一、一般使用机器学习算法遵循的步骤
摘自《机器学习实战》,感觉思路比较清晰
1.收集数据。
可以使用很多种方法收集样本数据,例如制作网络爬虫从网站上爬取数据,从RSS反馈或者API中得到信息,设备发送过来的实测数据(风速,血糖等)。2.准备输入数据。
得到数据之后,还必须确保数据格式符合要求,使用标准数据格式后可以融合算法和数据源,方便匹配操作。此外还需要为机器学习准备特定的数据格式,如某些算法要求特征值使用特定的格式,一些算法要求目标变量和特征值是字符串类型,而另一些算法可能要求是整数类型。3,分析输入数据。
此步骤主要是人工分析以前得到的数据。为了确保前两步有效,最简单的方法是用文本编辑器打开数据文件,查看得到的数据是否为空值,此外还可以进一步浏览数据,分析是否可以识别出模式:数据中是否存在明显的异常值,如某些数据点与数据集中的其它值明显存在差异。通过一维,二维三维图形展示数据也是不错的方法。
这一步主要作用是确保数据集中没有垃圾数据,如果产品化系统中使用机器学习算法并且算法可以处理系统产生的数据格式,或者我们信任数据来源,可以直接跳过这一步。4,训练算法。
机器学习算法到这一步才是真正的开始学习。根据算法不同,第四步和第五步是机器学习算法的核心。我们将前两步得到的格式化数据输入到算法,从中抽取知识或信息。这里得到的知识需要存储为计算机可以处理的格式,方便后续步骤使用。如果使用非监督学习算法,由于不存在目标变量值,因此也不需要训练算法,所有与算法相关的内容都集中在第五步
5,测试算法。
这一步将实际使用第四步机器学习得到的知识信息。为了评估算法,必须测试算法工作的效果。对于监督学习,必须已知用于评估算法的目标变量值,对于非监督学习,也必须用到其它的评测手段来检验算法的成功率。无论那种情形,如果不满意算法的输出结果,则可以回到第四步,改正并加以测试。问题常常会跟数据的收集与整理有关,这时就要跳到第一步重新开始。6,使用算法。
将机器学习算法转换为应用程序,执行实际任务,以检验上述步骤是否可以在实际环境中正常工作,此时如果遇到新的数据问题,同样需要重复执行上述的步骤。
二、机器学习算法训练预测模型的常规流程
以XGBoost算法为例,主要操作步骤如下:
- 读取集群目录数据
- 批量重新命名字段名称
- 统计各列缺失值个数
- 对缺失值进行填充(数值型变量采用中位数、分类变量采用众数)
- 过滤掉异常记录
- 过滤掉缺失值过多的列
- 对分类型变量进行编码,将label列转换为0/1类型
