一、概念分析
很多人好奇机器学习是什么,个人理解机器学习就是人工智能的前身,有许多机器学习的模型塑造才能有更符合实际的人工智能技术应用。机器学习的基础就是深度学习,让计算机深度学习人的思维方式,形成人的思维模式,做人期望完成的事情。比如人脸识别,就是用大量的面部识别建模形成的模型,对比人的五官进行核验,通过才能进行操作。

人工智能两个核心方法就是机器学习、深度学习。
机器学习:使用算法来解析数据,从中学习,然后对真实世界的事件做出决策和预测。例:垃圾邮件检测。
深度学习: 一种实现机器学习的方法。模仿神经网络建立模型,进行深度数据分析。比如人脸识别,自动驾驶。
机器学习的三大类别:监督式学习(垃圾邮件检测、房价预测)、非监督式学习(数据聚类、新闻邮件推送)、强化学习(强化学习是一种通过交互的目标导向学习方法,旨在找到连续时间序列的最优策略例如AlphaGo)。
二、开发环境搭建
2.1配置环境
python语言、scikit-learn 模块、Anaconda、jupyter nootbook、panda模块 numpy模块、机器学习环境的部署
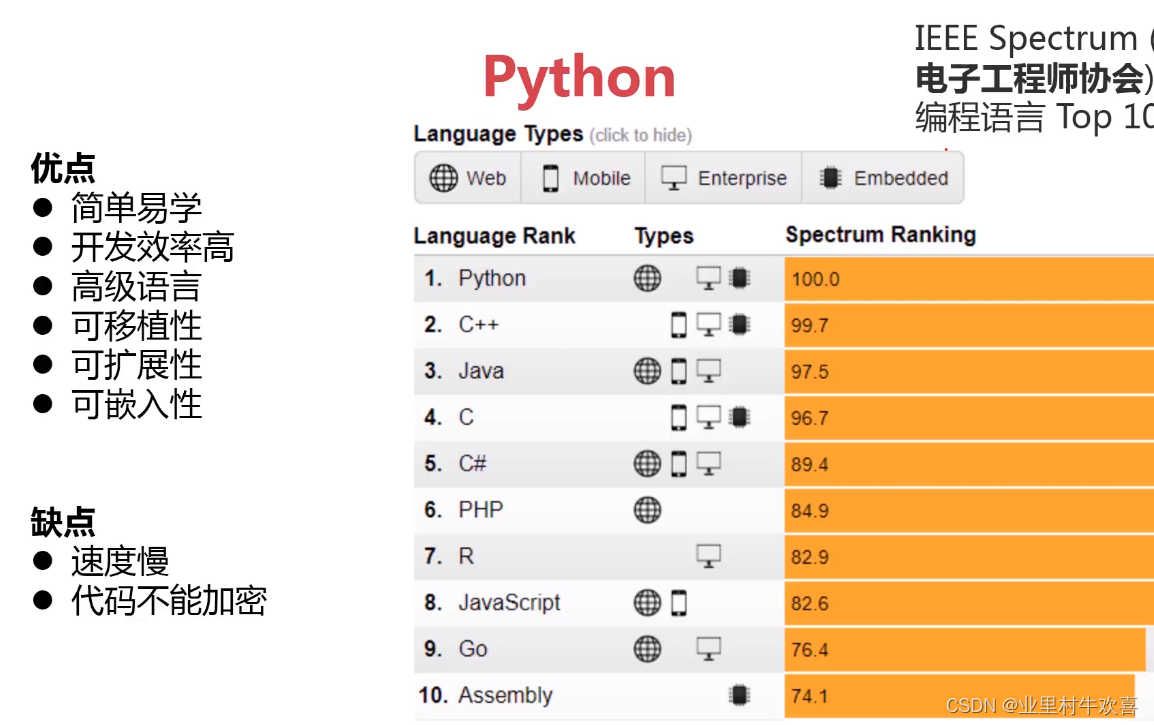
通过一张简图了解一下python语言的优缺点,任何语言都有自己的优势,也有自己的劣势。python语言是对面对象语言,和C语言其他语言不同,面向对象开发好比建设一个车子,需要车架、发动机、变数器、底盘、轮胎还有其他座椅操控台,pyhon语言开发可以设置每个零部件,组装一台汽车就可以调用一个零部件使用。每个零部件就是相当于python的一个模块,可以随意调用
scikit-learn 模块
简单安装、易导入,经常使用与深度学习,用于机器学习的案例使用。使用方法:可以在Anacanda中安装,或者使用官方API如下:
scikit-learn: machine learning in Python — scikit-learn 1.1.1 documentation https://scikit-learn.org/stable/
https://scikit-learn.org/stable/
pandas模块
用于读取office中word、excel、ppt文件的模块,可以在Anaconda安装库中安装,或者用Anaconda终端器中安装(这不细讲了)

pandas - Python Data Analysis Library
numpy模块
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPyhttp://www.numpy.org/
jupyter nootbook工具包
下载Anaconda就可以正常使用了,在Anaconda(Anaconda可以看我主页)工具界面就可以选择。

登录后的效果:
2.2安装步骤:
python环境可以不安装,直接在Anaconda中安装时在选择python环境勾选就行,安装完毕以后可以新建一个开发环境,相当于一个项目库里面进行调试。
scikit-learn、pandas、numpy模块包可以在Anaconda界面安装或者用指令安装都可以。
下面是指令安装界面:(老师我安装过了,结果呈现已经安装)
2.3实战环节:
1、测试几个模块包有没有安装成功
新建一个python3的模板

使用import 指令导入,就知道有没有安装成功。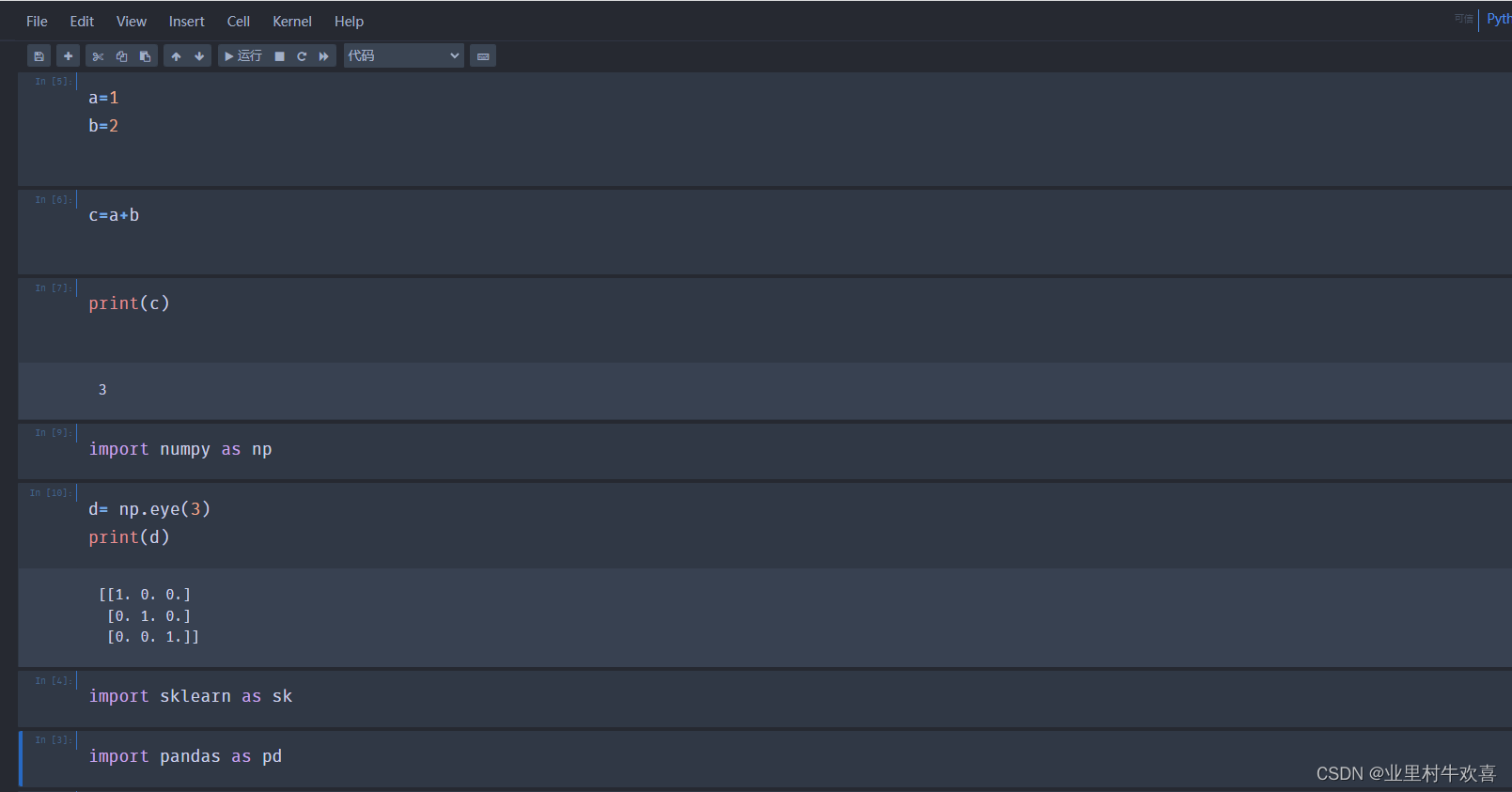
三、开发实战环节:
3.1数据预处理操作
理论解析:

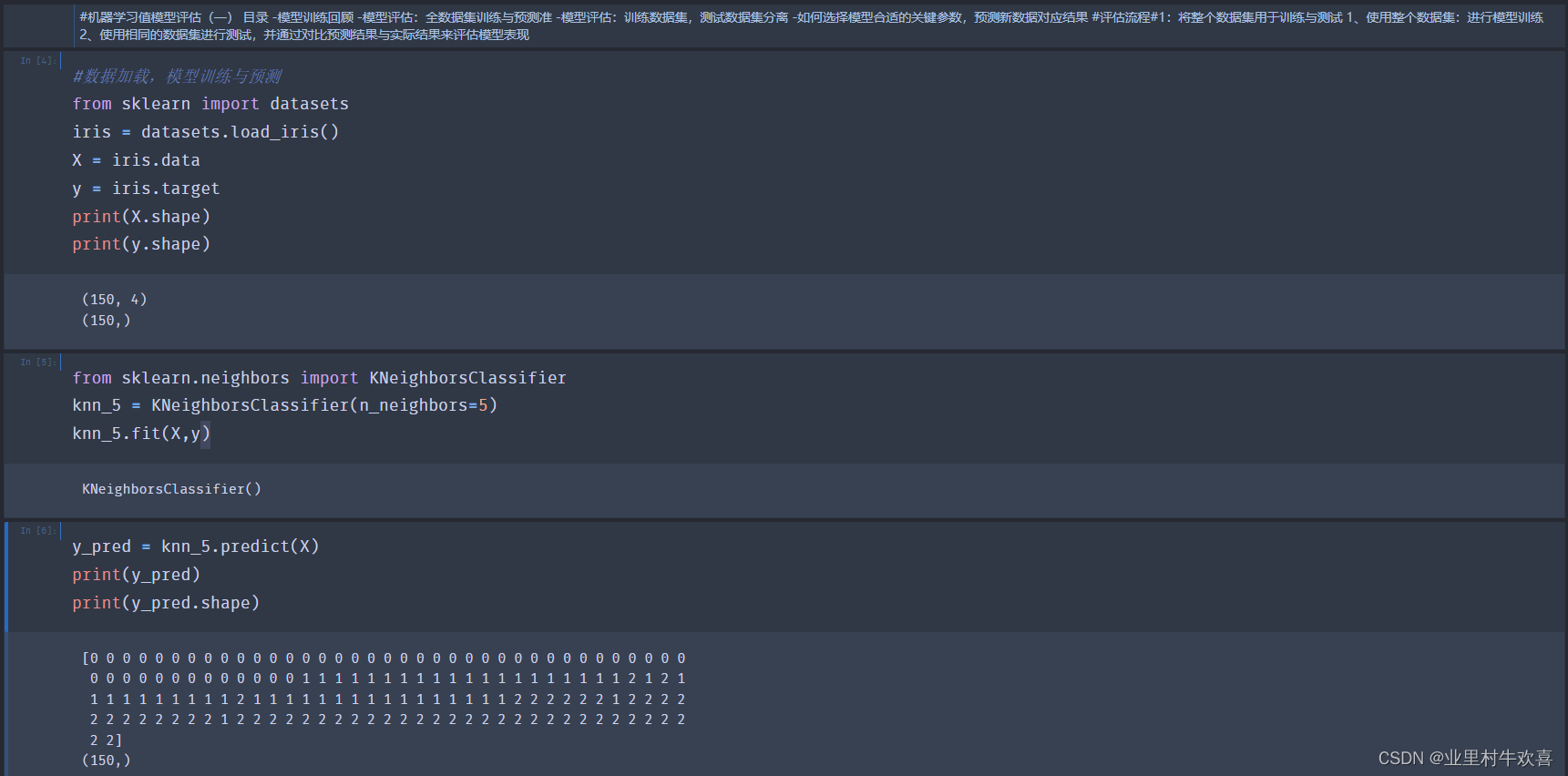
