我是靠谱客的博主 真实自行车,这篇文章主要介绍决策树(快递对账)第三步:使用分类决策树学习输入(出发省,目的省,订单重量)到输出(应付运费)的规则最后一步 存入数据库创作不易,点个关注在走吧!,现在分享给大家,希望可以做个参考。
决策树(快递对账)
第一步:快递账单导入delivery_fee
第二步:通过运单号将delivery_fee与raw_jst_invoice匹配
第三步:使用分类决策树学习输入(出发省,目的省,订单重量)到输出(应付运费)的规则
第四步:将运费对比结果导入delivery_fee_check
import pandas as pd
# 导入分类决策树
from sklearn.tree import DecisionTreeClassifier
import pymysql
# 导入cpca 可以将城市转换为省份的一个库
import cpca
file = "D:datas8月份快递账单.xlsx"
data = pd.read_excel(file,sheet_name = '工作表名称',skiprows= '跳过开始几行',skipfooter = '跳过结尾几行')
datas
这是打印:
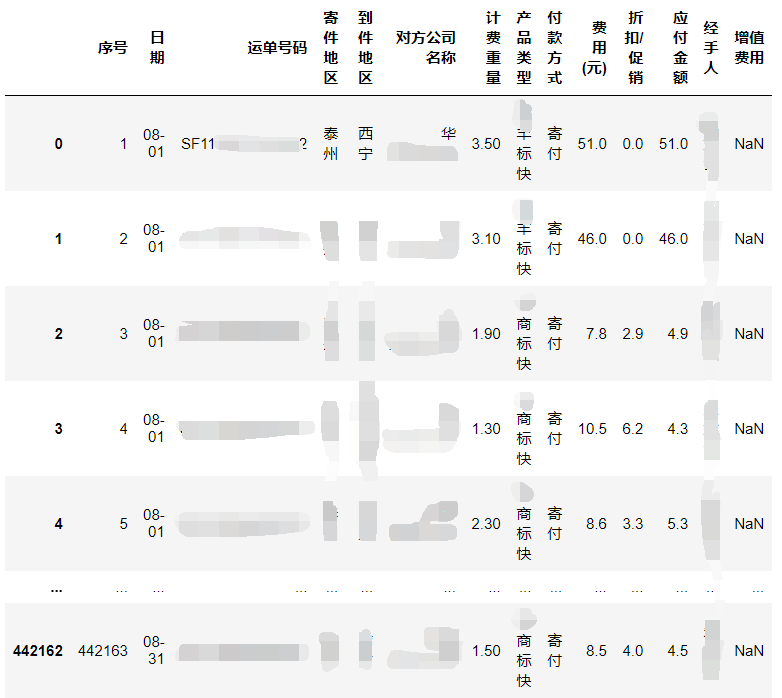
data.columns

data['日期'] = data['日期'].apply(lambda x:'2021-'+x)
data['fee_body'] = 'X化X丰'
data['send_province'] = None
data['receive_province'] = None
data2insert = data.loc[:,['fee_body','日期','运单号码','寄件地区','到件地区','计费重量','费用(元)','折扣/促销','应付金额','send_province','receive_province']]
data2insert.head()
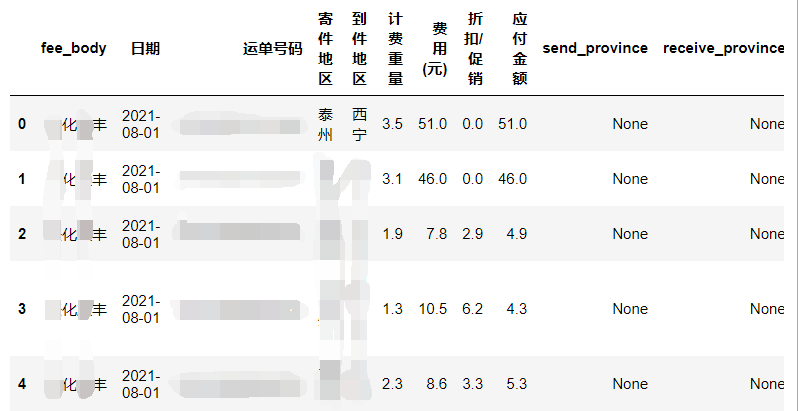
# 调用cpca库 将城市转化为省份
data2insert["send_province"] = cpca.transform(data2insert["寄件地区"])
data2insert["receive_province"] = cpca.transform(data2insert["到件地区"])
data2insert
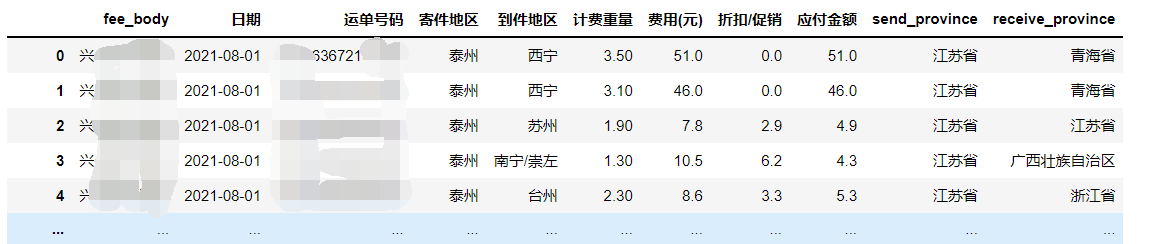
将账单导入数据库
con = pymysql.connect(host='',user='',password='',database='')