- 批量对分类变量先进行StringIndexer操作,再批量进行OneHotEncoderEstimator操作
- 使用VectorAssembler拼接字段
- 创建XGBoost
- 设置pipeline模式: val pipeline = new Pipeline().setStages(indexers ++ encoders ++ Array(vectorAssembler, xgb))
- 创建evaluator,采用ROC
- 创建XGBoost paramater grid
- 构造cv
- 切分trainingData、testData,设定seed便于数据复现
- 训练模型: val xgbModel = cv.fit(trainingData)
- 测试模型: val results = xgbModel.transform(testData)
- 保存BestModel: val bestPipelineModel = xgbModel.bestModel.asInstanceOf[PipelineModel]
- 创建一个测试数据集不含label字段,但是需要包含对应的user_id
- 读取创建的数据集进行预测
注:在进行特征工程之前需要单独封装一个函数,用于数据预处理,也便于后续进行模型预测,主要是特征工程暂时无法操作的数据预处理步骤。
三、项目实战(一)
机器学习一个完整的项目过程
1.准备数据
训练集和测试集的数据来源于很多地方,比如:数据库,csv文件或者其他存储数据的方式,为了操作的简便性,可以写一些小的脚本来下载并解析这些数据。在本文中,我们先写一个脚本来演示:
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = 'https://raw.githubusercontent.com/ageron/handson-ml/master/'
HOUSING_PATH = 'chapter02/datasets/housing'
HOUSING_URL = DOWNLOAD_ROOT + 'datasets/housing' + '/housing.tgz'
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
print(housing_url)
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, 'housing.tgz')
