决策树
决策树是一种基本的分类与回归方法,它可以被认为是一种if-then规则的集合。决策树由节点和有向边组成,内部节点代表了特征属性,外部节点(叶子节点)代表了类别。
目录
决策树
决策树的构建过程
计算数据集的经验熵和如何选择最优特征作为分类特征的代码
决策树实战篇——为自己配个隐形眼镜
ID3、C4.5&CART算法
ID3算法
Random Forest
GBDT
参考链接
决策树根据一步步地属性分类可以将整个特征空间进行划分,从而区别出不同的分类样本,如下图所示: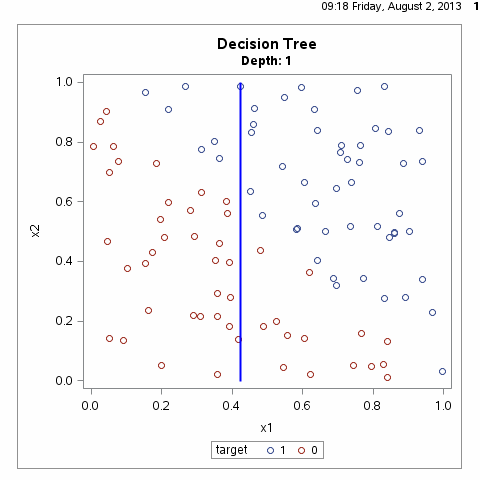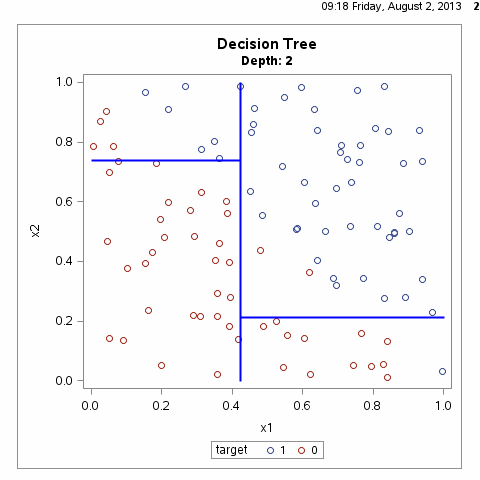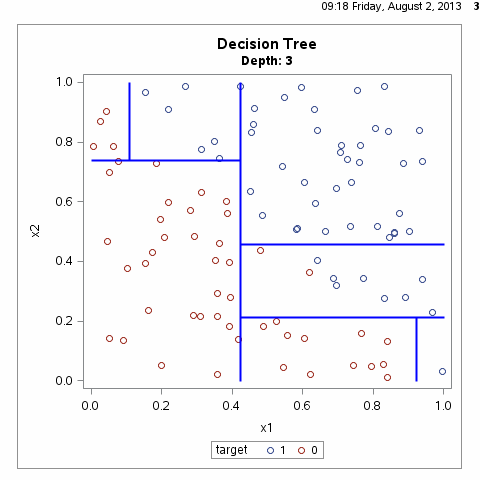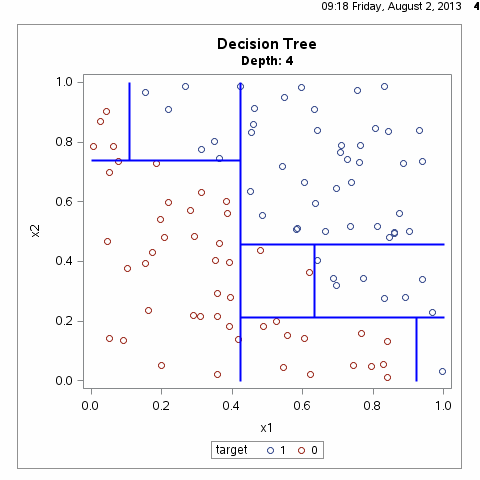
根据上图其实我们不难可以想到,满足样本划分的决策树有无数种,什么样的决策树才算是一颗好的决策树呢?性能良好的决策树的选择标准是一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。言外之意就是说,好的决策树不仅对训练样本有着很好的分类效果,对于测试集也有着较低的误差率。
决策树的构建过程
推导见https://blog.csdn.net/u014688145/article/details/53212112
决策树学习通常包括3个步骤:
1.特征选择
2.决策树的生成
3.决策树的修剪
这些决策树学习的思想主要来源于由Quinlan在1986年提出的ID3算法和1993年提出的C4.5算法,以及由Breiman等人在1984年提出的CART算法。
其实不同的决策树学习算法只是它们选择特征的依据不同,决策树的生成过程都是一样的(根据当前环境对特征进行贪婪的选择)。
计算数据集的经验熵和如何选择最优特征作为分类特征的代码
参考链接:https://blog.csdn.net/c406495762/article/details/75663451
from math import log
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
Author:
Jack Cui
Modify:
2017-03-29
"""
def calcShannonEnt(dataSet):
numEntires = len(dataSet) #返回数据集的行数
labelCounts = {} #保存每个标签(Label)出现次数的字典
for featVec in dataSet: #对每组特征向量进行统计
currentLabel = featVec[-1] #提取标签(Label)信息
if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
for key in labelCounts: #计算香农熵
prob = float(labelCounts[key]) / numEntires #选择该标签(Label)的概率
shannonEnt -= prob * log(prob, 2) #利用公式计算
return shannonEnt #返回经验熵(香农熵)
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 分类属性
Author:
Jack Cui
Modify:
2017-07-20
"""
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] #分类属性
return dataSet, labels #返回数据集和分类属性
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
Author:
Jack Cui
Modify:
2017-03-30
"""
def splitDataSet(dataSet, axis, value):
retDataSet = [] #创建返回的数据集列表
for featVec in dataSet: #遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #去掉axis特征
reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集
retDataSet.append(reducedFeatVec)
return retDataSet #返回划分后的数据集
"""
函数说明:选择最优特征
Parameters:
dataSet - 数据集
Returns:
bestFeature - 信息增益最大的(最优)特征的索引值
