问题介绍
pip install sklearn进行安装,我本人使用的是笔记本进行实验(Windows系统)
- 安装sklearn,使用sklearn中的iris数据集,将iris数据集划分为训练集与测试集,以及对应的标签;
- 使用训练集数据训练决策树模型,其中决策树采用信息增益衡量分类的质量;
- 使用测试集数据测试已训练好的决策树模型,得到精确率、召回率与F1值。
文章目录
- 问题介绍
- 决策树的介绍
- 基尼系数和信息增益的介绍
- iris数据集介绍
- 基尼系数和信息增益决策树的训练与对比
- 实验结果展示
决策树的介绍
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
针对决策树来说根据其属性进行分类时会产生不同深度的树的结构,决策树的深度也并不是越深越好,因为如果深度过深会导致过拟合的现象出现,这时候选取的属性过多,他会把所有训练集中的样本进行有效的分类,把其中的一些无关紧要的影响也会考虑而失去了样本整体的特征,这时候再用测试集进行测试的时候就会造成分类效果不好的情况,所以有必要进行相应的剪枝来提高训练模型的泛化能力。
基尼系数和信息增益的介绍
基尼指数是经典决策树CART用于分类问题时选择最优特征的指标,基尼指数(Gini不纯度)表示在样本集合中一个随机选中的样本被分错的概率。Gini指数越小表示集合中被选中的样本被参错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为一个类时,基尼指数为0。其计算公式为
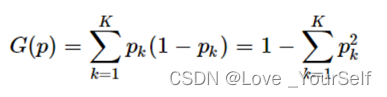
熵表示随机变量的不确定性,其公式为
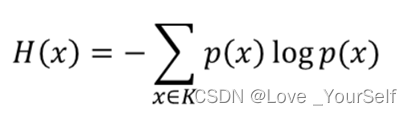
条件熵是在一个条件下,随机变量的不确定性,其公式为
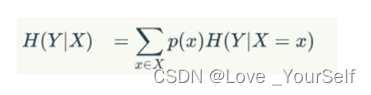
信息增益:熵 - 条件熵。表示在一个条件下,信息不确定性减少的程度。信息增益的计算要基于信息熵(度量样本集合纯度的指标)。构造决策树的时候选择信息增益作为指标的时候就是在选择特征的时候如果选择一个特征后,信息增益最大(信息不确定性减少的程度最大),那么我们就选取这个特征,这种使用信息增益作为判断选择哪个特征的指标的算法一般指ID3算法。
iris数据集介绍
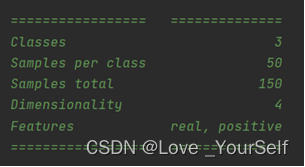
数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)这三种鸢尾花中的哪一品种。
下图显示的是在pycharm中查看sklearn包下面datasets下的load_iris函数之后显示的源码情况,这里展示了这个iris数据集的基本情况。然后将这150个数据集分为测试集和训练集,采用2:8的形式,测试集占20%,训练集占80%,可以使用sklearn中内置的函数,也可以自己设置数据集分配。
查看sklearn函数对于iris数据集的源码介绍
基尼系数和信息增益决策树的训练与对比
然后进行决策树的训练,在这个实验中我采用了两种方法的决策树的构建,一种是使用了信息增益当作特征选择的标准,还有一个是使用基尼系数作为特征选择的标准,然后查看使用这两个标准训练之后的决策树模型的效果,查看模型的准确性、召回率、F1-score等评价的参数值,然后进行对比。
使用sklearn中tree下的DecisionTreeClassifier函数设置决策树的一些分类器的参数,这里的criterion参数默认是gini,还可以设置为entropy,这时候为信息增益。为了对比两个参数对结果的影响,再设置一个分类器,比较两种分类器的效果,然后分别打印训练后的分类器性能指标。
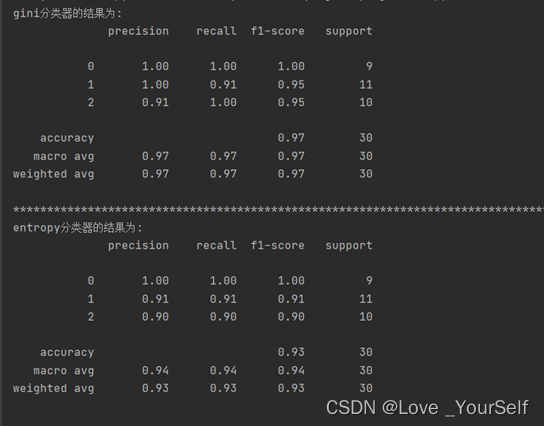
打印训练完成的分类器性能指标:使用测试集数据测试已训练好的决策树模型,得到P精确率、R召回率与F1值,这里的精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本;召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。F1是综合了这两个参数,F1=2PR/(P+R)。
# 加载数据集
iris = datasets.load_iris()
data_size = iris.data.shape[0] # {ndarray, dataframe} of shape (150, 4) The data matrix. If `as_frame=True`, `data` will be a pandas DataFrame.
index = [i for i in np.arange(data_size)]
random.shuffle(index) # 这里是将顺序打乱,因为在一开始的时候数据集是按类别顺序排列的
iris.data = iris.data[index]
iris.target = iris.target[index]
然后使用两种方式对数据集进行切分
#切分数据集
# method1:使用sklearn包中的函数进行切分
x_train,x_test,y_train,y_test = train_test_split(iris,iris.target,test_size = 0.2, random_state=0)
# method2:直接进行切分
test_size = int(data_size * 0.2) # 数据集的20%为测试集,80%为训练集
x_train = iris.data[test_size:]
x_test = iris.data[:test_size]
y_train = iris.target[test_size:]
y_test = iris.target[:test_size]
训练两个决策树分类器
# 进行决策树的训练
Classifier = tree.DecisionTreeClassifier(criterion="gini") # 这个是设置决策树的一些分类器的参数,这里的criterion参数为gini,默认也是gini,还可以设置为entropy,这时候为信息增益
Classifier.fit(X=x_train, y=y_train)
y_predict = Classifier.predict(x_test)
Classifier2 = tree.DecisionTreeClassifier(criterion="entropy") # 为了对比两个参数对结果的影响,再设置一个分类器,比较两种分类器的效果
Classifier2.fit(X=x_train, y=y_train)
y_predict2 = Classifier2.predict(x_test)
实验结果展示
经过实验结果显示,在这个数据集上此次实验gini作为特征选择的标准较entropy更好,其各项性能指标都较优。
最后
以上就是刻苦刺猬最近收集整理的关于基于决策树进行分类问题介绍决策树的介绍基尼系数和信息增益的介绍iris数据集介绍基尼系数和信息增益决策树的训练与对比实验结果展示的全部内容,更多相关基于决策树进行分类问题介绍决策树内容请搜索靠谱客的其他文章。








发表评论 取消回复