目录
- 写在前面
- DFS算法
- 所解决的问题
- 所需要的数据结构
- 代码结构及解释
- 方法一:递归
- 解释
- 递归dfs总结
- 方法二:栈
- 解释
- 栈dfs总结
写在前面
因为楼主也是刚开始刷leetcode,所以下面的内容都是自己的理解,如果有不对或者讲的不准确的地方欢迎评论区指出
DFS算法
就是一条路走到黑的算法,走不通了就往回走
所解决的问题
- 如果只是要找到某一个结果是否存在,那么DFS会更高效。因为DFS会首先把一种可能的情况尝试到底,才会回溯去尝试下一种情况,只要找到一种情况,就可以返回了。但是BFS必须所有可能的情况同时尝试,在找到一种满足条件的结果的同时,也尝试了很多不必要的路径;
- 如果是要找所有可能结果中最短的,那么BFS回更高效。因为DFS是一种一种的尝试,在把所有可能情况尝试完之前,无法确定哪个是最短,所以DFS必须把所有情况都找一遍,才能确定最终答案(DFS的优化就是剪枝,不剪枝很容易超时)。而BFS从一开始就是尝试所有情况,所以只要找到第一个达到的那个点,那就是最短的路径,可以直接返回了,其他情况都可以省略了,所以这种情况下,BFS更高效。
所需要的数据结构
- 队列:stack
- 哈希表(可以用别的):记录搜索过的节点
代码结构及解释
方法一:递归
// 强调写递归函数的技巧
// 一般来说dfs的参数是那些在递归的过程需要变化的参数,
// 比如说坐标x,y(这个与你树父节点与子节点的连接方式有关,
// 在矩阵路径中一般就是上下左右4个方向,或者是二叉树的左右子树)
void dfs()
{
// 写终止条件,即递归到什么时候停止,比如二叉树中子树为空,矩阵路径
// 中超出地图边界等等,当然根据问题不同这个地方也会有些变化
if ()
return;
// 当然为了防止反复遍历遍历过的节点,把遍历过的点标记
visited
// 递归与当前节点相连的要搜索的点。比如说矩阵路径中的上下左右四个点
// 又或者父节点的左右子节点
dfs();
dfs();
... // 取决当前节点每次循环递归需要遍历的子节点
return;
}
解释
通过一个leetcode题来解释整个dfs递归的过程

这个题的解法是对网格中的每一个点进行dfs搜索,基于每一个点搜索其上下左右四个点,如果满足条件,岛屿面积+1,基于满足条件的点继续搜索,直到当前根节点搜索完毕返回岛屿面积,最后返回最大的岛屿面积即可,上代码;
class Solution {