urllib.request.urlretrieve(housing_url, tgz_path)
print(tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
执行上边的代码后,数据就已经下载到本地了,接下来在使用pandas加载数据
mport pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
print(housing_path)
csv_path = os.path.join(housing_path, "housing.csv")
print(csv_path)
return pd.read_csv(csv_path)
2.数据预览
使用pandas解析后的数据是DataFrames格式,我们可以调用变量的head()方法,获取默认的前5条数据
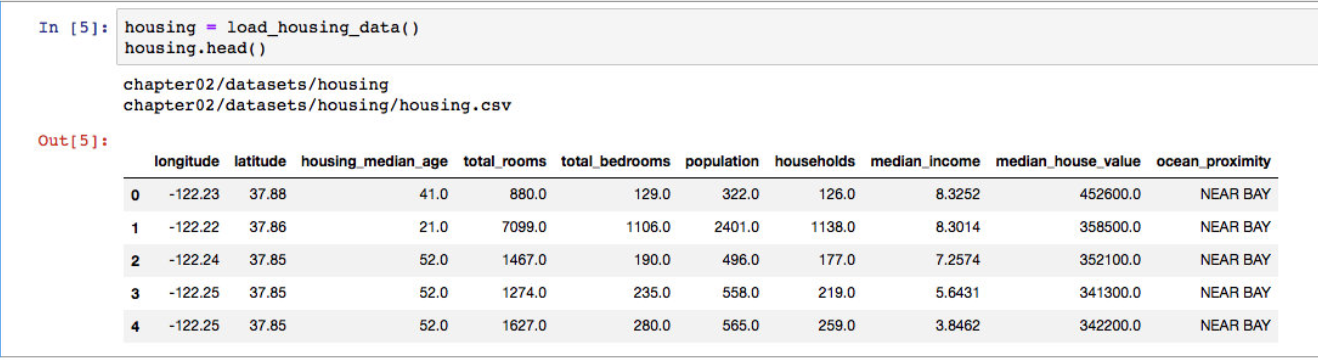
可以看出,总共有10条属性,在这5条中,显示数据都很完整,没有发现数值有空的情况,使用info(),我们可以对整个数据的信息进行预览:
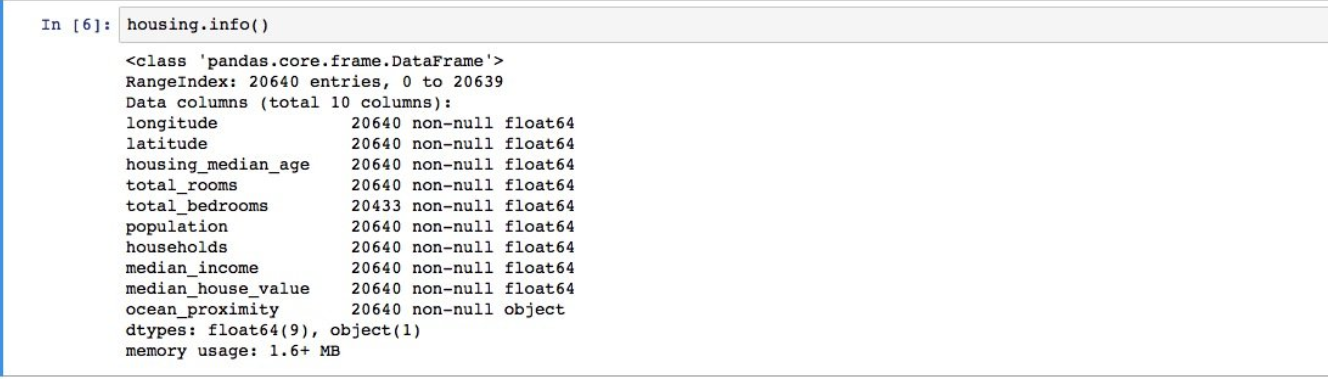
一共有20640条数据,这点数据对于ML来说是很小的,只有total_bedrooms的属性下存在数据为空的情况。
通过观察数据,我们发现,除了ocean_proximity之外的属性的值都是数值类型,数值类型很容易在ML算法中实现,再次观察上边5条数据的ocean_proximity值,可以推断出ocean_proximity应该存在几种类型,跟枚举有点像,使用value_counts()方法可以查看每个值得数量:
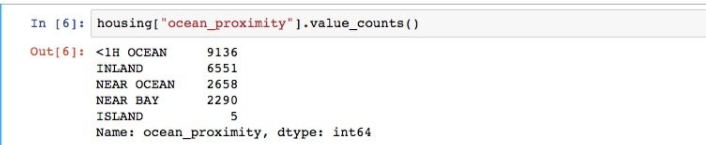
除此之外,使用describe()可以查看每一行更多的信息:
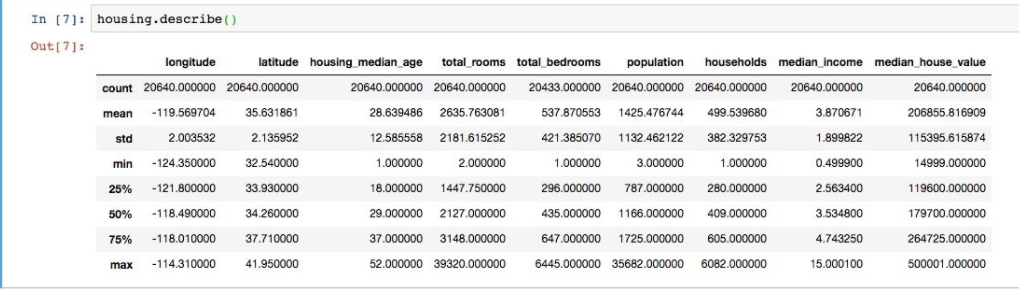
名词解释:
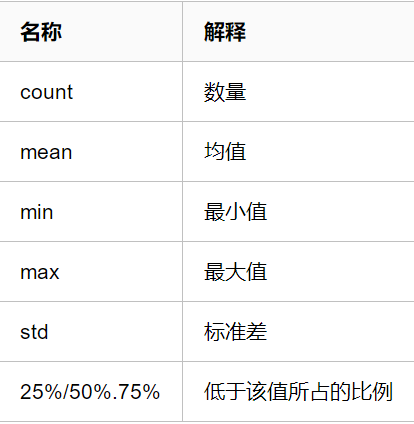
如果想查看每个属性更加详细的信息,我们可以使用hist()方法,查看每个属性的矩形图:
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20, 15))
plt.show()
