文章目录
- 1 信息熵
- 2 条件熵
- 3 互信息
- 4 相对熵(KL散度)
- 5 交叉熵
1948年,香农在著名的论文“通信的数学原理”中首次提出了熵(Entropy)的概念,这也解决了信息的度量问题,并量化了信息的作用。
1 信息熵
一条信息的信息量的多少,在直观上我们认为是和内容的多少有关,科学一点讲就是与不确定性有关,信息的不确定性越强,携带的信息量就越多。如果对于一件事一无所知,则这件事对于我们而言就具有极大的信息量,反之信息就极少。我们考虑以下一个问题:
- 在2014年的世界杯,32支球队参加了决赛,如果我们没有看世界杯,朋友也不直接告诉我们谁嬴得了冠军,通过猜的方式,我们需要几次才可以得到正确答案?(假设是7号得到冠军)
在最差的情况下,我们需要猜测五次。
1.冠军在1-16号球队? yes
2. 冠军在1-8号球队? yes
3. 冠军在1-4号球队? no
4. 冠军在5-6号球队?no
5. 冠军在7号球队?yes
所以对于谁是冠军这条信息而言,他的信息量为5,在信息里面,单位是比特(Bit)。如果是64只球队,那我们就需要多猜一次,需要6次得到答案,我们发现了信息的多少取决于log函数。
l
o
g
2
32
=
5
,
l
o
g
2
64
=
6
log_232=5, log_264=6
log232=5,log264=6
当然这是最差的情况下,我们需要5次才能猜出,在实际生活中,如果我们知道里面有巴西,德国等等强队,我们可能只需要3-4次就可以猜出来。这是因为引入了我们的先验知识,即各个球队夺冠的概率。记为
P
i
P_i
Pi。所以香农基于此提出了准确的信息量的度量——信息熵。
H
(
X
)
=
−
∑
p
i
l
o
g
(
p
i
)
H(X)=-sum p_ilog(p_i)
H(X)=−∑pilog(pi)
当所有球队的获胜概率一样时,信息量最大,不确定性越大,即最难猜出来。
2 条件熵
一直以来,信息和不确定性是联系在一起的,而信息和情报的英文表示都是information,情报是为了消除消息的不确定性,比如战争上的一句话的情报都可以改变战场。
一个事物X本身具有不确定性,记作U,为了消除这种不确定性,我们从外部引入信息I,当引入的信息I>U的时候,就可以事物的不确定性。当I<U时,就消除一部分的不确定性,得到新的不确定性 U ′ = U − I U'=U-I U′=U−I。
假设X,Y时两个随机变量,对于信息X,他的信息熵已经固定。随后我们知道了外部信息Y的情况,定义条件熵(conditional entropy)为:Y条件下X的条件概率分布的熵对Y的数学期望:
H ( X ∣ Y ) = ∑ y p ( y ) H ( X ∣ Y = y ) 进 一 步 推 导 : = − ∑ y p ( y ) ∑ x p ( x ∣ y ) l o g ( p ( x ∣ y ) ) = − ∑ y ∑ x p ( x , y ) l o g ( p ( x ∣ y ) ) = − ∑ x , y p ( x , y ) l o g P ( x ∣ y ) begin{aligned} H(X|Y)=&sum_{y}p(y)H(X|Y=y)\ 进一步推导: =&-sum_yp(y)sum_xp(x|y)log(p(x|y))\ =&-sum_ysum_xp(x,y)log(p(x|y))\ =& -sum_{x,y} p(x,y)logP(x|y) \ end{aligned} H(X∣Y)=进一步推导:===y∑p(y)H(X∣Y=y)−y∑p(y)x∑p(x∣y)log(p(x∣y))−y∑x∑p(x,y)log(p(x∣y))−x,y∑p(x,y)logP(x∣y)
另一个角度, H ( X ∣ Y ) = H ( X , Y ) − H ( Y ) H(X|Y)=H(X,Y)-H(Y) H(X∣Y)=H(X,Y)−H(Y)
H ( X , Y ) − H ( Y ) = − ∑ x , y p ( x , y ) log p ( x , y ) + ∑ y p ( y ) log p ( y ) = − ∑ x , y p ( x , y ) log p ( x , y ) + ∑ y ( ∑ x p ( x , y ) ) log p ( y ) = − ∑ x , y p ( x , y ) log p ( x , y ) + ∑ x , y p ( x , y ) log p ( y ) = − ∑ x , y p ( x , y ) log p ( x , y ) p ( y ) = − ∑ x , y p ( x , y ) log p ( x ∣ y ) begin{aligned} &H(X, Y)-H(Y) \ &=-sum_{x, y} p(x, y) log p(x, y)+sum_{y} p(y) log p(y) \ &=-sum_{x, y} p(x, y) log