2017运维/DevOps在线技术峰会上,饿了么运维负责人程炎岭带来题为“饿了么Redis Cluster集群化演进”的演讲。本文主要从数据和背景开始谈起,并对redis的治理进行分析,接着分享了redis cluster的优缺点,重点分析了corvus,包括commands、逻辑架构和物理部署等,最后分享了redis的运维和开发,并作了简要总结,一起来瞧瞧吧。
以下是精彩内容整理:
近几个月,运维事件频发。从“炉石数据被删”到“MongoDB遭黑客勒索”,从“Gitlab数据库被误删”到某家公司漏洞被组合攻击。这些事件,无一不在呐喊——做好运维工作的重要性。然而,从传统IT部署到云,人肉运维已经是过去式,云上运维该怎么开展?尤其是云2.0时代,运维已经向全局化、流程化和精细化模式转变。与此同时,人工智能的发展,“威胁论”也随之袭来——运维是不是快要无用武之地了?如何去做更智能的活,当下很多运维人在不断思考和探寻答案。
Redis Cluster在业内有唯品会、优酷蓝鲸等很多公司都已经在线上有了一定规模的Redis Cluster集群,那么,饿了么是怎样从现有的Redis技术迁移到Redis Cluster集群上的呢?
背景和数据
2015-2016年是饿了么的业务爆炸式增长阶段,订单量从几十w到到峰值900w/天,在增长的过程中我们也遇到了一些问题,我们有服务化治理诉求、应用性能和稳定诉求、人肉运维成本诉求,并且还要为未来的PAAS平台池化准备。
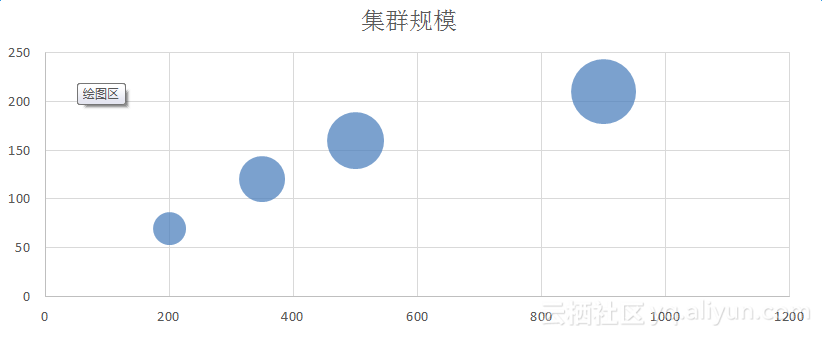
横坐标是订单量,纵坐标是集群数量,在多机房下整个集群规模是double的,可以看到,千万订单的集群规模大概在200个,在一个机房内我们有近200套集群,近4T数据在Redis里面,整个节点数大约在10000个左右。
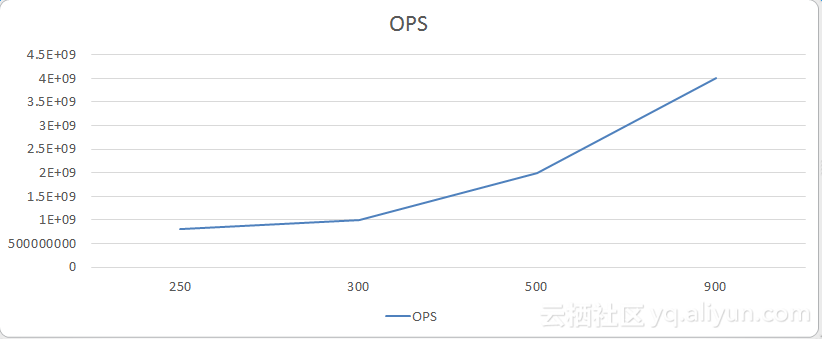
上图表示在高峰期时每天不同订单量下,整个Redis集群承载OPS的需求。
使用场景
外卖行业的使用场景要结合业务来看,所有需要高性能、高并发、降级数据库场景下都用到了Redis做缓存,包括用户端、商户端和物流配送,搜索排序、热卖、画像等目前也是往Redis里推送,除了缓存外,还有各类cache、计数器、分布式锁等。
为什么会考虑向Redis Cluster演进呢?