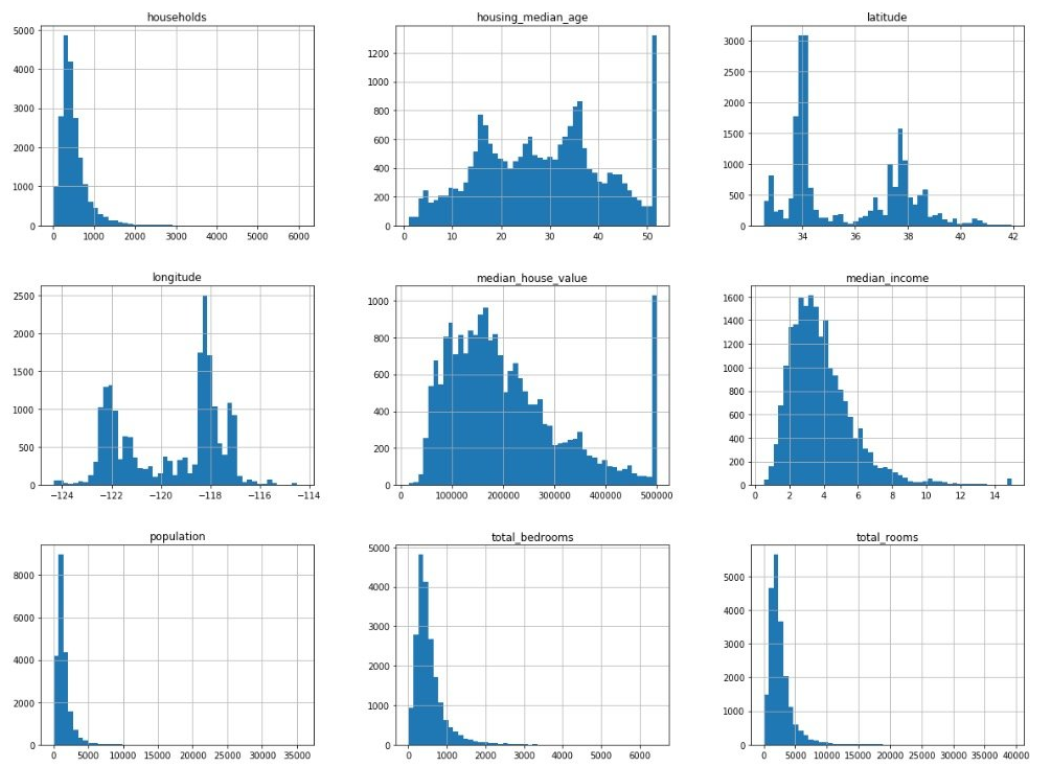
通过观察矩形图可以很容易的看出值的分布情况,矩形图的x轴表示值,y轴表示数量。针对我们这份数据,我们发现了如下信息:
(1) 对于median_income来说,它的值并不是表示的是真实的收入,而是通过计算的结果,取值范围在0.5~15之间,明白数值是如何计算的,也很重要。
(2)数据受限的情况,housing_median_age和median_house_value存在明显的值得限制,在他们的矩形图的右边有一条很长的条,这说明存在限制的情况,这会对ML算法产生一定的影响,比如,在使用算法预测的时候,是否需要也添加该限制?如果答案是不限制,需要对当前受限制的数据做进一步的处理:
a. 收集受限制的数据的真实值
b.删除这些受限制的数据
(3) 这些属性的取值范围有很大的区别,这个会在下文中解决这个问题
(4)图形中有存在尾重的现象,这个也会在下文中解决
创建test集
在创建test set的过程中, 能够进一步让我们了解数据,这对选择机器学习算法很有帮助。最简单的就是随机收取大约20%的数据作为test set。
使用随机函数的缺点是,每次运行程序得到的结果都不一样,因此,为处理这个问题,我们需要给每一行一个唯一的identifier,然后对identifier进行hash化,取它的最后一个字节值小于或等于51(20%)就可以了。
在原有的数据中,并不存在这样的identifier,因此需要调用**reset_index()函数,**为每行添加索引,作为identifier。
import hashlib
import numpy as np
def test_set_check(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash))
return data.loc[~in_test_set], data.loc[in_test_set]
# 给housing添加index
housing_with_id = housing.reset_index()
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
print(len(train_set), 'train +', len(test_set), "test")
