一 什么是搜索引擎
- 就是根据客户需求,运用一定的算法将数据通过检索的方式呈现给客户
二 倒排索引
- 将一段文本按照一定的规则,进行
分词,拆分成不同的词条然后记录词条和数据的唯一标识(ID)关系。 - 举例
假如我们在jd搜索“手机”关键词,此时我们是客户端,服务端会显示各种品牌手机,其名称各种各样,如华为手机、诺基亚手机、苹果手机等,这个时候服务端就将“xx手机”拆分为词条,服务端将搜索该词条返回给客户端。
三 elasticsearch概念
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
四 elasticsearch核心概念
- 索引:
es存储数据的地方,可以理解为关系型数据库中的数据库 - 映射:
定义了每个字段的类型,可以理解为关系型数据库中的表结构 - 文档:
es中的最小数据单元,常以json格式显示,一个文档相当于关系型数据库中的一行数据 - 倒排索引:
将一段文本按照一定的规则,进行分词,拆分成不同的词条然后记录词条和数据的唯一标识(ID)关系。 - 类型:
一种type相当于一张表
1:es5中一个index可以有多个type。
2:es6中一个index只能由一个type。
3:es7中已经移除了type,默认_doc。
五elasticsearch使用场景
- 原文连接
https://blog.csdn.net/laoyang360/article/details/52227541
- 总结:es在整个架构中充当的角色为“
搜索引擎”的角色,需要将数据库中的数据实时同步到es中,供给客户端检索。
六 elasticsearch官网
https://www.elastic.co/
七 安装es
版本:elasticsearch-7.4.0es是基于jdk环境,但是es在部署中包含了jdk环境,无需我们再次安装,并且es对应jdk版本环境,推荐使用其包含的jdk版本
1. 上传解压
tar xvf elasticsearch-7.4.0-linux-x86_64.tar.gz -C ~/APP
2. 修改配置文件
