碎碎念
这些内容主要是我翻译国外师傅博客的一小部分内容得来的。不得不说,这个师傅写的文章是真的详细而且亲民。
链接:https://blog.lexfo.fr/cve-2017-11176-linux-kernel-exploitation-part3.html
链接:https://blog.csdn.net/vanbreaker/article/details/7664296
涉及到的一些宏
offsetof宏:判断结构体中成员的偏移位置
container_of宏:根据成员的地址反过来来获取结构体地址。
list_for_each_entry_safe():相当于遍历整个双向循环链表,遍历时会存下下一个节点的数据结构,方便对当前项进行删除。
linux的内存分配
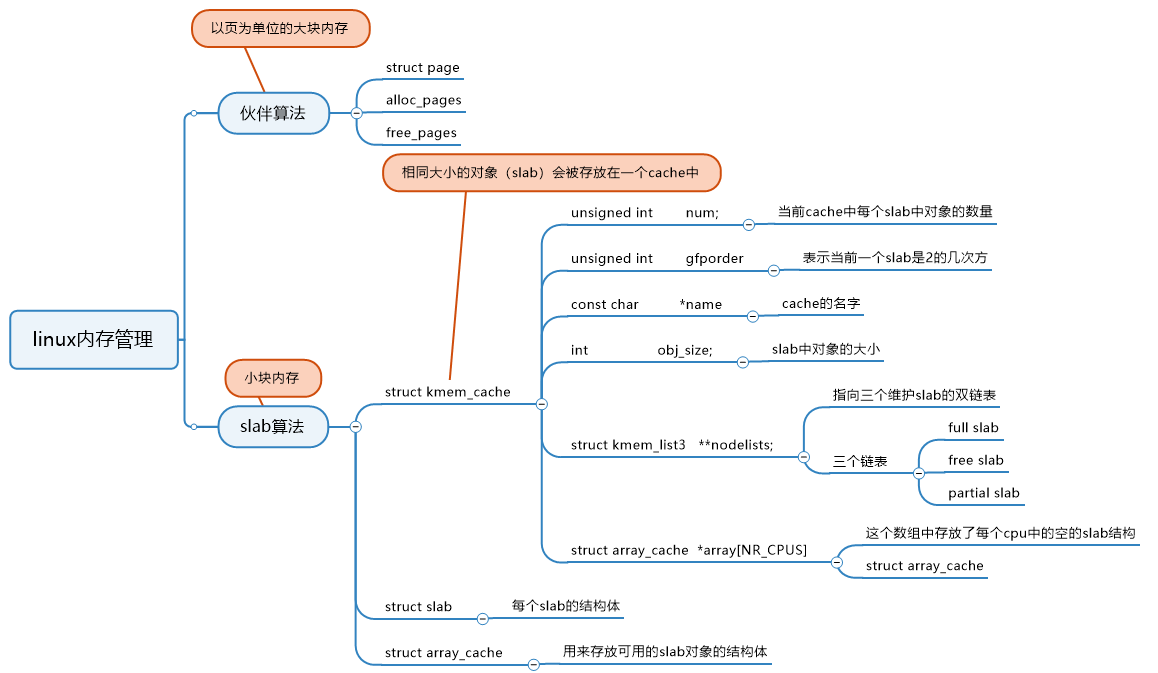
物理页管理(伙伴系统)
物理内存被划分为固定长度的连续内存块,被称为一页,基本上一页的大小都是4kb,可以用宏指令PAGE_SIZE 来查询。
内核必须要知道每一页的位置和具体信息。例如,他们必须知道特定的页面是不是可用的,这些信息被记录在页面数据结构struct page(也被叫做页面描述符)。
内核可以用alloc_pages()申请一个或者多个相邻的页面,用free_pages()来释放他们。分区页框分配器用来管理内核的这些请求,通常使用的伙伴系统算法。所以也被叫做伙伴伙伴分配器。
slab分配器
伙伴分配器不是经常儿用的,因为他总是以页为分配单位的,分配小块内存时会产生较大的内存碎片。为了解决这个问题,linux采用了slab分配器来分配小块的内存。同时slab分配器页复杂处理内核的malloc()和free().
