大数据分析Python除了循环遍历列表之外,for循环还有很多其他功能,在现实世界的数据科学工作中,您可能需要将numpy数组和pandas DataFrames用于其他数据结构的循环。
大数据分析Python For循环教程以如何使用for循环遍历列表以外的常见大数据分析Python数据结构(如元组和字典)开始。然后,我们将深入探讨与普通的大数据分析Python数据科学图书馆像串联使用for循环numpy,pandas和matplotlib。我们还将仔细研究该range()函数及其在编写循环时的作用。
快速回顾:大数据分析Python For循环
for循环是一条编程语句,它告诉大数据分析Python遍历对象集合,并对每个对象依次执行相同的操作。基本语法为:

每次大数据分析Python遍历循环时,变量object都会采用序列中下一个对象的值collection_of_objects,并且大数据分析Python将按顺序执行我们在每个对象上编写的代码collection_of_objects。
现在,让我们深入研究如何使用具有不同种类的数据结构的循环。我们将跳过列表,因为上一教程已经介绍过这些列表。如果您需要进一步检查,请在列表和循环中查看入门教程或Dataquest的交互式任务。
数据结构
元组
元组是序列,就像列表一样。元组和列表之间的区别在于元组是不可变的。也就是说,它们不能更改(了解有关大数据分析Python中可变和不可变对象的更多信息)。元组还使用括号代替方括号。
不管这些差异如何,在元组上循环与列表非常相似。
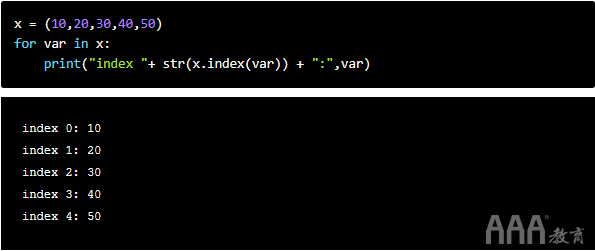
如果我们有一个元组列表,则可以通过将它们都作为变量包含在for循环中来访问列表中每个元组中的各个元素,如下所示:
辞典
除了列表和元组,字典是您在处理数据时可能会遇到的另一种常见的大数据分析Python数据类型,并且for循环也可以遍历字典。
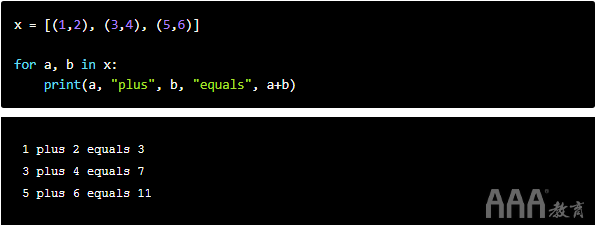
大数据分析Python字典由键值对组成,因此在每个循环中,我们需要访问两个元素(键和值)。与其enumerate()像使用列表那样使用,不如遍历两个键和每个键值对的对应值,我们需要调用该.items()方法。