cat << EOF >> /home/finance/APP/elasticsearch-7.4.0/config/elasticsearch.yml
#配置elasticsearch集群名称,建议修改成一个有意义的名称。
cluster.name: elasticsearch
#节点名称,elasticsearch会随机指定一个名称,建议修改成一个有意义的名称,方便管理。
node.name: node-1
#设置为0.0.0.0允许外网访问。
network.host: 0.0.0.0
#es的http端口
http.port: 9200
#初始化集群的时候需要此配置来进行master选举
cluster.initial_master_nodes: ["node-1"]
#数据目录位置
path.data: /home/finance/data/es7
#日志路径
path.logs: /home/finance/logs/es7
EOF
2.1 其他可配置参数
| 参数 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
3.优化系统参数
使用root用户
#修改limit最大打开数量
cat << EOF >> /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
EOF
#修改最大虚拟内存大小
cat << EOF >> /etc/sysctl.conf
vm.max_map_count=655360
fs.file-max=655360
EOF
#生效配置
sysctl -p
4.优化jvm参数
#将默认的1G改为512,也可根据业务需求更改
vim config/jvm.options
-Xms512m
-Xmx512m
5. 配置环境变量并启动
为了安全起见,es不允许root用户启动。
echo 'export PATH=$PATH:/home/finance/APP/elasticsearch-7.4.0/bin' >> /etc/profile.d/elasticsearch.sh
