目录
一、解题思路:
二、最终一致性的常用做法
三、实现方法说明
3.1、两阶段提交协议 2PC
3.2、三段提交协议3PC(弥补 2PC 协议缺点)
3.3、TCC模式(Try-Confirm-Cancel)----这个像 【两阶段提交协议】
3.4、 可靠事件模式
3.5、业务补偿模式
一、解题思路:
【最终一致性】:是指系统中的所有数据副本经过一段时间后,最终能够达到一致的状态。这里所说的一段时间,也要是用户可接受范围内的一段时间。
eg: 第一阶段----完成某项业务;第二阶段----n个dataSource的数据都进行更新并保证一定成功;
第一阶段好说,但你如何保证第二阶段的n个dataSource更新一定都成功?比如就有1个dataSource没更新呢?你凭什么保证,如何代码控制?
- 事务:n个dataSource要么全部更新成功,要么全部都不更新;
eg: 两阶段提交协议,三阶段提交协议;
- 非事务: 不用事务概念后搞不好就有某个dataSource失败的,真这样了只能补偿;
但凭什么保证补偿一定成功?
要么我暴力的“不停重试,直到成功”;eg:事务型消息队列
要么“第二阶段失败的概率比较小”,我稍微补偿一下就可以;eg:补偿任务
ps: 还有小概率真的不会成功,那怎么办?第二阶段每隔一段时间主动汇报执行结果;
二、最终一致性的常用做法
1、单数据库事务
如果应用系统是单一的数据库,那么这个很好保证,利用数据库的事务特性来满足事务的一致性,这时候的一致性是强一致性的;
2、多数据库事务
针对多数据库事务可以根据“二阶段提交协议”,采用spring 3.0 + Atomikos + JTA进行支持;
3、基于【事务型消息队列】的最终一致性
业务逻辑处理成功后,提交消息,确保消息是发送成功的,之后消息队列投递来进行处理,如果成功,则结束,如果没有成功,则重试,直到成功;
不过仅仅适用业务逻辑中,第一阶段成功,第二阶段必须成功的场景。
4、基于【消息队列+定时补偿机制】的最终一致性
前面部分和上面基于事务型消息的队列,不同的是,第二阶段重试的地方,不再是消息中间件自身的重试逻辑了,而是单独的补偿任务机制。
其实在大多数的逻辑中,第二阶段失败的概率比较小,所以单独把补偿任务标出来,可以更加清晰,能够比较明确的知道当前多少任务是失败的。
5、【异步回调】机制的引入
A应用调用B,在同步调用的返回结果中,B返回成功给到A,一般情况下,这时候就结束了;
其实在99.99%的情况是没问题的,但是有时候为了确保100%,最起码在系统设计中100%,这时候B系统再回调A一下,告诉A,你调用我的逻辑,确实成功了。
其实这个逻辑,非常类似 “TCP协议中的三次握手” 。
6、类似【double check】机制的确认机制
A在同步调用B,B返回成功了。这次调用结束了,但是A为了确保,在过一段时间,这个时间可以是几秒,也可以是每天定时处理,再调用B一次,查询一下之前的那次调用是否成功。
例如A调用B更新订单状态,这时候成功了,延迟几秒后,A查询B,确认一下状态是否是自己刚刚期望的。上图中的D流程。
三、实现方法说明
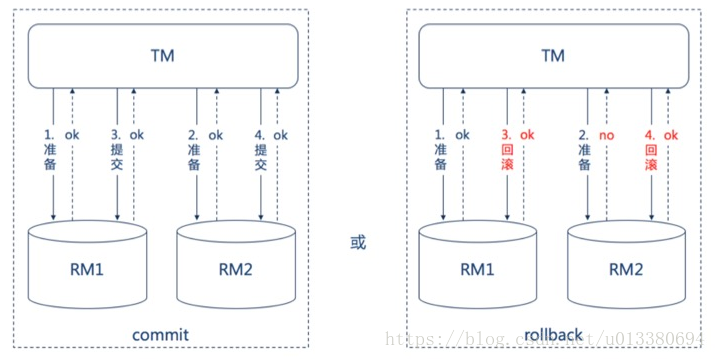
3.1、两阶段提交协议 2PC
要保证一致性得有个人来做总指挥协调,单机服务的此角色是事务,分布式事务得把这个角色单独拎出来——TM;
此处注意一个概念:TM----事务协调器
分布式事务来保证数据一致性,也就是常说的两阶段提交协议(2PC,Two Phase Commitment Protocol)