机器学习实现之模型训练 Iris数据加载
#通过sklearn自带数据包加载iris数据
from sklearn import datasets
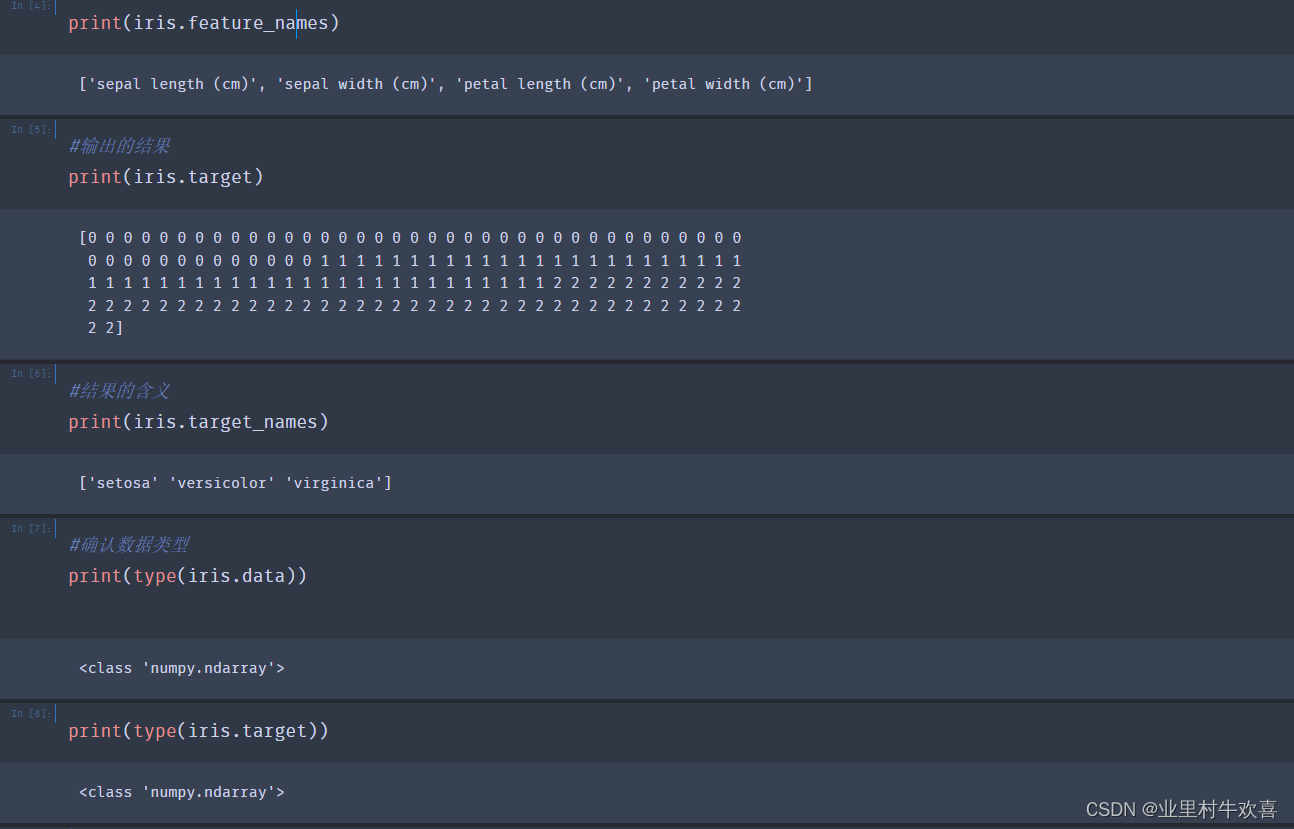
iris = datasets.load_iris()
#数据样本和结果样本分别赋值在“x”,"y"
X = iris.data
y = iris.target
注意数据的维度要相同,要不然后期数据建模会因为索引不同而影响结果。
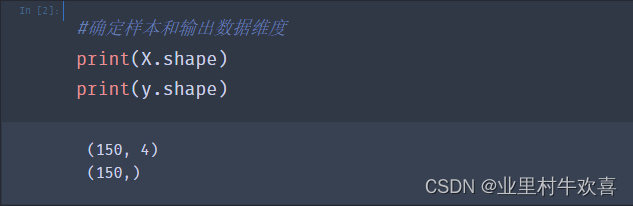
#确定样本和输出数据维度
print(X.shape)
print(y.shape)
#使用scikit-learn建模四步骤
1、调用需要使用的模型类 2、模型初始化(创建一个模型实例) 3、模型训练 4、模型预测
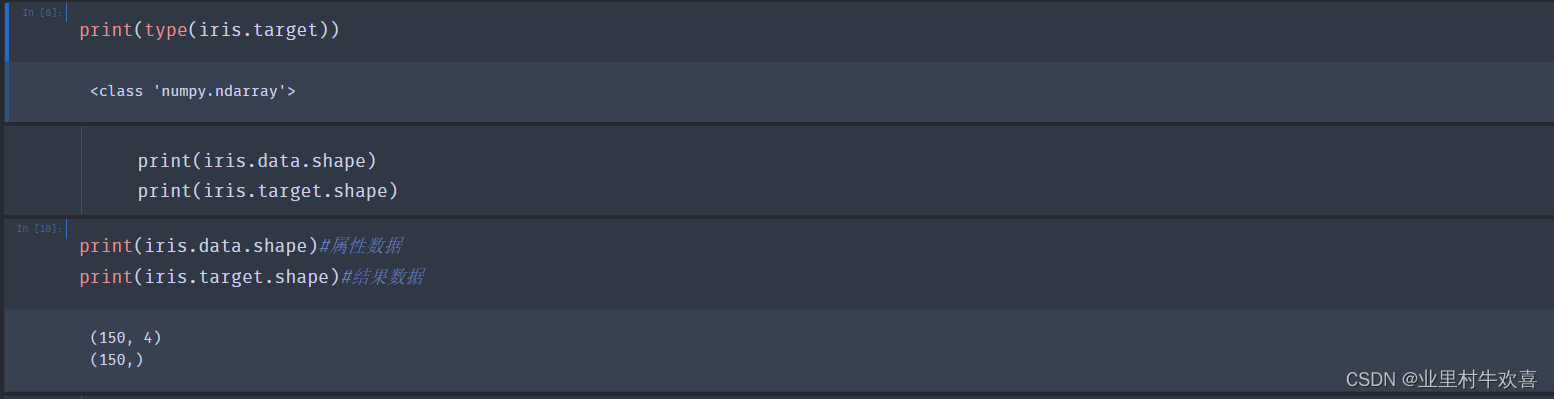
-分类问题是对应结果为类别(非连续性)的监督式学习问题 -每个预测的数值即是结果数据(或称为:目标、输出、标签) 使用scikit-learn进行数据处理的四个关键点 1、区分属性数据与结果数据 2、属性数据与结果数据是可量化的 3、运算过程中,属性数据与结果数据的类型都是numpy数组 4、属性数据和结果数据的维度是相同的。
#X输入数据赋值,Y输出数据赋值。
x=iris.data
y=iris.target
print('x值:',x)
print('y值:',y) 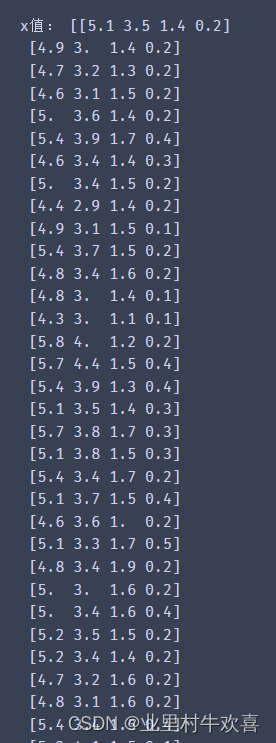

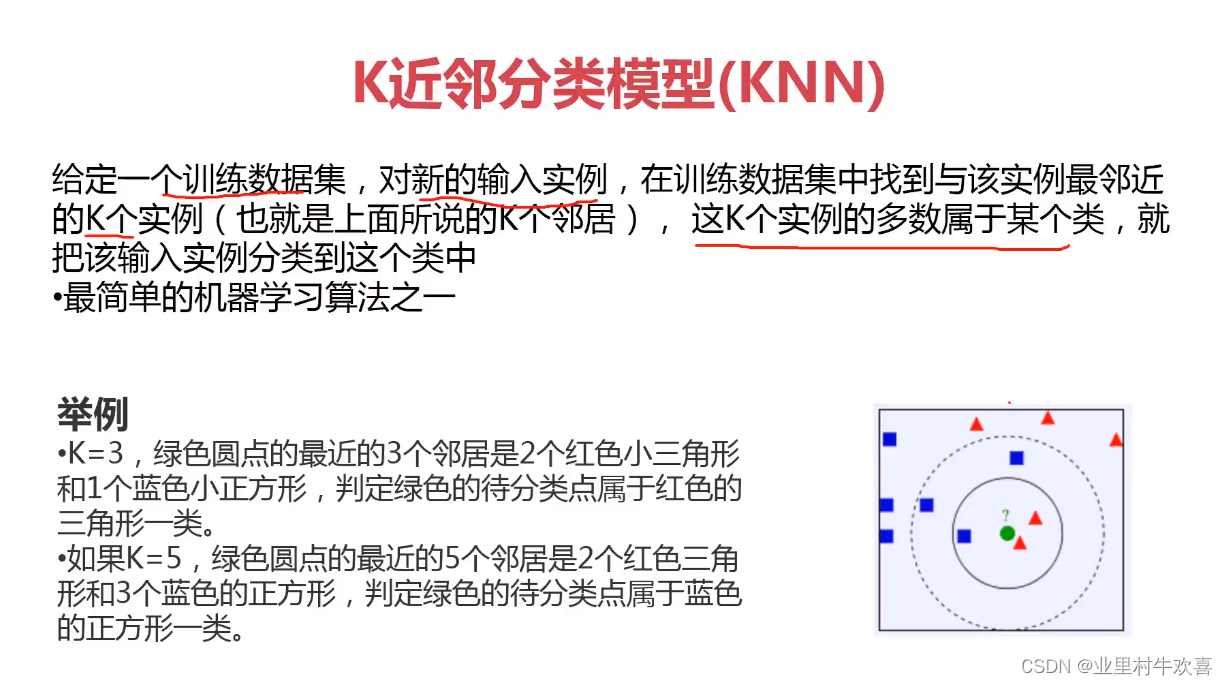
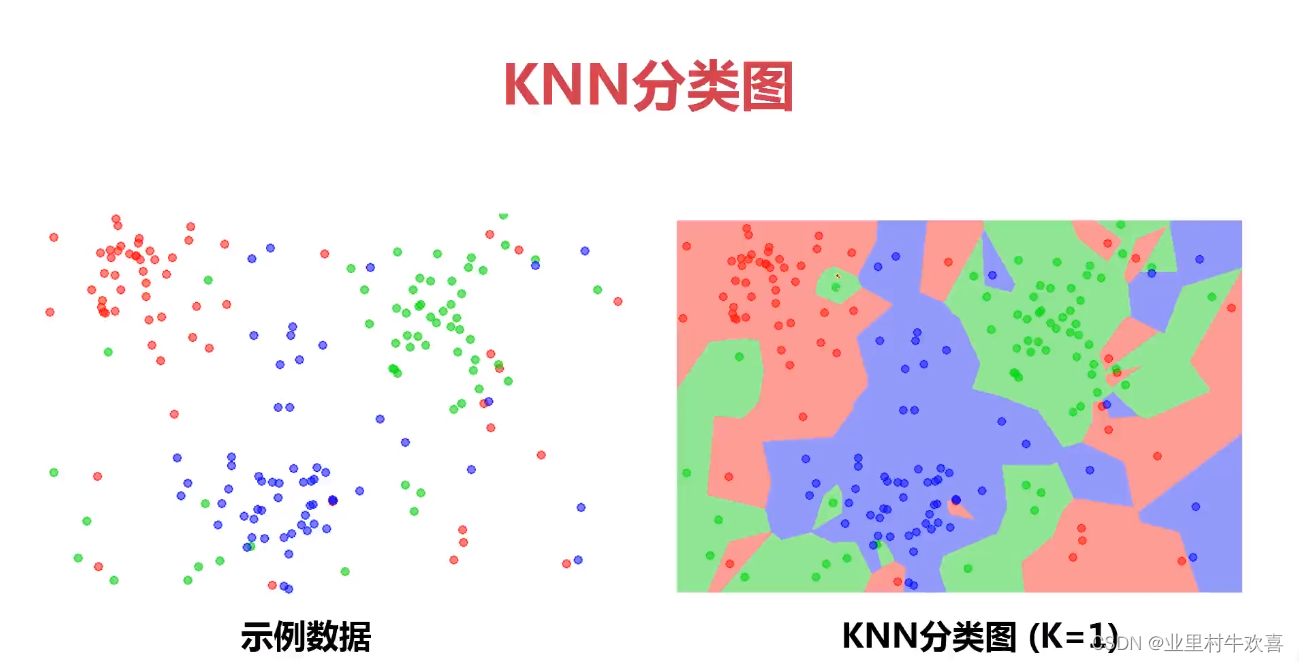
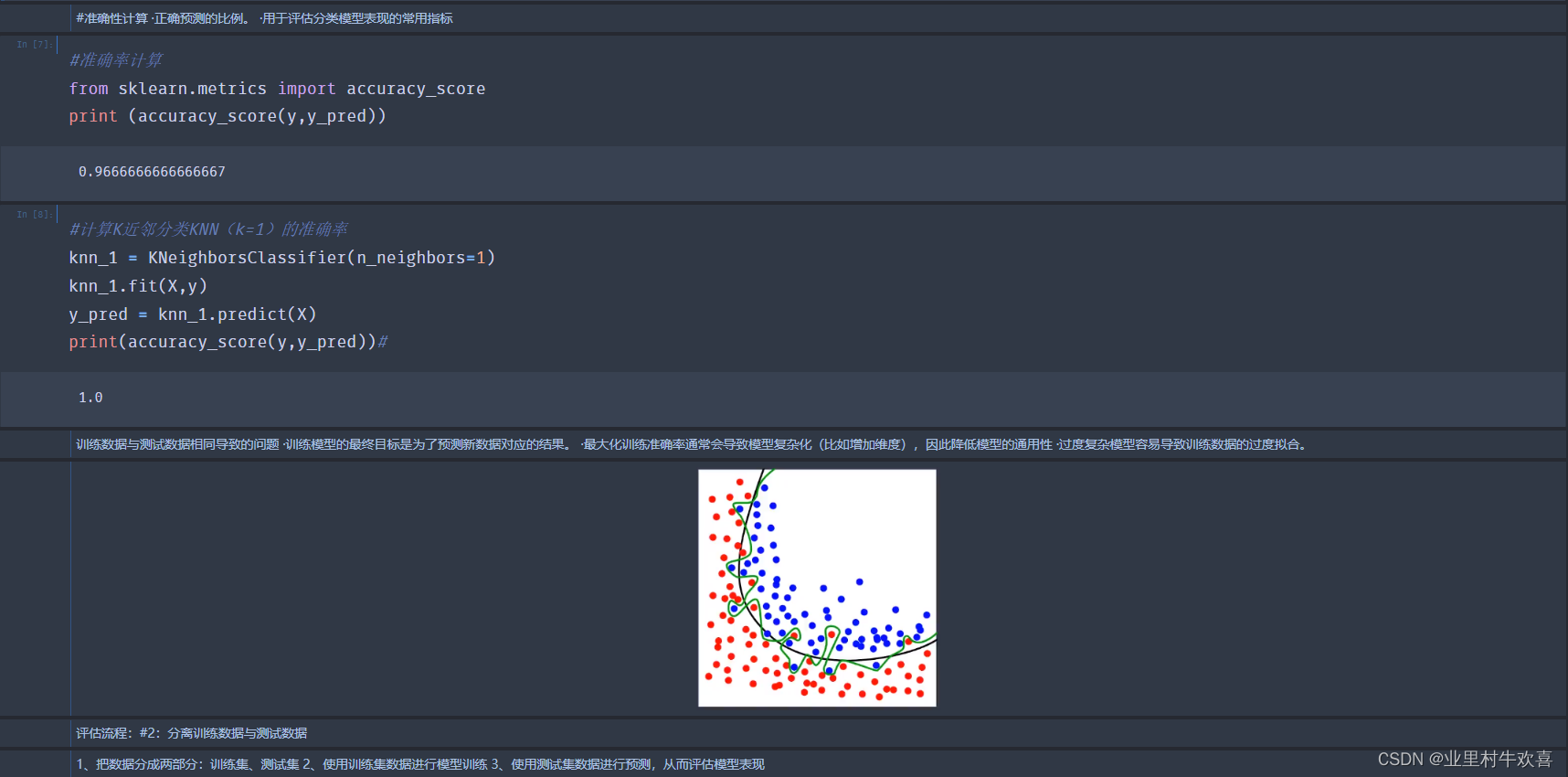
knn算法计算


机器学习实现之模型训练 Iris数据加载
#通过sklearn自带数据包加载iris数据
from sklearn import datasets
iris = datasets.load_iris()
#数据样本和结果样本分别赋值在“x”,"y"
X = iris.data
y = iris.target
#使用scikit-learn建模四步骤 1、调用需要使用的模型类 2、模型初始化(创建一个模型实例) 3、模型训练 4、模型预测
#模型调用,KNeighborsClassifier是k值
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
print (knn)
knn.fit(X,y)#模型训练
knn.predict([[1,2,3,4]])#预测结果以numpy的形式返回 
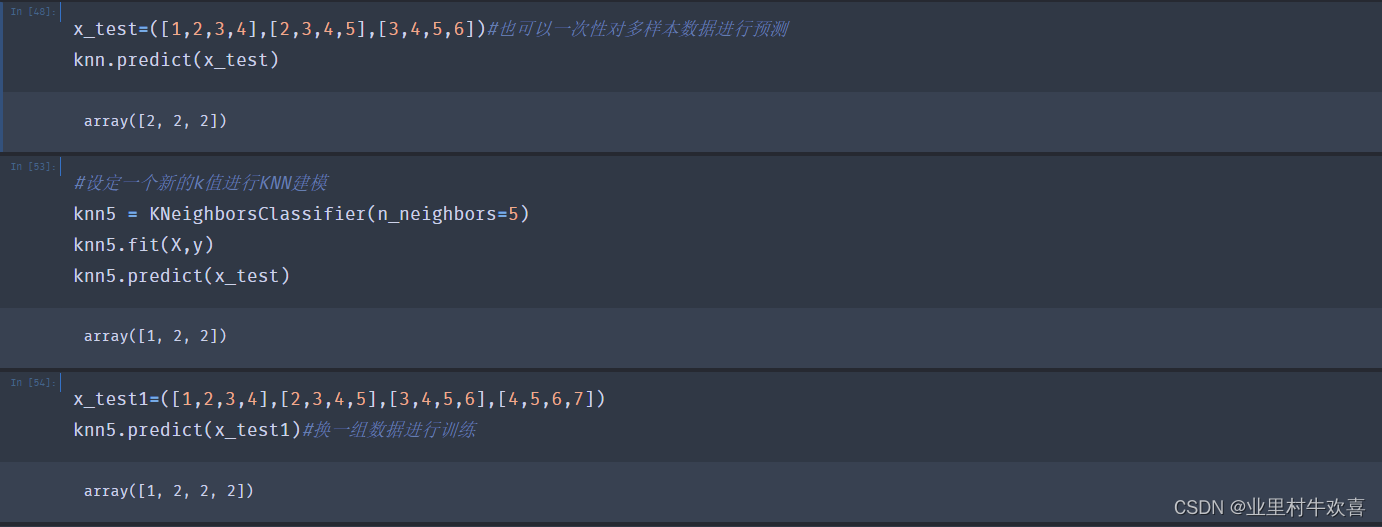
3.2机器学习实现模型评估一


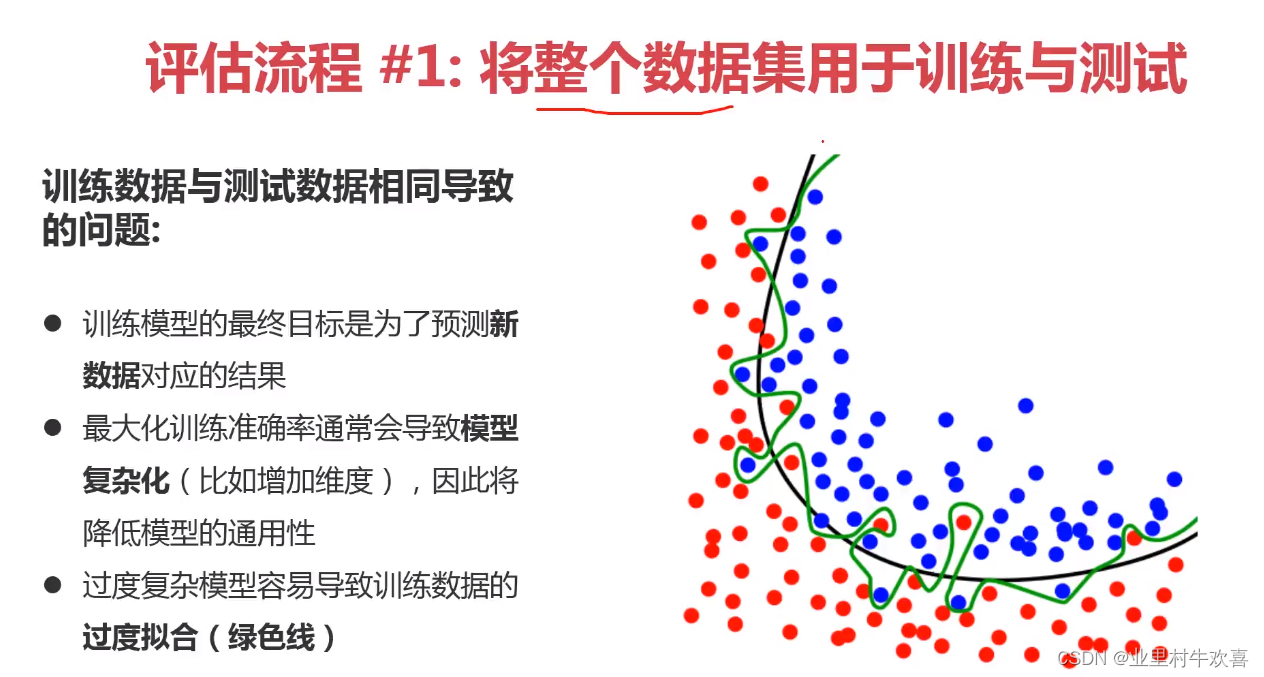
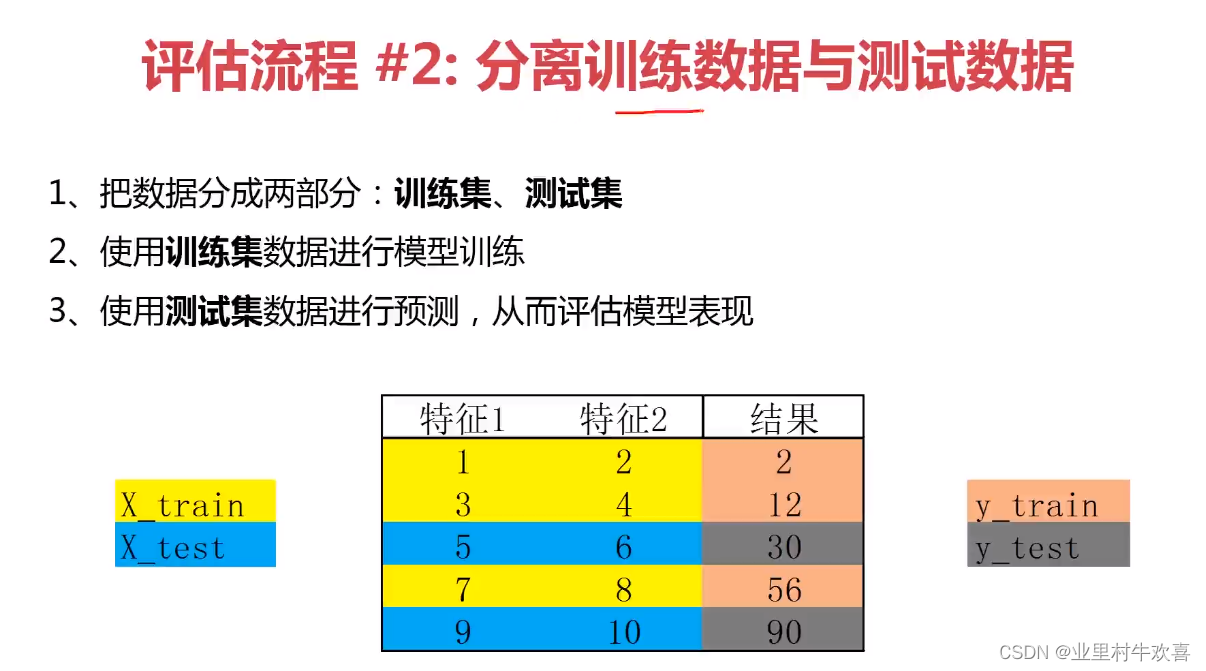


实操部分:
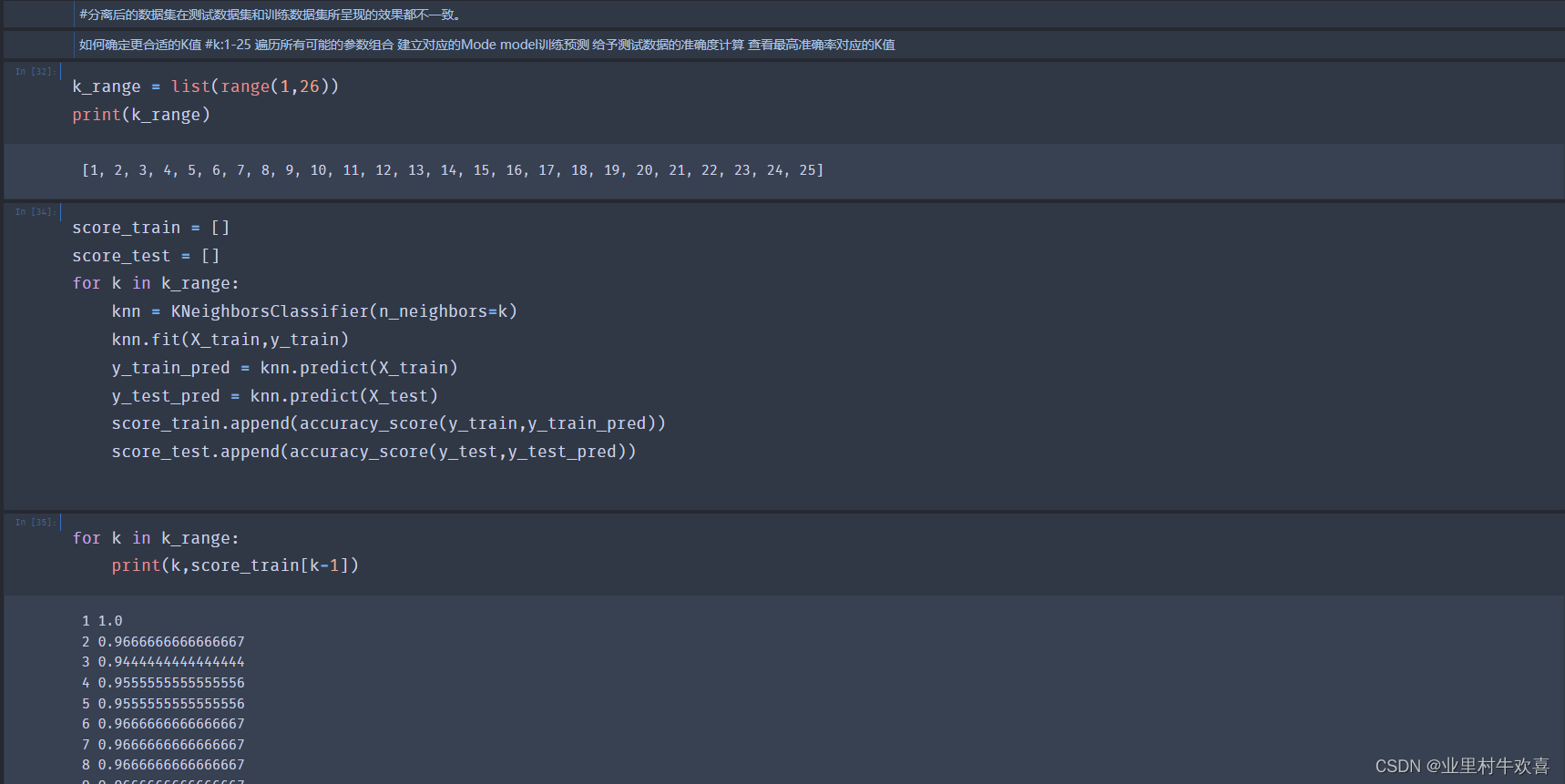
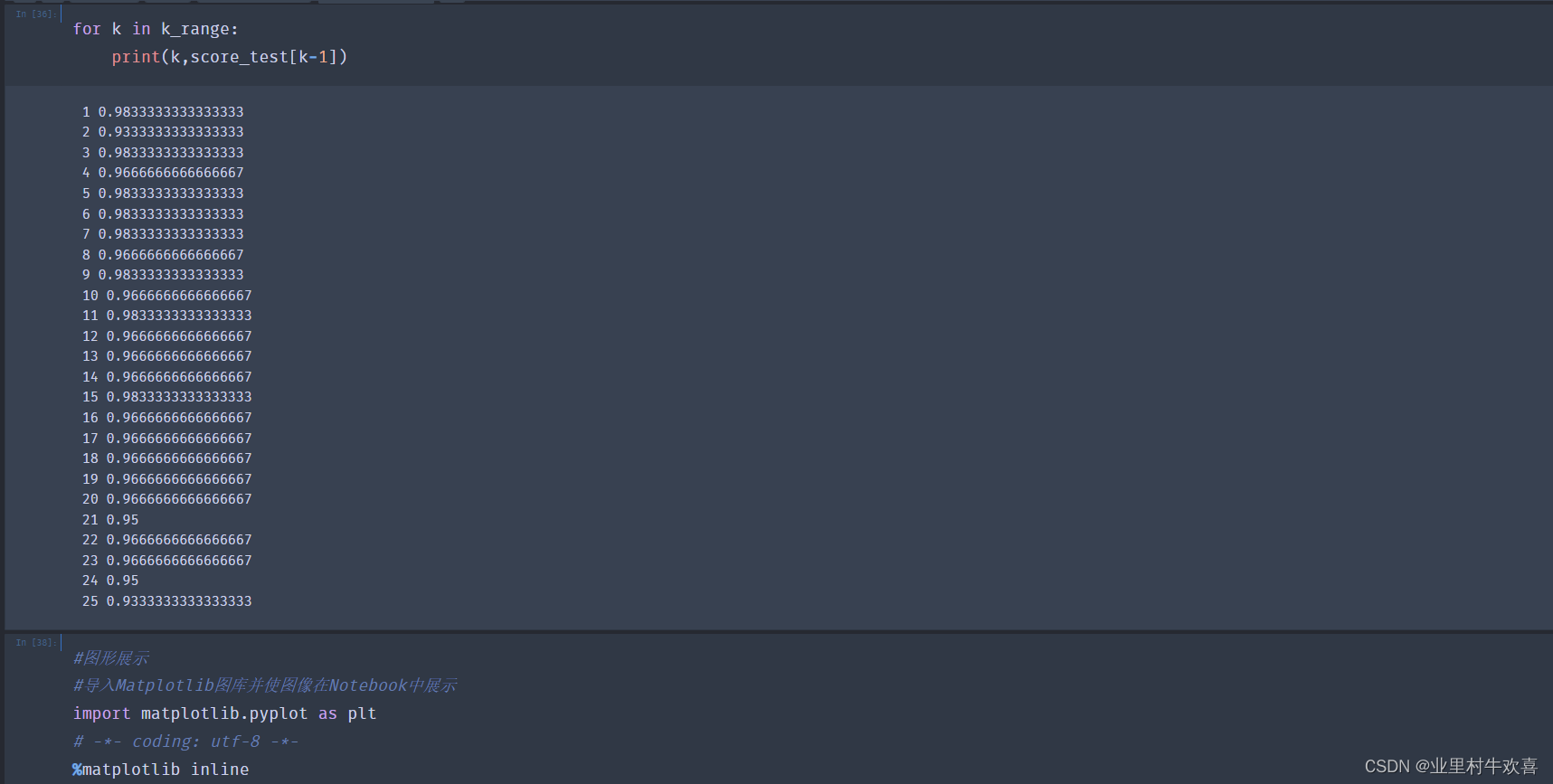
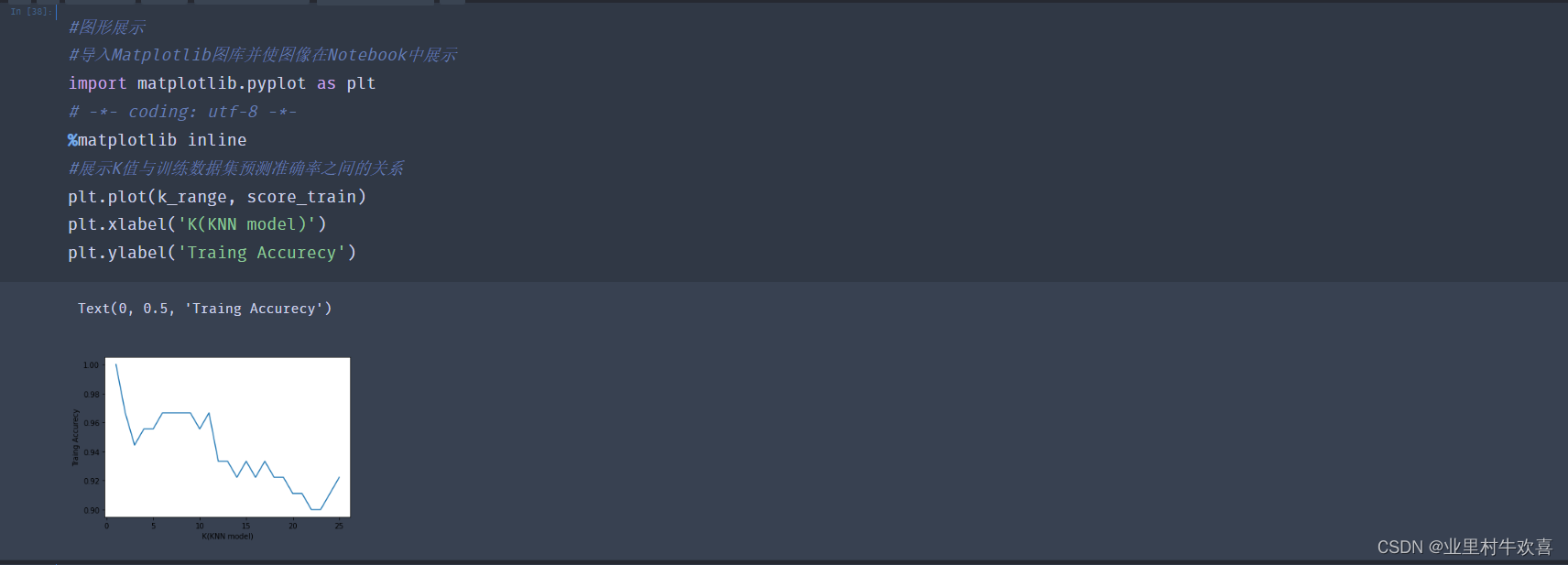
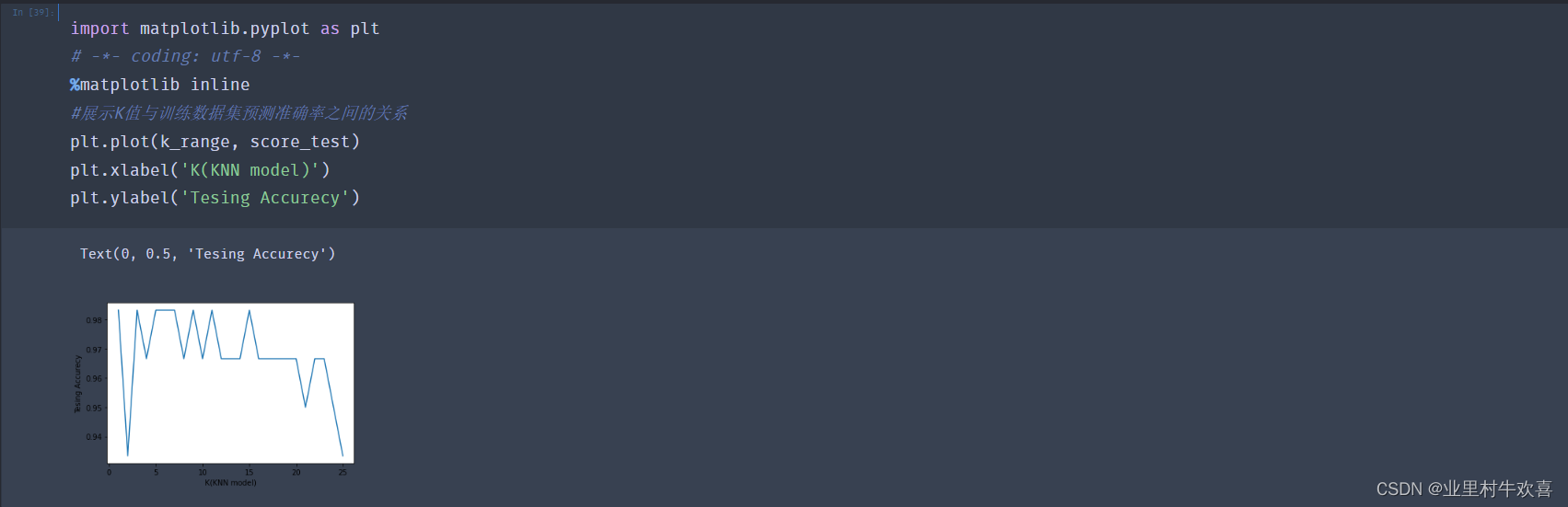

3.3机器学习实现之模型评估(二)





3.4机器学习实现之模型评估(三)