例如,假设我们有一个名为“字典”的字典stocks,其中包含股票行情自动收录器和相应的股票价格。我们将使用.items()字典上的方法为每次迭代生成键和值:
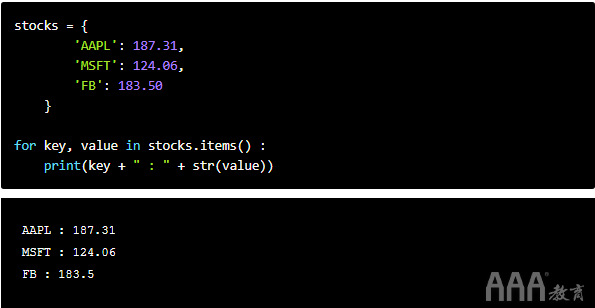
请注意,名称键和值完全是任意的。我们也可以将它们标记为k和v或x和y。
弦乐
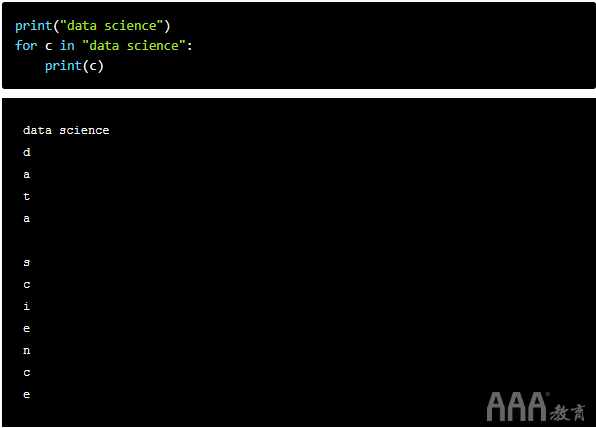
如入门教程中所述,for循环还可以遍历字符串中的每个字符。快速回顾一下,这是如何工作的:
numpy数组
现在,让我们看一下常见的大数据分析Python数据科学包及其数据类型如何使用for循环。
我们将从研究如何使用numpy数组循环开始,因此让我们从创建一些随机数数组开始。

在一维numpy数组上进行迭代与在列表上进行迭代非常相似:

现在,如果我们要遍历二维数组怎么办?如果我们使用与上面相同的语法来迭代二维数组,则每次迭代只能迭代整个数组。
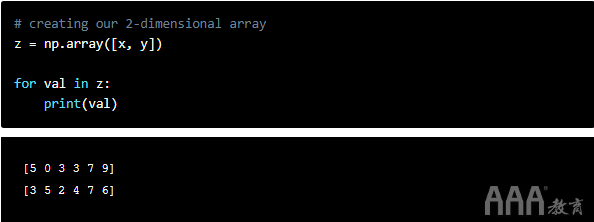
二维数组是由一对一维数组构成的。要访问每个元素而不是每个数组,我们可以使用numpy函数nditer(),它是一个以数组作为参数的多维迭代器对象。
在下面的代码中,我们将编写一个for循环,该循环将z二维数组作为参数 传递给每个元素nditer():
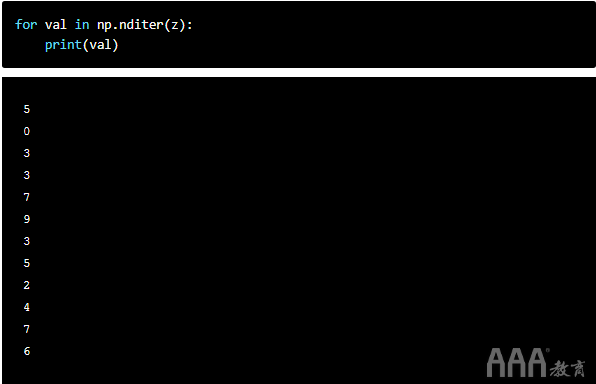
如我们所见,这首先列出了x中的所有元素,然后列出了y中的所有元素。
记得!当遍历这些不同的数据结构时,字典需要一个方法,numpy数组需要一个function。
熊猫数据框
当我们使用大数据分析Python处理数据时,我们经常使用pandasDataFrames。值得庆幸的是,我们也可以使用for循环遍历那些循环。
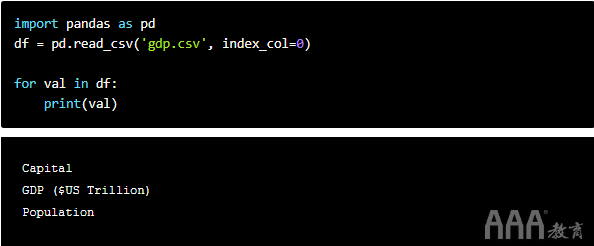
让我们练习使用一个小的CSV文件进行练习,该文件记录六个不同国家的GDP,首都和人口。我们将在下面将其读入pandas DataFrame中。