Author:
Jack Cui
Modify:
2017-03-30
"""
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数量
baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵
bestInfoGain = 0.0 #信息增益
bestFeature = -1 #最优特征的索引值
for i in range(numFeatures): #遍历所有特征
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) #创建set集合{},元素不可重复
newEntropy = 0.0 #经验条件熵
for value in uniqueVals: #计算信息增益
subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率
newEntropy += prob * calcShannonEnt(subDataSet) #根据公式计算经验条件熵
infoGain = baseEntropy - newEntropy #信息增益
print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益
if (infoGain > bestInfoGain): #计算信息增益
bestInfoGain = infoGain #更新信息增益,找到最大的信息增益
bestFeature = i #记录信息增益最大的特征的索引值
return bestFeature #返回信息增益最大的特征的索引值
if __name__ == '__main__':
dataSet, features = createDataSet()
print("最优特征索引值:" + str(chooseBestFeatureToSplit(dataSet)))决策树实战篇——为自己配个隐形眼镜
参考链接:https://blog.csdn.net/c406495762/article/details/76262487
from math import log
import operator
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-24
"""
def calcShannonEnt(dataSet):
numEntires = len(dataSet) #返回数据集的行数
labelCounts = {} #保存每个标签(Label)出现次数的字典
for featVec in dataSet: #对每组特征向量进行统计
currentLabel = featVec[-1] #提取标签(Label)信息
if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
for key in labelCounts: #计算香农熵
prob = float(labelCounts[key]) / numEntires #选择该标签(Label)的概率
shannonEnt -= prob * log(prob, 2) #利用公式计算
return shannonEnt #返回经验熵(香农熵)
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 特征标签
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-20
"""
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] #特征标签
return dataSet, labels #返回数据集和分类属性
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-24
"""
def splitDataSet(dataSet, axis, value):
retDataSet = [] #创建返回的数据集列表
for featVec in dataSet: #遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #去掉axis特征
reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集
retDataSet.append(reducedFeatVec)
return retDataSet #返回划分后的数据集
"""
函数说明:选择最优特征
Parameters:
dataSet - 数据集
Returns:
bestFeature - 信息增益最大的(最优)特征的索引值