换一组数据进行深度学习演示,先看训练的数据HR_comma_sep.csv表
代码实操部分:
总结:机器深度学习可以把数据集进行深度建模,以相应的算法进行测试和评估。上图模型训练的原理使用KNN模型、KNN模型适用寻找knn的值相等的数据集进行模型训练。模型评估使用准确率、数据分离和逻辑回归、混淆矩阵适用找寻数据中存在准确性、回归性、特异性。我们根据使用实际的业务需求范围进行技术选型,后期人工智能学习的范围还很广,深度还有。路漫漫兮,努力学习。
完整的代码:
训练模型一:
机器学习实现之模型评估(二)
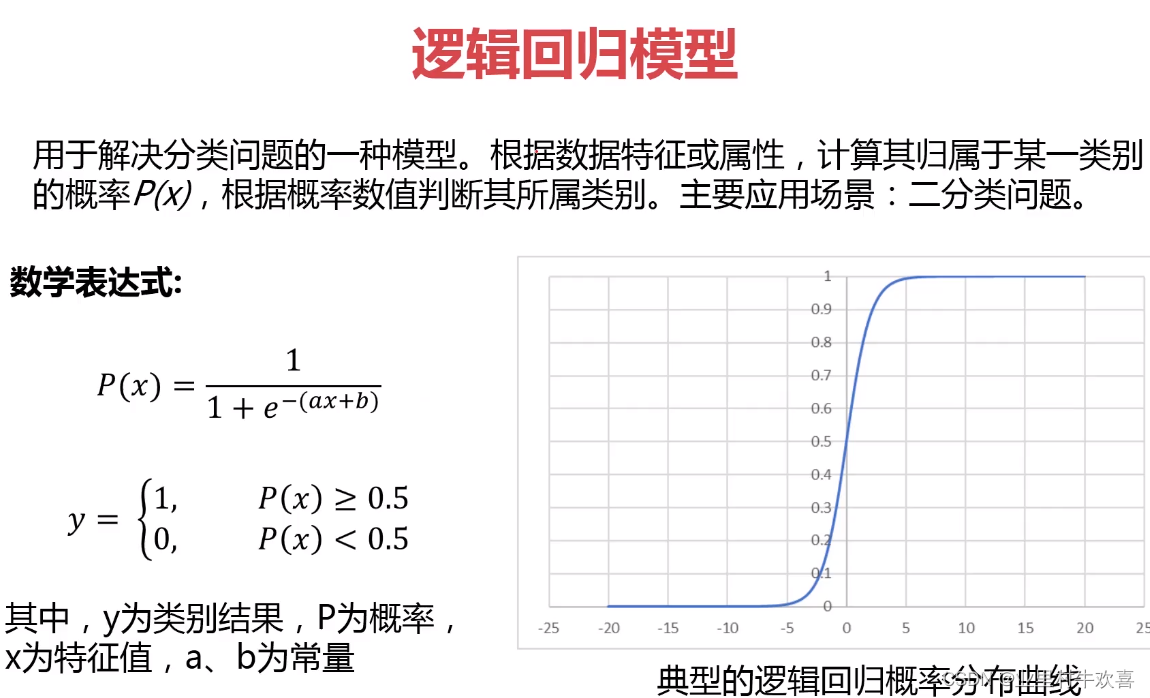
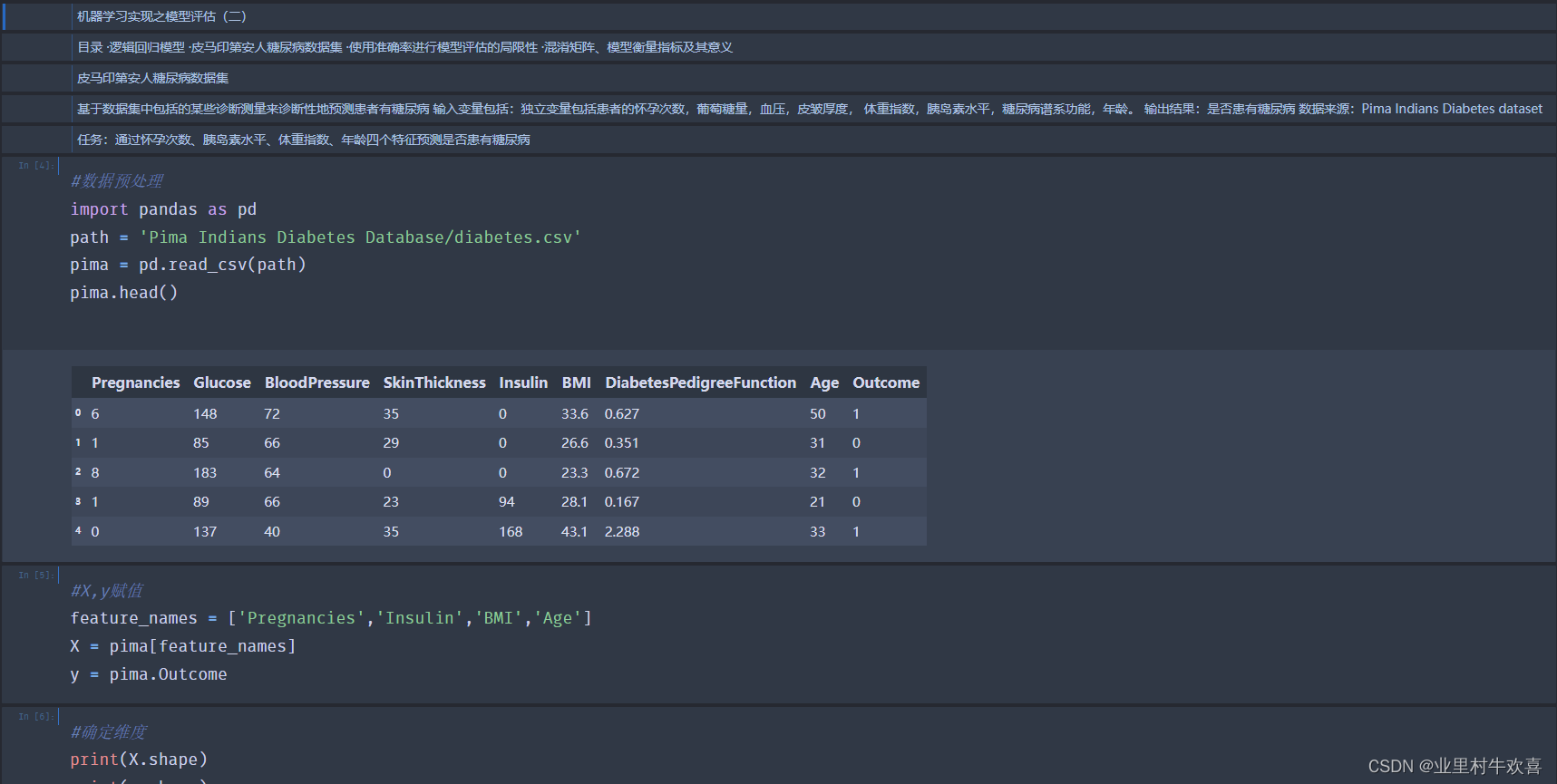
目录 ·逻辑回归模型 ·皮马印第安人糖尿病数据集 ·使用准确率进行模型评估的局限性 ·混淆矩阵、模型衡量指标及其意义
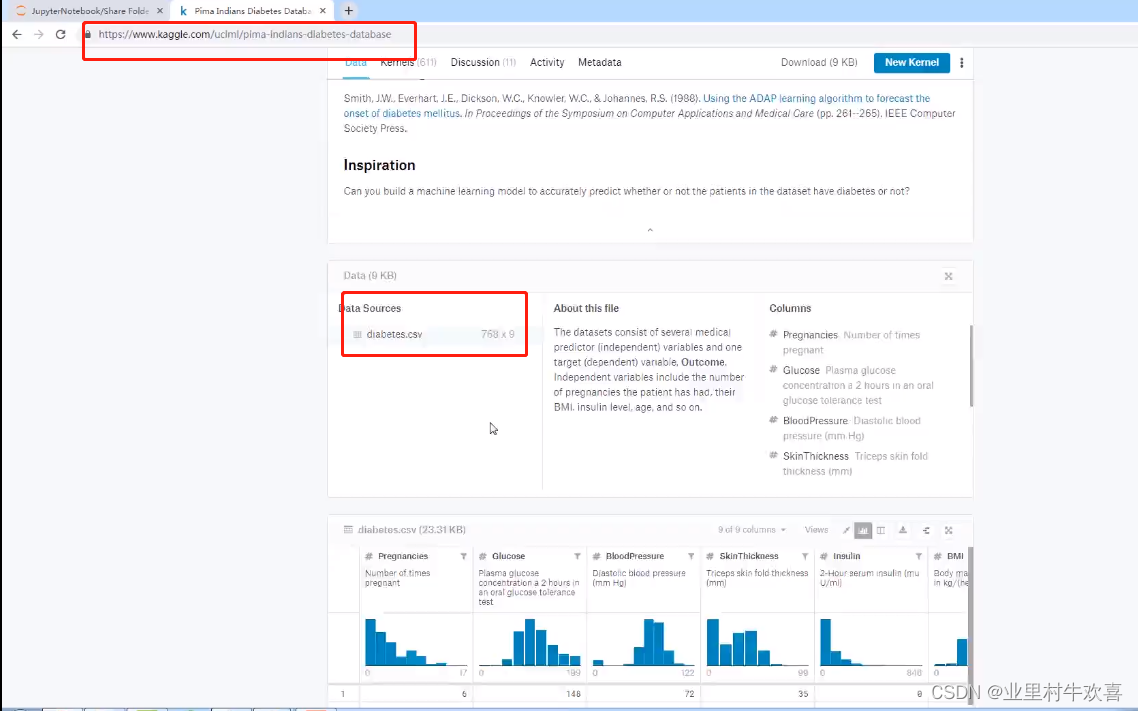
皮马印第安人糖尿病数据集
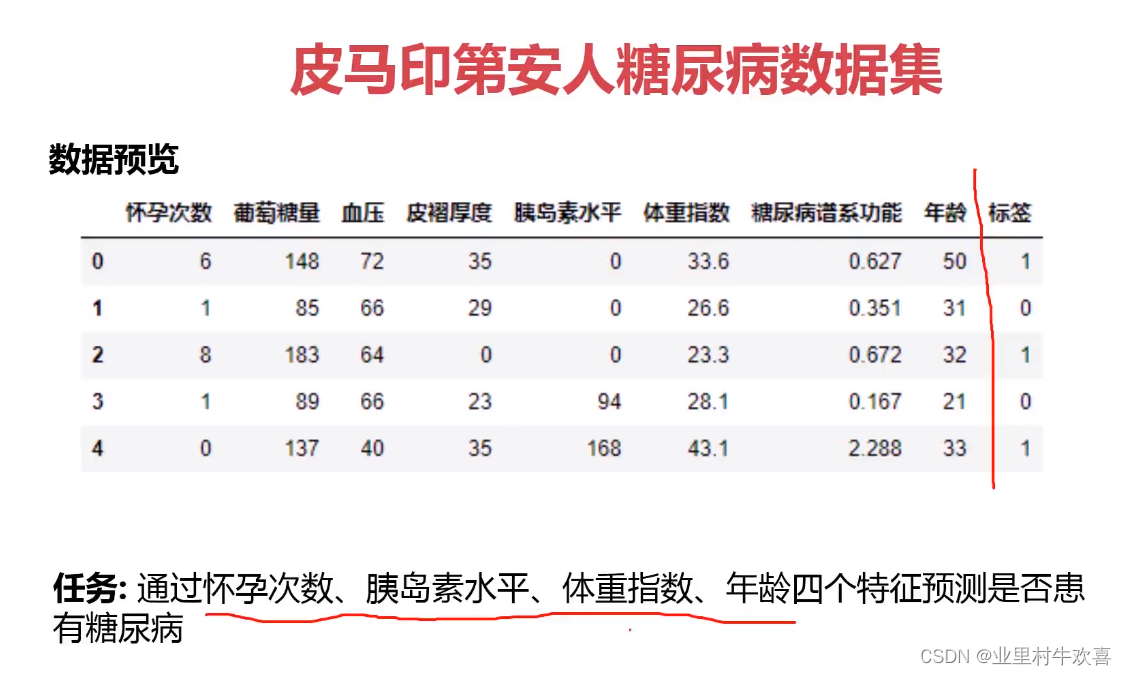
基于数据集中包括的某些诊断测量来诊断性地预测患者有糖尿病 输入变量包括:独立变量包括患者的怀孕次数,葡萄糖量,血压,皮皱厚度, 体重指数,胰岛素水平,糖尿病谱系功能,年龄。 输出结果:是否患有糖尿病 数据来源:Pima Indians Diabetes dataset
任务:通过怀孕次数、胰岛素水平、体重指数、年龄四个特征预测是否患有糖尿病
#数据预处理
import pandas as pd
path = 'Pima Indians Diabetes Database/diabetes.csv'
pima = pd.read_csv(path)
pima.head()
Pregnancies Glucose BloodPressure SkinThickness Insulin BMI DiabetesPedigreeFunction Age Outcome
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
3 1 89 66 23 94 28.1 0.167 21 0
4 0 137 40 35 168 43.1 2.288 33 1
#X,y赋值
feature_names = ['Pregnancies','Insulin','BMI','Age']
X = pima[feature_names]
y = pima.Outcome
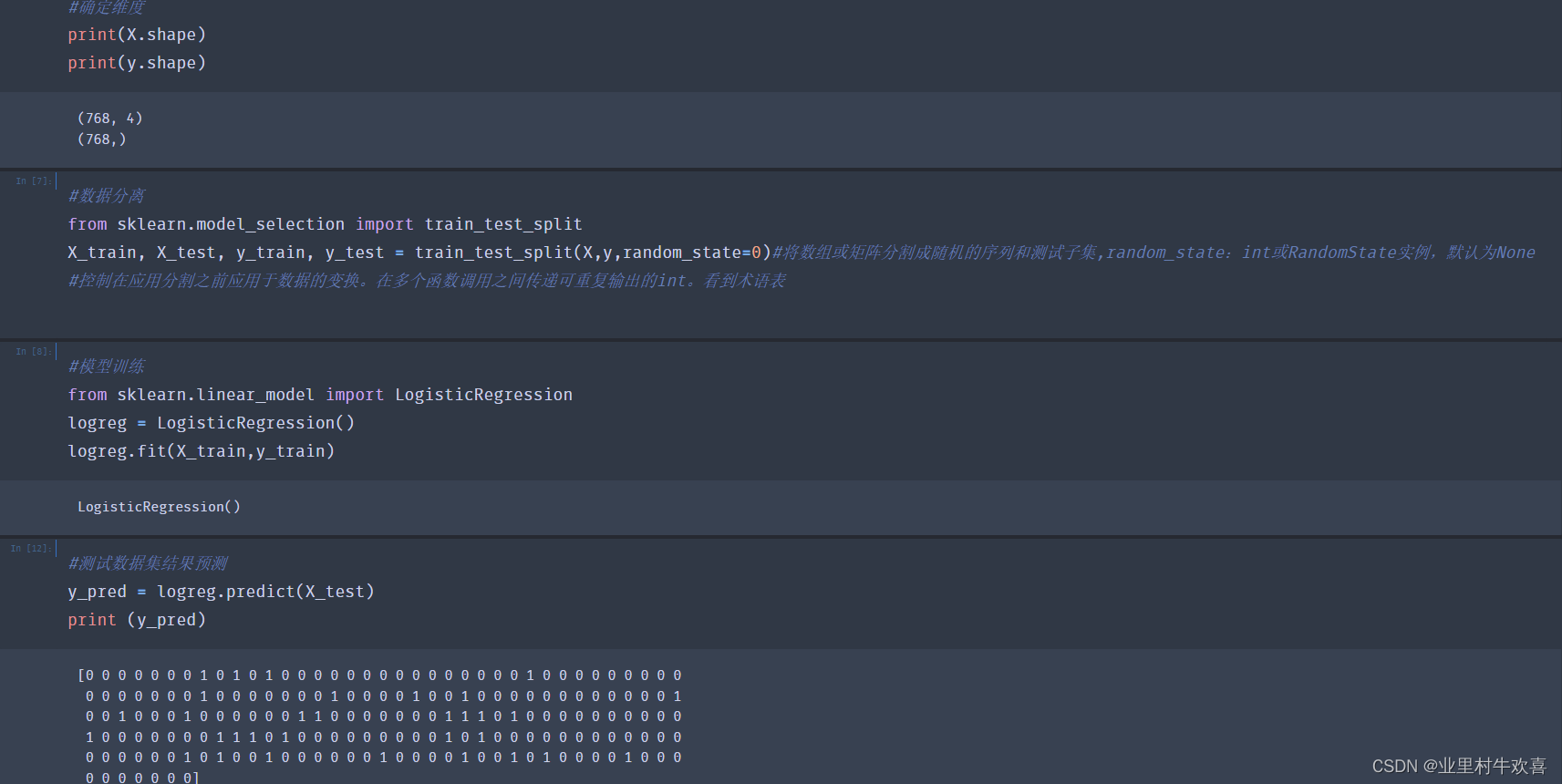
#确定维度
print(X.shape)
print(y.shape)
(768, 4)
(768,)
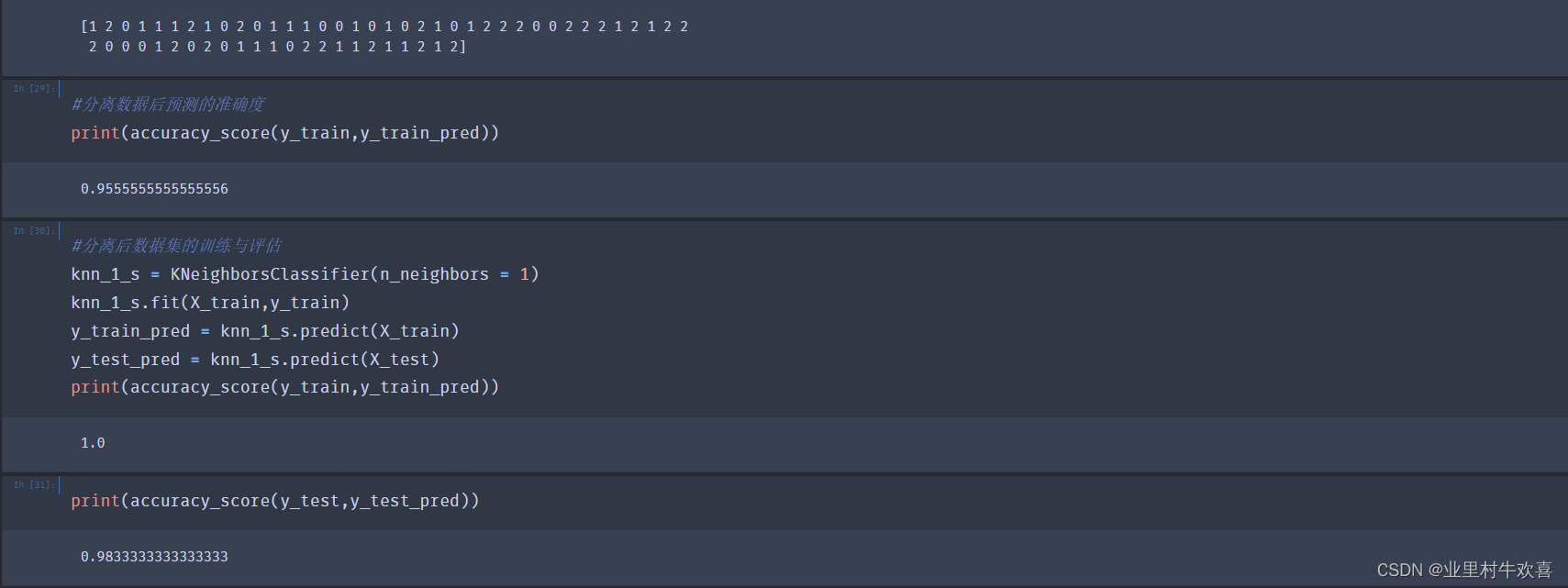
#数据分离
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)#将数组或矩阵分割成随机的序列和测试子集,random_state:int或RandomState实例,默认为None
#控制在应用分割之前应用于数据的变换。在多个函数调用之间传递可重复输出的int。看到术语表
#模型训练
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(X_train,y_train)
LogisticRegression()
#测试数据集结果预测
y_pred = logreg.predict(X_test)
print (y_pred)