source /etc/profile.d/elasticsearch.sh
#启动
elasticsearch -d
#验证,也可使用web页面
curl -I localhost:9200
八 es索引相关操作
1.接口请求方式
- Get
向特定资源发出请求(请求指定页面信息,并返回实体主体) - Post
向指定资源提交数据进行处理请求(提交表单、上传文件),又可能导致新的资源的建立或原有资源的修改 - Put
向指定资源位置上上传其最新内容(从客户端向服务器传送的数据取代指定文档的内容) - Head
与服务器索与get请求一致的相应,响应体不会返回,获取包含在小消息头中的原信息(与get请求类似,返回的响应中没有具体内容,用于获取报头) - Delete
请求服务器删除request-URL所标示的资源*(请求服务器删除页面) - Trace
回显服务器收到的请求,用于测试和诊断 - opions
返回服务器针对特定资源所支持的HTML请求方法 或web服务器发送*测试服务器功能(允许客户端查看服务器性能)
2. es常用接口请求
-
工具为postman
-
get:查
-
put:增
-
post:改
-
delete:删
2.1 增加索引
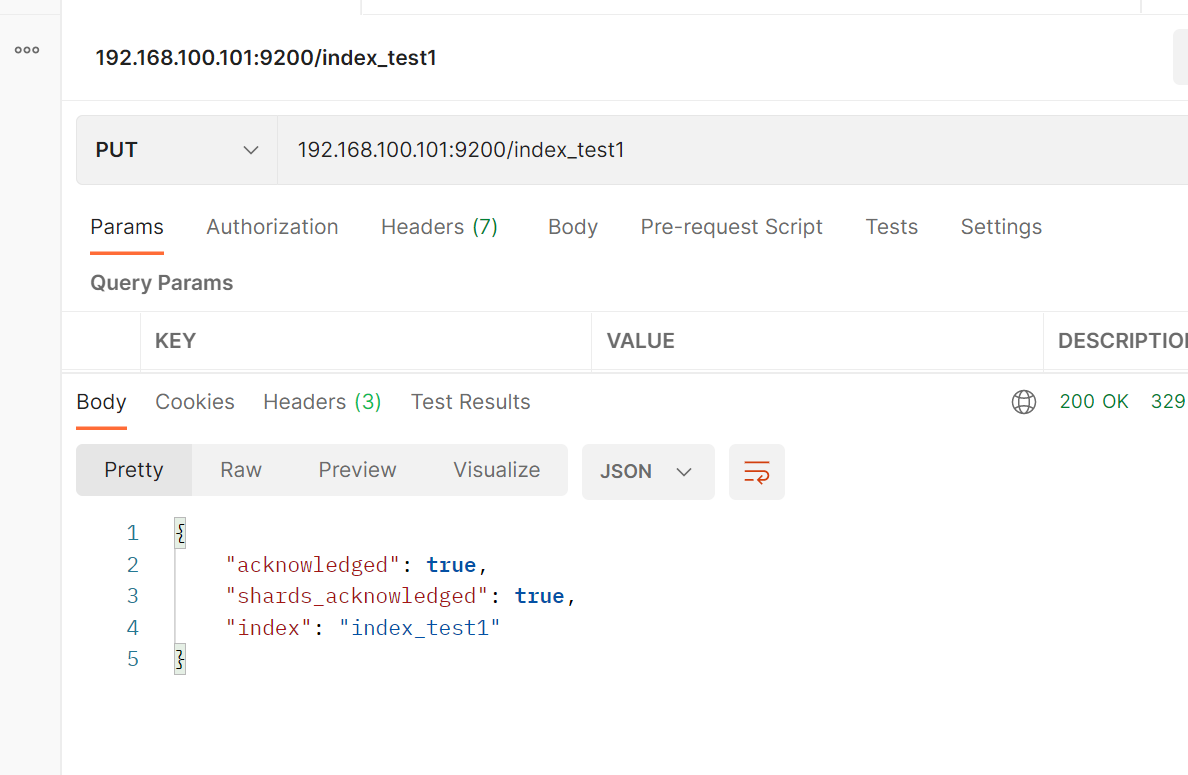
2.2 查看索引
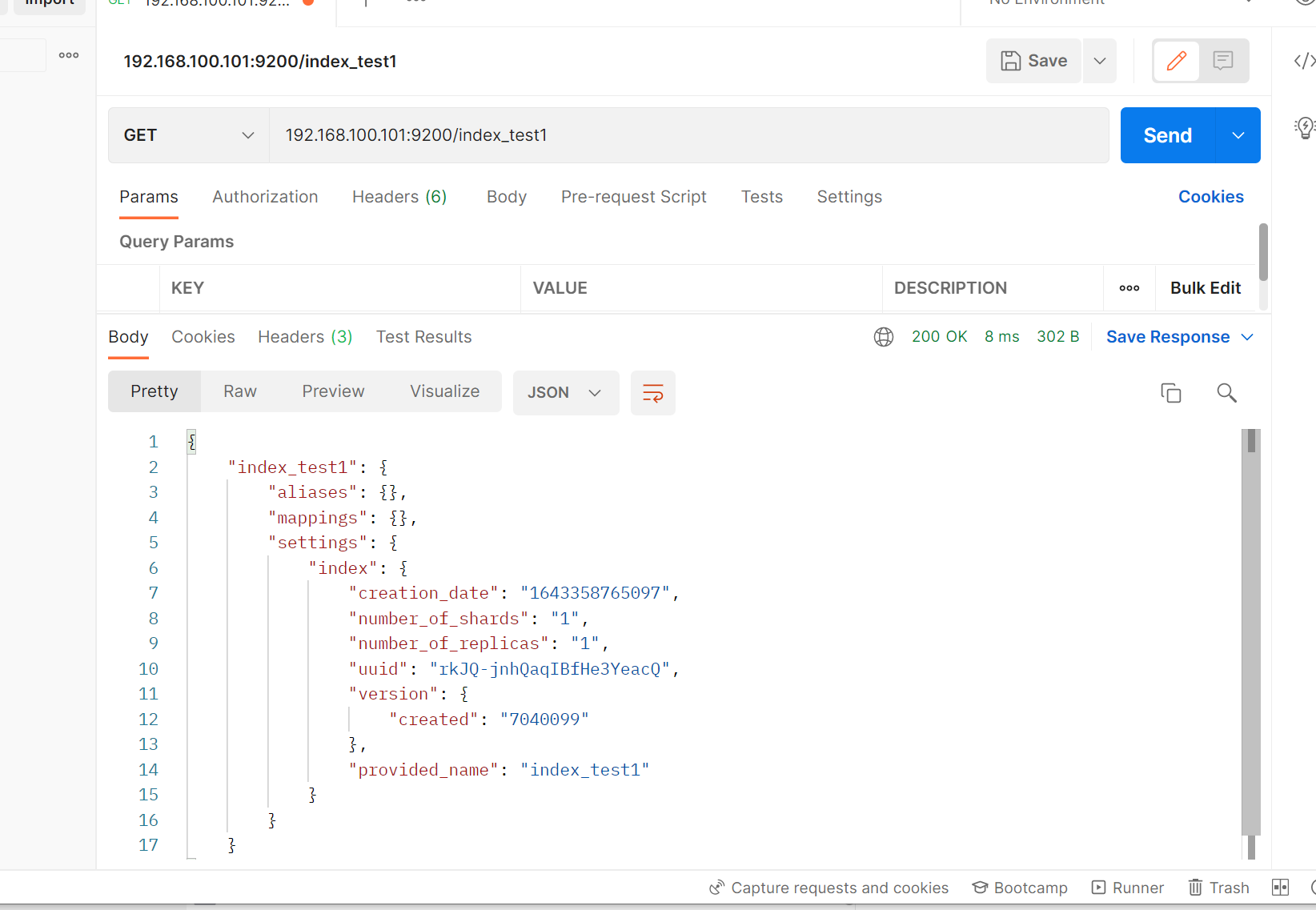
2.3 删除索引
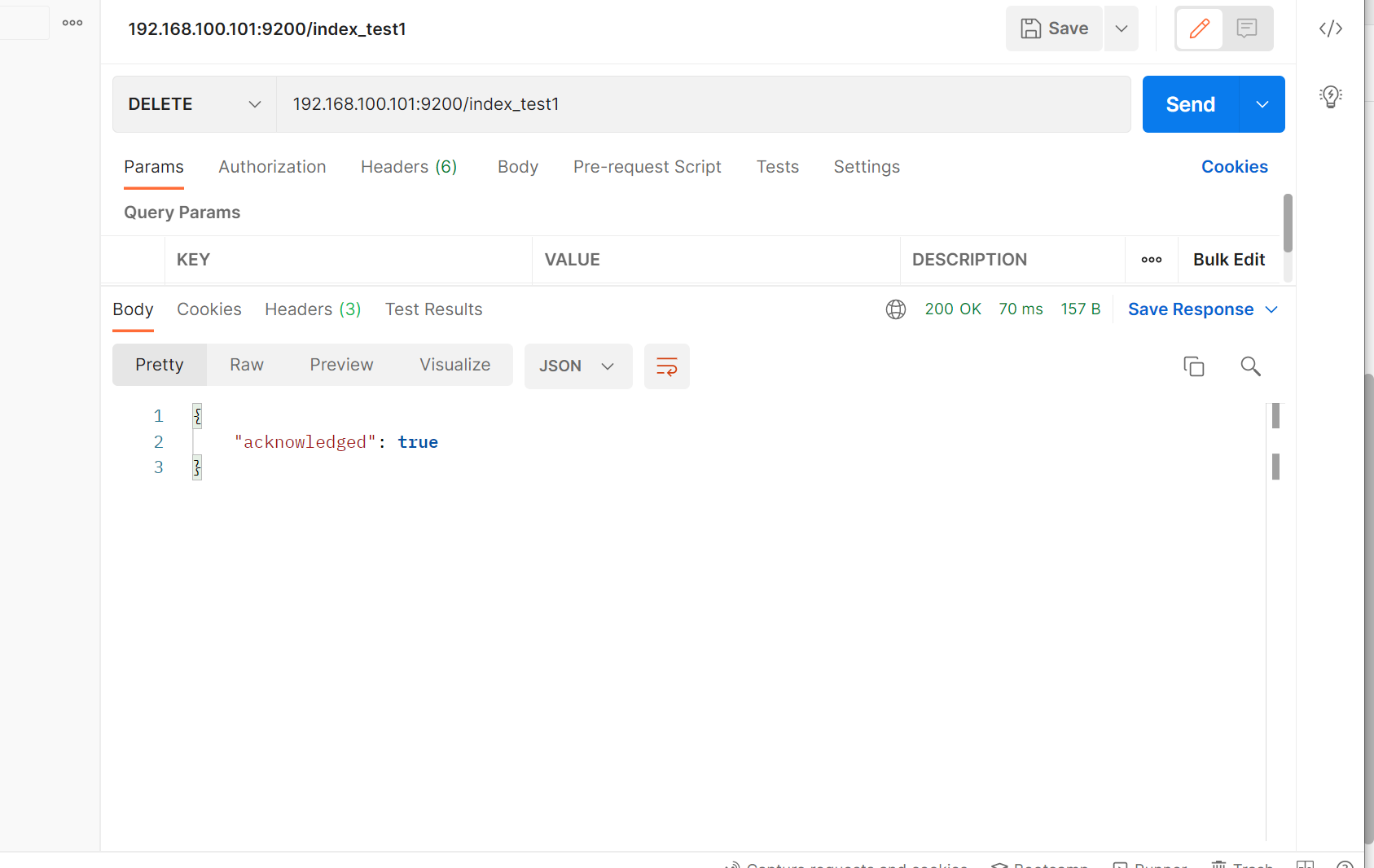
2.4 关闭索引
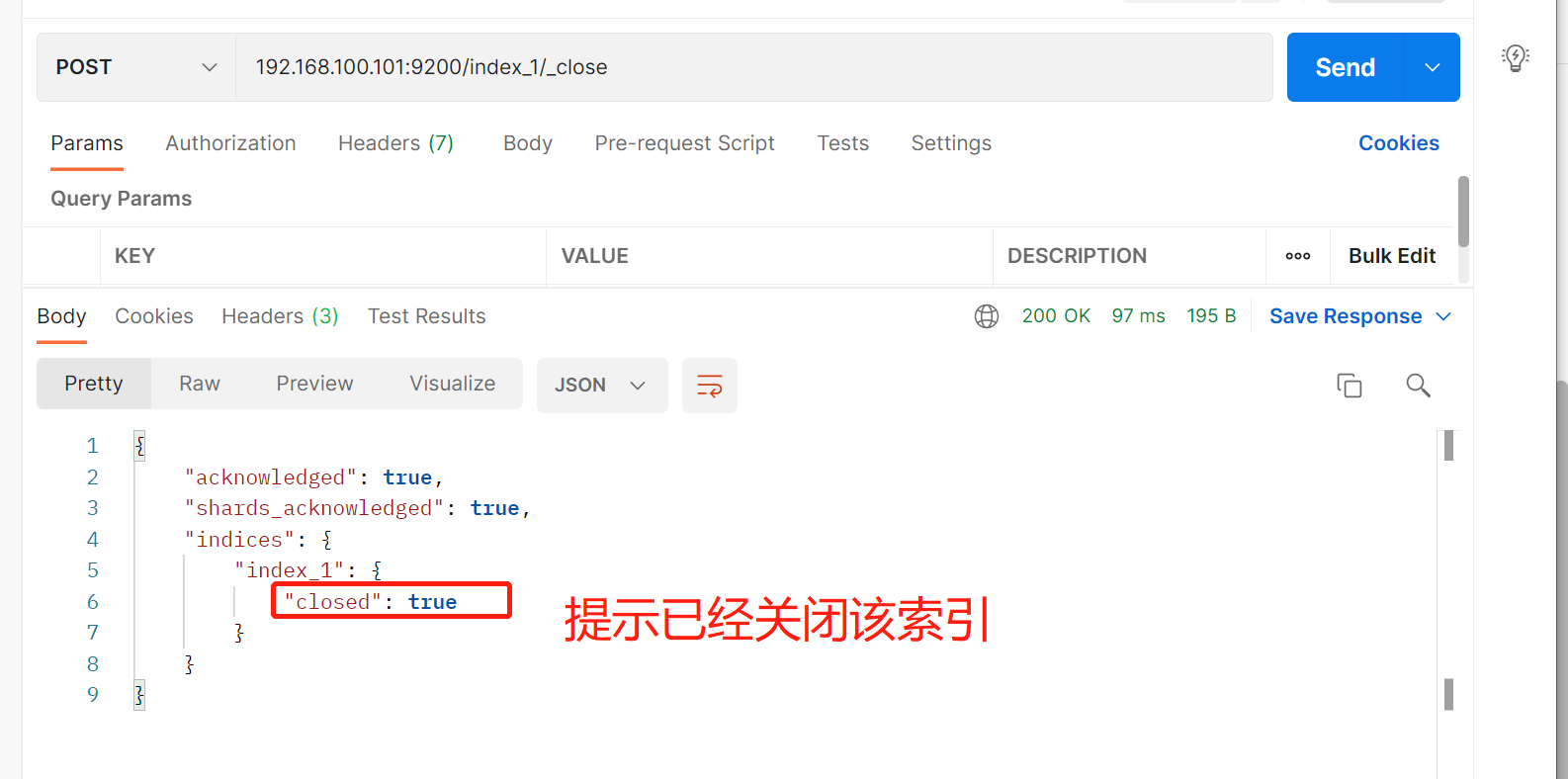
2.5 打开索引
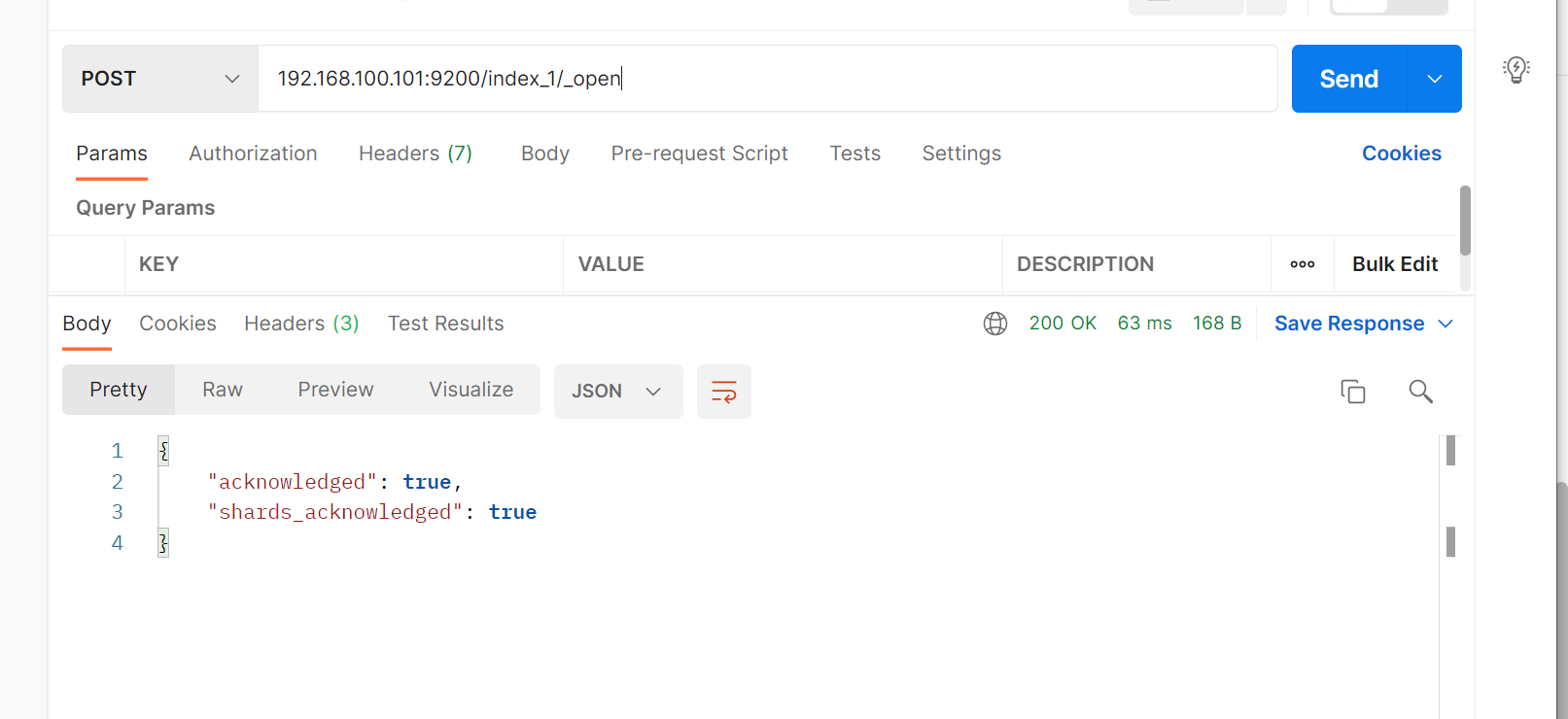
九 es集群分布式架构
1. 集群部署
1.1 主机分布
| clsuter name | node name | IP | PORT |
|---|---|---|---|
| elasticsearch | node-1 | 192.168.100.101 | 9200 |
