
01 起
在这篇文章中,我们讲解了如何训练决策树,然后我们得到了一个字典嵌套格式的决策树结果,这个结果不太直观,不能一眼看着这颗“树”的形状、分支、属性值等,怎么办呢?
本文就上文得到的决策树,给出决策树绘制函数,让我们对我们训练出的决策树一目了然。
在绘制决策树之后,我们会给出决策树的使用方法:如何利用训练好的决策树,预测训练数据的类别?
提示:不论是绘制还是使用决策树,中心思想都是递归。
02 决策树宽度和深度
在绘制决策树之前,我们需要知道利用python绘图的部分知识,比如如何在图中添加注解?
添加注解 annotate()
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format="retina"
#设置出图显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
#decisionNode={boxstyle:"sawtooth",fc:"0.8"} #决策节点样式
leafNode=dict(boxstyle="round4",fc="0.8") #叶节点样式
#设置标注箭头格式,->表示由注解指向外,<-表示指向注解,<->表示双向箭头
arrow_args=dict(arrowstyle="->")
#arrow_args=dict(facecolor="blue",shrink=0.05) #另一种设置箭头格式的方式
def plotNode(nodeText,centerPt,parentPt,nodeType):
# nodeTxt为要显示的文本,centerPt为文本的中心点,parentPt为指向文本的点
createPlot.ax1.annotate(nodeText,xytext=centerPt,textcoords="axes fraction",
xy=parentPt,xycoords="axes fraction",
va="bottom",ha="center",bbox=nodeType,arrowprops=arrow_args)
def createPlot():
fig=plt.figure(figsize=(6,6),facecolor="white")
fig.clf() #清空画布
# createPlot.ax1为全局变量,绘制图像的句柄,subplot为定义了一个绘图
#111表示figure中的图有1行1列,即1个,最后的1代表第一个图
# frameon表示是否绘制坐标轴矩形
createPlot.ax1=plt.subplot(111,frameon=False)
plotNode("决策节点",(0.8,0.4),(1.1,0.8),decisionNode)
plotNode("叶节点",(0.5,0.2),(0.2,0.5),leafNode)
plt.show()
运行createPlot()之后,得到这张图,注解就添加好了,之后我们会利用这个方法添加决策树的注解: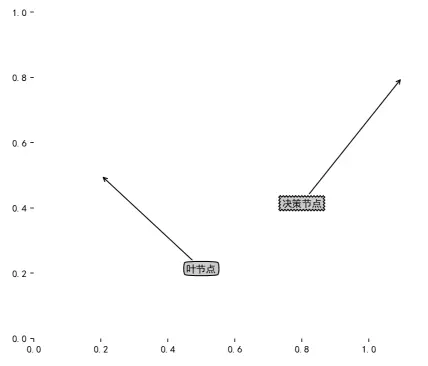
我们还需要知道如何计算一棵决策树的宽度和深度?
计算决策树宽度和深度
宽度:决策树的叶节点个数
深度:决策树最长分支的节点数
"""
输入:字典嵌套格式的决策树
输出:该决策树的叶节点数,相当于决策树宽度(W)
"""
def countLeaf(desicionTree):
cntLeaf=0
firstFeatrue=list(desicionTree.keys())[0] #决策树字典的第一个key是第一个最优特征,为什么要提取这个特征呢,因为后面要遍历该特征的属性值从而找个子树
subTree=desicionTree[firstFeatrue] #取节点key的value,即子树
for key in list(subTree.keys()): #遍历最优特征的各属性值,每个属性对应一个子树,判断子树是否为叶节点
if type(subTree[key]).__name__=="dict":
#如果当前属性值对应的子树类型为字典,说明这个节点不是叶节点,
#那么就递归调用自己,层层下探找到该通路叶节点,然后向上求和得到该通路叶节点数
cntLeaf += countLeaf(subTree[key]) #递归
else:
cntLeaf += 1
return cntLeaf
"""
输入:字典嵌套格式的决策树
输出:该决策树的深度(D)
"""
def countDepth(desicionTree):
maxDepth=0
firstFeatrue=list(desicionTree.keys())[0] #当前树的最优特征
subTree=desicionTree[firstFeatrue]
for key in list(subTree.keys()): #遍历最优特征的各属性值,每个属性对应一个子树,判断子树是否为叶节点
if type(subTree[key]).__name__=="dict":
thisDepth = 1+countDepth(subTree[key]) #这里值得认真思考过程,作图辅助思考
else:
thisDepth=1
if thisDepth>maxDepth:
maxDepth=thisDepth
我们拿上文训练好的决策树来测试一下,决策树长这样:
测试:
我们训练好的决策树宽度为8,深度为4
好了,下面我们可以进入绘制主函数了!