[0 0 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1
0 0 1 0 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 1 1 1 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 1 0 0 1 0 1 0 0 0 0 1 0 0 0
0 0 0 0 0 0 0]
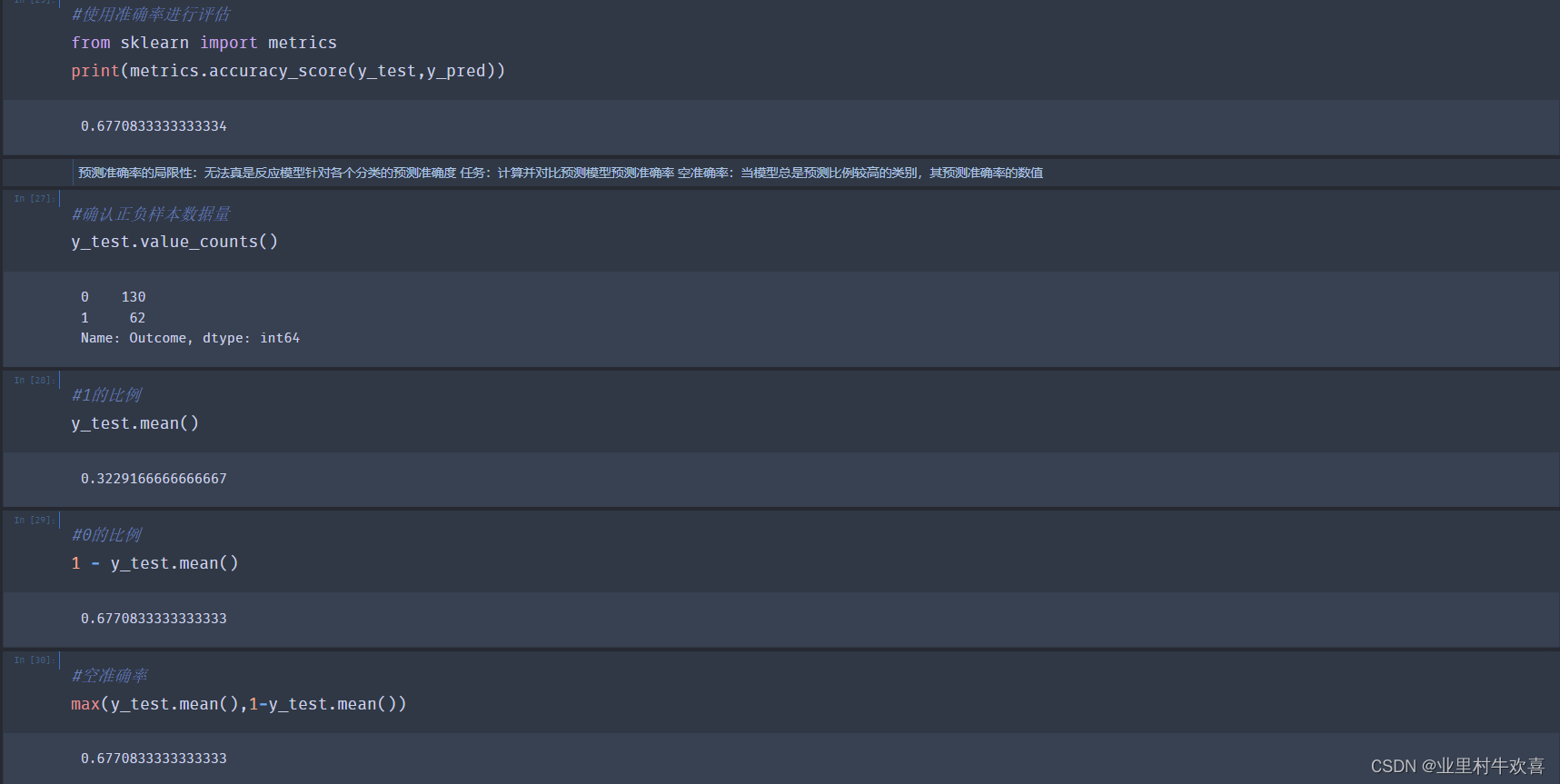
#使用准确率进行评估
from sklearn import metrics
print(metrics.accuracy_score(y_test,y_pred))
0.6770833333333334
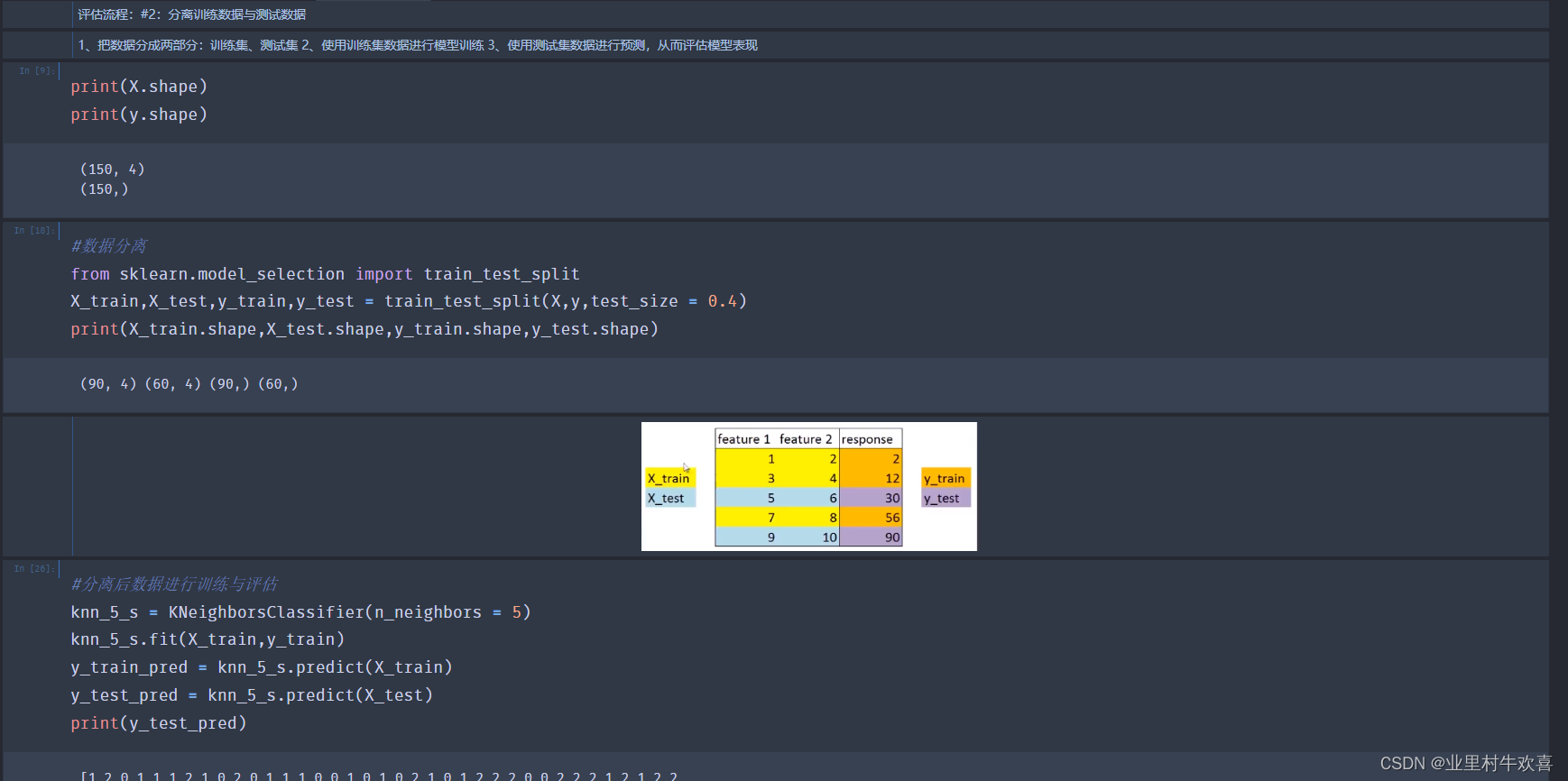
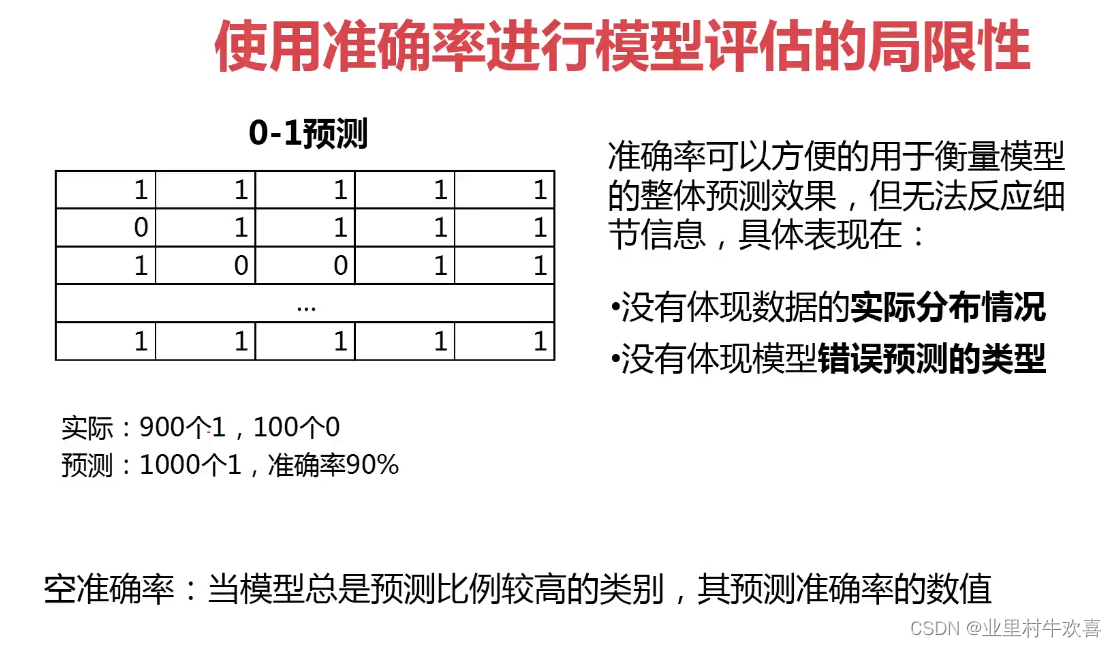
预测准确率的局限性:无法真是反应模型针对各个分类的预测准确度 任务:计算并对比预测模型预测准确率 空准确率:当模型总是预测比例较高的类别,其预测准确率的数值
#确认正负样本数据量
y_test.value_counts()
0 130
1 62
Name: Outcome, dtype: int64
#1的比例
y_test.mean()
0.3229166666666667
#0的比例
1 - y_test.mean()
0.6770833333333333
#空准确率
max(y_test.mean(),1-y_test.mean())
0.6770833333333333
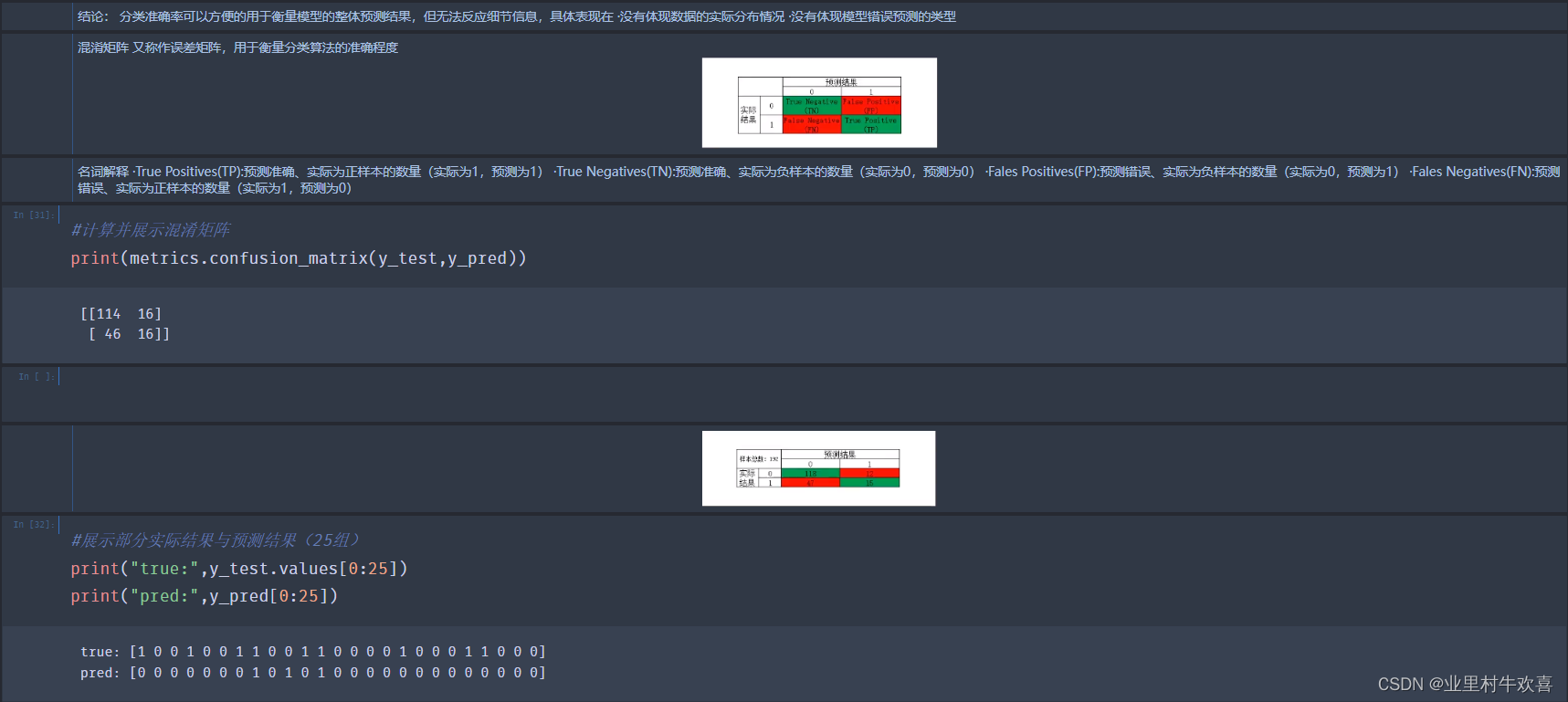
结论: 分类准确率可以方便的用于衡量模型的整体预测结果,但无法反应细节信息,具体表现在 ·没有体现数据的实际分布情况 ·没有体现模型错误预测的类型
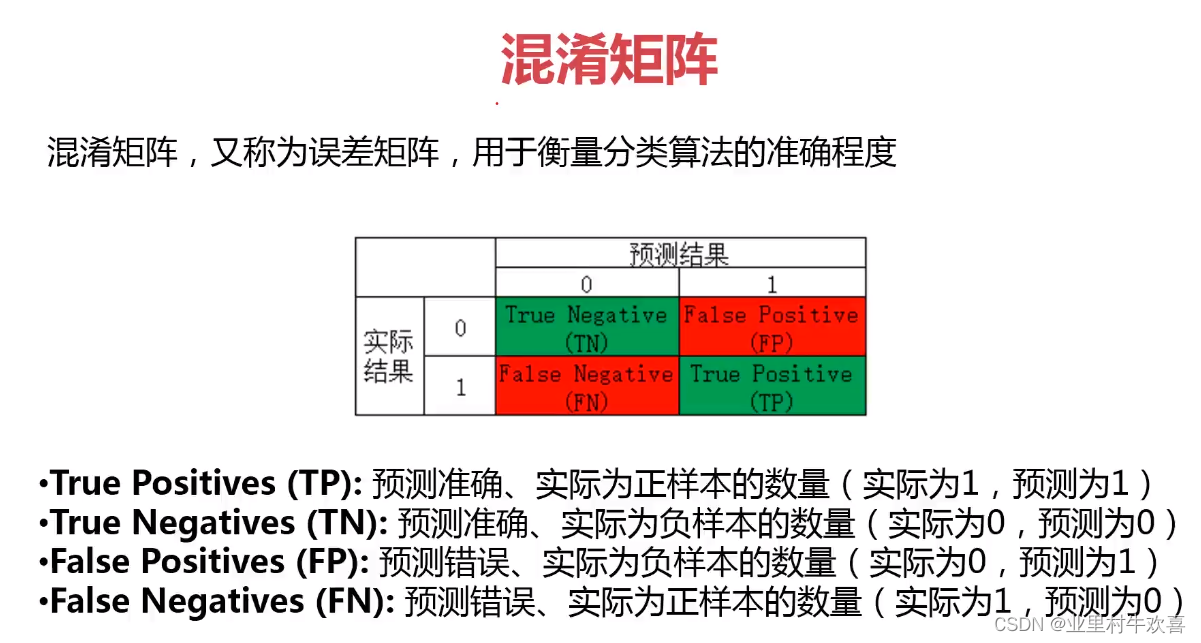
混淆矩阵 又称作误差矩阵,用于衡量分类算法的准确程度 image-2.png
名词解释 ·True Positives(TP):预测准确、实际为正样本的数量(实际为1,预测为1) ·True Negatives(TN):预测准确、实际为负样本的数量(实际为0,预测为0) ·Fales Positives(FP):预测错误、实际为负样本的数量(实际为0,预测为1) ·Fales Negatives(FN):预测错误、实际为正样本的数量(实际为1,预测为0)
#计算并展示混淆矩阵
print(metrics.confusion_matrix(y_test,y_pred))
[[114 16]
[ 46 16]]
image-3.png
#展示部分实际结果与预测结果(25组)
print("true:",y_test.values[0:25])
print("pred:",y_pred[0:25])
true: [1 0 0 1 0 0 1 1 0 0 1 1 0 0 0 0 1 0 0 0 1 1 0 0 0]
pred: [0 0 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0]
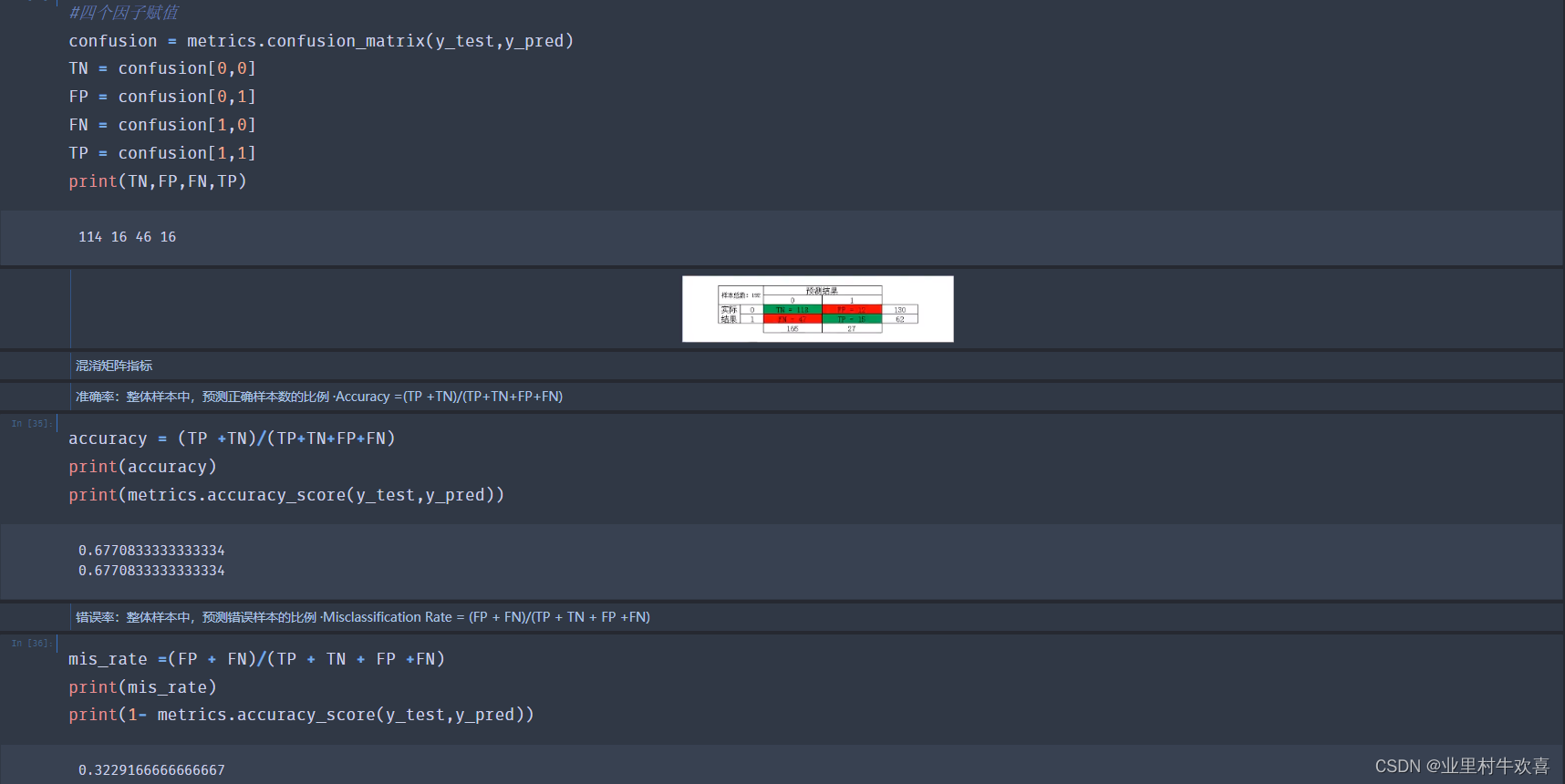
#四个因子赋值
confusion = metrics.confusion_matrix(y_test,y_pred)
TN = confusion[0,0]
FP = confusion[0,1]
FN = confusion[1,0]