# 也可以使用这种方式来创建id
# housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
# train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
在上边的代码中,使用index作为identifier有一个缺点,需要把新的数据拼接到数据整体的最后边,同时不能删除中间的数据,解决的方法是,使用其他属性的组合来计算identifier。
当然sklearn也提供了生成test set的方法
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
随机抽样比较适用于数据量大的样本,如果样本不够大,就会引入很大的抽样偏差。对于当前的数据,我们采取分层抽样。当你询问专家那个属性最重要的时候,他回答说median_income最重要,我们就要考虑基于median_income进行分层抽样。
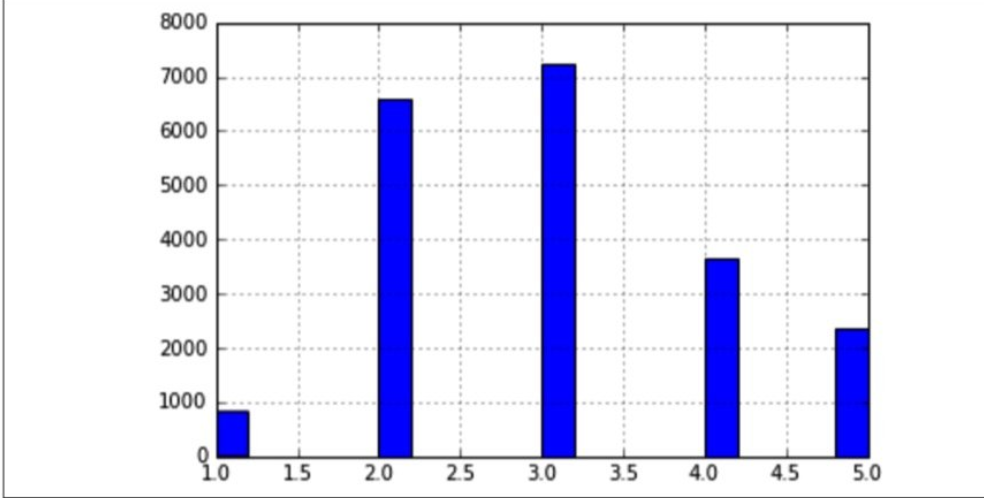
观察上图,可以发现,median_income的值主要集中在几个层次上,由于层次不够多,这也侧面说明了不太适合使用随机抽样。
我们为数据新增一个属性,用于标记每行数据属于哪个层次。对于大于5.0的,都归到5.0中。
# 随机抽样会在某些情况下存在偏差,这时候可以考虑分层抽样,每层的实例个数不能太少,分层不能太多
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
print(housing.head(10))
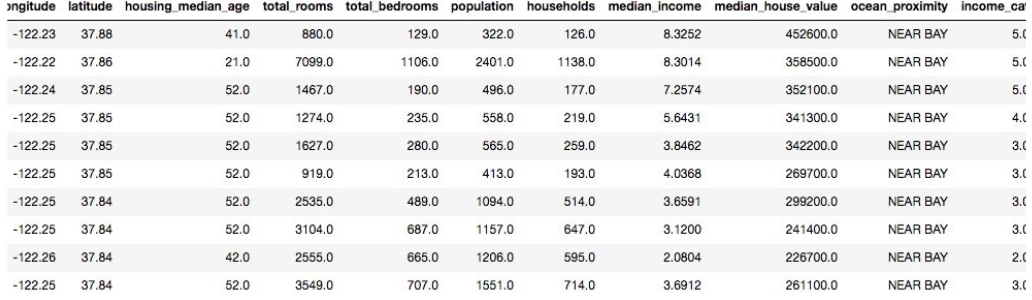
接下来就需要根据income_cat,使用sklearn对数据进行分层抽样。
# 使用sklearn的tratifiedShuffleSplit类进行分层抽样
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
print(housing["income_cat"].value_counts() / len(housing))
# 得到训练集和测试集后删除income_cat
for s in (strat_train_set, strat_test_set):
s.drop(["income_cat"], axis=1, inplace=True)
print(strat_train_set.head(10))