public:
int dir[4][2] = {{1, 0}, {0, 1}, {-1, 0}, {0, -1}};
int ans, m, n;
int dfs(vector<vector<int>>& grid, int x, int y)
{
if (x < 0 || y < 0 || x == m || y == n)
return ans;
if (grid[x][y] == 0)
return ans;
ans++;
grid[x][y] = 0; // 如果没有这一步循环就会一直继续
for (int i = 0; i < 4; i++)
{
dfs(grid, x + dir[i][0], y + dir[i][1]);
}
return ans;
}
int maxAreaOfIsland(vector<vector<int>>& grid) {
m = grid.size(), n = grid[0].size();
int maxAns = 0;
for (int i = 0; i < m; i++)
{
for (int j = 0; j < n; j++)
{
ans = 0;
maxAns = max(dfs(grid, i, j), maxAns);
}
}
return maxAns;
}
};
下面的分析过程建议读者参照题目的图和上面这个题解代码看。
如图,该题的做法就是对网格中的每一个点进行dfs搜索,找到最大的岛屿面积。对于任何一个当前点进入到dfs函数中,由于本题网格连接的方向只有上下左右,我们可以画出如下树状图,以点(0,7)为例
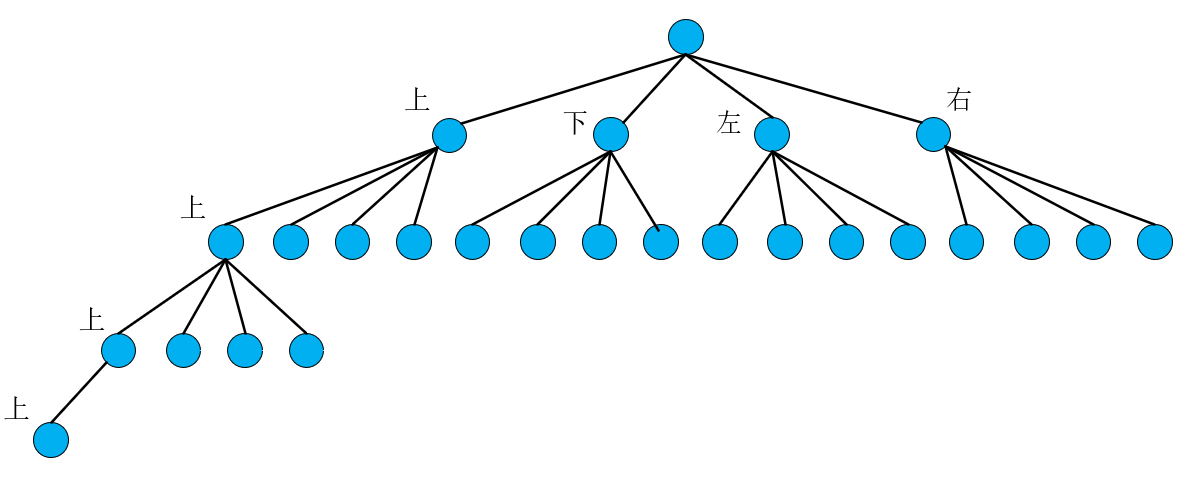
为什么说DFS算法是一条路走到黑,如果是从根节点开始进入dfs,假设不考虑dfs中的if return这个语句,就会直接进入到dfs中,假设一个dfs函数中套着四个递归函数dfs,如下代码所示。
// 强调写递归函数的技巧
// 一般来说dfs的参数是那些在递归的过程需要变化的参数,
// 比如说坐标x,y(这个与你树父节点与子节点的连接方式有关,
// 在矩阵路径中一般就是上下左右4个方向,或者是二叉树的左右子树)
void dfs()
{
// 递归与当前节点相连的要搜索的点。比如说矩阵路径中的上下左右四个点
// 又或者父节点的左右子节点
dfs(); // 当前节点上方节点
dfs(); // 当前节点下方节点
dfs(); // 当前节点左方节点