因为Redis存在很多问题,比如单点的内存上限受限制,将Redis当成DB或cache混用,共用一个redis、大key阻塞整个实例,经常需要扩容、扩容很痛苦,使用复杂且基础环境非标、存在各种配置,监控缺失以及不能统一配置等诸多问题。
治理
由于Redis请求量太大,打满了机器网卡,所以在2016年5月启动了治理redis的项目。
在自研选型部分,在OPS推广治理时我们与业内成熟技术做了比较,包括Redis vs redis Cluster,以及Twenproxy vs Codis vs Redis Cluster,比较了单节点的redis和redis Cluster,还有业内经过生产考验的proxy,最后决定自研自己的Redis Cluster + proxy。
Redis Cluster 的优缺点
为什么选择redis cluster作为我们的底层存储呢?
Redis cluster自带迁移功能,性能快、高可用,支持在线分片,丰富集群管理命令等。自研proxy在初期快速在生产上应用时候可以省略掉这部分,让redis cluster本身给我们提供这项功能就足够了。
Redis cluster也有一些不足:
- Client 实现复杂,需要缓存slot mapping关系并及时更新;
- Client不成熟导致提高开发难度;
- 存储和分布式逻辑耦合,节点太多时节点之间的检测占大量网卡带宽;
- 3.0.6版本前,只能单个key迁移,并且同时只允许一个slot处于迁移状态。
Corvus
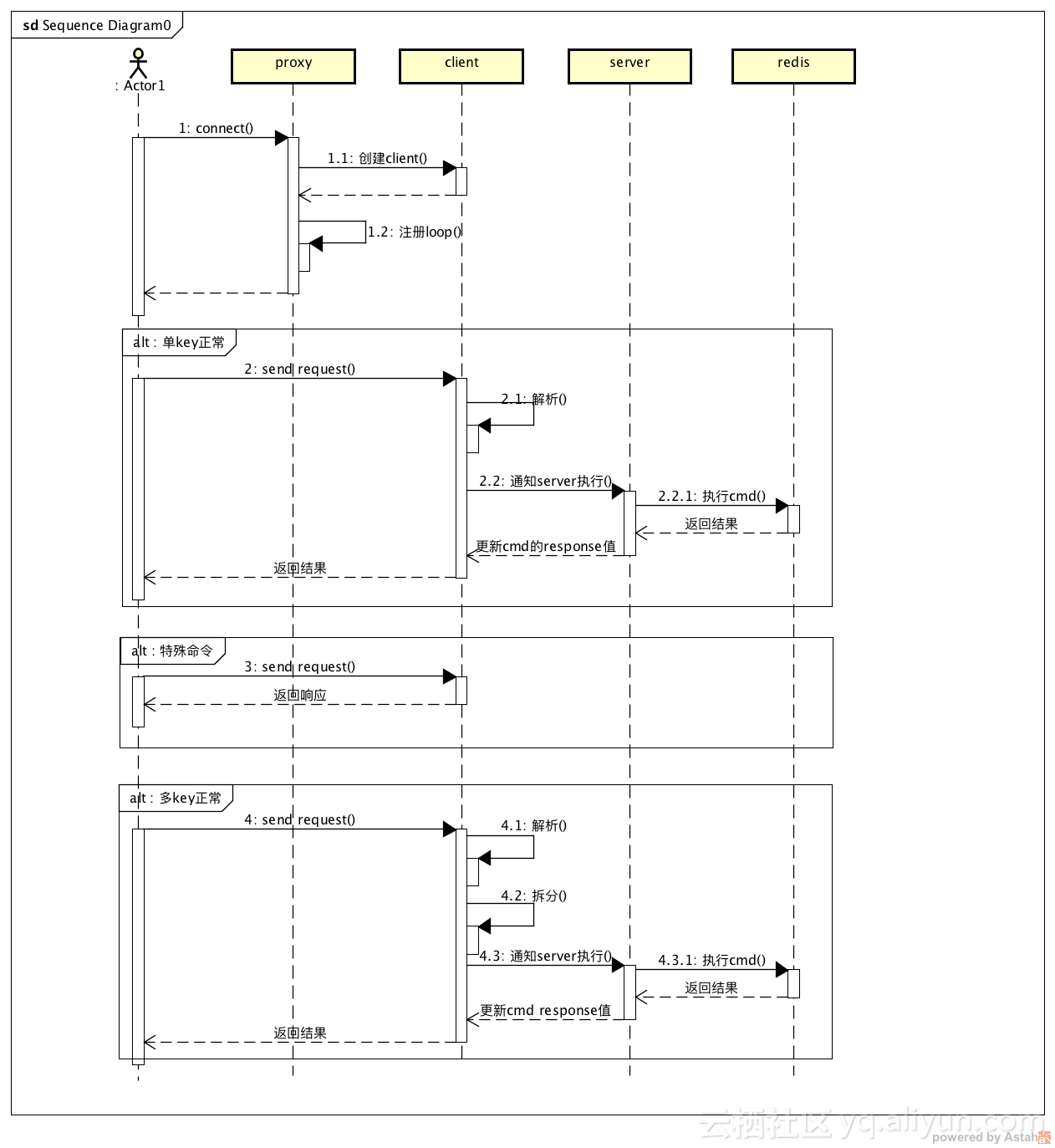
图中为corvus时序设计,可以看到,actor到后面的redis,中间的proxy、client和server是在corvus中实现的逻辑,proxy处理connect操作,接收用户的请求发送到client,server最终实现命令的处理。我们分成三个分类,对于单key、特殊命令和多key的处理,对复合命令操作做了单独操作,并对返回结果做聚合,同时还有一些特殊命令,比如cluster命令的处理逻辑。
