文章目录
- 前言
- 一、介绍一下物联网后台数据
- 二、分析网页后台
- 1.分析物联网平台后台
- 2.分析模拟登陆的前端请求和后端返回
- 1.前端请求-headers
- 2.前端请求-打包数据
- 3.前端请求-代码请求
- 4.后端返回-分析返回数据
- 3.数据获取
- 1.数据采集-headers
- 2.数据采集-获取检索时间段内有多少页数据
- 3.数据采集-根据页码遍历取数
- 三、效果
- 四、总结
前言
鉴于网上以及视频教材很多都是直接用cookie写到了headers中,这样验证是会过期的,我这里直接模拟浏览器请求。
物联网平台爬虫应用,账号是内部的账号,因此没有账号的可以学习思路,有账号的可以考虑实战爬虫。
物联网平台的爬虫主要获取一些数据表格,主要是传感器的数据,包括:时间、风速、雨量、大气温度、日雨量累计、数字气压、紫外线、风向、负氧离子、大气湿度等数据
一、介绍一下物联网后台数据
如图,本次取数内容为一下内容:
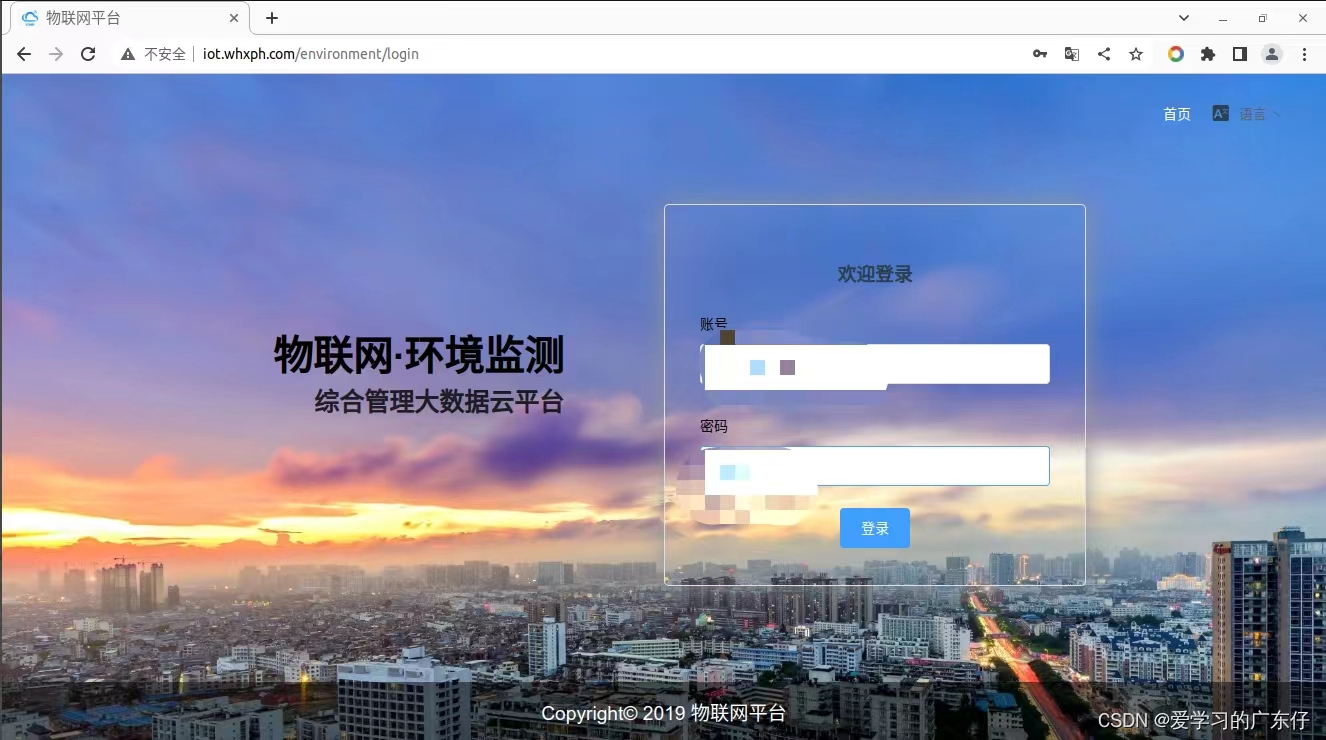
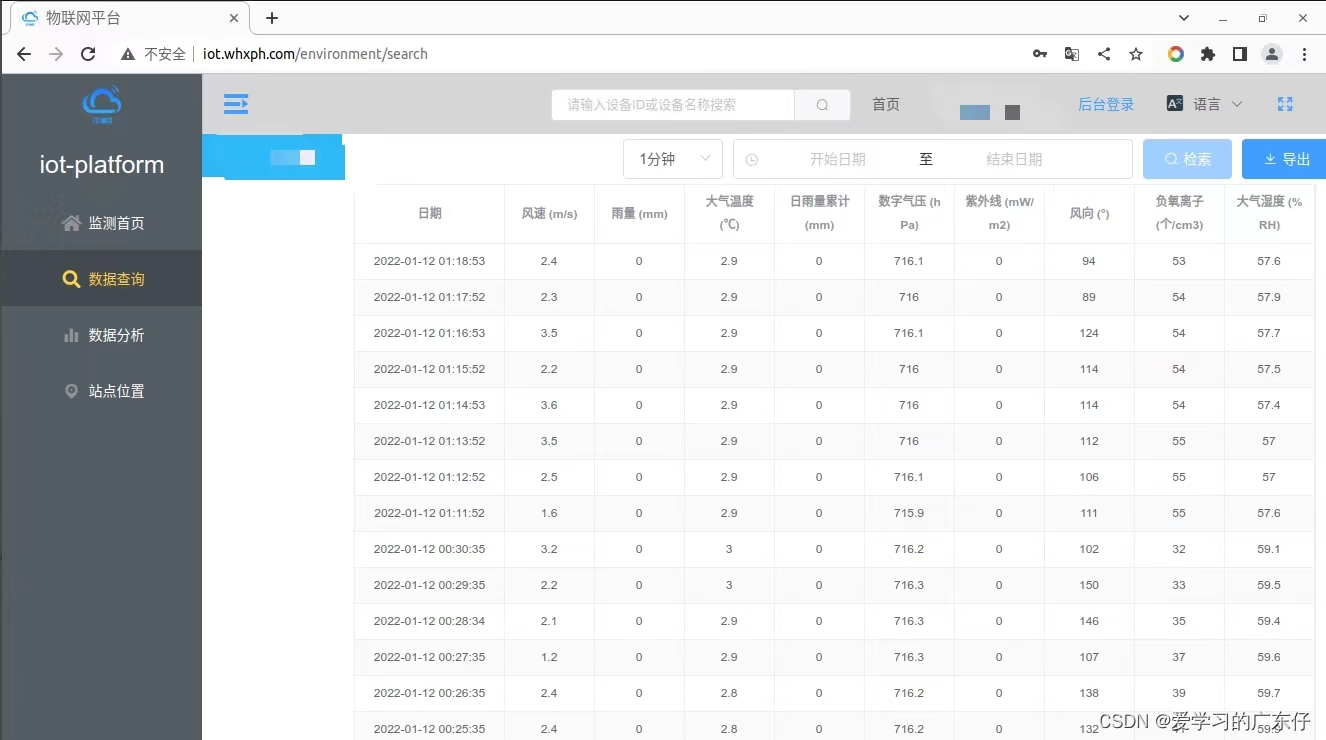
从入口到查询等步骤可以分析,此爬虫比较简单,只需要把用户名和密码直接传递进去即可,不存在验证码等问题。
二、分析网页后台
1.分析物联网平台后台
base_url = 'http://iot.whxph.com/environment/login'
从前面分析可知,本次需要先模拟登陆,因此,我们按下F12,进入浏览器开发者工具,选择Network板块。
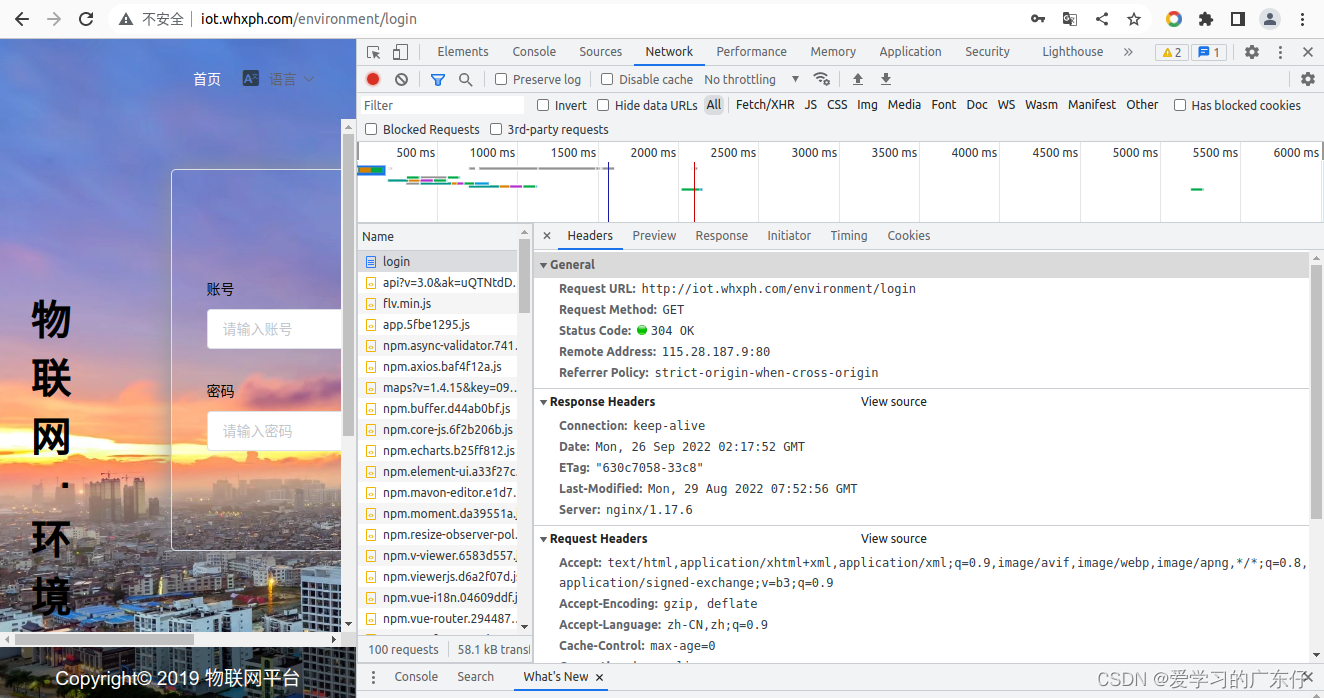
然后重新刷新一下网页,这个时候我们会在开发者工具中得到后台的一些请求步骤,同时我们需要随便输入一个用户名和密码,查看登陆的时候前端浏览器会怎样发送数据到后台的,如图:
刷新网页的后台请求数据:
随便用户登录的时候的请求内容:
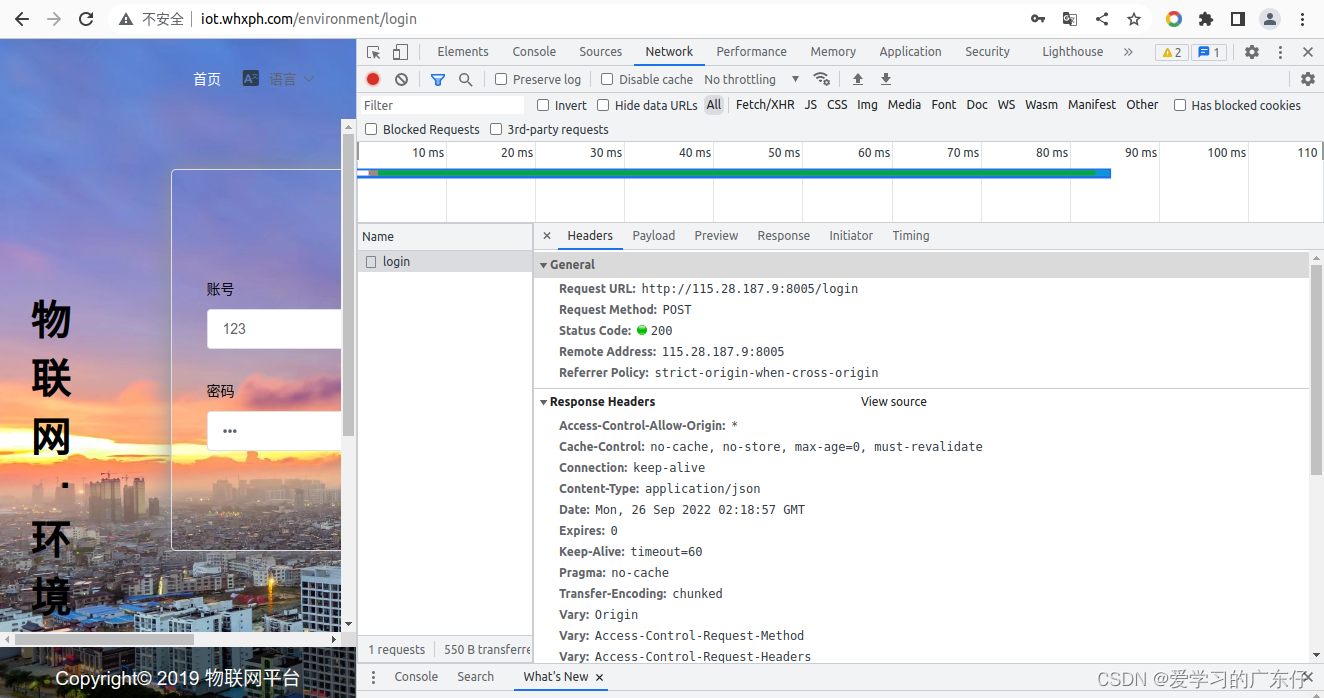
从上边的分析可知,base_url的请求基本作用不大,因此我们代码请求的时候可完全忽略,其次随便输入用户信息点击登陆发现这个后台数据就是模拟登陆的关键,因此我们着重分析此请求内容
2.分析模拟登陆的前端请求和后端返回
1.前端请求-headers
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/json',
'Host': '115.28.187.9:8005',
'Origin': 'http://iot.whxph.com',
'Referer': 'http://iot.whxph.com/',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
2.前端请求-打包数据
先上图,按照这个图来构建请求数据包即可:
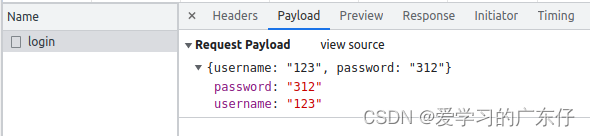
代码构建数据包:
post_data={
'password':passwd,
'username':user
}
3.前端请求-代码请求
request = urllib.request.Request(self.login_url,data,headers)
login_result = self.opener.open(request).read().decode('utf-8')
login_jsonresult = json.loads(login_result)
4.后端返回-分析返回数据
如图:
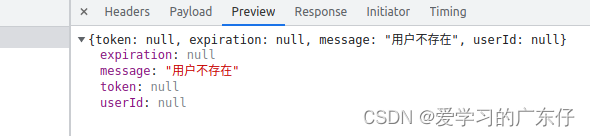
从返回数据可以知道,token是后续请求数据用到的,还有就是用户登陆是否成功的标志,因此分析后段字段即可实现,代码如下:
if '认证成功' in login_jsonresult['message']:
self.token = login_jsonresult['token']
return True
else:
self.token = None
return False
3.数据获取
在模拟登陆完成之后,即可做数据采集了,先分析采集页面:
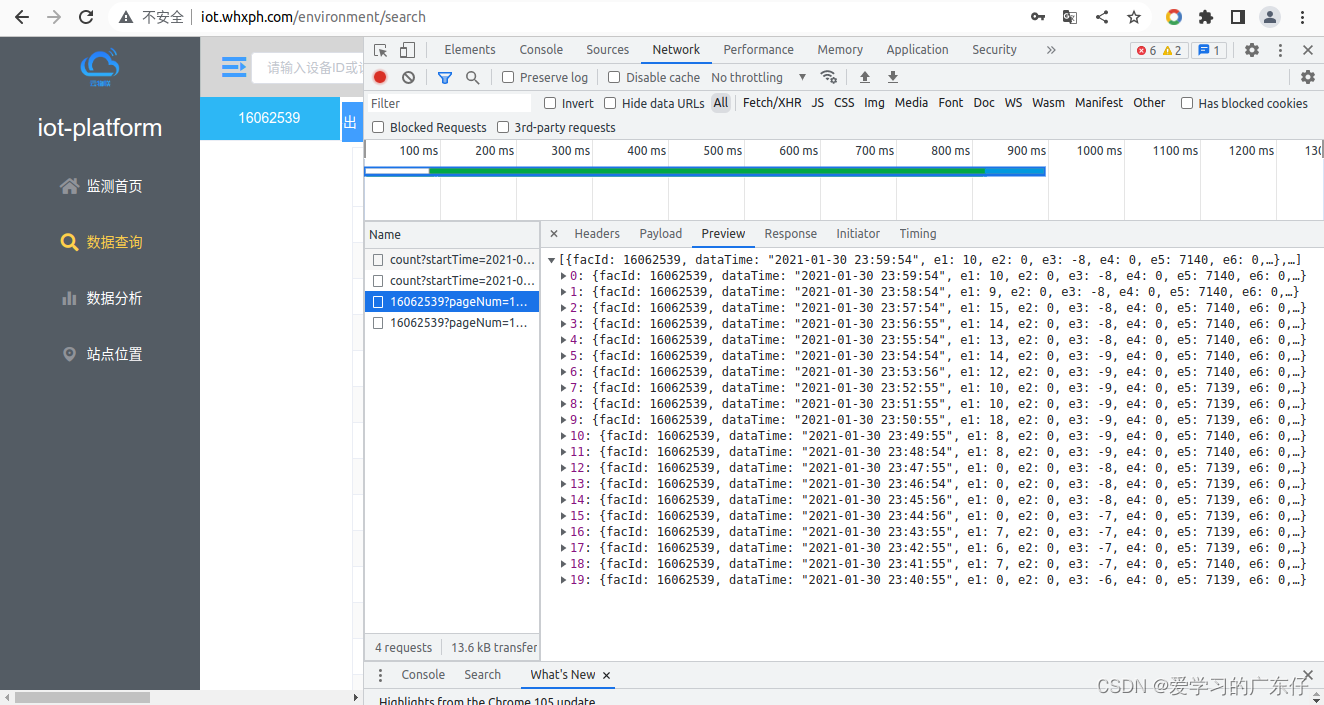
随便检索一下可以查看到数据的请求url,因此我们构建此图的请求内容:
data_url=’ http://115.28.187.9:8005/datas/16062539?pageNum=1&pageSize=20&startTime=2021-01-01+00:00:00&endTime=2021-01-31+00:00:00&interval=1’
通过分析data_url,后面附带的参数意思为:
pageNum:请求第几页
pageSize:每页数据量
startTime:查询的开始时间
endTime:查询的结束时间
interval:不重要参数,直接用即可
根据之前学习的分析步骤,下边直接请求取数:
1.数据采集-headers
data_url = 'http://115.28.187.9:8005/datas/16062539?pageNum={0}&pageSize={1}&startTime={2}+{3}:{4}:{5}&endTime={6}+{7}:{8}:{9}&interval=1'
header={
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': '115.28.187.9:8005',
'Origin': 'http://iot.whxph.com',
'Referer': 'http://iot.whxph.com/',