03 绘制决策树
目前我们已经得到了决策树的宽度和深度,还知道了如何在图中添加注解,下面我们开始绘制决策树,中心思想还是递归。
#自定义函数,在父子节点之间添加文本信息,在决策树中,相当于标注父结点特征的属性值
#cntPt是子节点坐标,parentPt是父节点坐标
def plotMidText(cntrPt,parentPt,nodeText):
xMid=(parentPt[0]-cntrPt[0])/2+cntrPt[0]
yMid=(parentPt[1]-cntrPt[1])/2+cntrPt[1]
createPlot.ax1.text(xMid,yMid,nodeText)
#自定义函数,是绘制决策树的主力军
def plotTree(decisionTree,parentPt,nodeText):
cntLeafs=countLeaf(decisionTree)
depth=countDepth(decisionTree)
feature=list(decisionTree.keys())[0] #提取当前树的第一个特征
subDict=decisionTree[feature] #提取该特征的子集,该子集可能是一个新的字典,那么就继续递归调用子集绘制图,否则该特征对应的子集为叶节点
#绘制特征以及该特征属性
cntrPt=(plotTree.xOff+(1.0+float(cntLeafs))/2.0/plotTree.totalW,plotTree.yOff) #根据整棵树的宽度深度计算当前子节点的绘制坐标
plotMidText(cntrPt,parentPt,nodeText) #绘制属性
plotNode(feature,cntrPt,parentPt,decisionNode) #绘制特征
#第一个特征绘制好之后,第二个特征的y坐标向下递减(因为自顶向下绘制,yOff初始值为1.0,然后y递减)
plotTree.yOff=plotTree.yOff-1.0/plotTree.totalD
#遍历当前树的第一个特征的各属性值,判断各属性值对应的子数据集是否为叶节点,是则绘制叶节点,否则递归调用plotTree(),直到找到叶节点
for key in subDict.keys():
if type(subDict[key]).__name__=="dict":
plotTree(subDict[key],cntrPt,str(key))
else:
plotTree.xOff=plotTree.xOff+1.0/plotTree.totalW #从左至右绘制,x初始值较小,然后x递增
plotNode(subDict[key],(plotTree.xOff,plotTree.yOff),cntrPt,leafNode)
plotMidText((plotTree.xOff,plotTree.yOff),cntrPt,str(key))
#在上述递归调用plotTree()的过程中,yOff会不断被减小
#当我们遍历完该特征的某属性值(即找到该属性分支的叶节点),开始对该特征下一属性值判断时,若无下面语句,则该属性对应的节点会从上一属性最小的yOff开始合理
#下面这行代码,作用是:在找到叶节点结束递归时,对yOff加值,保证下一次判断时的y起点与本次初始y一致
#若不理解,可以尝试注释掉下面这行语句,看看效果
plotTree.yOff=plotTree.yOff+1.0/plotTree.totalD
#绘图主函数
def createPlot(decisionTree):
fig=plt.figure(figsize=(10,10),facecolor="white")
fig.clf() #清空画布
axprops=dict(xticks=[],yticks=[]) #设置xy坐标轴的刻度,在[]中填充坐标轴刻度值,[]表示无刻度
# createPlot.ax1为全局变量,绘制图像的句柄,subplot为定义了一个绘图
#111表示figure中的图有1行1列,即1个,最后的1代表第一个图
# frameon表示是否绘制坐标轴矩形
createPlot.ax1=plt.subplot(111,frameon=False,**axprops)
plotTree.totalW=float(countLeaf(decisionTree)) #全局变量,整棵决策树的宽度