corvus封装了redis cluster 协议,提供redis 协议,这样用原来成熟的redis client操作redis cluster集群,接入到corvus,这时可以做到无缝的改动;扩容缩容应用无感知,corvus服务是注册的机制,对应用程序来说,连接是通过一层本地proxy,我们对应用程序提供SDK,但目前我们通过本地proxy连接接入corvus已经能够满足大部分应用;corvus实时缓存了slots mapping,它会不停的发送corvus notes去获取redis node与slots mapping的关系,并更新到corvus本身的缓存中,还有Multiple Thread、Lightweight和Reuseport support等。
Corvus commands
- Corvus支持Pipeline;
- Modified commands,对复合命令做spring操作,我们已经对命令本身进行了修改,但可能对我们看监控数据有疑惑,统计端节点命中率与应用程序命中率可能不一样;
- Restricted commands;
- Unsupported commands,比如对GU的处理,目前还没有在redis cluster中使用GU的应用,暂时不会支持。
Corvus performance
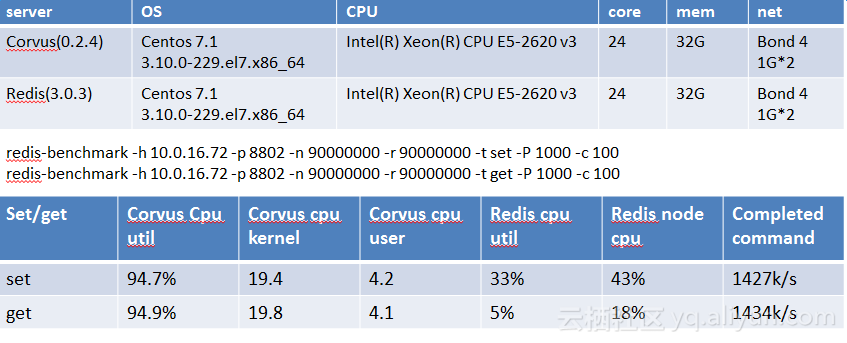
图中为corvus的测试报告,这是很极端的压测情况,set/get可以达到140万QPS数据。
Corvus 逻辑架构
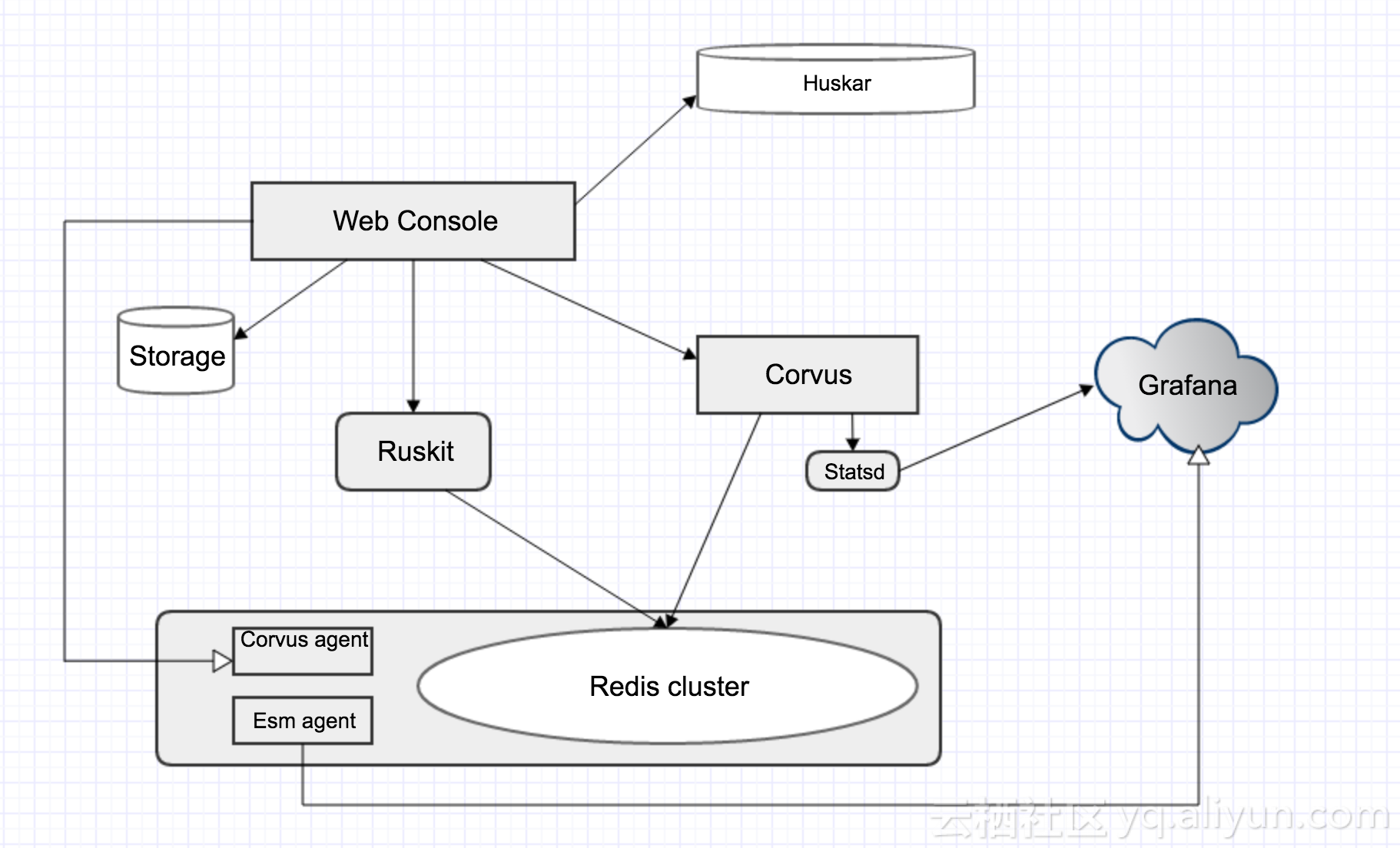