内核提供了三种slab分配器:
SLAB分配器:历史分配器,专注于硬件缓存优化(Debian仍然使用它)。
SLUB分配器:自2007年以来的“新”标准分配器(由Ubuntu / CentOS / Android使用)。
SLOB分配器:用于嵌入式系统的小内存。
slub分配器似乎时最好理解的,没有用缓存着色,不追踪"full slab",没有内部和外部的slab管理。
用下面的代码可以查看机器使用的slab分配器。
缓存着色详见:https://blog.csdn.net/qianlong4526888/article/details/18005221
grep "CONFIG_SL.B=" /boot/config-$(uname -r)
重新分配内存取决于slab分配器,与SLUB相比,在SLAB上利用“use-after-free”更容易。利用slub还有一个好处就是slab混淆(更多的对象被存在"general" kmemcaches)。
ps: kmemcache是memcache的linux内核移植版,具体的请看https://blog.csdn.net/hjxhjh/article/details/12000413
cache和slab
由于内核偏向于分配相同内存大小的对象,所有为了避免反复申请释放同一块内存,slab分配器把相同大小的对象放在cache(一个已分配页框架的池)里面,cache用到的结构体时struct kmem_cache(缓存描述符)。
struct kmem_cache {
// ...
unsigned int num; // 每个slab中的对象数量
unsigned int gfporder; // 一个slab对象包含连续页是2的几次方
const char *name; // 这个cache的名字
int obj_size; // 管理的对象的大小
struct kmem_list3 **nodelists; // 维护三个链表empty/partial/full slabs
struct array_cache *array[NR_CPUS]; // 每个cpu中空闲对象组成的数组
};
一个slab基本上是一个或者多个页。一个简单的slab持有num数量的对象,每个对象大小都是obj_size,例如一个页大小的slab可以有四个1kb的对象。
struct slab {
struct list_head list; //用于将slab链入kmem_list3的链表
unsigned long colouroff; //该slab的着色偏移
void *s_mem; // 指向slab中的第一个对象
unsigned int inuse; //已经分配对象的数量
kmem_bufctl_t free; //下一个未分配对象的下标
unsigned short nodeid; //节点标识号
};
slab的数据结构对象(slab描述符)可以被存在slab内部或者另一个内存的位置。这样做的根本原因是减少外碎片。slab的数据结构对象具体别存在哪取决于缓存对象的大小,如果当前的对象大小小于512字节,那么会存在slab内部,否则会存在slab外部。
note: internal/external stuff不需要被担心,我们在利用use-after-free。在另一方面,如果你要利用堆溢出,理解这个很有必要。
检索slab中对象的虚拟地址,可以直接通过s_mem(第一个对象的地址)加上偏移量获得。为了让他变得简单,所以第一个对象得地址就是s_mem,第二个就是s_mem + obj_size等等。其实上比这个更复杂,因为有"colouring" stuff (ps:缓存着色相关的?不怎么理解),但是这个是题外话。
slabs内部管理和伙伴系统作用
当一个slab被创建的时候,slab分配器项伙伴分配器申请物理页,当然,当他被销毁的时候,会把物理页面还给伙伴分配器。内存会降低slab的创建和销毁以提高效率。
note:为什么gfporder (struct kmem_cache)是同一个slab相邻页面的对数,这是因为伙伴系统不用byte来分配大小,而是以2的几次幂来分配的。gfporder 为0,表示单页,为1表示相邻的两页,为2表示相邻的四页。
对于每一个cache,slab分配器会保持三个双链表结构为了slabs。
- full slabs:当前slab中的所有对象都被使用了。
- free slabs:当前slab中的所有对象都是空的。
- partial slabs:当前slab中的部分对象被使用了。
这些页面被存储与描述符中,nodelists(struct kmem_cache),每个slab属于三个列表中的一个,并且能在自身情况改变后,在三个列表中进行切换。
为了减少与伙伴分配器的交互,slab分配器会保留一个有少量free slabs和partial slabs的池。当slab分配器申请一个对象的时候,会先检索自己的池中是否有空闲的slab,如果没有就会调用cache_grow()方法向伙伴分配器申请更多的物理页,当然,如果slab分配器发现自己的池中有太多的空闲slab,也会销毁一些slab将我i里也还给伙伴分配器。
每个cpu中的缓存数组(array_cache)
每次申请,slab分配器需要扫描整个free slabs 或者 partial slabs。通过扫描整个列表来寻找空闲的空间是低效的。(这会要求一些锁,还需要去找偏移)
为了提高性能,slab分配器保存一个队列指向空的对象。即struct array_cache,保存在缓存描述符中(struct kmem_cache)。
struct array_cache {
unsigned int avail; // 存放可用对象指针的数量也是当前空闲空闲数组的下标
unsigned int limit; // 最多可以存放的对象指针数量
unsigned int batchcount;
unsigned int touched;
spinlock_t lock;
void *entry[]; // 对象指针数组
};
ps:貌似最近的版本中entry[]变成了entry[0],entry[0]表示一个可变长度的数组。
array_cache 采用的是LIFO的数据结构,从漏洞利用者的角度来说,这是一个极好的方式,这也是为什么在SLAB和SLUB分配器下use-after-free是更容易利用。
最简单的申请内存:
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags) // yes... four "_"
{
void *objp;
struct array_cache *ac;
ac = cpu_cache_get(cachep);
if (likely(ac->avail)) {
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
objp = ac->entry[--ac->avail]; // <-----
}
// ... cut ...