第一阶段:TM联系业务相关的所有数据库,通知其进行准备;相关数据库可以应答说OK,也可以应答说 NO OK;
- 各数据库节点执行本地事务操作,但在执行完成后并不会真正提交数据库本地事务;
- 数据库只要应答了说OK,那就默认你一定都做好准备,只要提交事务,你肯定不会失败;
- 数据库若应答了 NO OK,那你得考虑回滚(比如做准备需要3步,前2步你都做了,删除数据库的代码已经运行了,到第3步发现做不了了,你说NO OK,那已经做的前2步是不是得回滚);
第二阶段:TM收到应答,收集综合意见决定下一步操作;若所有的数据库都OK,那就指示大家都提交事务;只要有一个数据库响应说NO OK,那就指示大家都做回退;
3.2、三段提交协议3PC(弥补 2PC 协议缺点)
2PC协议缺点:
- 在2PC完成期间,所有的 参与者资源 和 协调者资源 都是被锁住的;
- 由于 TM 的重要性,一旦 TM 发生故障。参与者数据库 会一直阻塞下去;
3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段;
第一阶段: 跟2PC一样,只不过CanCommit是 尝试获取数据库锁,2PC不是;
第二阶段:跟第一阶段差不多,只不多 协调者和参与者都引入了超时机制 (2PC中只有协调者可以超时,参与者没有超时机制);
第三阶段:跟第二阶段差不多;
这个3PC网上找的资料感觉写的不是很详细,先不深究了,知道有这么个东西就行;
3.3、TCC模式(Try-Confirm-Cancel)----这个像 【两阶段提交协议】
TCC模式要求从服务提供三个接口:Try、Confirm、Cancel;
第一阶段:【主业务服务】在活动管理器中登记所有从业务服务,并分别调用所有【从业务】的try操作,所有从业务服务的try操作要么都调用成功,要么某个从业务服务的try操作失败;
第二阶段:活动管理器根据第一阶段的执行结果来执行confirm或cancel操作。如果第一阶段所有try操作都成功,则活动管理器调用所有从业务活动的confirm操作。否则调用所有从业务服务的cancel操作。
3.4、 可靠事件模式
举例: 客户成功下单---->消息代理---->支付服务,支付成功---->消息代理---->下单成功待出库
这个感觉像消息中间件的模式,放这怎么感觉有些混乱,我认为这可能是因为可靠事件模式属于【事件驱动架构】,事件来了这样解决更合适,消息中间件是解决此问题的一个工具,但还得在消息中间件上加一层【可靠】保证;
那么单纯这样做有哪些【不可靠】的地方呢?
- 某个服务在更新了业务实体后发布事件却失败
- 虽然服务发布事件成功,但是消息代理未能正确推送事件到订阅的微服务
- 接受事件的微服务重复消费了事件
【可靠事件模式】解决了上述的不可靠问题,具体怎么解决的此处不细说;
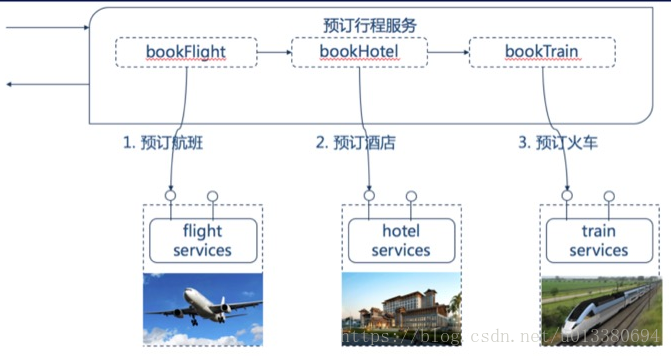
3.5、业务补偿模式
举例:旅行社给你的行程【预定航班】--》【预定酒店】--》【预定火车】,若【预定火车】失败,那么取消之前预订的酒店、航班即为【补偿过程】;
【补偿模式】使用一个额外的协调服务来协调各个需要保证一致性的微服务,协调服务按顺序调用各个微服务,如果某个微服务调用异常就取消之前所有已经调用成功的微服务;
最后
以上就是哭泣小松鼠最近收集整理的关于分布式系统CAP----数据的【最终一致性】 一、解题思路:二、最终一致性的常用做法三、实现方法说明的全部内容,更多相关分布式系统CAP----数据内容请搜索靠谱客的其他文章。








发表评论 取消回复