cr = con.cursor()
sql = 'REPLACE INTO `delivery_fee` VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
rows = [tuple(row) for row in data2insert.values]
try:
n = cr.executemany(sql,rows)
con.commit()
print(n,data.shape)
except Exception as e:
print(e)
con.rollback()
finally:
cr.close()
con.close()
和另一表做匹配 将另一张表的商品重量匹配上去
con = pymysql.connect(host='',user='',password='',database='')
sql = '''
SELECT DISTINCT d.*,
o.order_weight
FROM delivery_fee d JOIN raw_jst_invoice o ON d.d_id = o.delivery_id
WHERE fee_body = 'X化X丰'
AND ds >= '2021-8-1'
AND o.order_weight > 0
'''
d = pd.read_sql(sql,con)
con.close()
d

第三步:使用分类决策树学习输入(出发省,目的省,订单重量)到输出(应付运费)的规则
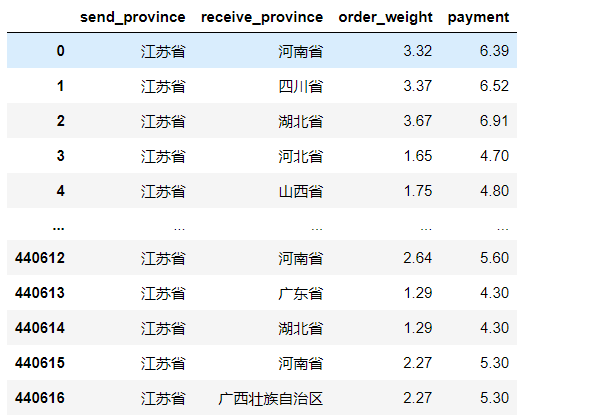
d = d.dropna(how='any')
train = d[['send_province','receive_province','order_weight','payment']].copy()
# 将读取出来的payment 保留一位小数
train.payment =train.payment.apply(lambda x:format(x,'.2f'))
train
# 将省转换为数字
for c in [0,1]:
dt = {j:i for i,j in enumerate(train.iloc[:,c].unique())}
print(dt)
train.iloc[:,c] = train.iloc[:,c].apply(lambda x:dt[x])
train
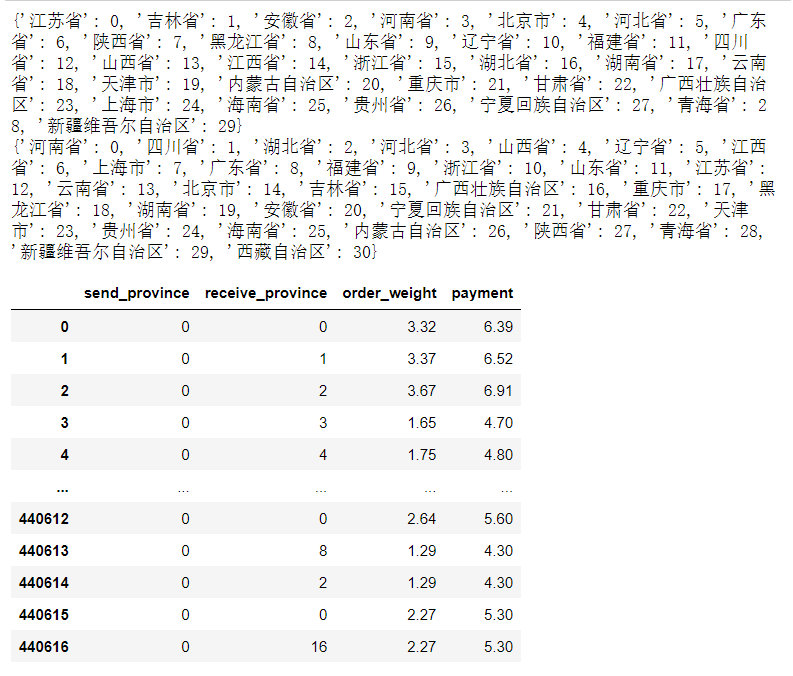
# 保留其 出发省 目的地 重量
x = train.values[:,0:-1]