| elasticsearch | node-2 | 192.168.100.102 | 9200 |
| elasticsearch | node-3 | 192.168.100.102 | 9200 |
1.2 配置文件更改
node-1
# 集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-1
# 绑定IP地址
network.host: 0.0.0.0
# 指定服务访问端口
http.port: 9200
# 指定API端户端调用端口
transport.tcp.port: 9300
#集群通讯地址
discovery.seed_hosts: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
#数据目录位置
path.data: /home/finance/data/es7
#日志路径
path.logs: /home/finance/logs/es7
node-2
# 集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-2
# 绑定IP地址
network.host: 0.0.0.0
# 指定服务访问端口
http.port: 9200
# 指定API端户端调用端口
transport.tcp.port: 9300
#集群通讯地址
discovery.seed_hosts: ["192.168.100.101:9300", "192.168.100.102:9301","192.168.100.103:9302"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.100.101:9300", "192.168.100.102:9301","192.168.100.103:9302"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
#数据目录位置
path.data: /home/finance/data/es7
#日志路径
path.logs: /home/finance/logs/es7
node-3
cluster.name: elasticsearch
#节点名称
node.name: node-3
# 绑定IP地址
network.host: 0.0.0.0
# 指定服务访问端口
http.port: 9200
# 指定API端户端调用端口
transport.tcp.port: 9300
#集群通讯地址
discovery.seed_hosts: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
#数据目录位置
path.data: /home/finance/data/es7
#日志路径
path.logs: /home/finance/logs/es7
1.3 查看节点及状态
#查看健康状态
curl localhost:9200/_cat/health?v
curl localhost:9200/_cat/nodes
1.3.1 健康状态回显说明
cluster
集群名称status
集群状态,共有三种状态,分别green(正常)、red(代表主分片不可以,可能已经丢失数据)、yellow(代表了主分片,但至少缺失了一个副本,此时集群数据仍完整)node.total
在线的节点总数量node.data
在线的数据节点总数量shards
存活的分片数量pri
存活的主分片数量,正常情况下,pri是shards的两倍relo
迁移中的分片数量,正常是0init
初始化中的分片数量,正常是0unassign
未分配的分片,正常是0pending_tasks
准备中的任务,任务指迁移中的分片等,正常是0max_task_wait_time
任务最长等待时间active_shards_percent
正常分片百分比,正常情况为100%
2. 集群概念
2.1 集群
elasticsearch集群是由一个或者多个节点组成的集合。每一个集群都有一个唯一的名称。默认是elasticsearch,我们可以自己设置的cluster_name的值,cluster_name的值非常重要,一个节点就是通过集群的名称加入集群的。然后,每一个节点都有自己的名称。节点是可以存储数据,参与集群索引数据,以及搜索数据的独立服务。