'token': self.token,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
2.数据采集-获取检索时间段内有多少页数据
_get_data_start_time = get_data_start_time.strftime("%Y-%m-%d %H:%M:%S")
start_hours = _get_data_start_time.split(' ')[1].split(':')[0]
start_min = _get_data_start_time.split(' ')[1].split(':')[1]
start_sec = _get_data_start_time.split(' ')[1].split(':')[2]
_get_data_end_time = get_data_end_time.strftime("%Y-%m-%d %H:%M:%S")
end_hours = _get_data_end_time.split(' ')[1].split(':')[0]
end_min = _get_data_end_time.split(' ')[1].split(':')[1]
end_sec = _get_data_end_time.split(' ')[1].split(':')[2]
page_Num = -1
request = urllib.request.Request(page_url.format(_get_data_start_time.split(' ')[0],start_hours,start_min,start_sec,_get_data_end_time.split(' ')[0],end_hours,end_min,end_sec),headers=header)
data_num = int(self.opener.open(request).read().decode('utf-8'))
if data_num==0:
print("get {4}-{3} date:{0}~{1} -> empty[{2}]".format(get_data_start_time,get_data_end_time,0,table_name,self.Scenic_Spot))
start_time = get_data_end_time + datetime.timedelta(seconds=1)
return
page_Num = data_num//rows + 1
3.数据采集-根据页码遍历取数
add_dict_list=[]
for each_page in range(0,page_Num):
request = urllib.request.Request(data_url.format(each_page+1, rows,_get_data_start_time.split(' ')[0],start_hours,start_min,start_sec,_get_data_end_time.split(' ')[0],end_hours,end_min,end_sec),headers=header)
result_data = self.opener.open(request).read().decode('utf-8')
data = json.loads(result_data)
for each_data in data:
MGDB_data={}
MGDB_data['日期'] = each_data['dataTime']
try:
MGDB_data['日期'] = datetime.datetime.strptime(MGDB_data['日期'], '%Y-%m-%d %H:%M:%S')
except:
pass