dfs(); // 当前节点右方节点
return;
}
可以发现,每次递归函数都是先进入第一个dfs(),重新递归又是先进入第一个dfs,所以搜索会一直沿着上这个方向走下去,这就是一条路走到黑,这也就是说明为什么这个算法叫做深度优先搜索
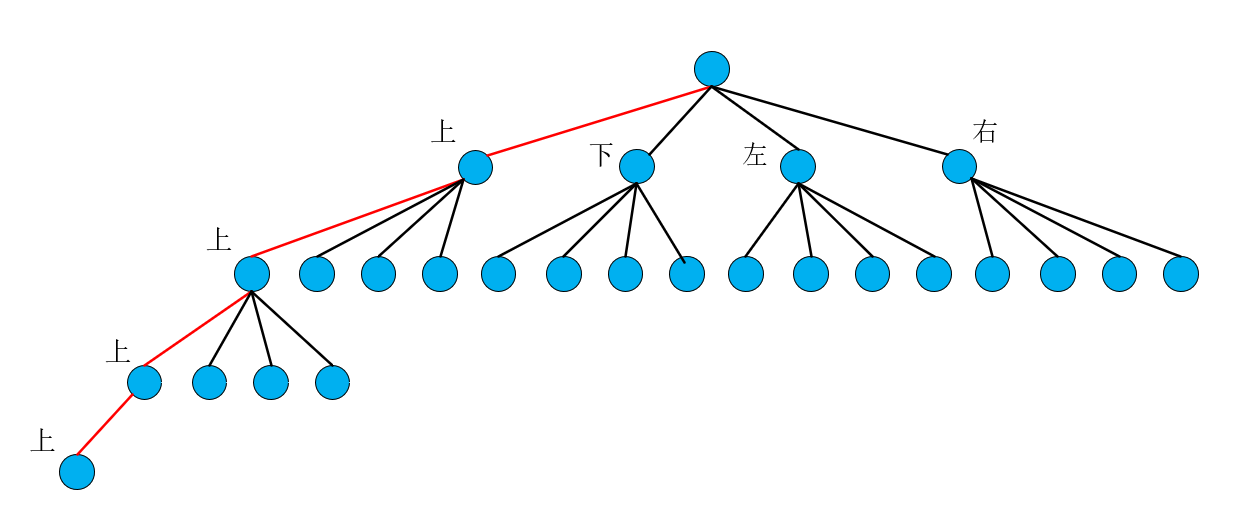
但是递归的过程不可能无休止的下去,所以递归需要一个终止条件,这个终止条件根据任务的不同而自己决定,在本示例中终止条件是,如果当前节点超出网格范围或者当前节点的grid值为0的时候就不用往下递归了。
假设当前网格为(0,7),进入到dfs中,首先判断终止条件,不符合条件开始递归第一个方向为上的dfs。
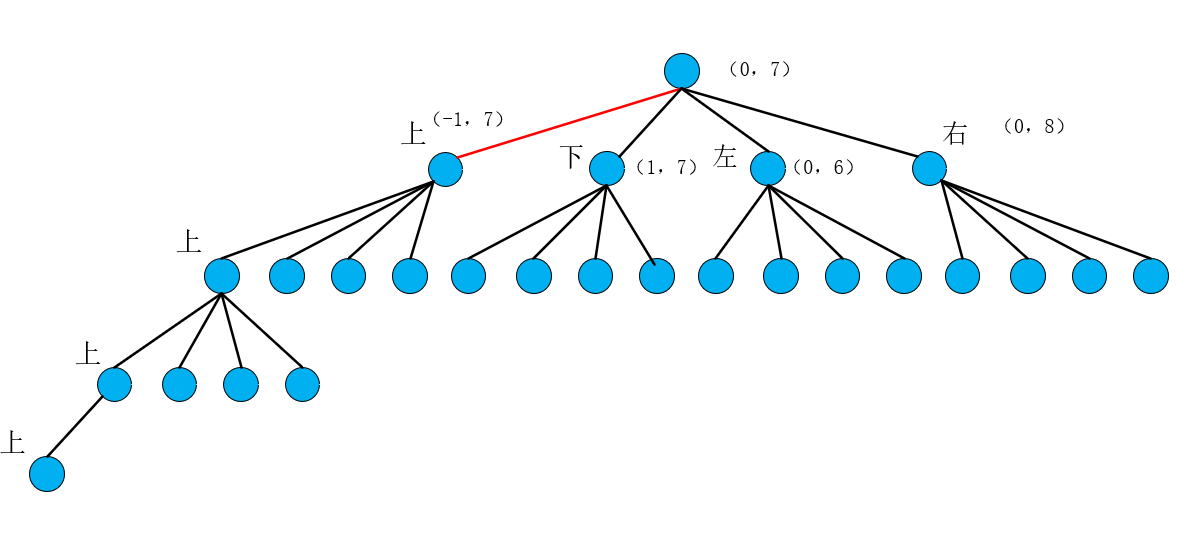
可以发现递归上这个方向时,进入到新的dfs()函数中,首先判断(-1,7)这个网格,明显是满足终止条件的,所以这个方向直接终止,返回到上一层递归函数中。
void dfs() // 当前点为根节点
{
if() return;
dfs(); // 当前节点上方节点,这个方向进入无法前进,所以return出来,现在运行下一条语句
dfs(); // 当前节点下方节点,上一条dfs递归发现路不通,所以运行这个递归,
dfs(); // 当前节点左方节点
dfs(); // 当前节点右方节点
return;
}
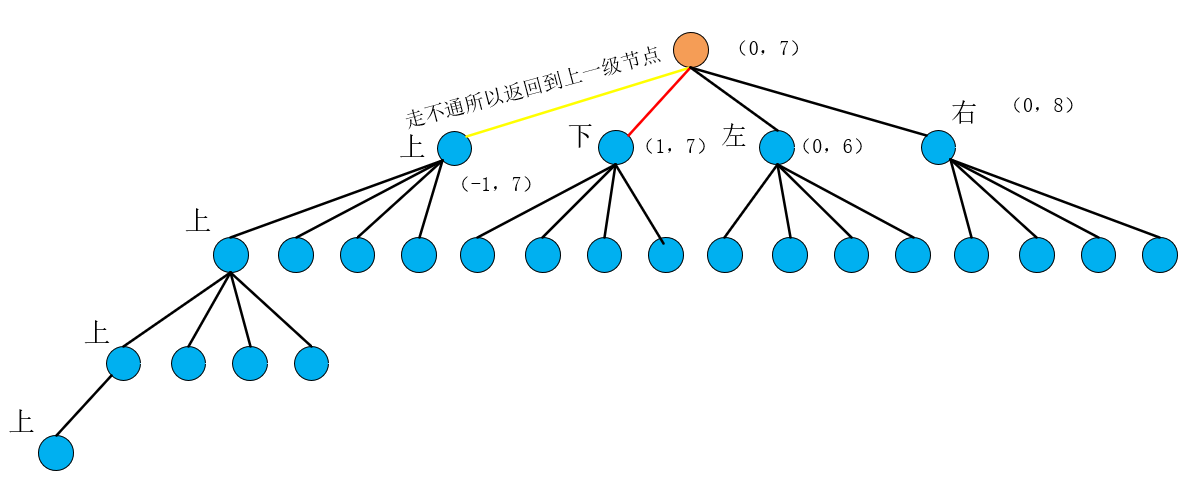
欧克,现在当前点变成了(1,7),我们发现该网格是不满足终止条件的,也就是这个点的基础上我们还可以dfs搜索,贯彻一路走到黑的原则,我们先进入到一个dfs递归也就是 上 这个方向,如图
void dfs() // 当前点为(1,7)
{
if() return; // 不满足,开始递归,运行下面的递归函数
dfs(); // 当前节点上方节点,先运行这条语句
dfs(); // 当前节点下方节点
dfs(); // 当前节点左方节点
dfs(); // 当前节点右方节点
return;
}
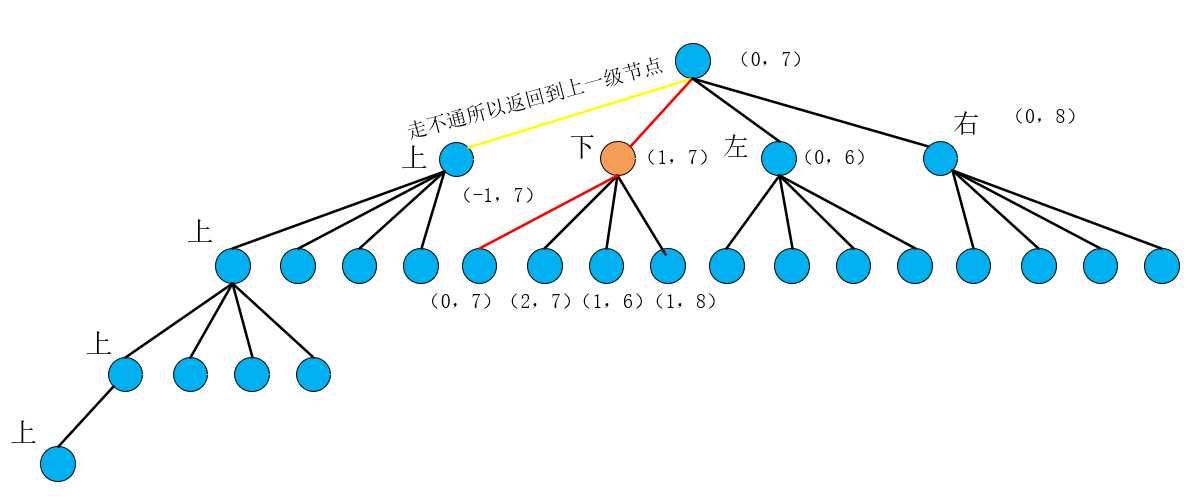