可以看到,底层存储用redis cluster,web console通过后端ruskit操作redis cluster,当我们注册redis cluster时,APPid存储在storage里,监控部分我们通过Esm agent发送到Grafana,corvus本身也会采集server log发送到Statsd去收集,corvus agent去部署时首先要初始化corvus agent注册到host console里,通过corvus agent去拉起或回收某一套redis cluster,Huskar是我们的集中配置管理,对应到我们后端的zk技术。
Corvus 物理部署
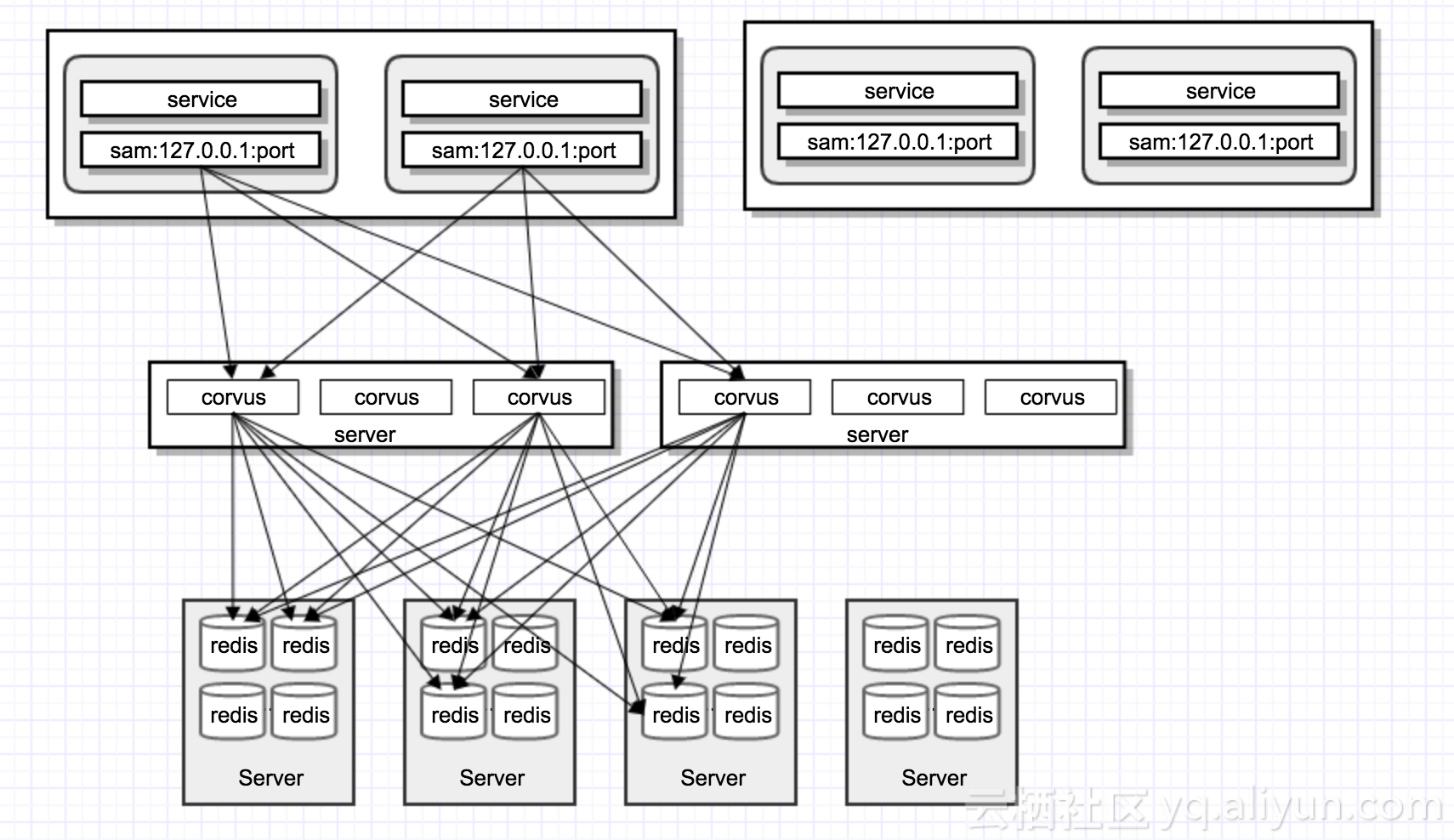
Corvus的物理部署如图所示,上面是应用程序端,应用程序连接到本地的corvus服务端口,corvus服务端口作为本地的sam port,一个corvus实例对应到redis cluster的一些master节点,会部署在不同的物理服务器上,根据不同的和数去创建corvus服务实例以及redis节点。
这里有两层proxy,首先连接本地的sam,也就是go proxy,go proxy这层提供应用服务化、本地接入,corvus是redis cluster proxy这一层,两层proxy意味着两层的性能损耗,在这个基础上,我们也做了针对redis cluster相同的直连的性能损失,对比来看,proxy层性能损耗相比运维成本以及服务化成本而言,是可以接受的。
Redis 运维和开发
Redis运维
- 我们将redis移交数据库团队运维
- 统一redis 物理部署架构
- 标准化redis/corvus 服务器以及单机容量
- 设定redis 开发设计规范
- 设定redis资源申请流程,做好容量评估
- 完善监控,监控分corvus和redis cluster两部分,跟进全链路压测,从最前端打进来,到底层的redis和数据库