TP = confusion[1,1]
print(TN,FP,FN,TP)
114 16 46 16
image.png
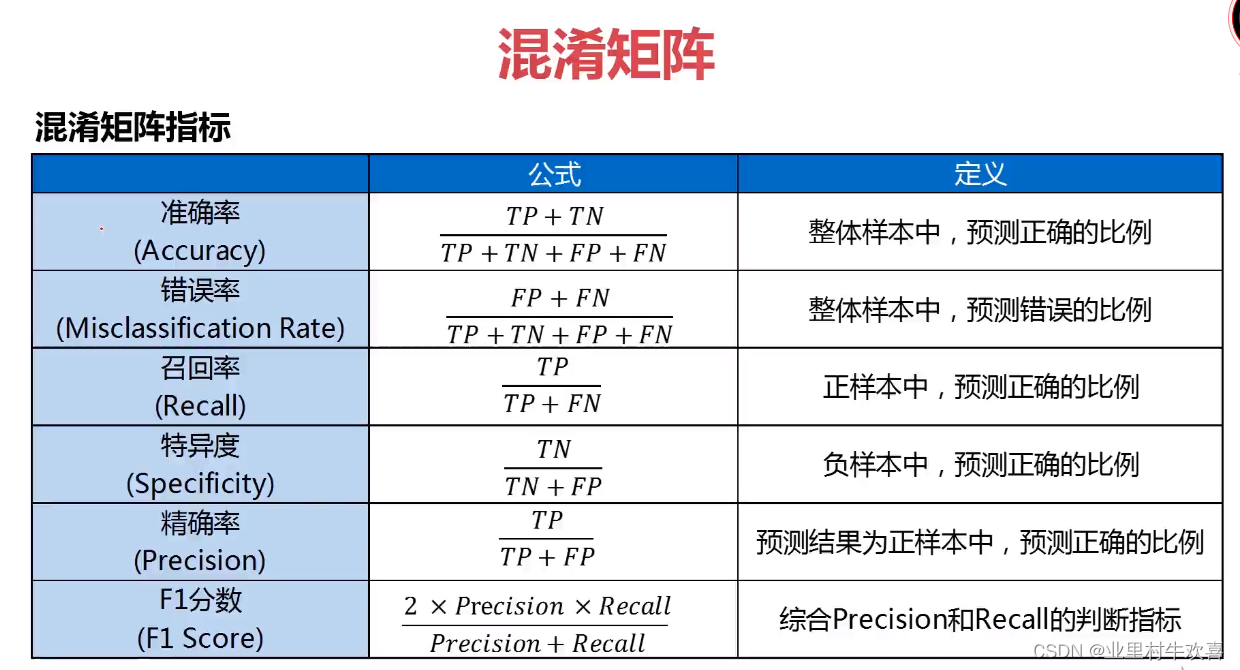
混淆矩阵指标
准确率:整体样本中,预测正确样本数的比例 ·Accuracy =(TP +TN)/(TP+TN+FP+FN)
accuracy = (TP +TN)/(TP+TN+FP+FN)
print(accuracy)
print(metrics.accuracy_score(y_test,y_pred))
0.6770833333333334
0.6770833333333334
错误率:整体样本中,预测错误样本的比例 ·Misclassification Rate = (FP + FN)/(TP + TN + FP +FN)
mis_rate =(FP + FN)/(TP + TN + FP +FN)
print(mis_rate)
print(1- metrics.accuracy_score(y_test,y_pred))
0.3229166666666667
0.32291666666666663
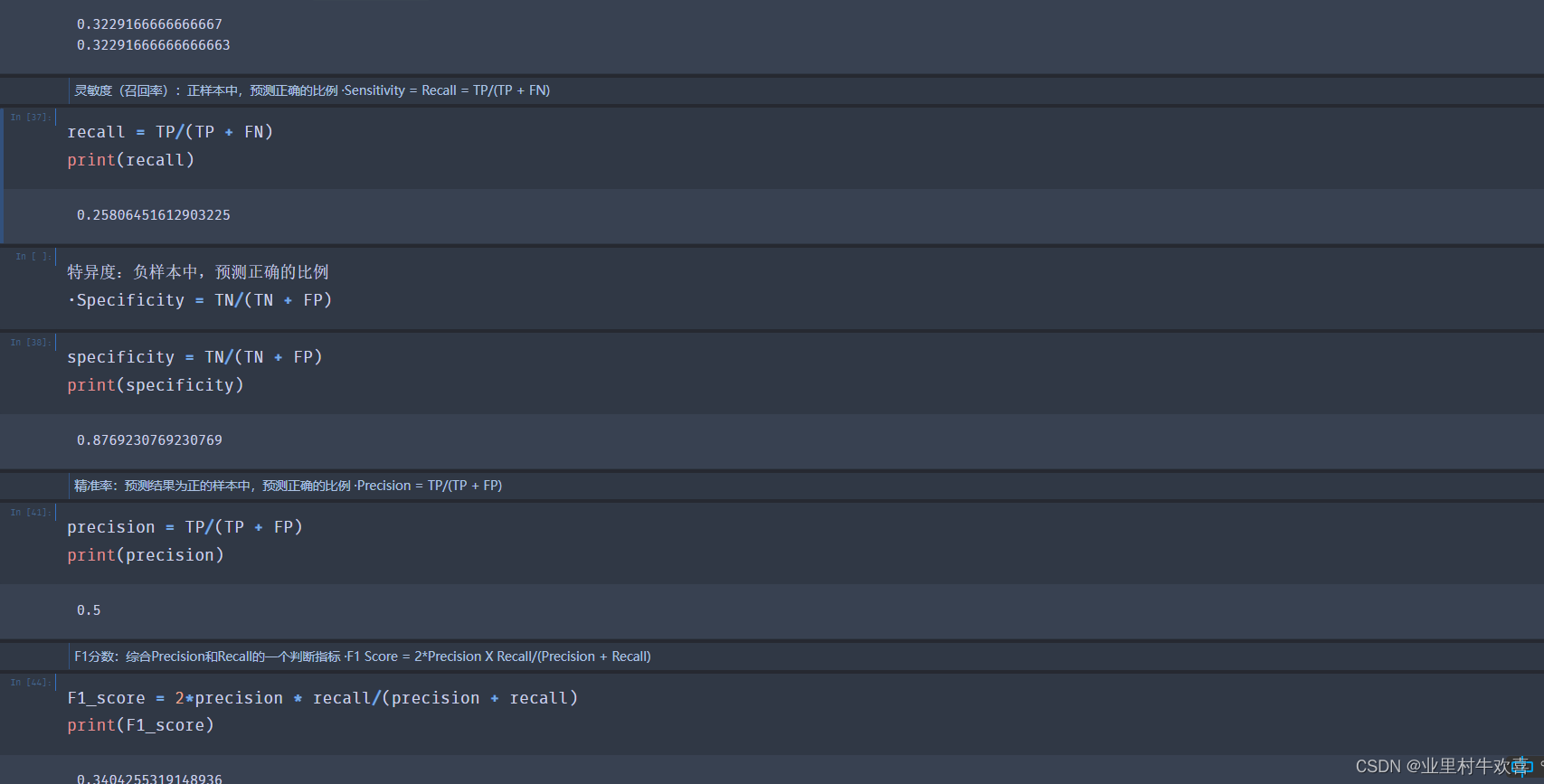
灵敏度(召回率):正样本中,预测正确的比例 ·Sensitivity = Recall = TP/(TP + FN)
recall = TP/(TP + FN)
print(recall)
0.25806451612903225
特异度:负样本中,预测正确的比例
·Specificity = TN/(TN + FP)
specificity = TN/(TN + FP)
print(specificity)
0.8769230769230769
精准率:预测结果为正的样本中,预测正确的比例 ·Precision = TP/(TP + FP)
precision = TP/(TP + FP)
print(precision)
0.5
F1分数:综合Precision和Recall的一个判断指标 ·F1 Score = 2*Precision X Recall/(Precision + Recall)
F1_score = 2*precision * recall/(precision + recall)
print(F1_score)
0.3404255319148936
结论: ·分类任务重,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信息 ·通过混淆矩阵,我们可以计算出多样的模型表现衡量指标,从而更好地选择模型 哪个衡量指标更加关键呢? ·衡量指标的选择取决于应用场景 ·垃圾邮件检测【(正样本为“垃圾邮件”):希望普通邮件(负样本)不要被判断为垃圾邮件(正样本),需要关注精准度,希望判断为垃圾邮件的样本都是判断正确的;还需要关注召回率,希望所有垃圾邮件尽可能判断出来】 ·异常交易检测:(正样本为“异常交易”):希望所有的异常交易都被检测到,即判断为正常交易中可能不存在异常交易,需要关注特异度训练模型二:
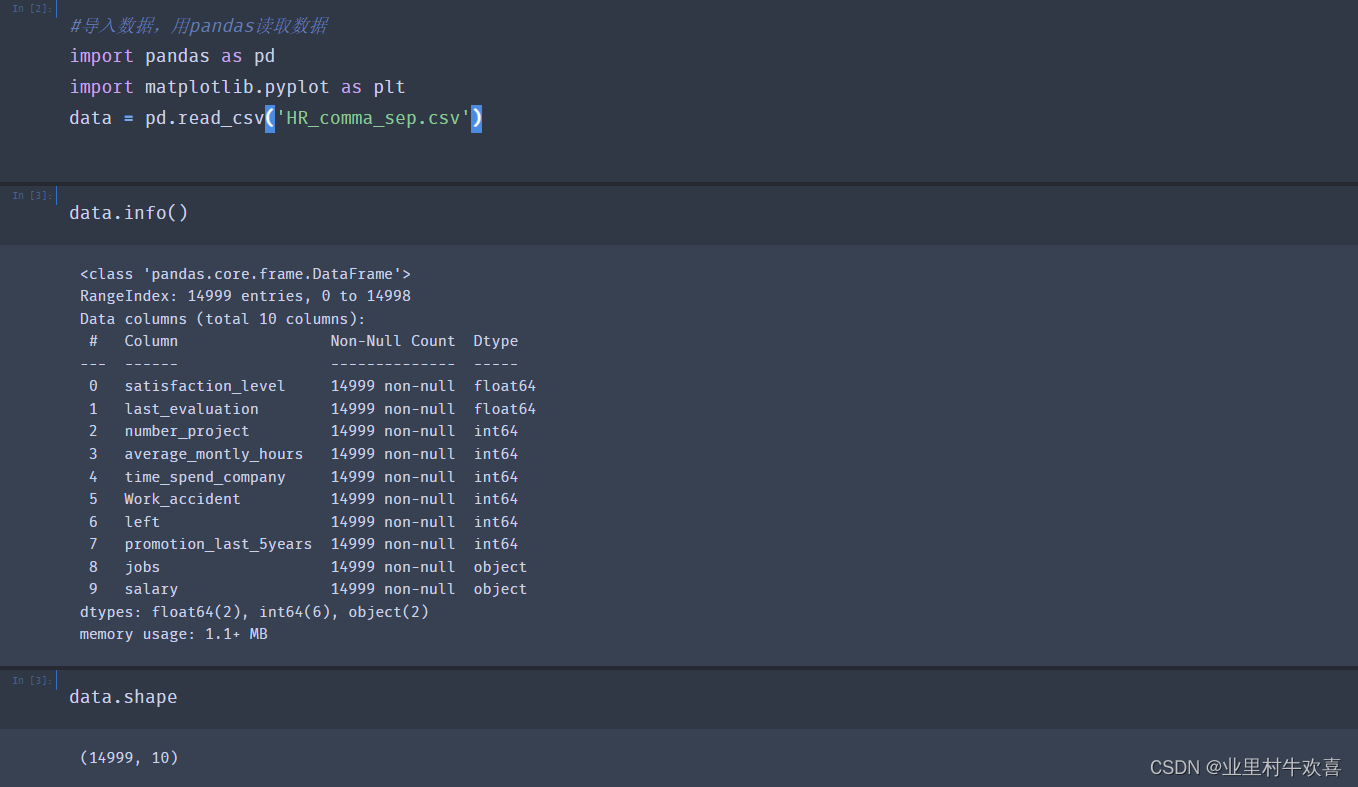
#导入数据,用pandas读取数据
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('HR_comma_sep.csv')
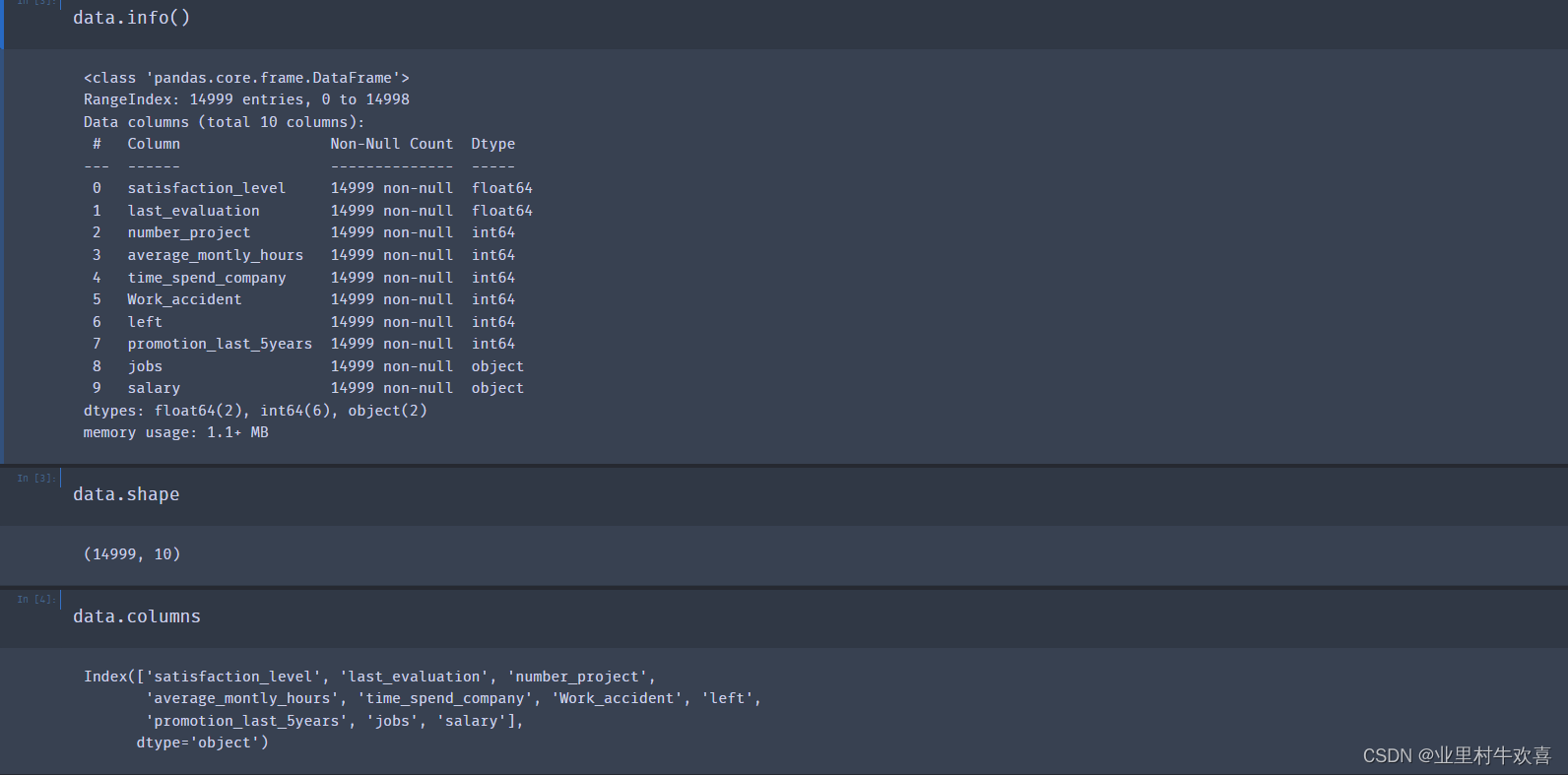
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14999 entries, 0 to 14998