这里有一个新的问题,运行第一个dfs,我们发现居然搜到了(0,7)这个根节点,这个节点从上面的分析可知它是可以避开终止条件继续dfs的,然后在dfs就会有一条路不停的(0,7)->(1,7)->(0,7)->…,这显然是不对的,所以对于搜索过的(0,7)我们要进行一个标记,加入到visited中,防止它反复被搜索,这就是为什么dfs搜索需要visited数组,当然,这个标记的方法你可以有很多,比如说利用unorder_map,set等,当然也还有很多标记的方法,比如本题你可以直接将搜索过的点的grid值改成0,下次就不会搜索到这个点,因为我们的终止条件里面就包含了grid[当前点] == 0时这条路就走不通了
于是(0,7)这个点无法前进,我们退回到(1,7)这个点搜索第二个dfs也就是当前点下方这个点,由于这个点的grid值为0,所以也走不通,又退回到(1,7)搜索进入第三条dfs搜索左方向,也是走不通(grid为0),于是运行第四个dfs,搜索右方向节点,发现这个点没超出边界,而且gird为1,故以右节点(1,8)为当前点继续搜索
void dfs() // 当前点为(1,7)
{
if() return; // 不满足,开始递归,运行下面的递归函数
dfs(); // 当前节点上方节点,(0,7)搜索过了,走不通,运行下一个搜索语句
dfs(); // 当前节点下方节点,走不通,运行下一个dfs,
dfs(); // 当前节点左方节点,也走不通,运行最后一个dfs
dfs(); // 当前节点右方节点,这个发现能走通
return;
}
新的dfs
void dfs() // 当前点为(1,8)
{
if() return; // 不满足,开始递归,运行下面的递归函数
dfs(); // 当前节点上方节点
dfs(); // 当前节点下方节点
dfs(); // 当前节点左方节点
dfs(); // 当前节点右方节点
return;
}
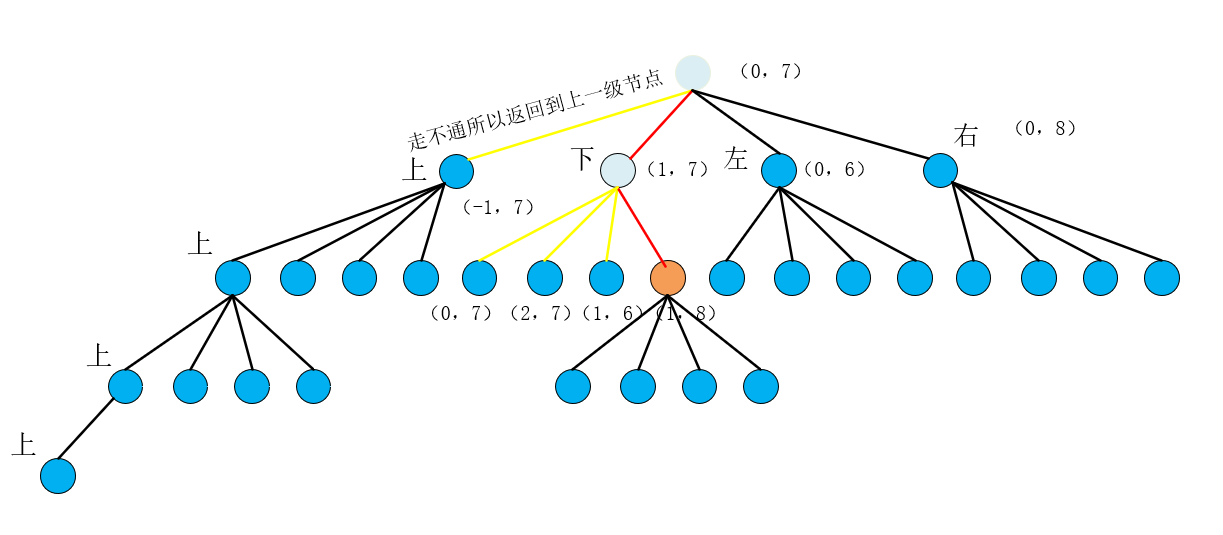
进入到新的当前点之后,我们贯彻一条路走到黑的原则,也是上下左右去dfs,如果哪个方向可行,接着那个方向继续上下左右搜索,得到下图,
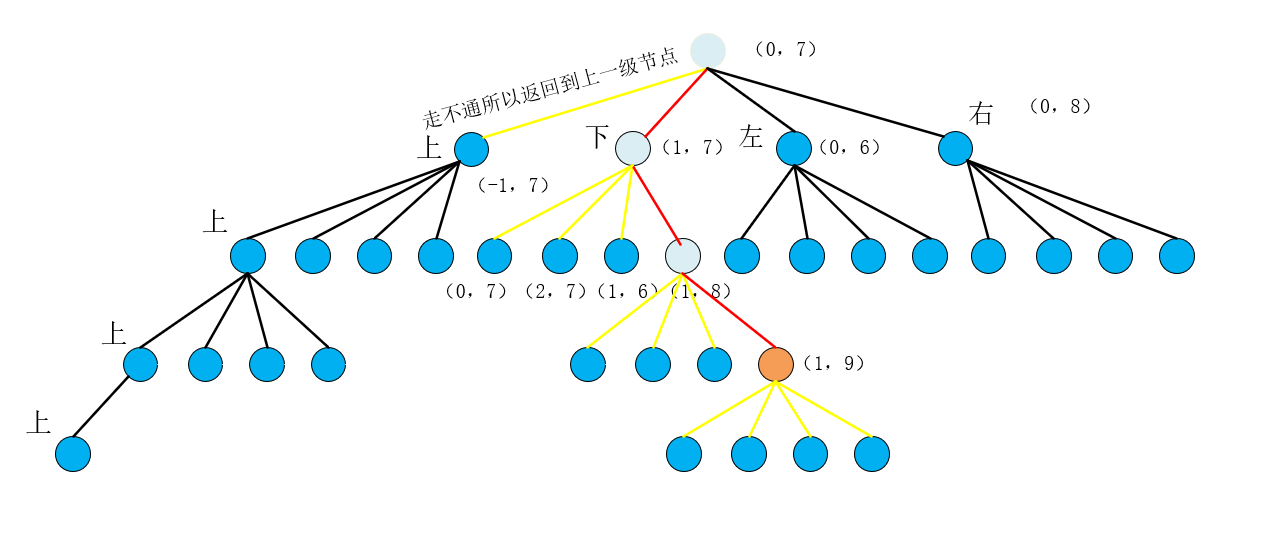
哦吼完蛋,(1,9)进入之后发现周围四个方向都走不通了,于是退到(1,8),诶(1,8)也没路走了于是退到(1,7),(1,7)说我这也没路了呀,迫于无奈只能退到(0,7),于是(0,7)开始搜索 左 这个方向
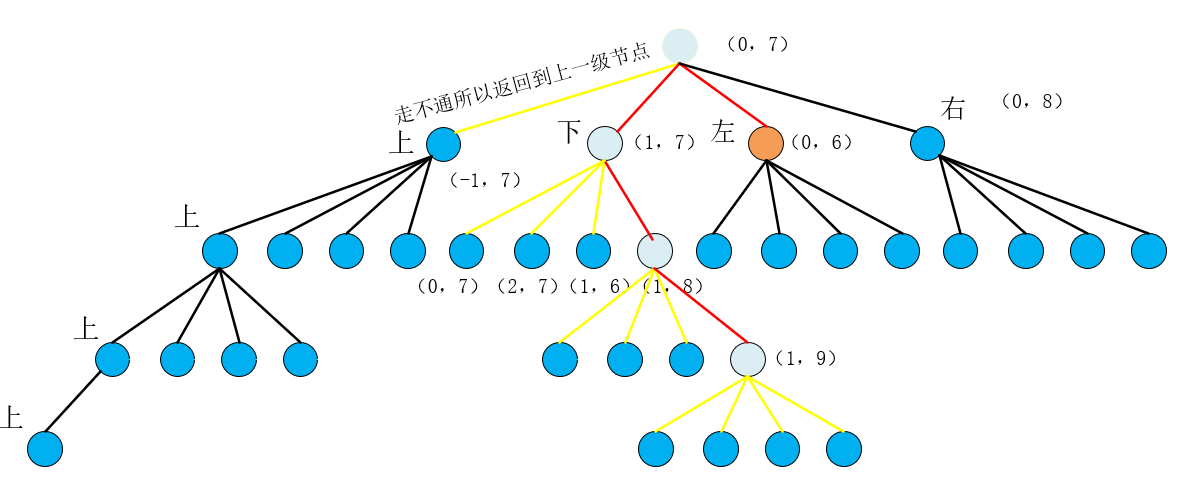
从这个回退过程中,我们可以分析,当最外层的dfs退到(0,7)连根节点都无路可走的时候,dfs过程就结束了!