上边的代码在抽样成功后,删除了income_cat属性,结果如下:

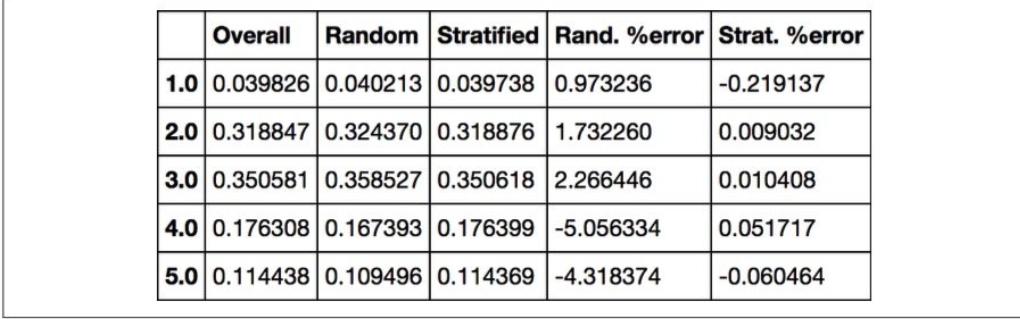
如果我们计算test set和原数据的误差,能够得到下边这张表格,可以看出,分层抽样的错误明显小于随机抽样。
发现数据的更多信息
要想找到数据中隐藏的信息,就要使用可视化的手段,对于我们的housing数据来说,它包含经纬度信息,基于地理位置应该是一个好的切入口。
housing = strat_train_set.copy()
housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(20, 12))
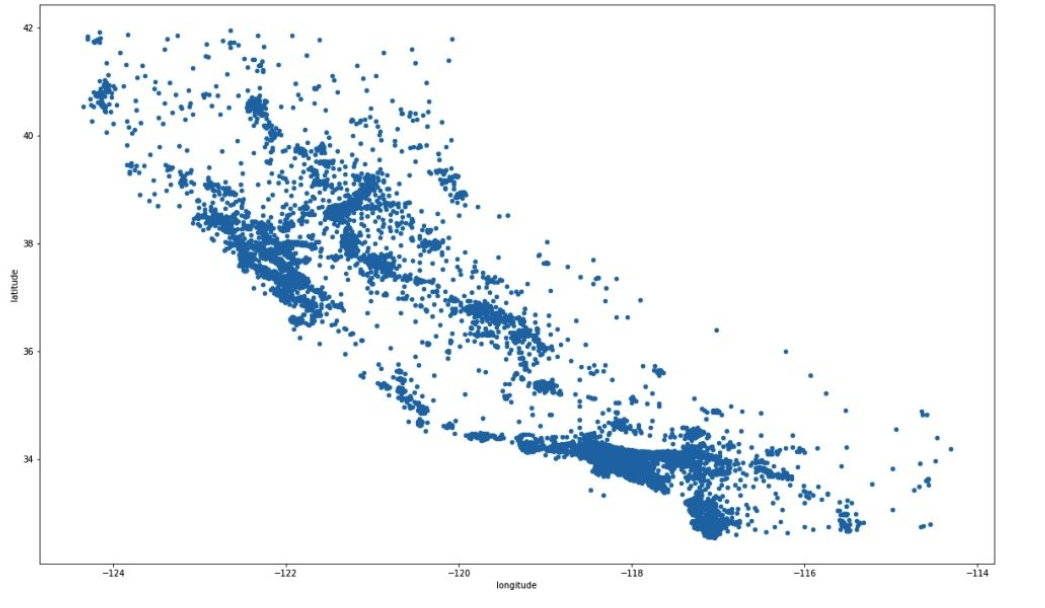
这张图如果绘制成这样的,很难发现有什么特点,我们调整点的透明度试一试。
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1, figsize=(20, 12))
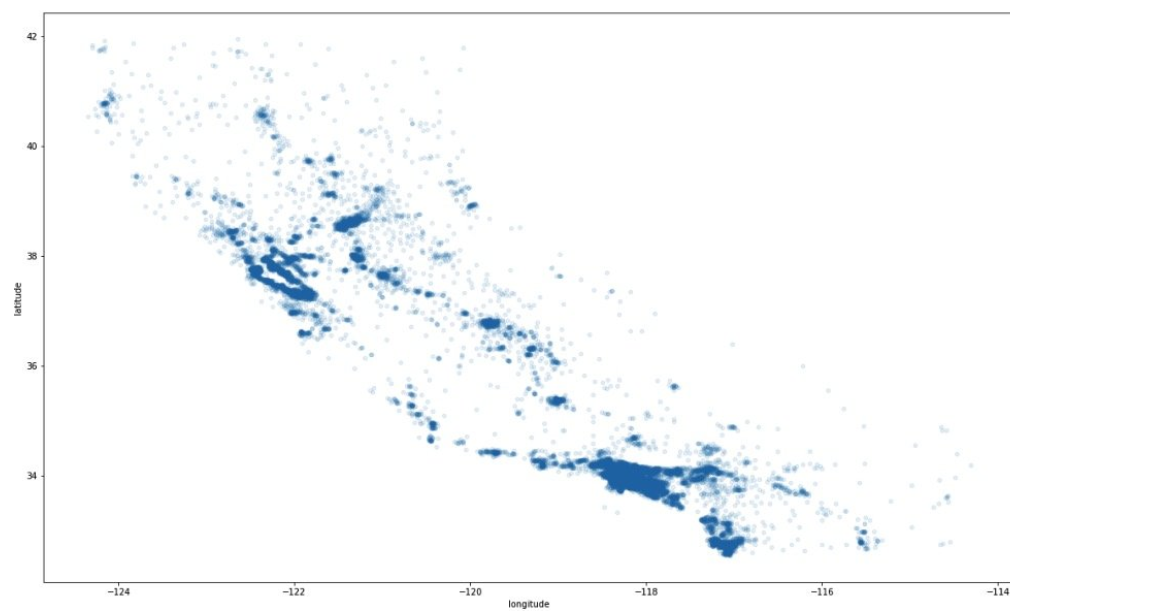
这样我们的头脑自动分析后,很容易得出数据浓度高的地方存在特殊性,那么这些是否与价格相关?更进一步,我们用点的半径表示相应点的人口规模,用颜色表示价格,然后绘图:
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True, figsize=(20, 12))
plt.legend()

从这张图,可以观察到,价格跟位置和人口密度有很大的关系,和ocean_proximity同样有关系,因此,从直觉上,我们可以考虑使用聚类算法。
相关性
由于当前的数据集比较小,我们可以直接用corr()计算标准相关系数:
# 标准相关系数, 查看feature的关联度
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
最后
以上就是动人中心最近收集整理的关于机器学习算法几种常见步骤(附项目案例)的全部内容,更多相关机器学习算法几种常见步骤(附项目案例)内容请搜索靠谱客的其他文章。

![[滑模控制器浅述] (1) 二阶系统的简单滑模控制器设计[滑模控制器浅述] (1) 二阶系统的简单滑模控制器设计](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)






发表评论 取消回复