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-20
"""
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数量
baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵
bestInfoGain = 0.0 #信息增益
bestFeature = -1 #最优特征的索引值
for i in range(numFeatures): #遍历所有特征
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) #创建set集合{},元素不可重复
newEntropy = 0.0 #经验条件熵
for value in uniqueVals: #计算信息增益
subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率
newEntropy += prob * calcShannonEnt(subDataSet) #根据公式计算经验条件熵
infoGain = baseEntropy - newEntropy #信息增益
# print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益
if (infoGain > bestInfoGain): #计算信息增益
bestInfoGain = infoGain #更新信息增益,找到最大的信息增益
bestFeature = i #记录信息增益最大的特征的索引值
return bestFeature #返回信息增益最大的特征的索引值
"""
函数说明:统计classList中出现此处最多的元素(类标签)
Parameters:
classList - 类标签列表
Returns:
sortedClassCount[0][0] - 出现此处最多的元素(类标签)
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-24
"""
def majorityCnt(classList):
classCount = {}
for vote in classList: #统计classList中每个元素出现的次数
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序
return sortedClassCount[0][0] #返回classList中出现次数最多的元素
"""
函数说明:创建决策树
Parameters:
dataSet - 训练数据集
labels - 分类属性标签
featLabels - 存储选择的最优特征标签
Returns:
myTree - 决策树
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-25
"""
def createTree(dataSet, labels, featLabels):
classList = [example[-1] for example in dataSet] #取分类标签(是否放贷:yes or no)
if classList.count(classList[0]) == len(classList): #如果类别完全相同则停止继续划分
return classList[0]
if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类标签
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat] #最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
del(labels[bestFeat]) #删除已经使用特征标签
featValues = [example[bestFeat] for example in dataSet] #得到训练集中所有最优特征的属性值
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征,创建决策树。
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels)
return myTree
if __name__ == '__main__':
dataSet, labels = createDataSet()
featLabels = []
myTree = createTree(dataSet, labels, featLabels)
print(myTree)ID3、C4.5&CART算法