return objp;
}
最简单的释放内存:
static inline void __cache_free(struct kmem_cache *cachep, void *objp)
{
struct array_cache *ac = cpu_cache_get(cachep);
// ... cut ...
if (likely(ac->avail < ac->limit)) {
STATS_INC_FREEHIT(cachep);
ac->entry[ac->avail++] = objp; // <-----
return;
}
}
简单来说,最好的情况下,申请和释放操作的复杂度只有O(1)。
WARNING:如果这个快捷的方式失败了,分配算法会回到慢的解决方案,即一个个遍历。
note:每个cpu都有一个数组缓存,可以用cpu_cache_get()方法来获取,如此做可以减少锁的次数,从而提高性能。
note:array cache中的每一个空闲的指针可能指向的是不容的slabs
通用和专用缓存
为了减少外碎片,内核创建缓存以2的次方的大小,这样确保内碎片小于50%的大小,事实上,当内核去申请指定大小的尺寸时,他会申请到最适合的内存大小,即申请100字节会给你128字节的内存空间。
在SLAB中,通用缓存会有前缀"size-"(size-32,size-64)。在SLUB中,通用缓存会有前缀"kmalloc-"(kmalloc-32)。由于我们觉得SLUB的前缀更好,所以我们通常用他哪怕我们的目标是SLAB。
内核使用kmalloc()和kfree()方法去申请和释放通用缓存。
因为有一些对象会被频繁的申请和释放,内核创建了一些特殊的专用缓存。例如file文件对象是非常常用的对象,他
有自己的专用缓存(filp)。这些专用缓存的内碎片会接近于0。
内核使用kmem_cache_alloc()和kmem_cache_free()方法去申请和释放一块专用的内存空间。
在最后kmalloc()和kmem_cache_alloc()会变成 __cache_alloc()函数,当然kfree()和kmem_cache_free()会变成__cache_free()函数。
note:你可以看到全部的cache清单和一些有用的信息,在/proc/slabinfo中。
list_for_each_entry_safe()函数的介绍
container_of()宏
linux内核中广泛的使用到了双向循环列表,理解他对我们达到任意命令执行很必要,接下来我们会用一个具体的例子来理解双向循环列表的使用。这节结束时,你会明白list_for_each_entry_safe()宏的作用。
#define container_of(ptr, type, member) ({
const typeof( ((type *)0)->member ) *__mptr = (ptr);
(type *)( (char *)__mptr - offsetof(type,member) );})
//ptr 当前的地址
//type 所涉及的数据结构
//member 数据结构中的成员名
container_of()宏的意义在于利用结构成员的地址找回结构本身的地址。他使用两个宏:
typeof() - 定义编译时的类型
offsetof() - 查找结构中字段的偏移地址(以字节为单位)
例子:
struct foo {
unsigned long a;
unsigned long b; // offset=8
}
void* get_foo_from_b(unsigned long *ptr)
{
// "ptr" points to the "b" field of a "struct foo"
return container_of(ptr, struct foo, b);
}
void bar() {
struct foo f;
void *ptr;
printf("f=%pn", &f); // <----- print 0x0000aa00
printf("&f->b=%pn", &f->b); // <----- print 0x0000aa08
ptr = get_foo_from_b(&f->b);
printf("ptr=%pn", ptr); // <----- print 0x0000aa00, the address of "f"
}
也就是说,他利用他自己的当前段的地址减去他在该结构中的偏移地址。
使用双向循环列表
linux用以下结构处理双向循环列表:
struct list_head {
struct list_head *next, *prev;
};
这个结构有两个作用:
1.代表双向循环列表本身。
2.代表列表中的一个元素。
INIT_LIST_HEAD()函数被用来创建双向循环列表,并将其next和prev指针都指向列表本身。
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
我们先定义一个resource_owner结构体
struct resource_owner
{
char name[16];
struct list_head consumer_list;
};
void init_resource_owner(struct resource_owner *ro)
{
strncpy(ro->name, "MYRESOURCE", 16);
INIT_LIST_HEAD(&ro->consumer_list);
}
为了使用列表,每个列表成员的结构必须一致,即每个成员都必须有struct list_head字段。
struct resource_consumer
{
int id;
struct list_head list_elt; // <----- this is NOT a pointer
};
成员可以被添加和删除通过list_add()和list_del()方法。
int add_consumer(struct resource_owner *ro, int id)
{
struct resource_consumer *rc;
if ((rc = kmalloc(sizeof(*rc), GFP_KERNEL)) == NULL)
return -ENOMEM;
rc->id = id;
list_add(&rc->list_elt, &ro->consumer_list);
return 0;
}
接下来,我们想要释放一个成员,但是这个列表中只有一个元素,所以我们可以直接用container_of()宏来辅助释放当前元素。因为我们需要释放整一个resource_consumer对象,但是列表中只有list_elt的地址,所以需要把列表中的list_elt地址取出来,用container_of()宏来取到resource_consumer的地址,然后调用kfree()。
void release_consumer_by_entry(struct list_head *consumer_entry)
{
struct resource_consumer *rc;