MGDB_data['风速(m/s)'] = each_data['e1']
MGDB_data['雨量(mm)'] = each_data['e2']
MGDB_data['大气温度(℃)'] = each_data['e3']
MGDB_data['日雨量累计(mm)'] = each_data['e4']
MGDB_data['数字气压(hPa)'] = each_data['e5']
MGDB_data['紫外线(mW/m2)'] = each_data['e6']
MGDB_data['风向(°)'] = each_data['e7']
MGDB_data['负氧离子(个/cm3)'] = each_data['e8']
MGDB_data['大气湿度(%RH)'] = each_data['e9']
add_dict_list.append(MGDB_data)
print("get {4}-{3} date:{0}~{1} -> ok[{2}]".format(get_data_start_time,get_data_end_time,len(add_dict_list),table_name,self.Scenic_Spot))
这里的add_dict_list就是所有数据,MGDB_data就是处理过程中的单条数据
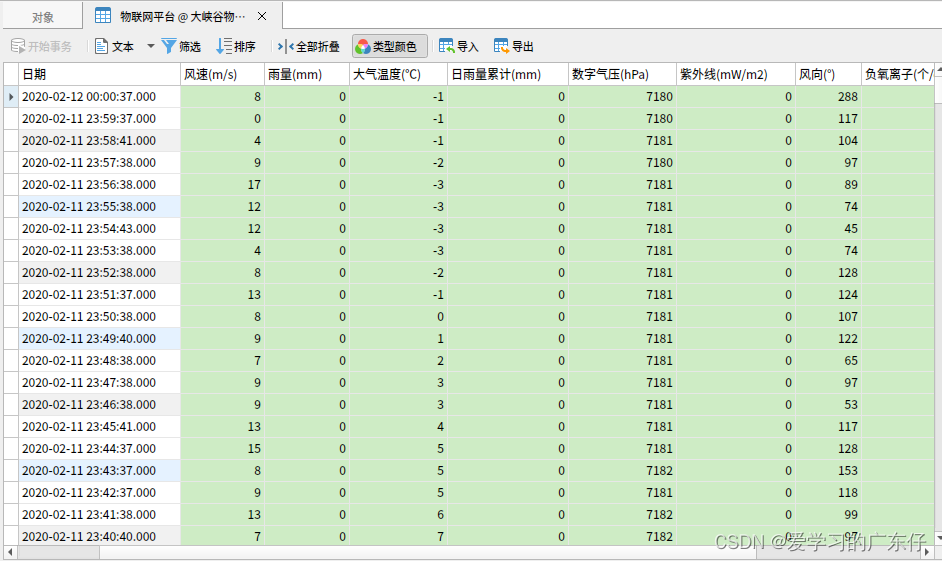
三、效果
我这边主要是把数据塞进数据库,最终效果如图:
四、总结
本项目代码比较简单,源码基本就是上边的源码,只需要读懂按照步骤即可实现数据采集,完成爬虫
最后
以上就是顺利心情最近收集整理的关于爬虫篇-物联网平台【附源码】前言一、介绍一下物联网后台数据二、分析网页后台三、效果四、总结的全部内容,更多相关爬虫篇-物联网平台【附源码】前言一、介绍一下物联网后台数据二、分析网页后台三、效果四、总结内容请搜索靠谱客的其他文章。








发表评论 取消回复