ID3算法的核心是在决策树各个节点上应用信息增益准则选择特征,每一次都选择使得信息增益最大的特征进行分裂,递归地构建决策树。
ID3算法以信息增益作为划分训练数据集的特征,有一个致命的缺点。选择取值比较多的特征往往会具有较大的信息增益,所以ID3偏向于选择取值较多的特征。
针对ID3算法的不足,C4.5算法根据信息增益比来选择特征,对这一问题进行了校正。
CART指的是分类回归树,它既可以用来分类,又可以被用来进行回归。CART用作回归树时用平方误差最小化作为选择特征的准则,用作分类树时采用基尼指数最小化原则,进行特征选择,递归地生成二叉树。
决策树的剪枝:我们知道,决策树在生成的过程中采用了贪婪的方法来选择特征,从而达到对训练数据进行更好地拟合(其实从极端角度来看,决策树对训练集的拟合可以达到零误差)。而决策树的剪枝是为了简化模型的复杂度,防止决策树的过拟合问题。具体的决策树剪枝策略可以参见李航的《统计学习方法》。
ID3算法
输入:训练数据集D,特征集A,阈值ϵ
输出:决策树T
(1) 若D中所有实例属于同一类Ck,则T为单结点树,并将类Ck作为该结点的类标记,返回T;
(2) 若A=∅,则T为单结点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T;
(3) 否则,计算A中各特征对D的信息增益,选择信息增益最大的特征Ag;
(4) 如果Ag的信息增益小于阈值ϵ,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T;
(5) 否则,对Ag的每一个可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6) 对第i个子子结点,以Di为训练集,以 A−{Ag}为特征集,递归地调用步(1)~(5),得到子树Ti,返回Ti;
C4.5算法
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多特征的问题。使用信息增益比可以对这一问题进行校正。这是特征选择的另一准则。
输入:训练数据集D,特征集A,阈值ϵ
输出:决策树T
(1) 若D中所有实例属于同一类Ck,则T为单结点树,并将类Ck作为该结点的类标记,返回T;
(2) 若A=∅,则T为单结点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T;
(3) 否则,计算A中各特征对D的信息增益比,选择信息增益比最大的特征Ag;
(4) 如果Ag的信息增益小于阈值ϵ,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T;
(5) 否则,对Ag的每一个可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6) 对第i个子子结点,以Di为训练集,以 A−{Ag}为特征集,递归地调用步(1)~(5),得到子树Ti,返回Ti;
Random Forest
随机森林是一种集成学习+决策树的分类模型,它可以利用集成的思想(投票选择的策略)来提升单颗决策树的分类性能(通俗来讲就是“三个臭皮匠,顶一个诸葛亮”)。
集集成学习和决策树于一身,随机森林算法具有众多的优点,其中最为重要的就是在随机森林算法中每棵树都尽最大程度的生长,并且没有剪枝过程。
随机森林引入了两个随机性——随机选择样本(bootstrap sample)和随机选择特征进行训练。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
有关随机森林的详细介绍可以参见之前的一篇博文《随机森林(Random Forest)》。
GBDT
迭代决策树GBDT(Gradient Boosting Decision Tree)也被称为是MART(Multiple Additive Regression Tree))或者是GBRT(Gradient Boosting Regression Tree),也是一种基于集成思想的决策树模型,但是它和Random Forest有着本质上的区别。不得不提的是,GBDT是目前竞赛中最为常用的一种机器学习算法,因为它不仅可以适用于多种场景,更难能可贵的是,GBDT有着出众的准确率。这也是为什么很多人称GBDT为机器学习领域的“屠龙刀”。
这么牛叉的算法,到底是怎么做到的呢?说到这里,就不得不说一下GBDT中的“GB”(Gradient Boosting)。Gradient Boosting的原理相当的复杂,但是看不懂它也不妨碍我们对GBDT的理解和认识,有关Gradient Boosting的详细解释请见wiki百科。
在这里引用另外一个网友的解释来说明一下对GBDT中的Gradient Boosting的理解:
以下一段内容引自《GBDT(MART) 迭代决策树入门教程 | 简介》。
“Boosting,迭代,即通过迭代多棵树来共同决策。这怎么实现呢?难道是每棵树独立训练一遍,比如A这个人,第一棵树认为是10岁,第二棵树认为是0岁,第三棵树认为是20岁,我们就取平均值10岁做最终结论?当然不是!且不说这是投票方法并不是GBDT,只要训练集不变,独立训练三次的三棵树必定完全相同,这样做完全没有意义。之前说过,GBDT是把所有树的结论累加起来做最终结论的,所以可以想到每棵树的结论并不是年龄本身,而是年龄的一个累加量。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义。”
其实从这里我们可以看出GBDT与Random Forest的本质区别,GBDT不仅仅是简单地运用集成思想,而且它是基于对残差的学习的。我们在这里利用一个GBDT的经典实例进行解释。
假设我们现在有一个训练集,训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图1所示结果:
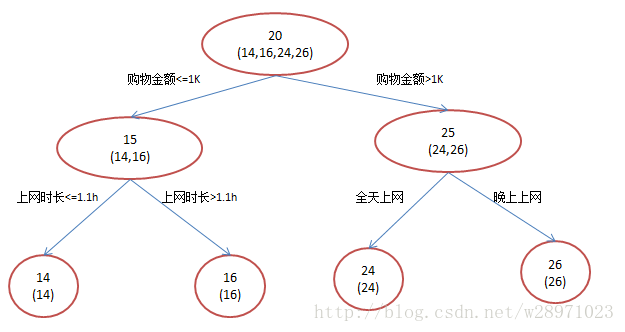
现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图2所示结果:
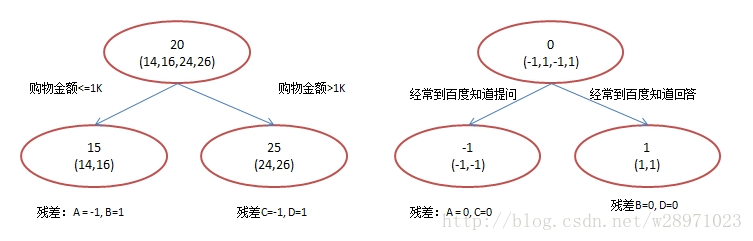
在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是我可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
换句话说,现在A,B,C,D的预测值都和真实年龄一致了。Perfect!:
A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26
那么哪里体现了Gradient呢?其实回到第一棵树结束时想一想,无论此时的cost function是什么,是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。
注:图1和图2 最终效果相同,为何还需要GBDT呢?答案是过拟合。过拟合是指为了让训练集精度更高,学到了很多“仅在训练集上成立的规律”,导致换一个数据集当前规律就不适用了。只要允许一棵树的叶子节点足够多,训练集总是能训练到100%准确率的。在训练精度和实际精度(或测试精度)之间,后者才是我们想要真正得到的。我们发现图1为了达到100%精度使用了3个feature(上网时长、时段、网购金额),其中分枝“上网时长>1.1h” 很显然已经过拟合了,这个数据集上A,B也许恰好A每天上网1.09h, B上网1.05小时,但用上网时间是不是>1.1小时来判断所有人的年龄很显然是有悖常识的;相对来说图2的boosting虽然用了两棵树 ,但其实只用了2个feature就搞定了,后一个feature是问答比例,显然图2的依据更靠谱。
可见,GBDT同随机森林一样,不容易陷入过拟合,而且能够得到很高的精度。
补充实例(2015-10-7)
在此引用李航博士《统计学习方法》中提升树的实例来进一步阐述GBDT的详细流程。
一直认为李航博士讲的机器学习更加贴近算法的本质,我们先来看一下他是如何对GBDT进行定义的(在《统计学习方法中》,GBDT又被称为是提升树boosting tree)。
提升方法实际采用了加法模型(即基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树,对分类问题决策树是二叉分类树,而对于回归问题决策树是二叉回归树。提升树模型可以表示为决策树的加法模型:
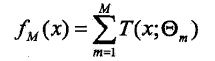
其中,![]() 表示决策树;
表示决策树;![]() 表示决策树的参数;M为树的个数。
表示决策树的参数;M为树的个数。
针对不同问题的提升树(GBDT),其主要区别在于使用的损失函数不同,包括用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及用一般损失函数的一般决策问题。
提升树的流程:

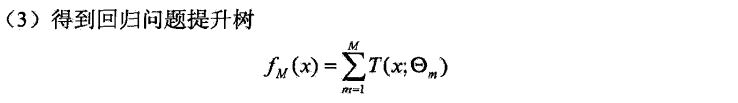
下面我们通过一个实例来透彻地来看一下提升树(GDBT)到底是怎样一步一步解决问题的。





参考链接
[1]http://www.cnblogs.com/maybe2030/p/4734645.html
最后
以上就是自然石头最近收集整理的关于Machine Learning学习笔记(五)决策树与迭代决策树决策树的全部内容,更多相关Machine内容请搜索靠谱客的其他文章。








发表评论 取消回复