使用正则表达式抓取图片信息,一定要了解正则表达的意义。推荐看这位老师的网站(Python正则表达式详解 (超详细,看完必会!)_全 洛的博客-CSDN博客_python正则表达式),学习正则表达式的大部分使用方法了。正则表达式抓取图片信息,最主要是抓取到的网站数据怎么匹配数据值,难点也是怎么用正则方法去匹配数据值。将匹配的值转化为本地存储。
下面介绍几个正则表达式的作业,爬取某浪网站的图片,完全用于技术分享,不用于商业发展。
作业一:
# -*- conding:utf-8 -*-
import requests
import re
#需求:爬取某体育中图片信息
if __name__ == "__main__":
#检查图片地址
url = 'https://n.sinaimg.cn/sports/transform/180/w640h340/20221129/622c-86c9b926b93c22862eee0fc6416d4fde.jpg'
#伪装浏览器
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 '}
#content返回的是二进制形式的图片数据
#text(字符串),content(二进制)json(对象)
image_data = requests.get(url=url).content
with open('./qutu.jpg','wb') as fp:
fp.write(image_data)
print('get图片结束!')编译结果:

作业二:
# -*- conding:utf-8 -*-
import requests
import re
import os
#需求:爬取某体育中图片信息
if __name__ == "__main__":
#判断系统是否存在文件夹,没有文件夹自行创建。
if not os.path.exists('./gitPicture'):
os.mkdir('./gitPicture')
#检查图片地址
url = 'http://sports.sina.com.cn/'
#伪装浏览器
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 '}
#text(字符串),content(二进制)json(对象)
picture_data = requests.get(url=url,headers=headers).text
#使用聚焦爬虫将页面中所有的新浪图片进行解析/提取,使用正则表达式匹配字符。 .是匹配任意字符,#匹配前面字符出现多次,?匹配前面字符出现一次或者零次
ex = 'height: 236px;">.*?<img src="(.*?)" alt.*? '
#使用正则表达式函数匹配,用re.S进行换行搜索
image_src_list = re.findall(ex,picture_data,re.S)
#使用for循环从列表中抽取每个图片数据,进行命名保存。
for src in image_src_list:
img = src
image_data = requests.get(url=img,headers=headers).content
image_name = img.split('/')[-1]
image_Path = './gitPicture/'+image_name
#本地化存储到对应文件夹中
with open(image_Path,'wb') as fp:
fp.write(image_data)
print(image_name,'下载成功!!!')编译结果:
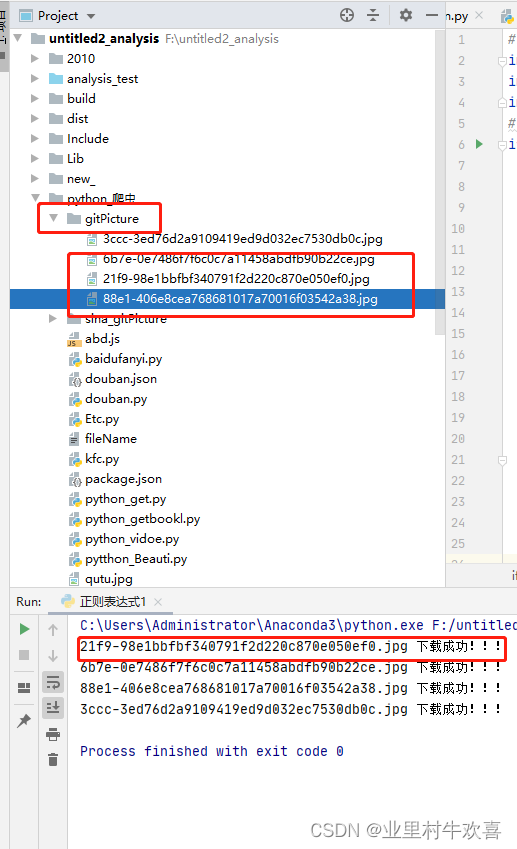
作业三:
# -*- conding:utf-8 -*-
import requests
import re
import os
#需求:爬取某体育网站中图片信息
if __name__ == "__main__":
# 伪装浏览器标识符
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 '}
#判断系统是否存在文件夹,没有文件夹自行创建。
if not os.path.exists('./sina_gitPicture'):
os.mkdir('./sina_gitPicture')
#检查图片地址,%d是变量值,
url = 'http://slide.sports.sina.com.cn/g/slide_2_730_282986.html#p=%d'
#p=1,2,3,4,5,6,7---到12对应不同的值,不同的值对应不同的图片信息。
# pic_list=[]
#取一个for循环,旋转每个值抓取不同图片值,但是p=2的url里面已经包涵所有高清值的图片了。
for pageNum in range(2,3):
new_url = format(url%pageNum)
picture_data = requests.get(url=new_url, headers=headers).text
#使用正则表达式定义到爬取下来的文本图片数据的位置,采用字符拼接的方式,利用前面http开头相同的数据值,抓取后面不同值得数据值,后续在用字符串拼接的方式将url拼接回来了
ex = '<dd>.*?http://n.sinaimg.cn/sports/2_img/dfic/a7a65bdb/(.*?)</dd>.*?'