熊猫的工作方式与numpy有所不同,因此我们将无法简单地重复已经学习的numpy过程。如果我们像遍历一个numpy数组一样尝试遍历pandas DataFrame,则只会打印出列名:
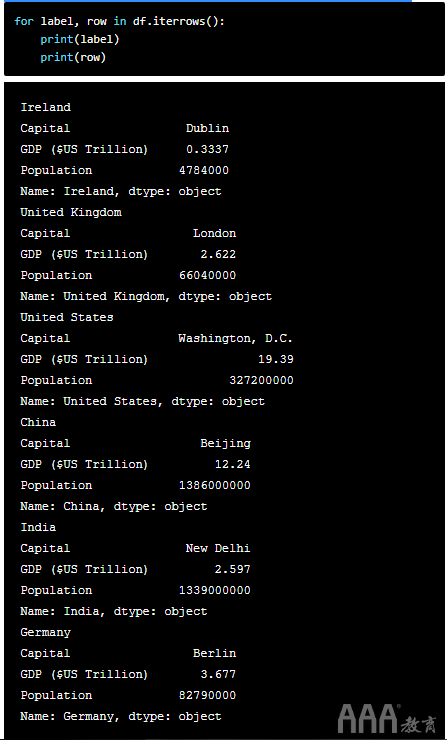
相反,我们需要明确提及我们要遍历DataFrame的行。为此,我们iterrows()在DataFrame上调用方法,并打印行标签和行数据,其中一行是整个熊猫系列。
我们还可以从熊猫系列访问特定值。假设我们只想打印出每个国家的首都。我们可以指定仅希望从“ Capital”列中输出,如下所示:
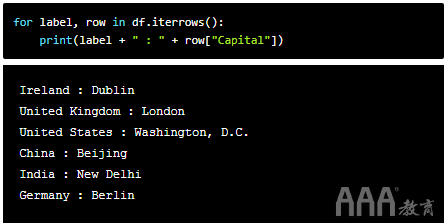
为了使事情比简单的打印输出更进一步,让我们使用for循环添加一列。让我们添加“人均GDP”列。请记住,这.loc[]是基于标签的。在下面的代码中,我们将添加该列并通过将每个国家的总GDP除以其人口并将结果乘以一万亿来计算每个国家的内容(因为GDP的数字以万亿为单位)。
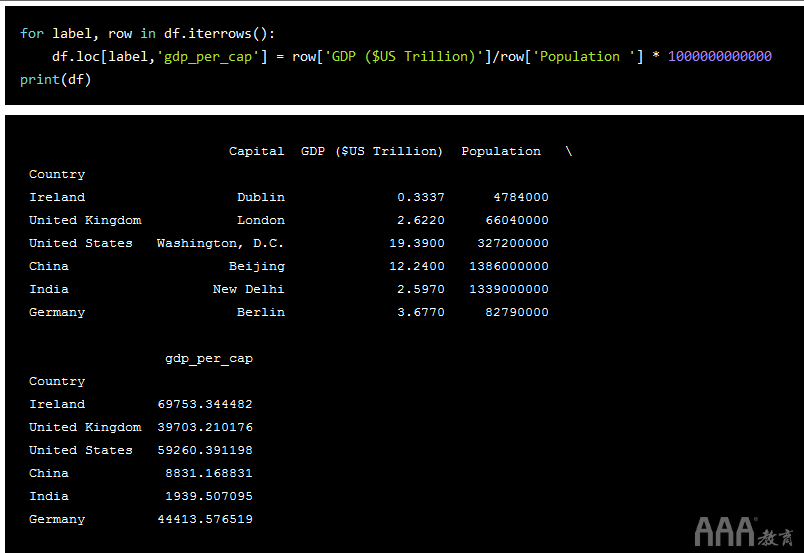
对于数据框中的每一行,我们将创建一个新标签,并将行数据设置为等于GDP总量除以该国人口,再乘以$ 1T得出数千美元。
该range()功能
我们已经看到了如何使用for循环迭代任何序列或数据结构。但是,如果我们想以特定顺序或特定次数迭代这些序列,该怎么办?
这可以通过大数据分析Python的内置range()函数来完成。根据传递给该函数的参数数量,您可以确定该系列数字将在哪里开始和结束以及一个数字与下一个数字之间的差值有多大。请注意,类似于列表,range()函数的计数从0开始而不是从1开始。
我们可以通过三种方式致电range():
a.范围(停止)
b.范围(开始,停止)
c.范围(开始,停止,步进)
range(stop)
range(stop)有一个参数,当我们要迭代从0开始的一系列数字时使用,并包括直到但不包括我们设置为stop的数字的每个数字。

range(start, stop)