递归dfs总结
!!!刚才dfs的过程分析是为了方便大家理解这个过程,但是实际上遇到问题的时候不用这么纠结递归函数运行到哪里了,纠结的话你头会爆炸的,相信我
那实际上我们遇到需要dfs解决的问题的时候,我们的难点无非就是怎么写dfs函数,写函数其实就那么几个问题上,返回值,函数的参数,函数体,当然对于递归来说终止条件也是很重要的事,因为我们可以发现递归的过程中其实每一层做的事情都是类似的,所以我们只需要知道这一层干了什么就好
// 强调写递归函数的技巧
// 一般来说dfs的参数是那些在递归的过程需要变化的参数,
// 比如说坐标x,y(这个与你树父节点与子节点的连接方式有关,
// 在矩阵路径中一般就是上下左右4个方向,或者是二叉树的左右子树)
void dfs()
{
// 写终止条件,即递归到什么时候停止,比如二叉树中子树为空,矩阵路径
// 中超出地图边界等等,当然根据问题不同这个地方也会有些变化
if ()
return;
// 当然为了防止反复遍历遍历过的节点,把遍历过的点标记
visited
// 递归与当前节点相连的要搜索的点。比如说矩阵路径中的上下左右四个点
// 又或者父节点的左右子节点
dfs();
dfs();
... // 取决当前节点每次循环递归需要遍历的子节点
return;
}
- 画出搜索树:这个步骤非常关键,有了搜索树之后写代码的过程就容易很多
- 返回值:其实看了很多博客提到这个选择的时候,都是去分析每一层干了什么,我目前也没有好的办法,我的做法一般都是先void,然后那种需要叠加的值我一般就用一个全局变量去做,我觉得这样写起来更简单。返回值这个确实不好想
- 终止条件:根据任务的要求来定,本示例就是搜到为0的点或者超出范围的点return
- 递归的对象:一般递归的是与当前节点有连接关系的点,比如说题中上下左右,二叉树的左右子树等等
- 递归函数的参数:需要在递归过程中随着递归改变的量,比如本例中的当前点的横纵坐标,因为防止被搜索过的点被反复搜索所改变的grid地图,还有一半是递归的深度
对返回值的补充:
- 要求一共有多少种方式:用ans += dfs(); return ans; 终止时返回的是 0 或 1,这里有一个种题型会要求你不考虑序列的顺序,比如说搜索树上212与122其实是不一样的,但对于要求的结果而言是一样的,所以就解决的方法就是递归函数里引入参数index,保证递归的过程有递增或递减的趋向
- 求某一条路是否存在:用bool dfs(); return dfs(); 终止时返回的是 true 或 false
- 求最长树枝:int dfs(int index, int depth),也就是加一个depth记录深度,然后每次递归都返回当前子树里面最大的深度,如return max(a, b),a b是两个子树递归返回的深度