2.2 分片
因为 ES 是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节。
2.3 副本
ES 默认为一个索引创建 5 个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由 5 个主分片成本, 而每个主分片都相应的有一个 copy。对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求,它们的唯一区别在于只有主分片才能处理索引请求.副本对搜索性能非常重要,同时用户也可在任何时候添加或删除副本。额外的副本能给带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。
十 kibina
1. 部署
1.1下载kibina
kibana版本要与es版本匹配,不然会出现兼容性问题,此次部署的es7x
#查看es版本
elasticsearch -V
#kibana下载
https://www.elastic.co/cn/downloads/past-releases
1.2 部署kibana
tar xvf kibana-7.4.0-linux-x86_64.tar.gz -C APP/
cd APP/
mv kibana-7.4.0-linux-x86_64/ kibana
cat >> /home/finance/APP/kibana/config/kibana.yml << EOF
#开启中文
i18n.locale: "zh-CN"
#http端口
server.port: 5601
#地址,此处不可写127.0.0.1,不然web页面访问不了
server.host: "192.168.100.101"
#服务名称
server.name: kibana
#es地址
elasticsearch.hosts: ["http://localhost:9200/"]
EOF
1.3 全局变量
cat >> /etc/profile.d/kibana.sh << EOF
export PATH=$PATH:/home/finance/APP/kibana/bin
EOF
source /etc/profile.d/kibana.sh
1.4 启动并验证
kibana >> /home/finance/logs/kibana.log &
#jobs查看是否running状态
#查看5601端口
#web访问IP:5601
2. 管理es集群
2.1 修改kibana配置
#此处为es集群地址,修改完以后重启kibana
elasticsearch.hosts: ["http://localhost:9200","http://192.168.100.101:9200","http://192.168.100.102:9200"]
十一 集群管理
1. 分片配置
在创建索引时,如果不指定分片,则默认主分片为1,副本分片为1.
1.1 创建分片
3个主分片,一个副本分片
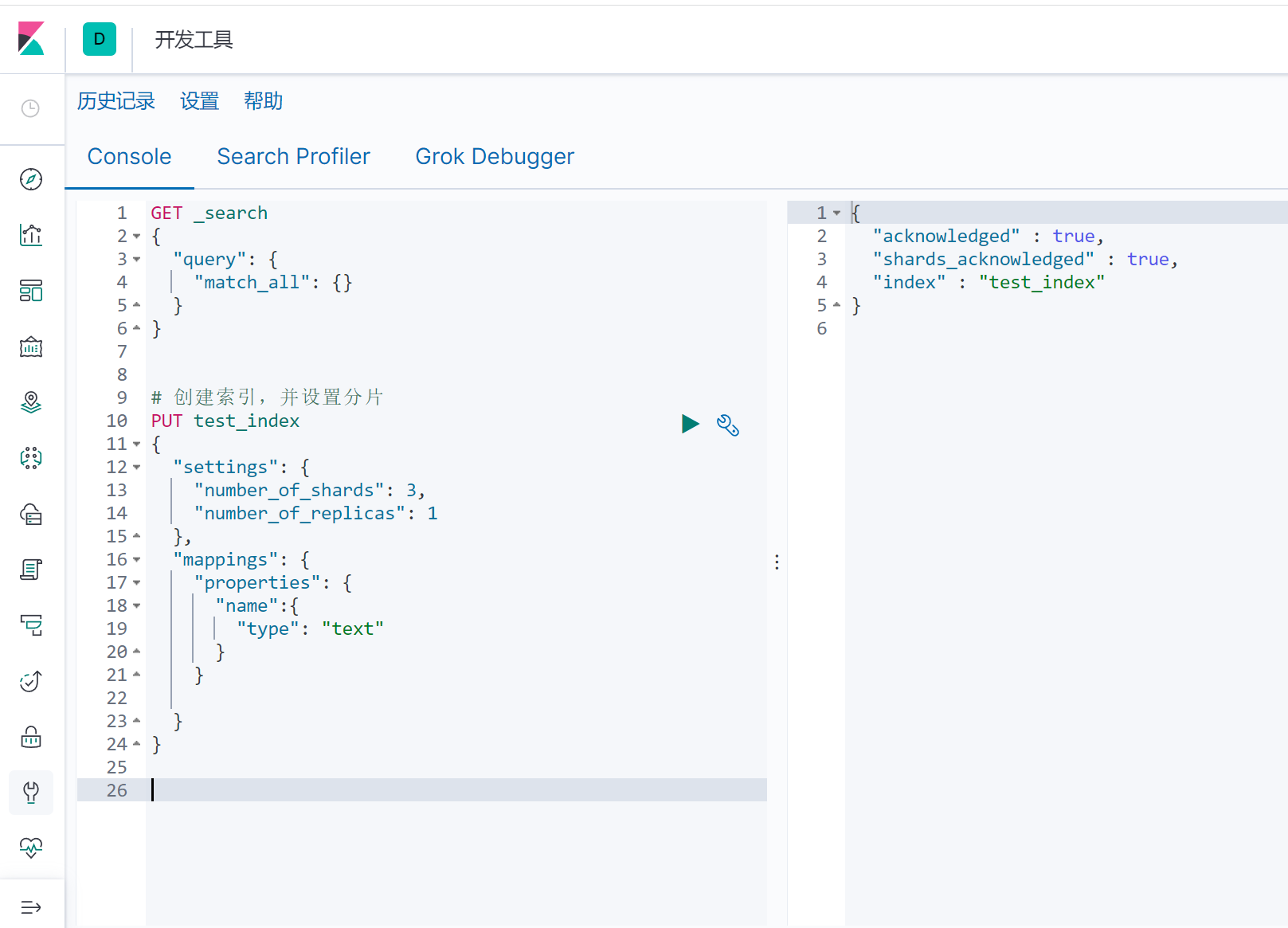
查看索引分片及副本
可以看到主分片及副本分片,在三个节点上都已经存在,如果node-1节点宕机,还可以通过其他两个节点获取到索引分片。
2.脑裂
一个es集群中,启动了多台master,即为脑裂
2.1 网络问题
集群通信因为网络延迟、波动等情况,node节点与master节点失联,将会在选举一个master,这个时候就出现了脑裂的问题。
2.1.1 避免脑裂
discovery.zen.ping.timeout超时时间设置大一些,默认是3s
2.2 节点负载
主节点的角色即为master又为date,数据量访问较大时,可能出现假死状态。
配置文件参数:
#是否有主节点资格
node.master: true
#是否存储数据
node.date: true
2.2.1 避免脑裂
角色分离策略
- 候选主节点配置
#是否有主节点资格
node.master: true
#是否存储数据
node.date: false
- 数据节点配置
#是否有主节点资格
node.master: false