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 satisfaction_level 14999 non-null float64
1 last_evaluation 14999 non-null float64
2 number_project 14999 non-null int64
3 average_montly_hours 14999 non-null int64
4 time_spend_company 14999 non-null int64
5 Work_accident 14999 non-null int64
6 left 14999 non-null int64
7 promotion_last_5years 14999 non-null int64
8 jobs 14999 non-null object
9 salary 14999 non-null object
dtypes: float64(2), int64(6), object(2)
memory usage: 1.1+ MB
data.shape
(14999, 10)
data.columns
Index(['satisfaction_level', 'last_evaluation', 'number_project',
'average_montly_hours', 'time_spend_company', 'Work_accident', 'left',
'promotion_last_5years', 'jobs', 'salary'],
dtype='object')
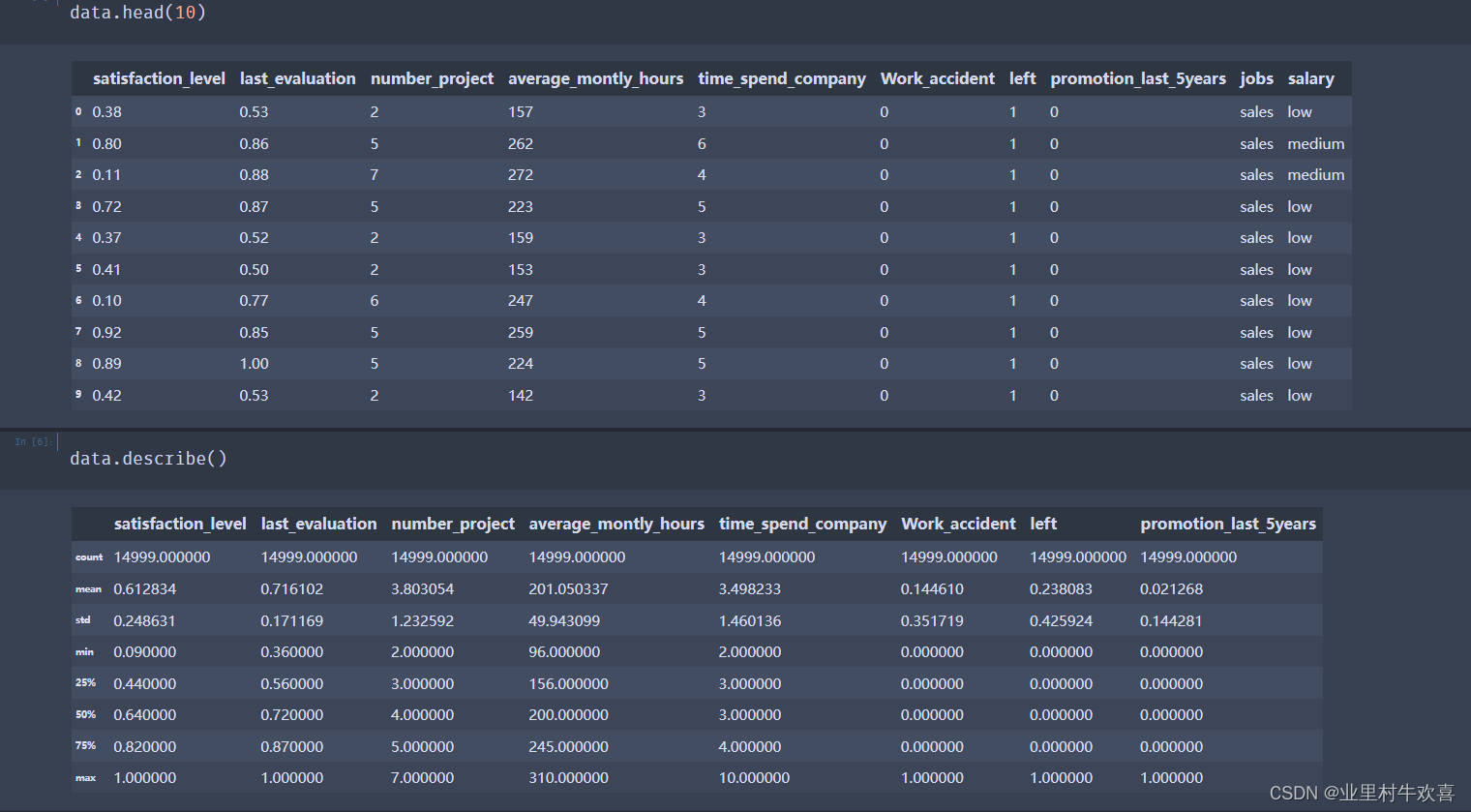
data.head(10)
satisfaction_level last_evaluation number_project average_montly_hours time_spend_company Work_accident left promotion_last_5years jobs salary
0 0.38 0.53 2 157 3 0 1 0 sales low
1 0.80 0.86 5 262 6 0 1 0 sales medium
2 0.11 0.88 7 272 4 0 1 0 sales medium
3 0.72 0.87 5 223 5 0 1 0 sales low
4 0.37 0.52 2 159 3 0 1 0 sales low
5 0.41 0.50 2 153 3 0 1 0 sales low
6 0.10 0.77 6 247 4 0 1 0 sales low
7 0.92 0.85 5 259 5 0 1 0 sales low
8 0.89 1.00 5 224 5 0 1 0 sales low
9 0.42 0.53 2 142 3 0 1 0 sales low
data.describe()
satisfaction_level last_evaluation number_project average_montly_hours time_spend_company Work_accident left promotion_last_5years
count 14999.000000 14999.000000 14999.000000 14999.000000 14999.000000 14999.000000 14999.000000 14999.000000