// "consumer_entry" points to the "list_elt" field of a "struct resource_consumer"
rc = container_of(consumer_entry, struct resource_consumer, list_elt);
list_del(&rc->list_elt);
kfree(rc);
}
我们想要访问一个元素通过他的id,所以我们使用list_for_each()宏遍历列表。
#define list_for_each(pos, head)
for (pos = (head)->next; pos != (head); pos = pos->next)
\如果pos指针没有指到头节点,就继续往下。
#define list_entry(ptr, type, member)
container_of(ptr, type, member)
我们可以看到list_for_each()只提供了一个迭代器,所以我们仍然需要container_of()宏,但是一般用list_entry()宏,因为虽然功能一样,但是名字更好。。。
struct resource_consumer* find_consumer_by_id(struct resource_owner *ro, int id)
{
struct resource_consumer *rc = NULL;
struct list_head *pos = NULL;
list_for_each(pos, &ro->consumer_list) {
rc = list_entry(pos, struct resource_consumer, list_elt);
if (rc->id == id)
return rc;
}
return NULL; // not found
}
不得不申明list_head变量,使用list_entry()/container_of()宏有点复杂,所以出现了list_for_each_entry()宏(使用了list_first_entry() 和 list_next_entry()宏)
#define list_first_entry(ptr, type, member)
list_entry((ptr)->next, type, member)
\取出下一个指针的结构体本身的地址
#define list_next_entry(pos, member)
list_entry((pos)->member.next, typeof(*(pos)), member)
\取出结构体中的取出当前元素所在元素链表中的下一个,然后返回下一个元素的结构的指针
#define list_for_each_entry(pos, head, member)
for (pos = list_first_entry(head, typeof(*pos), member);
&pos->member != (head);
pos = list_next_entry(pos, member))
\c=typeof(*pos) 可以把c指向pos的数据类型
我们重写之前的代码,不再申明struct list_head。
struct resource_consumer* find_consumer_by_id(struct resource_owner *ro, int id)
{
struct resource_consumer *rc = NULL;
list_for_each_entry(rc, &ro->consumer_list, list_elt) {
if (rc->id == id)
return rc;
}
return NULL; // not found
}
接下来,如果我们要释放每一个成员,就会遇到两个问题:
我们release_consumer_by_entry()函数写的很烂,因为需要一个struct list_head指针。
ps:list_for_each()宏是基于列表不变的基础上的。
我们无法再遍历列表时删除元素,这会让我们的use-after-free很难进行,所以我们使用 list_for_each_safe()宏来解决,他会预先读取下一个元素。
#define list_for_each_safe(pos, n, head)
for (pos = (head)->next, n = pos->next; pos != (head);
pos = n, n = pos->next)
这意味着我们需要两个struct list_head变量。
void release_all_consumers(struct resource_owner *ro)
{
struct list_head *pos, *next;
list_for_each_safe(pos, next, &ro->consumer_list) {
release_consumer_by_entry(pos);
}
}
最后一个是因为release_consumer_by_entry()写的很烂,所以我们我们用一个struct resource_consumer 指针作为参数。(不再使用container_of())
void release_consumer(struct resource_consumer *rc)
{
if (rc)
{
list_del(&rc->list_elt);
kfree(rc);
}
}
由于我们不用再使用struct list_head作为参数,所以利用 list_for_each_entry_safe()宏 重写release_all_consumers()函数
#define list_for_each_entry_safe(pos, n, head, member)
for (pos = list_first_entry(head, typeof(*pos), member),
n = list_next_entry(pos, member);
&pos->member != (head);
pos = n, n = list_next_entry(n, member))
即:
void release_all_consumers(struct resource_owner *ro)
{
struct resource_consumer *rc, *next;
list_for_each_entry_safe(rc, next, &ro->consumer_list, list_elt) {
release_consumer(rc);
}
}
最后, list_for_each_entry_safe()宏在很多方面都用到了,包括
我们去实现任意命令执行。我们甚至会在汇编中查看他(因为偏移量)。
最后
以上就是可耐黑夜最近收集整理的关于linux的内存分配和 list_for_each_entry_safe()函数的介绍的全部内容,更多相关linux的内存分配和内容请搜索靠谱客的其他文章。








发表评论 取消回复