#是否存储数据
node.date: true
2.3 jvm回收
当master节点设置的jvm内存较小时,引发jvm大量的内存回收,造成es失去响应
2.3.1 避免脑裂
elasticsearch-7.4.0/config/jvm.options里-Xms,-Xmx
十二 logstash
1. logstash简述
logstash是一个数据收集引擎,是数据源与数据分析存储分析工具之间重要的桥梁,他有着丰富的过滤器插件。
2.logstash组件讲解
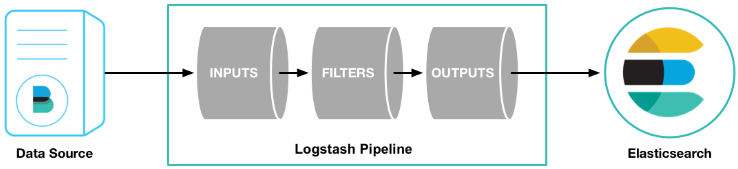
logstash由三部分组成,imput、filter、output
2.1 input输入插件
此插件作用为使 Logstash 能够读取特定的事件源,及使用此插件可选择从不同的数据源抽取数据
官网可选插件:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
2.2 filter过滤器插件
此插件为将input插件获取的数据进行特定的条件过滤
官网可选插件https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
2.3 output输出插件
此插件作用为将事件数据输出到指定的目的地,也就是说会将imput读取到的数据,经过filter过滤,然后通过output插件输出到指定的地方
官网可选插件:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
2.4 流程图
最后
以上就是内向小蝴蝶最近收集整理的关于elastic stack一 什么是搜索引擎二 倒排索引三 elasticsearch概念四 elasticsearch核心概念五elasticsearch使用场景六 elasticsearch官网七 安装es八 es索引相关操作九 es集群分布式架构十 kibina十一 集群管理十二 logstash的全部内容,更多相关elastic内容请搜索靠谱客的其他文章。








发表评论 取消回复