mean 0.612834 0.716102 3.803054 201.050337 3.498233 0.144610 0.238083 0.021268
std 0.248631 0.171169 1.232592 49.943099 1.460136 0.351719 0.425924 0.144281
min 0.090000 0.360000 2.000000 96.000000 2.000000 0.000000 0.000000 0.000000
25% 0.440000 0.560000 3.000000 156.000000 3.000000 0.000000 0.000000 0.000000
50% 0.640000 0.720000 4.000000 200.000000 3.000000 0.000000 0.000000 0.000000
75% 0.820000 0.870000 5.000000 245.000000 4.000000 0.000000 0.000000 0.000000
max 1.000000 1.000000 7.000000 310.000000 10.000000 1.000000 1.000000 1.000000
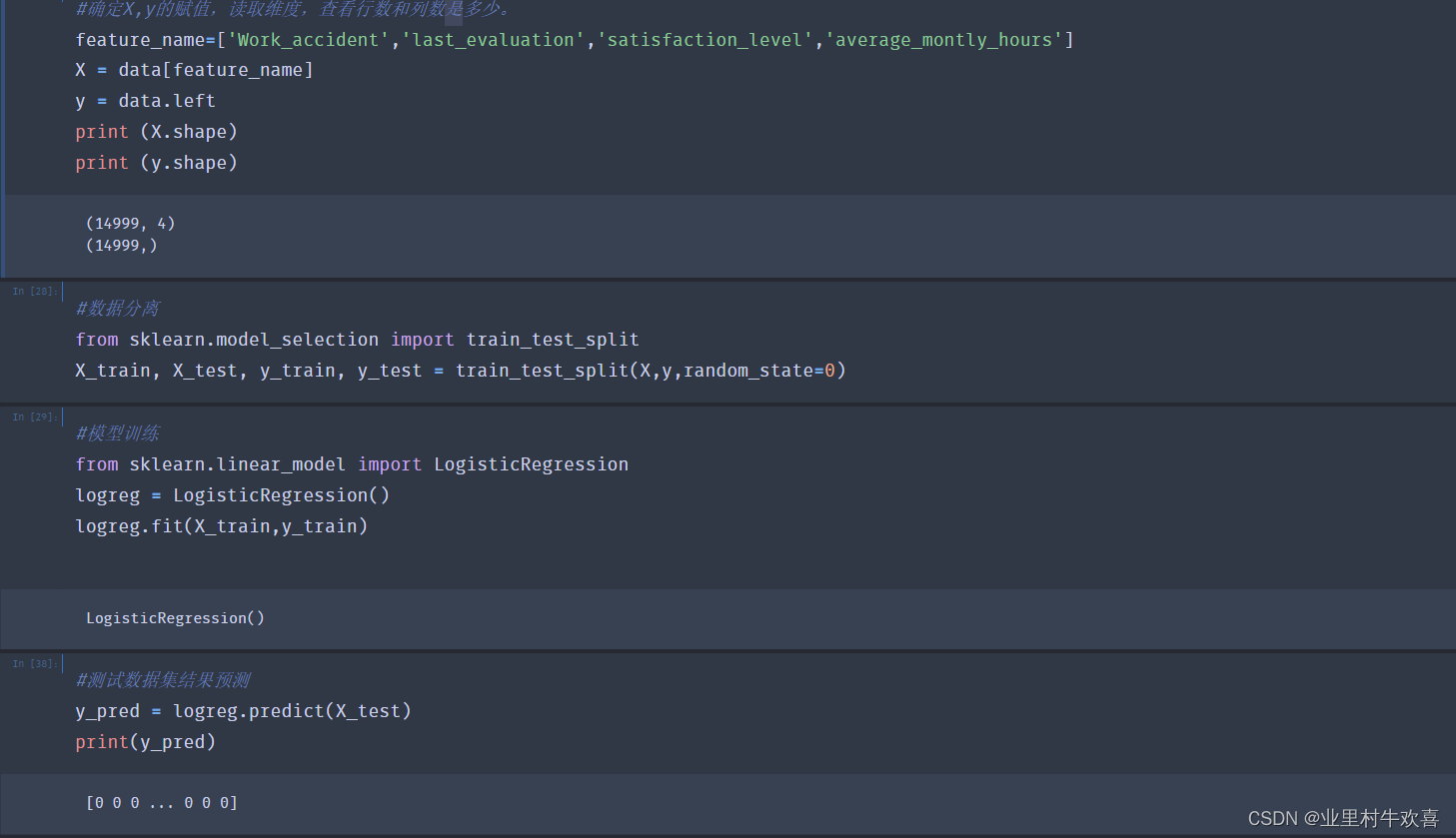
#确定X,y的赋值,读取维度,查看行数和列数是多少。
feature_name=['Work_accident','last_evaluation','satisfaction_level','average_montly_hours']
X = data[feature_name]
y = data.left
print (X.shape)
print (y.shape)
(14999, 4)
(14999,)
#数据分离
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
#模型训练
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(X_train,y_train)
LogisticRegression()
#测试数据集结果预测
y_pred = logreg.predict(X_test)
print(y_pred)
[0 0 0 ... 0 0 0]
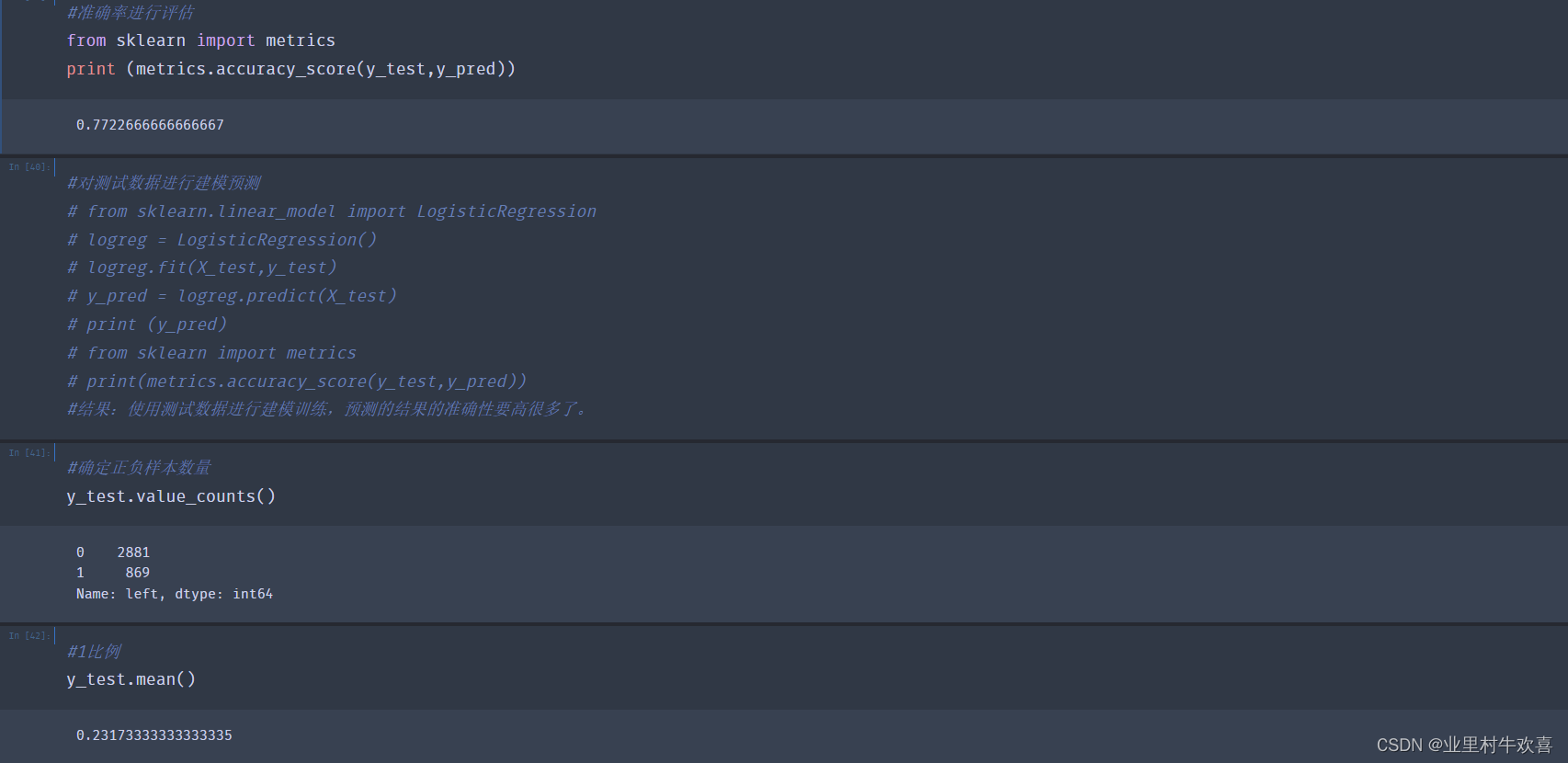
#准确率进行评估
from sklearn import metrics
print (metrics.accuracy_score(y_test,y_pred))
0.7722666666666667
#对测试数据进行建模预测
# from sklearn.linear_model import LogisticRegression
# logreg = LogisticRegression()
# logreg.fit(X_test,y_test)
# y_pred = logreg.predict(X_test)
# print (y_pred)
# from sklearn import metrics
# print(metrics.accuracy_score(y_test,y_pred))
#结果:使用测试数据进行建模训练,预测的结果的准确性要高很多了。
#确定正负样本数量
y_test.value_counts()
41
0 2881
1 869
Name: left, dtype: int64
#1比例
y_test.mean()