# 金额(运费)
y = train.values[:,-1]
# 调用决策树
model = DecisionTreeClassifier()
# fit 在model本身作改变(让model去学习了一下)
model.fit(x,y)
# score 看下模型的结果和本身的结果有多少不一样的(准确率)
model.score(x,y)
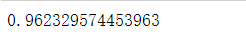
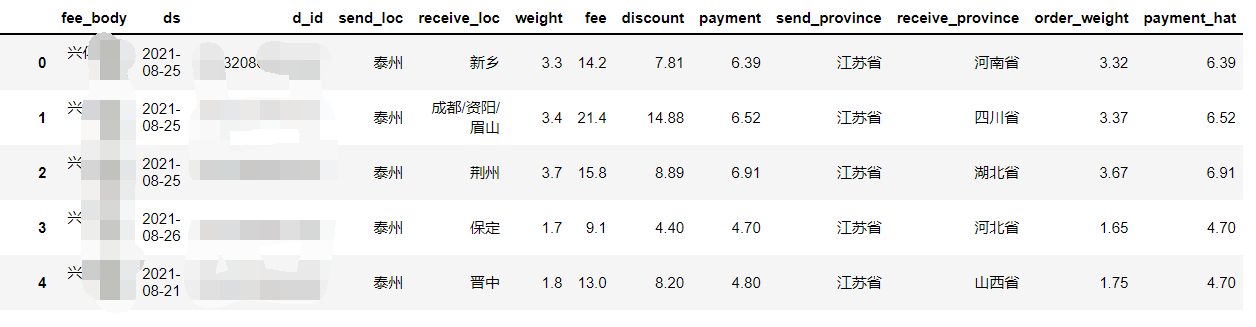
# predict根据x来预测运费 astype顺便转换成小数
d['payment_hat'] = model.predict(x).astype(float)
d
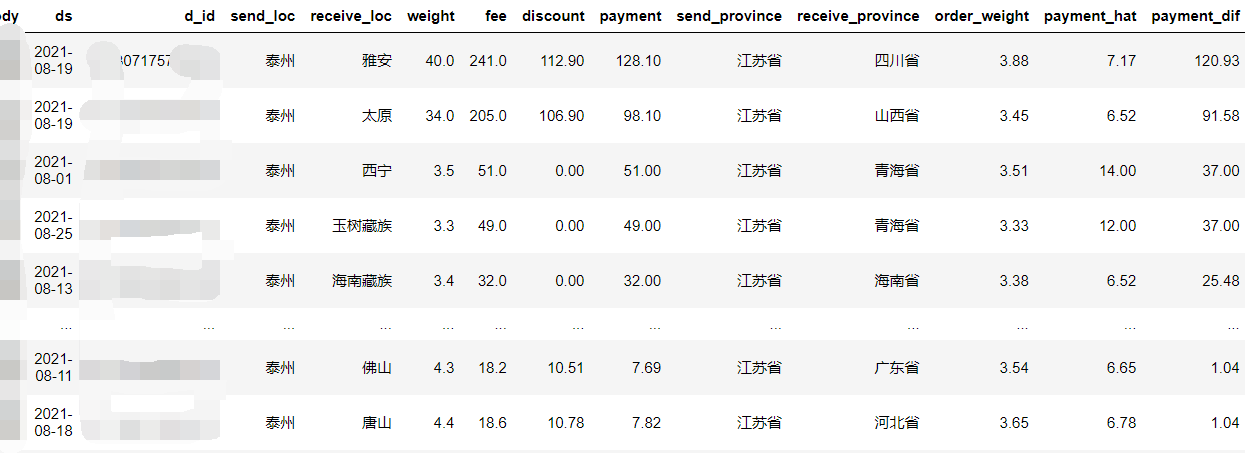
# 查看差异比较大的数据
d['payment_dif'] = d.payment.astype(float) - d.payment_hat.astype(float)
# sort_values 排序
# ascending 降序排序
d[d.payment_dif>1].sort_values(by='payment_dif',ascending=False)
最后一步 存入数据库
# 导入核算账单
con = pymysql.connect(host='',user='',password='',database='')
cr = con.cursor()
sql = 'REPLACE INTO `delivery_fee_check` VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
rows = [tuple(row) for row in d.iloc[:,:-1].values]
try:
n = cr.executemany(sql,rows)
con.commit()
print(n,d.shape)
except Exception as e:
print(e)
con.rollback()
finally:
cr.close()
con.close()
创作不易,点个关注在走吧!
最后
以上就是真实自行车最近收集整理的关于决策树(快递对账)第三步:使用分类决策树学习输入(出发省,目的省,订单重量)到输出(应付运费)的规则最后一步 存入数据库创作不易,点个关注在走吧!的全部内容,更多相关决策树(快递对账)第三步:使用分类决策树学习输入(出发省,目的省,订单重量)到输出(应付运费)的规则最后一步内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复