range(start,stop)有两个参数,我们不仅可以设置序列的结尾,还可以设置起点。您可以使用range()使用range(A,B)生成从A到B的一系列数字。

range(start, stop, step)
range(开始,停止,步进)采用三个参数。除了最小值和最大值之外,我们还可以设置序列中一个数字与下一个数字之间的差。如果未提供,则默认步进值为1。
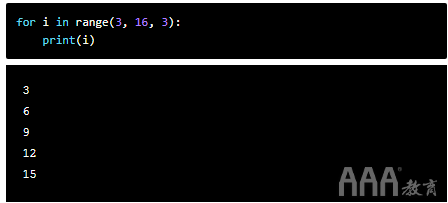
请注意,这对于非数字序列也是如此。
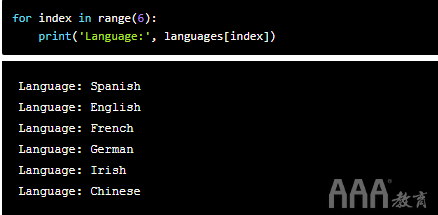
我们还可以使用序列中元素的索引进行迭代。关键思想是首先计算列表的长度,然后在此长度范围内迭代序列。让我们看一个例子:
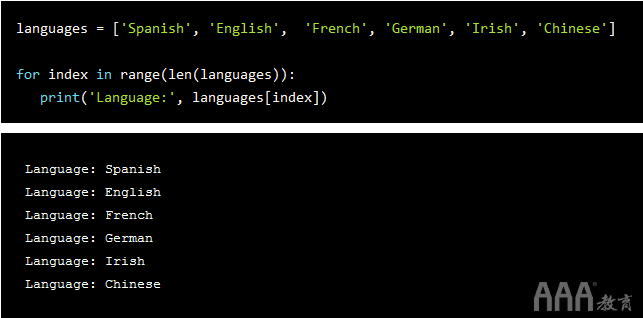
在上面的for循环中,我们查看变量的索引和语言,in关键字以及range()创建数字序列的函数。请注意,我们也使用len()在这种情况下,函数,因为列表不是数字。
对于每次迭代,我们都在执行我们的打印语句。因此,对于len(languages)范围内的每个索引,我们都希望打印一种语言。因为我们的语言序列的长度是6(即计算得出的len(langauges)值),所以我们可以按以下方式重写语句:
用For循环绘制
假设我们要遍历一个集合,并使用每个元素来生成一个子图,甚至是单个图中的每个迹线。例如,让我们采用流行的虹膜数据集(了解有关此数据的更多信息)并使用for循环进行一些绘制。考虑下图。
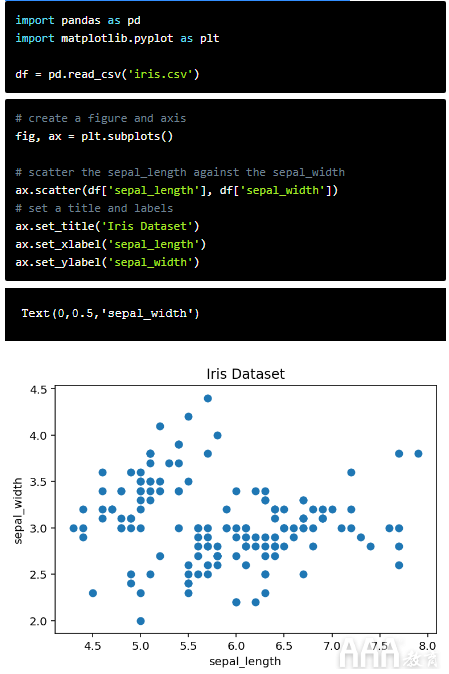
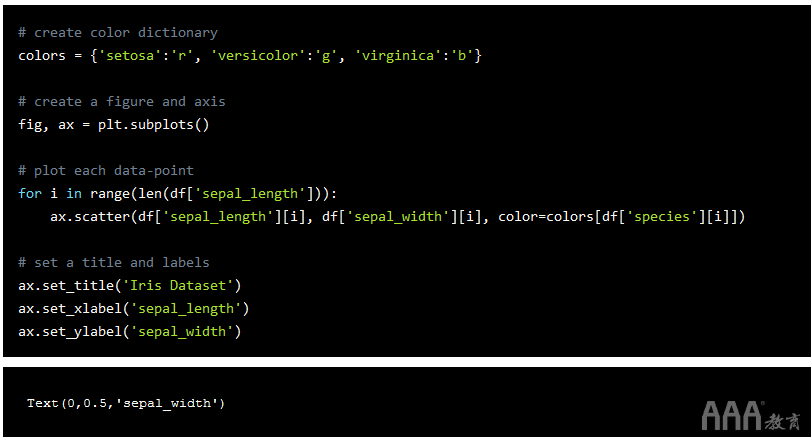
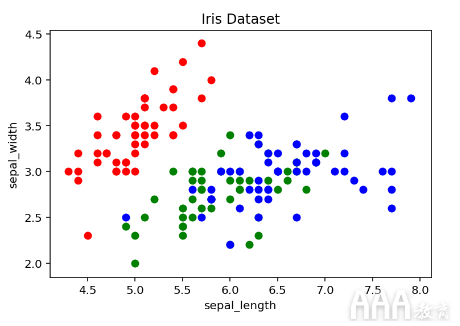
上面,我们绘制了每个萼片长度与萼片宽度的关系图,但是我们可以通过在每个数据点上按每种花的种类分类给图赋予更多的含义。一种方法是通过使用for循环将每个点单独散布并传入相应的颜色。
如果我们想可视化虹膜数据集某些特征的单变量分布怎么办?我们可以使用来执行此操作plt.subplot(),它可以在网格内创建一个子图,可以设置其列数和行数。