# 使用正则表达式函数匹配,用re.S进行逐行搜索
image_src = re.findall(ex, picture_data, re.S)
#利用for循环在列表中抽取正则表达式抓下来的数据值。
for src in image_src:
#用字符串拼接的方式,组成合格的URL取值。
new_src='http://n.sinaimg.cn/sports/2_img/dfic/a7a65bdb/'+src
#get的方法抓取图片的数据。
image_data = requests.get(url=new_src, headers=headers).content
#利用分隔符split将/后面的数据信息抓取出来命名。
image_name = new_src.split('/')[-1]
image_Path = './sina_gitPicture/' + image_name
# 本地化存储到对应文件夹中
with open(image_Path, 'wb') as fp:
fp.write(image_data)
print(image_name, '下载成功!!!')
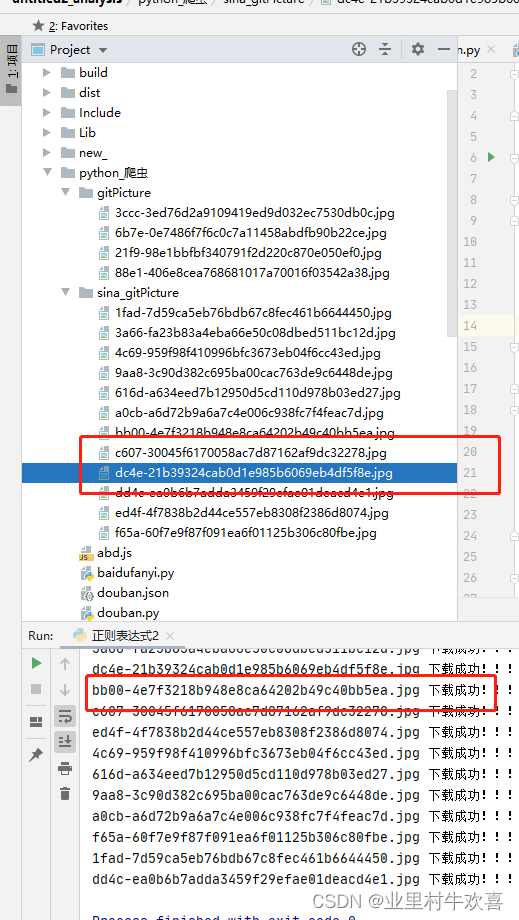
总结:本帖子只用于技术研究和探讨了,不用于商业利益的使用。爬虫是利用浏览器的属性和载荷值进行爬取图片资料,最重要是正则表达式的精准定位到图片的jpg位置,然后用正则表达式进行抓取数据,将抓取的数据加入列表中,在进行For循环本地存储。
技术参考网站:
4.正则解析案例02_哔哩哔哩_bilibili
Python 中使用 join() 函数把列表拼接成一个字符串_宁萌Julie的博客-CSDN博客_python列表拼接成字符串
最后
以上就是复杂洋葱最近收集整理的关于Python使用正则表达式爬取网站图片信息的全部内容,更多相关Python使用正则表达式爬取网站图片信息内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复