plotTree.totalD=float(countDepth(decisionTree))#全局变量,整棵决策树的深度
plotTree.xOff=-0.5/plotTree.totalW
plotTree.yOff=1.0
plotTree(decisionTree,(0.5,1.0),'')
plt.show()
下面我们用训练好的决策树测试一下绘制函数,激动人心的时刻到了
createPlot(my_tree)
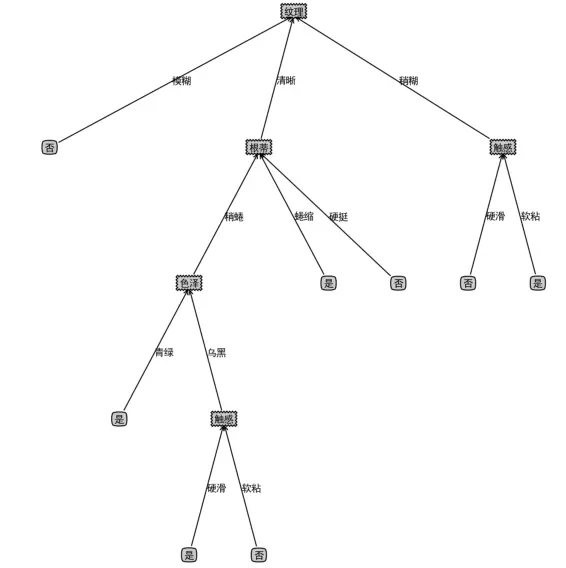
这就是我们训练的决策树,每个节点代表一个特征,节点连接的箭头属性代表该特征的属性值,比如特征(纹理)=属性值(清晰)
04 使用决策树执行分类
目前,我们能够训练决策树,能够绘制决策树了,但是决策树主要的作用还没有发挥出来。
分类决策树,作用在于利用训练好的决策树,对测试集数据进行分类。
下面我们就展示如何利用我们训练好的决策树对测试集进行分类。
中心思想:比较某条测试数据与决策树的数值,递归执行,直到找到某条测试数据的叶节点,然后该测试数据被分类为该叶节点分类
"""
输入:训练好的分类决策树、该决策树的特征列表、某条测试数据各特征属性值(顺序与决策树特征列表一致)
输出:该条测试数据的分类
思路:
比较某条测试数据与决策树的数值,递归执行,
直到找到某条测试数据的叶节点,然后该测试数据被分类为该叶节点分类
"""
def classifyDT(decisionTree,treeFeatures,testVec):
firstFeature=list(decisionTree.keys())[0]
subDict=decisionTree[firstFeature]
#寻找当前树最优特征在特征列表中的位置,便于定位测试数据集对于的特征位置
featureIndex=treeFeatures.index(firstFeature)
"""判断逻辑
遍历当前树最优特征各属性值
若测试数据对应位置的特征值与key一致,就在这个分支上找下去
若此特征属性值对应的分支不是叶节点,就递归调用自己,继续在此分支上下探寻找叶节点
若此特征属性值对应的分支是叶节点,就把该测试数据分类到该叶节点类别
"""
for key in list(subDict.keys()): #遍历当前树最优特征各属性值
if testVec[featureIndex]==key: #若测试数据对应位置的特征值与key一致,就在这个分支上找下去
if type(subDict[key]).__name__=="dict": #若此特征属性值对应的分支不是叶节点,就递归调用自己,继续在此分支上下探寻找叶节点
classLabel=classifyDT(subDict[key],treeFeatures,testVec)
else:
classLabel=subDict[key] #若此特征属性值对应的分支是叶节点,就把该测试数据分类到该叶节点类别
return classLabel
我们来测试一下,classifyDT(),第一个参数代表训练好的决策树,第二个参数代表决策树对应的特征列表,第三个参数就是训练集数据的特征属性了,这些属性要对应第二个参数的特征顺序。
classifyDT(my_tree,
['色泽', '根蒂', '敲声', '纹理', '脐部', '触感'],
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '软粘'])
预测结果: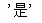
我们训练的决策树告诉我们,这颗待预测的西瓜,是一颗好瓜!
nice!
05 总结
本文给出了决策树绘制方法和决策树使用方法,中心思想都是递归。
本文训练决策树使用的算法是ID3,信息增益,这种算法只能处理离散型数据,且只能用于分类。如果之后有精力,我们会给出另一种决策树训练算法—CART算法,这种方法可以处理连续型数据,且还可以用于回归。
敬请期待~~
06 参考
- 《统计学习方法》 李航 Chapter5
- 《机器学习实战》 Peter Harrington Chapter3
最后
以上就是朴素月亮最近收集整理的关于决策树(Decision Tree) | 绘制决策树的全部内容,更多相关决策树(Decision内容请搜索靠谱客的其他文章。








发表评论 取消回复