p(x, y)+sum_{y}left(sum_{x} p(x, y)right) log p(y) \ &=-sum_{x, y} p(x, y) log p(x, y)+sum_{x, y} p(x, y) log p(y) \ &=-sum_{x, y} p(x, y) log frac{p(x, y)}{p(y)} \ &=-sum_{x, y} p(x, y) log p(x mid y) end{aligned} H(X,Y)−H(Y)=−x,y∑p(x,y)logp(x,y)+y∑p(y)logp(y)=−x,y∑p(x,y)logp(x,y)+y∑(x∑p(x,y))logp(y)=−x,y∑p(x,y)logp(x,y)+x,y∑p(x,y)logp(y)=−x,y∑p(x,y)logp(y)p(x,y)=−x,y∑p(x,y)logp(x∣y)
可以证明得到H(X)>=H(X|Y),也就是说,引入了信息Y之后,X的信息熵变小了,即X的不确定性变小了。如果当X和Y完全没有任何关系的时候,等号依旧成立,说明引入外部信息Y没有丝毫意义。
总结:信息的作用在于消除不确定性,NLP问题就是寻找相关的信息。
3 互信息
在条件熵中我们发现了相关的信息可以消除不确定性,所以需要一个度量“相关性”的变量。也就是下文的互信息。定义:
I
(
X
;
Y
)
=
∑
x
,
y
P
(
x
,
y
)
l
o
g
P
(
x
,
y
)
P
(
x
)
P
(
y
)
I(X;Y)=sum_{x,y} P(x,y)log frac {P(x,y)}{P(x)P(y)}
I(X;Y)=x,y∑P(x,y)logP(x)P(y)P(x,y)
即是:
I
(
X
;
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
I(X;Y)=H(X)-H(X|Y)
I(X;Y)=H(X)−H(X∣Y)
当x和y完全不相关时,
I
(
X
;
Y
)
=
0
I(X;Y)=0
I(X;Y)=0
互信息用来度量两个事件的相关性后,用在了NLP机器翻译问题中,在机器翻译中,最难解决的问题之一就是词的歧义性,比如Bush既是“布什总统”的名字,也是“灌木丛”,产生了歧义,在机器翻译中,可以通过互信息,如果Bush和白宫,总统,美国等词出现了较高的互信息,就翻译为布什;如果和草地,地面,植物等词有较高的互信息,就翻译为灌木丛。这是20世纪90年代宾夕法尼亚大学的雅让斯基博士生提出的解决方法,也让他三年就拿到了博士学位。
4 相对熵(KL散度)
相对熵也用来衡量相关性,和互信息不同的是,它用来衡量取值为正数的相似性。
K
L
(
f
(
x
)
∣
∣
g
(
x
)
)
=
∑
x
f
(
x
)
⋅
l
o
g
f
(
x
)
g
(
x
)
KL(f(x)||g(x))=sum_x f(x)cdot logfrac{f(x)}{g(x)}
KL(f(x)∣∣g(x))=x∑f(x)⋅logg(x)f(x)
我们不必关注公式的本身,只需要记住下面三条结论即可:
- 对于完全相同的函数,相对熵为0
- 相对熵越大,两个函数之间的差异越大,反之成立。
- 对于概率分布或者概率密度函数,取值均>0时,相对熵可以度量两个随机分布的差异性。
此外,相对熵并不是对称的: K L ( f ( x ) ∣ ∣ g ( x ) ) ≠ K L ( g ( x ) ∣ ∣ f ( x ) ) KL(f(x)||g(x))neq KL(g(x)||f(x)) KL(f(x)∣∣g(x))=KL(g(x)∣∣f(x))
为了对称,詹森和香农提出了新的计算公式:
J
S
(
f
(
x
)
∣
∣
g
(
x
)
)
=
1
2
[
K
L
(
f
(
x
)
∣
∣
g
(
x
)
)
+
K
L
(
g
(
x
)
∣
∣
f
(
x
)
)
]
JS(f(x)||g(x))=frac 12[KL(f(x)||g(x))+KL(g(x)||f(x))]
JS(f(x)∣∣g(x))=21[KL(f(x)∣∣g(x))+KL(g(x)∣∣f(x))]
5 交叉熵
对相对熵的公式进行变形:
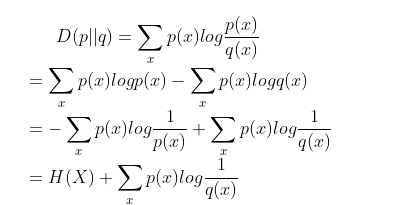
进一步得到交叉熵的公式:
H
(
p
,
q
)
=
−
∑
p
l
o
g
(
q
)
H(p,q)=-sum plog(q)
H(p,q)=−∑plog(q)
可以衡量两个概率分布p.q之间的相似程度,交叉熵越小,两个概率分布就越接近,所以可以当作分类问题的损失函数。
最后
以上就是会撒娇铃铛最近收集整理的关于通俗易懂——信息熵,条件熵,互信息和相对熵1 信息熵2 条件熵3 互信息4 相对熵(KL散度)5 交叉熵的全部内容,更多相关通俗易懂——信息熵,条件熵,互信息和相对熵1内容请搜索靠谱客的其他文章。








发表评论 取消回复