- 根据压测结果做隔离关键集群,比如整个外卖后端和商户的redis,将它们做单独隔离,redis cluster本身对网卡要求很高,分专用资源和公共资源,专用资源的corvus或redis cluster机器独栈给到APPid,公共资源是混布情况,我们只需监控网卡流量、cpu等
- 升级万兆网卡,新采购的服务器都是万兆配置
Redis 开发约定
Redis开发约定如下:
- Key 格式约定:object-type:id:field。用":"分隔域,用"."作为单词间的连接,对于整个field怎样分隔,我们有很多种改法;
- 禁止大k-v,我们基于全链路压测,比如一套集群有多种类型的pattern的key,其中某一个的key value很长,占用内存很大,我们就要告诉开发者像这种使用姿势是不对的,须被禁止;
- 只用作cache, Key TTL设置;
- 做好容量评估,由于redis cluster的迁移限制,所以前期我们要做好容量评估,比如整套集群申请100G,我们需要计算需要的内存容量以及所在的应用场景负载;
- 设定集群上限,规定redis cluster集群数不超过200,单个节点容量4~8G;
- 接入统一为本地goproxy
Redis 改造
我们要定义一个节奏,对redis进行改造,具体如下:
1. 将Redis 迁移cluster
2. 完善system、redis、corvus监控
3. 对线上redis拆分、扩容
4. 非标机器腾挪下线
5. 大key、热节点、大节点扫描,比如同一个redis cluster集群某个节点明显高于其它节点,我们会做节点分析和key的分析等
6. 网卡Bond,多队列绑定
7. 修改jedis源码,加入matrix埋点上报etrace,就可以在etrace看到每个应用trace到整条链路到哪一个端口,它的响应时间、请求频次、命中率等。