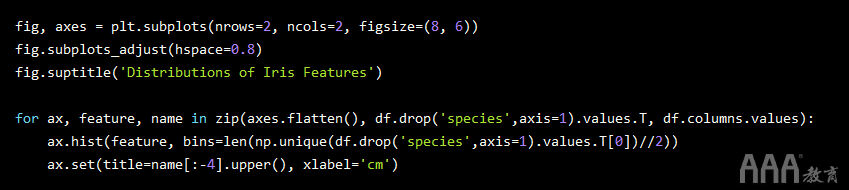
暂时不深入了解matplotlib语法,以下是对图的每个主要组件的简要说明:
1)plt.subplot()–用于创建我们的2×2网格并设置整体大小。
2)zip()–这是一个内置的大数据分析Python函数,使同时循环遍历相同长度的多个可迭代对象变得非常简单。
3)axes.flatten(),其中flatten()是一种numpy数组方法–这将返回我们数组(列)的展平版本。
4)ax.set()–允许我们axes使用一个方法设置对象的所有属性。
附加操作
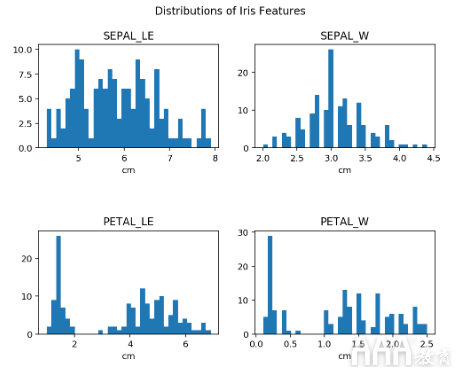
嵌套循环
大数据分析Python允许我们在另一个循环中使用一个循环。这涉及到一个外部循环,该循环在其命令内部具有一个内部循环。
考虑以下结构:
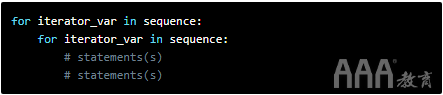
嵌套的for循环对于在由列表组成的列表中的项目之间进行迭代很有用。在一个由列表组成的列表中,如果我们仅使用一个for循环,则程序会将每个内部列表作为一项输出:
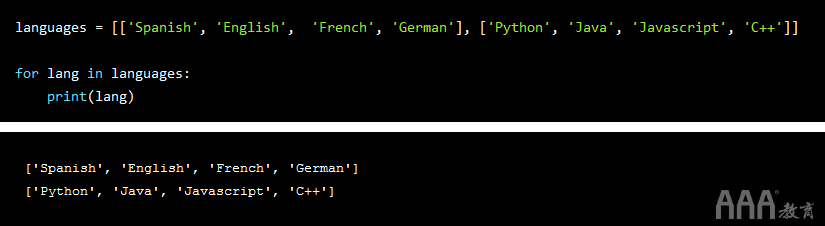
为了访问内部列表的每个单独项,我们定义了一个嵌套的for循环:
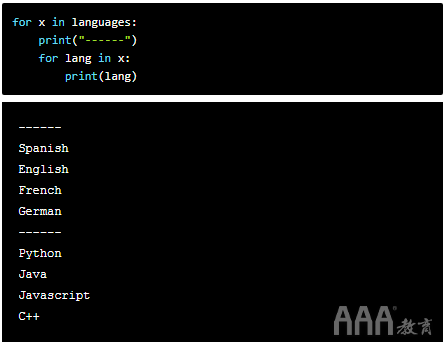
在上方,外部for循环遍历主列表列表(在此示例中包含两个列表),内部for循环遍历各个列表本身。外循环执行2次迭代(针对每个子列表),并且在每次迭代时,我们执行内循环,打印相应子列表的所有元素。
这告诉我们控件从最外层循环开始,遍历内层循环,然后再次返回到外层for循环,一直持续到控件覆盖整个范围为止,在这种情况下,该范围是2倍。
继续和打破循环
循环控制语句从其正常顺序更改for循环的执行。
如果我们想在内部循环中滤除特定语言怎么办?我们可以使用continue语句来执行此操作,这使我们可以在触发外部条件时跳过循环的特定部分。
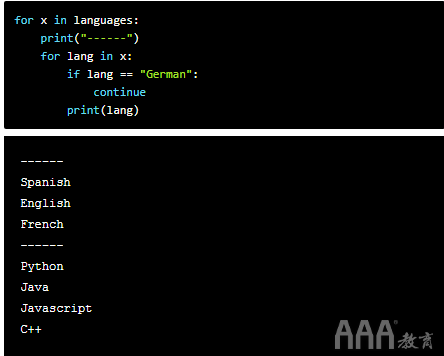