方法二:栈
myStk.push({0,7})// 加入搜索的根节点比如说示例中的(0,7)
while (!myStk.empty())
{
// 取出mystk.top(),并pop();
if () // 如果遇到不符合条件的点就直接进入下一个操作,有点像递归中的终止条件,
// 一进递归就先判断当前点满不满足条件
continue;
visited;
// 把与当前节点周围需要dfs搜索的点加进来,比如本题的上下左右
mystk.push({});
}
// 直到栈中的点都弹空了就结束了
解释
通过一个leetcode题来解释整个dfs通过栈实现的过程。
这个题的解法是对网格中的每一个点进行dfs搜索,基于每一个点搜索其上下左右四个点,如果满足条件,岛屿面积+1,基于满足条件的点继续搜索,直到当前根节点搜索完毕返回岛屿面积,最后返回最大的岛屿面积即可,上代码;
class Solution {
public:
int dir[4][2] = {{0, 1}, {0, -1}, {11, 0}, {-1, 0}};
int maxAreaOfIsland(vector<vector<int>>& grid) {
int ans = 0;
for (int i = 0; i < grid.size(); i++)
{
for (int j = 0; j < grid[0].size(); j++)
{
int curAns = 0;
stack<pair<int, int>> myStk;
myStk.push({i, j});
while (!myStk.empty())
{
pair<int, int> curP = myStk.top();
myStk.pop();
if (curP.first < 0 || curP.second < 0 || curP.first == grid.size() || curP.second == grid[0].size() || grid[curP.first][curP.second] == 0)
continue;
curAns++;
grid[curP.first][curP.second] = 0; // 这条就是起visited作用的
for (int i = 0; i < 4; i++)
{
int curPx = curP.first + dir[i][0];
int curPy = curP.second + dir[i][1];
myStk.push({curPx, curPy});
}
}