经验总结
对于redis我们可谓经验丰富,总结如下:
- Redis 更适合cache,cluster下更不合适做持久化存储
- 一致性保证,不做读写分离(尽管corvus支持)
- 单实例不宜过大,节点槽位要均衡
- 发现问题,复盘,积累经验
- 不跨机房部署,性能优先
- 异地多活通过订阅消息更新缓存
- 大部分的故障都是由于hot-key/big-key
- 关心流量,必要时立刻升级万兆
遗留问题
目前redis还不够自动化,某些操作还是分成多个步骤来实现,大集群Reshard扩容慢;遇到版本升级问题时,可以新起一条集群;Sam->corvus->redis链路分析,应用程序在etrace上访问端口会很慢,需要从redis和corvus层层自证等;多活跨机房写缓存同步;我们通过定时任务的发起AOF/RDB来保证数据尽快恢复,实际上我们是关闭掉的;冷数据也是不够完善的,还有集群自愈,当遇到问题时我们可以快速拉起另外一套集群将数据更新过去,或者通过数据更新预热将缓存更新过去。
池化
我们在根据全链路压测时的一些特性或数据去做集群隔离,分放公共池和专用池,以及对整个池内资源做buffer的监控;资源申请只需关注容量以及使用方式,无需关心机器;另外,新申请以及扩容缩容按组(group)操作,运维操作自动化,不需要登录到某个机器上执行某个命令。
开发自助
我们最终的目标是在缓存部分实现开发自助,具体步骤如下:
1. 开发自助申请redis 资源
2. 填入demo key/value,自动计算容量
3. 状态,告警推送,对线上实时运行情况的透明化
4. 各类文档齐全
目前我们还做不到,需要OPS团队干预开发。
最后
以上就是认真帆布鞋最近收集整理的关于饿了么Redis Cluster集群化演进的全部内容,更多相关饿了么Redis内容请搜索靠谱客的其他文章。








发表评论 取消回复