在上面的循环中,在内层循环中,如果语言等于“德语”,我们将仅跳过该迭代,并继续循环的其余部分。循环不会终止。
让我们看下面的数字示例:
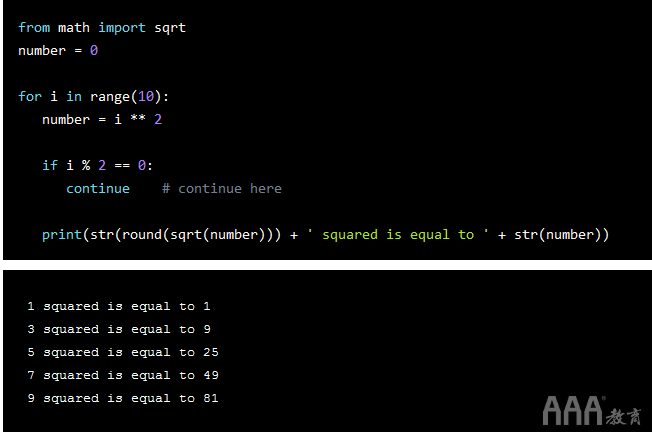
因此,在这里,我们定义了一个循环,该循环遍历所有数字0到9,并对每个数字求平方。在循环中,在每次迭代中,我们都在检查数字是否可被2整除,这时循环将继续执行,当我求出偶数时,将跳过该迭代。
怎么样一个break语句?这使我们可以在满足外部条件时完全退出循环。让我们使用与上面相同的示例来简单演示其工作原理:
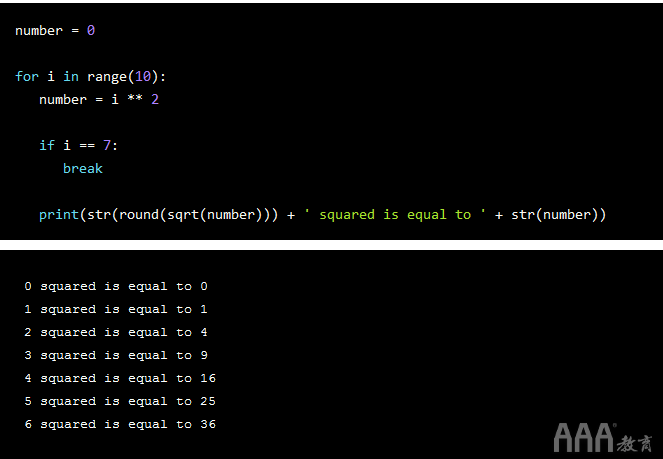
在上面的示例中,我们的if语句提出了以下条件:如果我们的变量i的值等于7,则循环将中断,因此我们的循环将在0到6之间对整数进行迭代,然后再完全退出循环。
寻找更多?以下是一些可能有用的其他资源:
1)大数据分析Python教程 —我们不断扩展的数据科学大数据分析Python教程列表。
2)数据科学课程 -直接在浏览器中通过完全交互式的编程,数据科学和统计课程将您的学习提升到一个新的水平。
结论
在大数据分析Python For循环教程中,我们了解了for循环的一些更高级的应用程序,以及如何在典型的大数据分析Python数据科学工作流中使用它们。
我们学习了如何迭代不同类型的数据结构,以及如何将循环与pandas DataFrames和matplotlib一起使用以编程方式创建多个跟踪或子图。
最后,我们研究了一些更高级的技术,这些技术使我们可以更好地控制for循环的操作和执行。
摘自:https://www.aaa-cg.com.cn/data/2311.html
最后
以上就是老实香氛最近收集整理的关于大数据分析Python For循环教程的全部内容,更多相关大数据分析Python内容请搜索靠谱客的其他文章。


![[Simulink] Simulink与51单片机示例A0 点亮LEDA1 LED闪烁A2 LED流水灯A3 数码管显示A4 按键-外部中断](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)





发表评论 取消回复