ans = max(ans, curAns);
}
}
return ans;
}
};
首先还是解释它是怎么一步走到黑的,也是假设没有if continue这条语句,也是假设当前{i,j}是(0.7),把这个点添加进栈中,然后弹出当前点,并把当前点的右左下上(代码里面for的顺序)四个点加入到栈中,所以此时栈的情况为
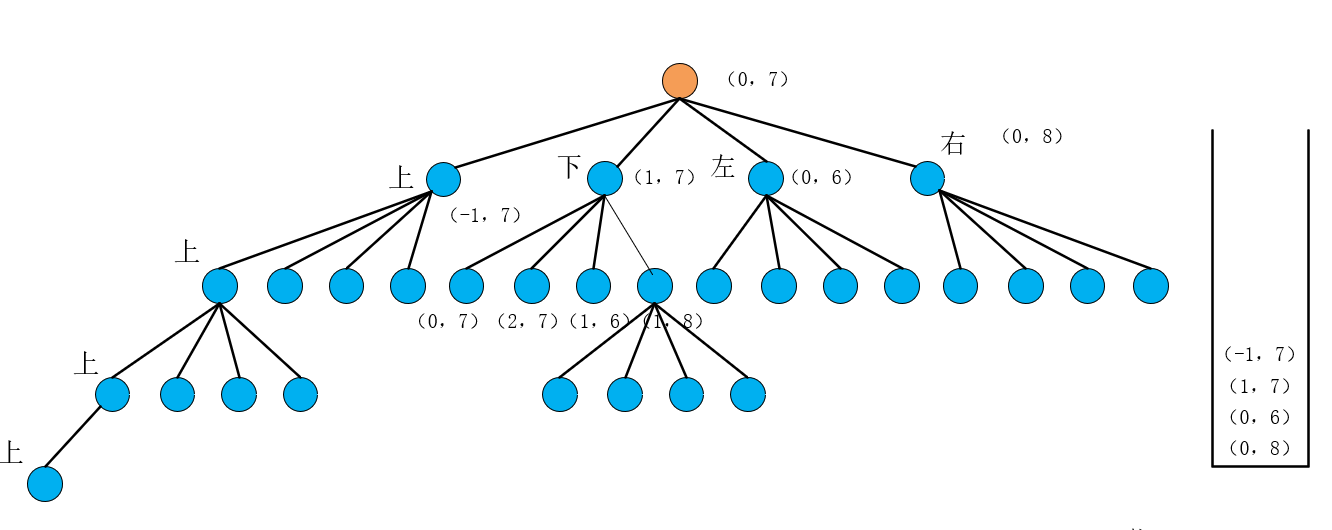
进入while的第二次循环,弹出栈顶并作为当前子树的根节点即(-1,7),此时状态为
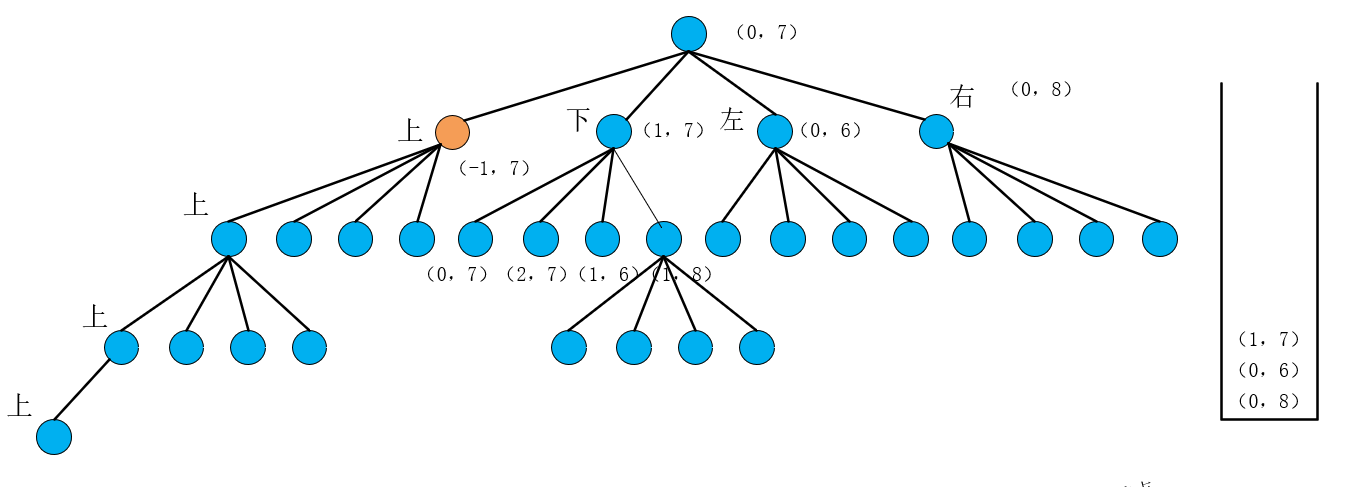
然后按照依次把当前根节点(-1,7)右左下上四个点加入栈中变成如下图状态
此时弹出栈顶元素继续搜索栈顶元素右左下上的元素,我们发现没有终止条件的话搜索会一直沿着 上 这方向的树枝搜索,这也就是栈为什么也能实现dfs算法,是因为栈每次循环中都会弹出栈顶元素,而往里压栈的顺序是固定的右左下上,因此每次弹出的元素的方向也是 上 这个方向。
现在不能让它一路走到黑,于是我们加入if continue的条件,然后简单的过一遍流程。注意这次过程,我们就不讲解visited的作用了,假设我们这个过程中标记了visited。
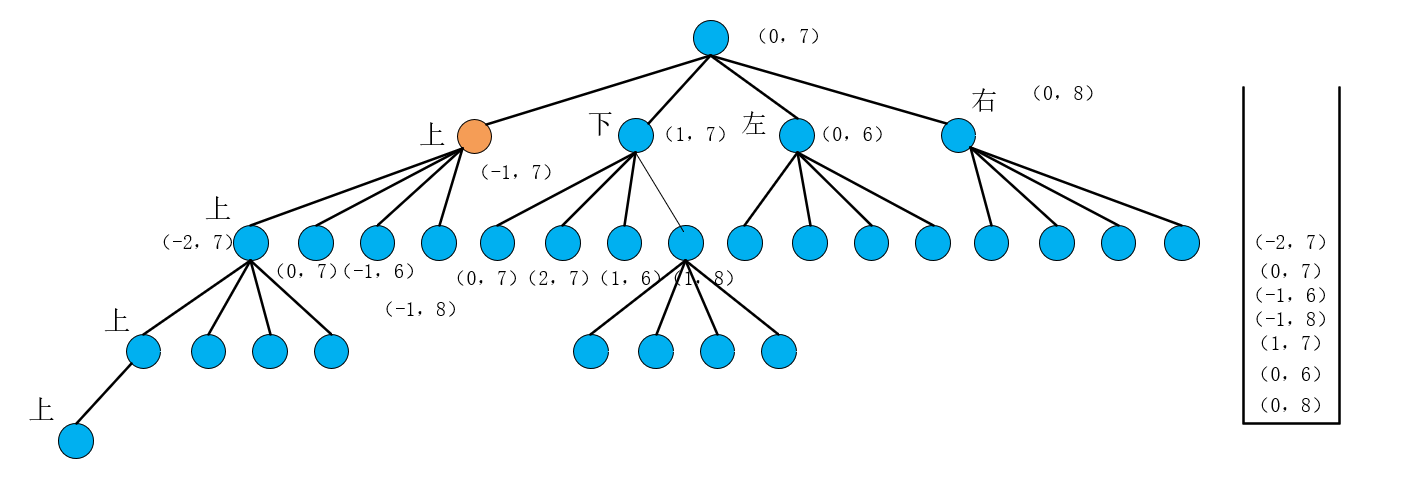
首先第一步把(0,7)加入栈顶,进入while循环,先弹出栈顶元素并把该元素作为当前点(即当前带搜索的子树的根节点),然后按照当前点右左下上的店的顺序压栈得到下图:
第二次while中,首先弹出栈顶元素(-1.7)作为当前点(即当前带搜索的子树的根节点),判断if条件我们发现该点超出地图范围于是,continue,进入第三次while,首先弹出栈顶元素(1.7)作为当前点(即当前带搜索的子树的根节点),这里跟用递归写的方法有点区别,递归的过程我们发现遇到走不通的路,我们是先返回到上一层节点即(0,7)然后执行下一个dfs递归语句也就是递归(1,7),所以在递归中体现了一种回溯的思想,而用栈实现的dfs是直接进入下一次循环弹出栈顶并没有回到上一层节点,这也就是为什么回溯算法一般都是用递归实现的
// 回溯
void dfs() // 当前点为(0,7)
{
if ()
return;
visited
dfs(); // 进入到这个递归里面发现(-1,7)走不通,于是在这个函数体里面返回出来执行下一条dfs,这里
// 就回溯到了以(0,7)为根节点的函数中
dfs();
dfs();
dfs();
return;
}
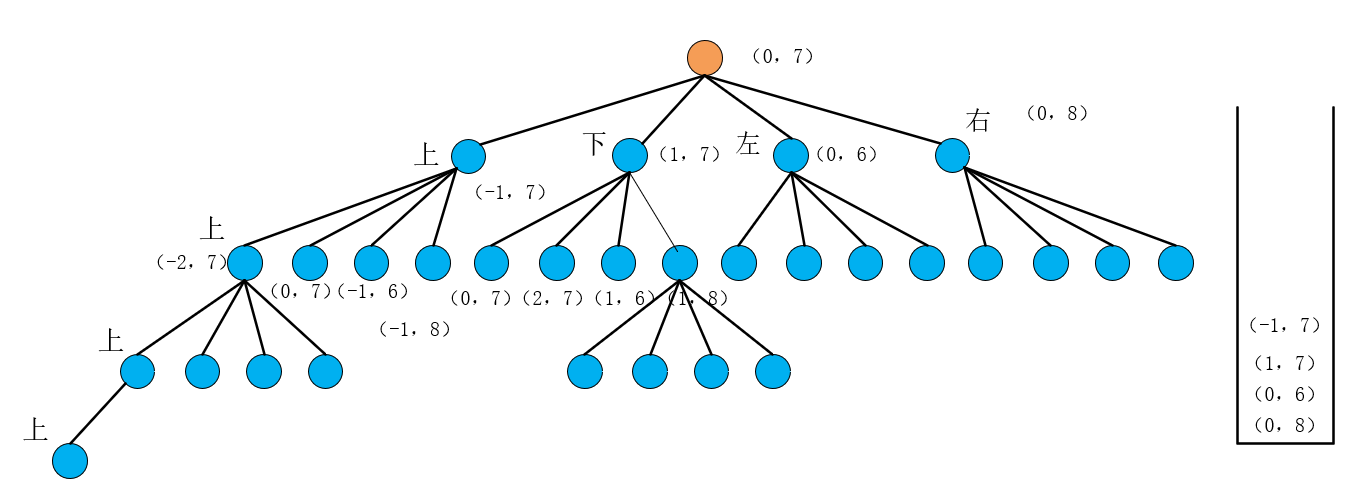