0.23173333333333335
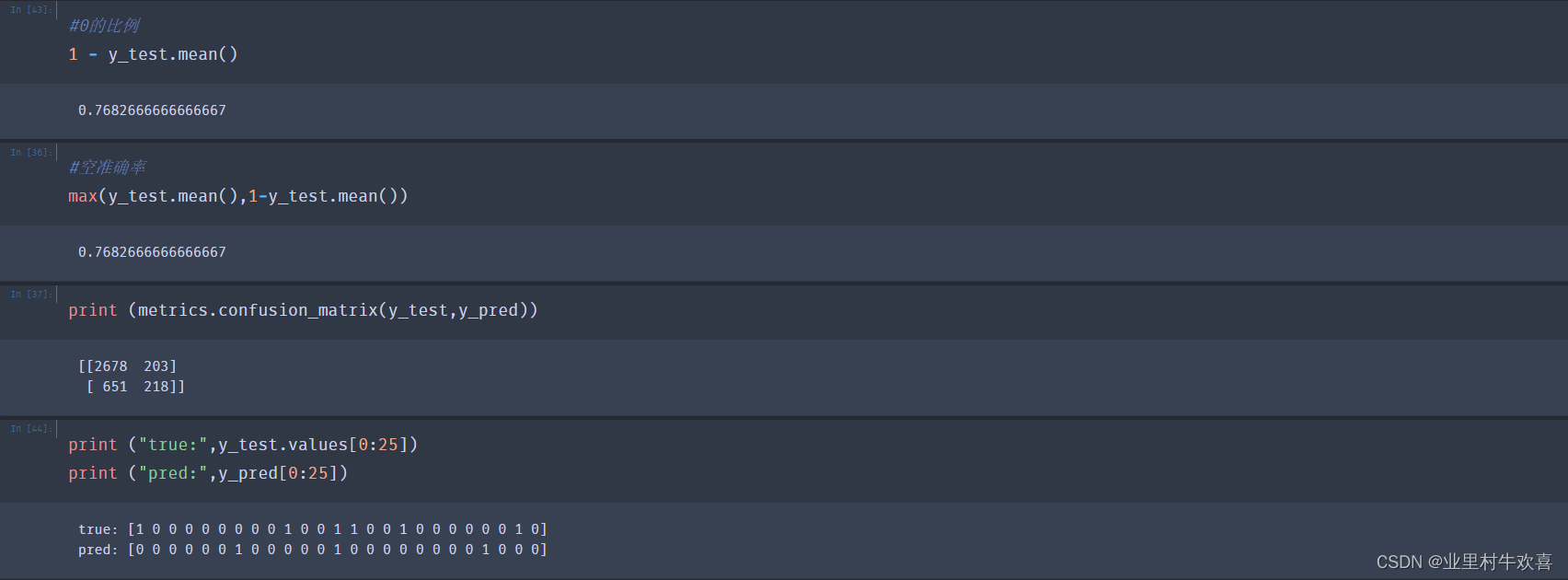
#0的比例
1 - y_test.mean()
0.7682666666666667
#空准确率
max(y_test.mean(),1-y_test.mean())
0.7682666666666667
print (metrics.confusion_matrix(y_test,y_pred))
[[2678 203]
[ 651 218]]
print ("true:",y_test.values[0:25])
print ("pred:",y_pred[0:25])
true: [1 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 1 0 0 0 0 0 0 1 0]
pred: [0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0]
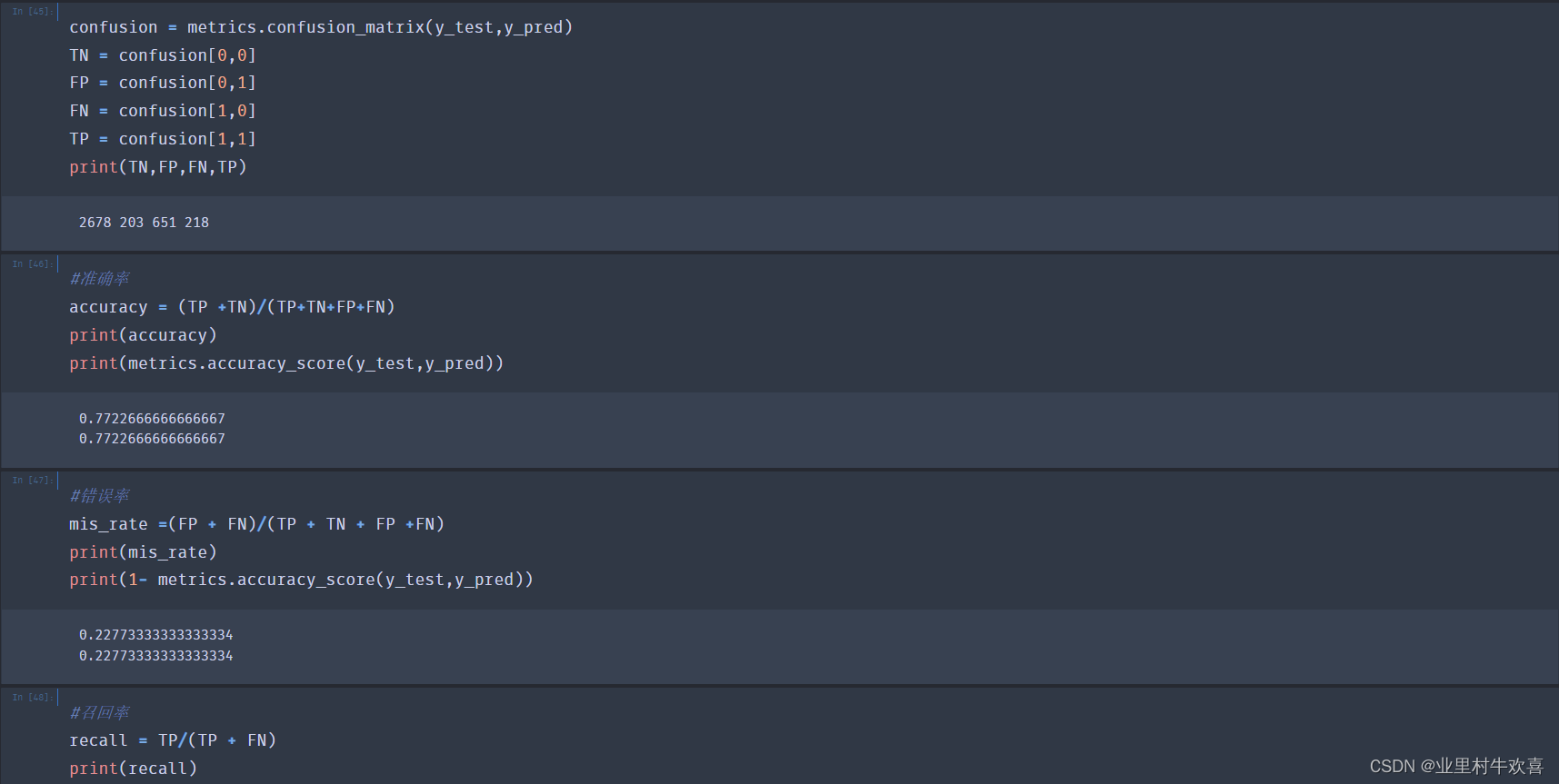
confusion = metrics.confusion_matrix(y_test,y_pred)
TN = confusion[0,0]
FP = confusion[0,1]
FN = confusion[1,0]
TP = confusion[1,1]
print(TN,FP,FN,TP)
2678 203 651 218
#准确率
accuracy = (TP +TN)/(TP+TN+FP+FN)
print(accuracy)
print(metrics.accuracy_score(y_test,y_pred))
0.7722666666666667
0.7722666666666667
#错误率
mis_rate =(FP + FN)/(TP + TN + FP +FN)
print(mis_rate)
print(1- metrics.accuracy_score(y_test,y_pred))
0.22773333333333334
0.22773333333333334
#召回率
recall = TP/(TP + FN)
print(recall)
0.2508630609896433
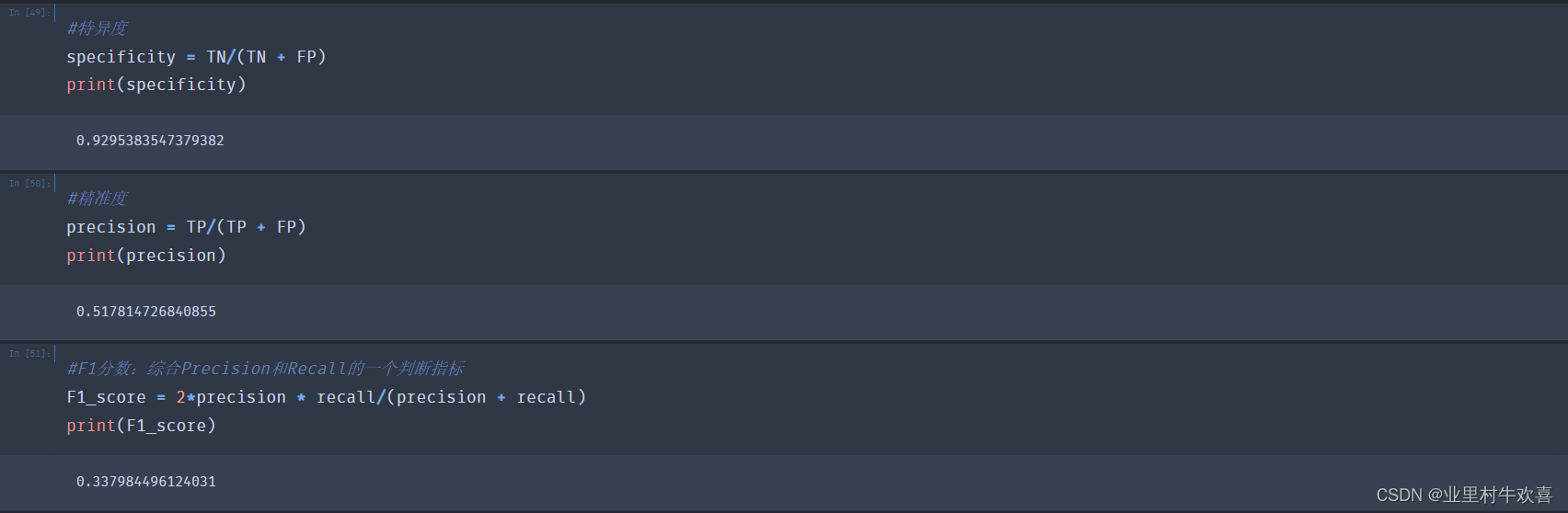
#特异度
specificity = TN/(TN + FP)
print(specificity)
0.9295383547379382
#精准度
precision = TP/(TP + FP)
print(precision)
0.517814726840855
#F1分数:综合Precision和Recall的一个判断指标
F1_score = 2*precision * recall/(precision + recall)
print(F1_score)
0.337984496124031参考网站:课程总结与人工智能实战提升,人工智能入门:Python实现机器学习教程-慕课网
kaggel竞赛之员工离职分析_二郎银的博客-CSDN博客_kaggle员工离职数据集
从小白到进阶 | 10个适合数据人练手的Kaggle数据集_CDA·数据分析师的博客-CSDN博客_kaggle数据集汇总
最后
以上就是耍酷手链最近收集整理的关于机器学习的入门教学-scikit-learn 一、概念分析二、开发环境搭建三、开发实战环节:的全部内容,更多相关机器学习的入门教学-scikit-learn 内容请搜索靠谱客的其他文章。








发表评论 取消回复