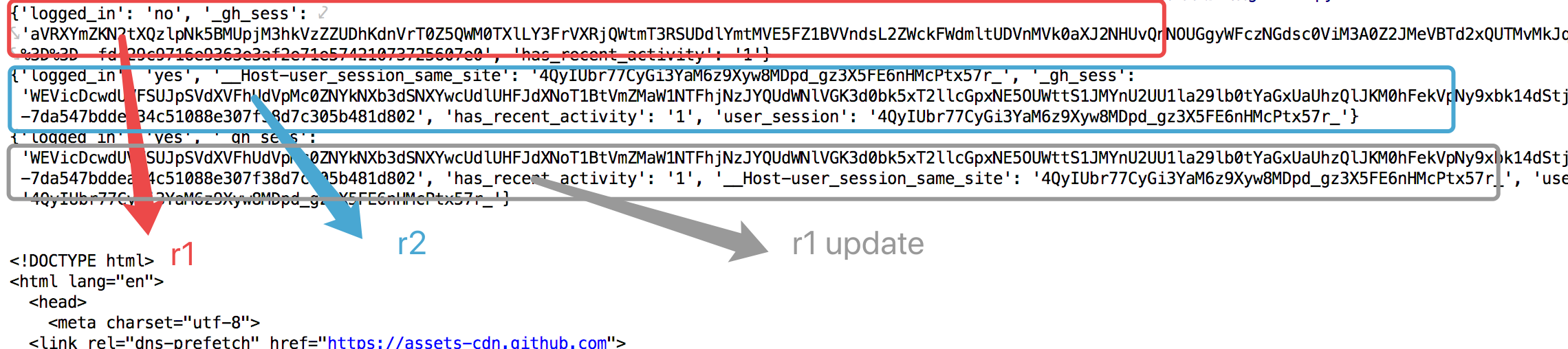
r3.text:
 View Code
View Code
最后
以上就是潇洒白羊最近收集整理的关于python爬虫自动登录_Python 爬虫四 基础案例-自动登陆github的全部内容,更多相关python爬虫自动登录_Python内容请搜索靠谱客的其他文章。








发表评论 取消回复