回到主题,(1,7)不满足if的判断条件即这个点我们是需要用的,于是我们把(1,7)右左下上的点都加入到栈中,得到的状态如下图所示
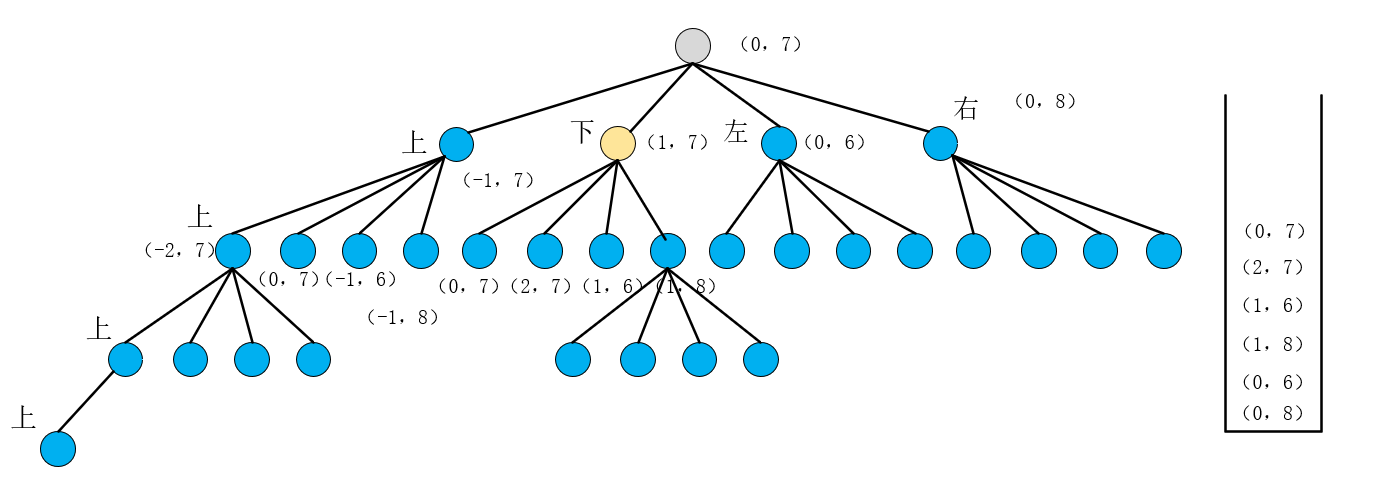
然后依次弹出(0,7)【是因为搜过】, (2,7)【grid=0】, (1,6) 【grid=0】发现这三个点都符合if条件即我们不用这些点即这些方向都不通,直到弹出(1,8)时发现(1,8)是不满足if的判断条件即这个点我们是需要用的,所以基于这个点又把其右左下上的点压到栈中,如图所示:
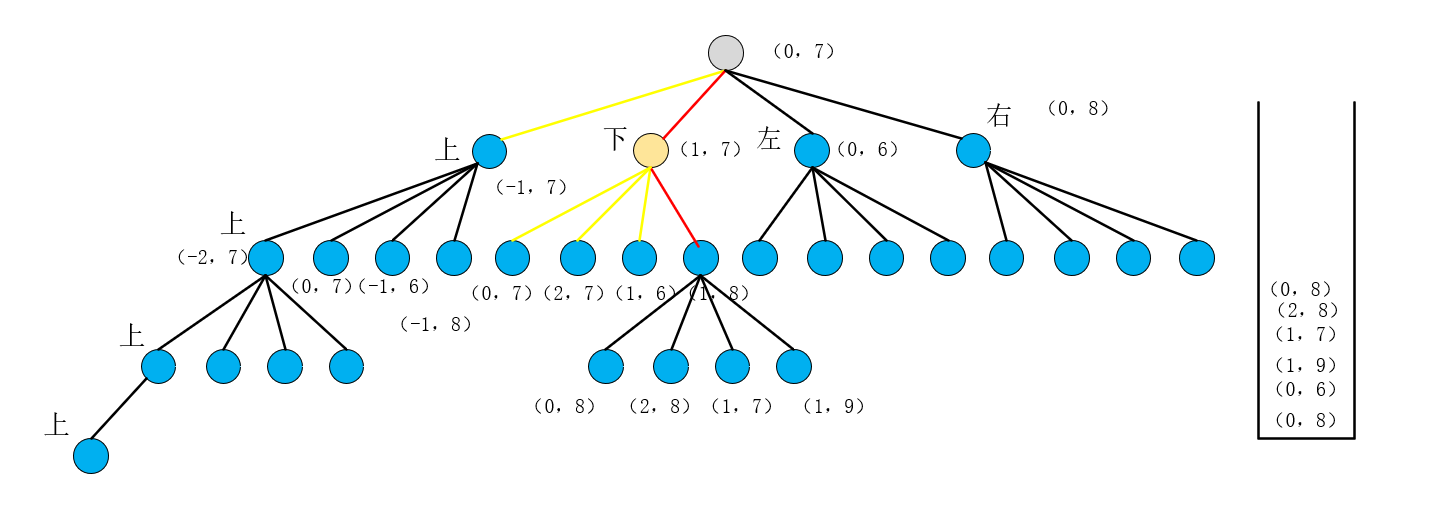
然后依次弹出(0,8)【grid=0】, (2,8)【grid=0】, (1,7) 【搜过】发现这三个点都符合if条件即我们不用这些点即这些方向都不通,直到弹出(1,8)时发现(1,9)是不满足if的判断条件即这个点我们是需要用的,所以基于这个点又把其右左下上的点压到栈中,如图所示:
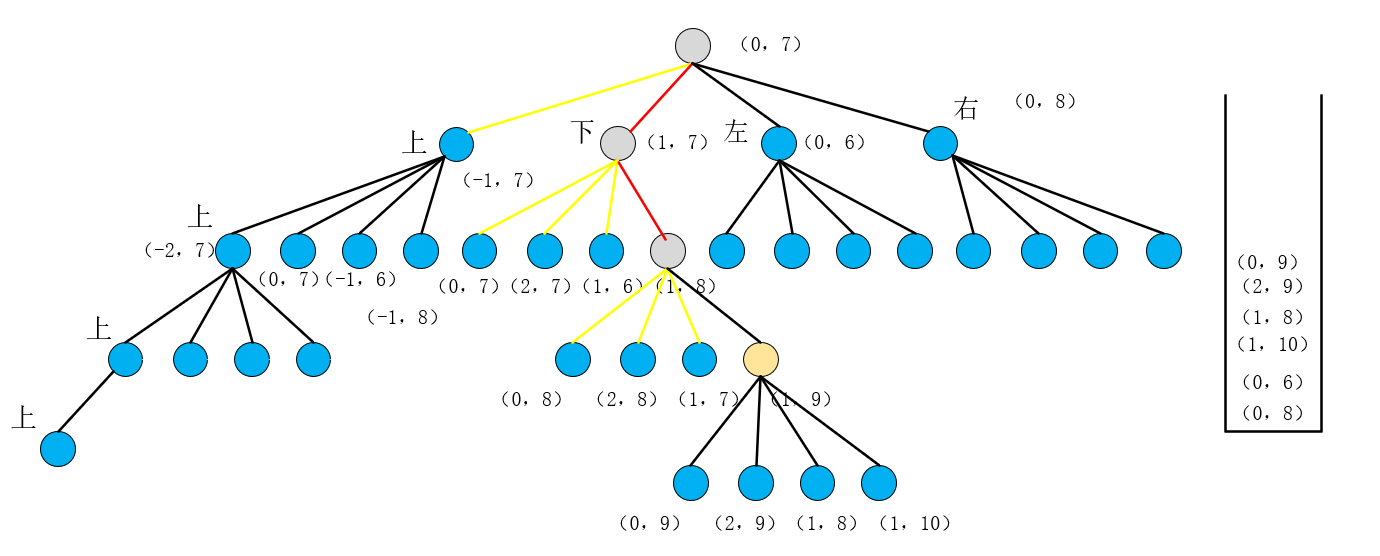
进入新的四次循环弹出的四个点(不加以赘述)都符合if条件即我们不用这些点即这些方向都不通,即
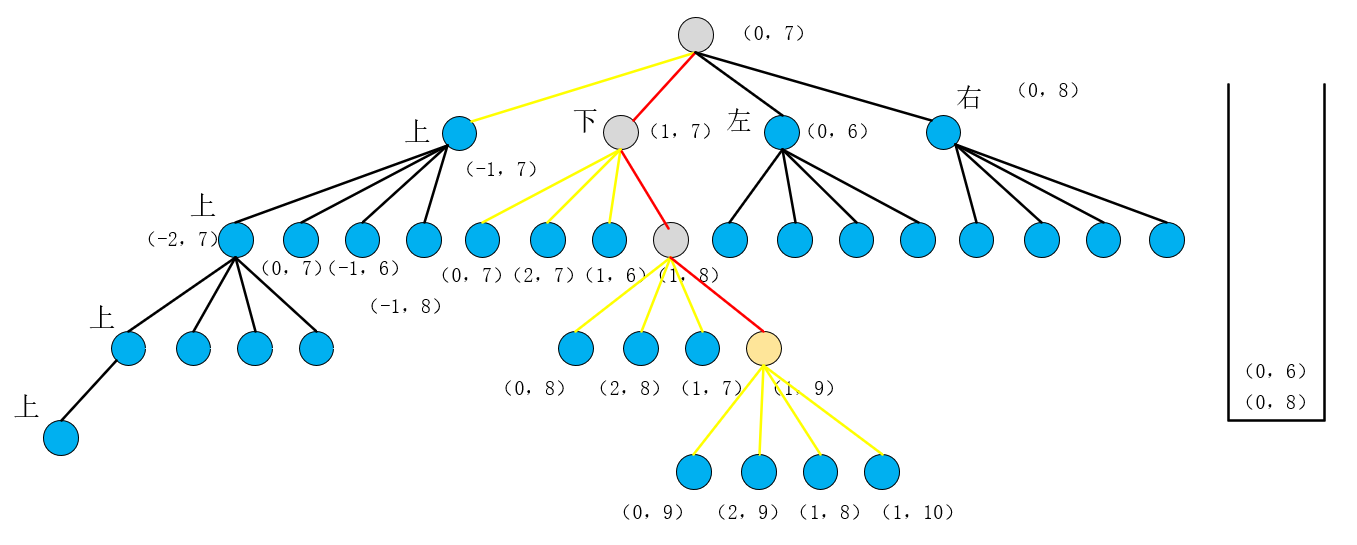
此时这条路算是全黑了,所以再弹出新的点的时候就是从(0,6)开始了,注意这个地方也是没有递归一层一层往上回溯的过程,是直接弹出(0,6)就进入到了新的征程
栈dfs总结
用栈实现的dfs算法逻辑上来说比递归更清晰,因为没有函数来来回回的调用和回溯,你也不用考虑函数运行到哪一步了,其实通过上面的分析可知,写栈的dfs过程跟递归的很类似,当前点需要递归哪些方向的点就类似于栈顶元素弹出后作为当前点所需要压栈的当前点周围的点,if continue 也类似与递归中的if return 这决定了哪些方向是不可行的也就是不能一直无休止的压栈,visited的作用也类似,但是两种方法也有区别,递归在返回的过程中有往上层节点一步一步回溯的思想,但是栈是没有的,所以后面需要使用回溯算法的时候会发现一般都是使用递归的方式
最后
以上就是幸福电源最近收集整理的关于DFS算法原理及其具体流程,包你看一遍就能理解写在前面DFS算法所解决的问题所需要的数据结构代码结构及解释的全部内容,更多相关DFS算法原理及其具体流程,包你看一遍就能理解写在前面DFS算法所解决内容请搜索靠谱客的其他文章。
![[滑模控制器浅述] (1) 二阶系统的简单滑模控制器设计[滑模控制器浅述] (1) 二阶系统的简单滑模控制器设计](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)







发表评论 取消回复