编译原理
- 实现jsx语法转成js语法的编译器。
如将
<h1 id=“title”><span>hello</span>world</h1>
转成
React.createElement(
"h1", {id: title},
React.createElement("span", null, hello),"world"
)
步骤差不多就是,jsx代码->ast -> 处理转换ast -> ast生成js代码 -> js代码
编译器工作流
- 解析(parse),将原始代码转为更加抽象的抽象语法树(AST)
- 转换(transform), 对抽象语法树机进行处理
- 代码生成(code generation)接收处理之后的代码表示,把他转为新的代码。
解析
解析一般分为两个阶段,词法分析(Lexical Analysis)和语法分析(Syntactic Analysis)。
- 词法分析:接收源代码,将他分割成为token,这个过程在词法分析器完成。
- token是一个数组,由一些代码语句的语句组成,可以是数字,标签,标点符号,运算符等等。
- 语法分析接受token,转成更加抽象的表示,这种抽象的表示描述了代码语句中的每一个片段和他们之间的关系,称为AST,抽象语法树。
- 抽象语法树是一个嵌套成都很深的对象,用一种容易处理的方式代表了代码本身。
比如下面的jsx代码
<h1 id=“title”><span>hello</span>world</h1>
转成tokens就差不多是
[
{type: "Punctuator', value: '<'},
{type: 'JSXIdentifier', value: 'h1'},
.....
]
语法树就差不多是
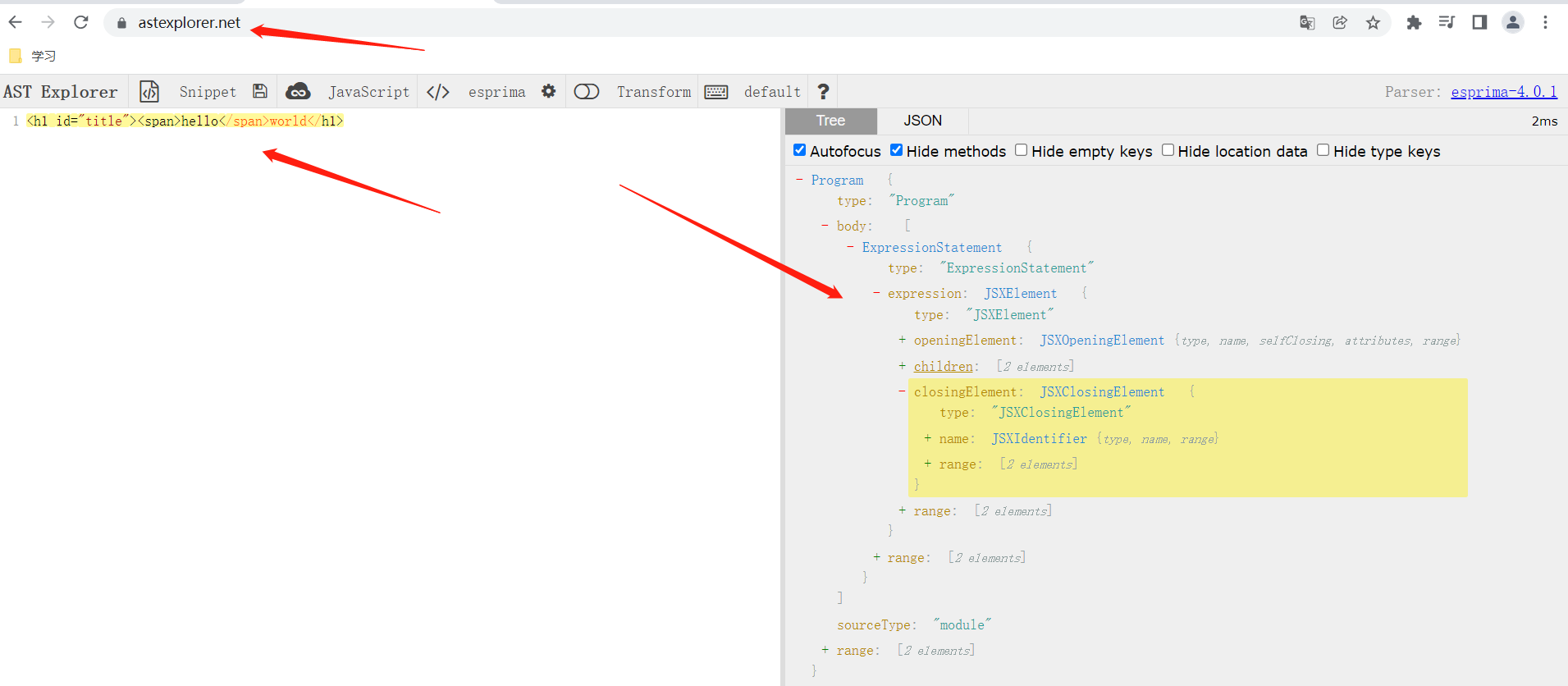
一个树级结构。
使用esprima看看
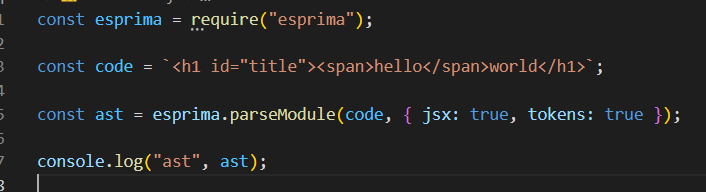
打印结果
ast Module {
type: 'Program',
body: [
ExpressionStatement {
type: 'ExpressionStatement',
expression: [JSXElement]
}
],
sourceType: 'module',
tokens: [
{ type: 'Punctuator', value: '<' },
{ type: 'JSXIdentifier', value: 'h1' },
{ type: 'JSXIdentifier', value: 'id' },
{ type: 'Punctuator', value: '=' },
{ type: 'String', value: '"title"' },
{ type: 'Punctuator', value: '>' },
{ type: 'Punctuator', value: '<' },
{ type: 'JSXIdentifier', value: 'span' },
{ type: 'Punctuator', value: '>' },
{ type: 'JSXText', value: 'hello' },
{ type: 'Punctuator', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'JSXIdentifier', value: 'span' },
{ type: 'Punctuator', value: '>' },
{ type: 'JSXText', value: 'world' },
{ type: 'Punctuator', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'JSXIdentifier', value: 'h1' },
{ type: 'Punctuator', value: '>' }
]
}
expirma内部要得到ast,
- 1 需要将源代码进行分析,得到tokens数组。
- 2 接着才能将tokens数组转成抽象语法树。
基本把js拆开了。
/**
* <h1 id="title"><span>hello</span>world</h1>
*
* <
* h1
* id
* =
* title
* >
* <
* span
* >
* hello
* <
* /
* span
* >
*/
遍历
- 对于能处理的所有节点,需要遍历他们,使用深度优先遍历。
使用estraverse遍历
const estraverse = require('estraverse-fb')
let indent = 0
function padding(){
return ' '.repeat(indent)
}
//深度优先遍历
estraverse.traverse(ast, {
enter(node){
console.log(padding() + node.type + '进入');
indent+=2
},
leave(node){
console.log(padding() + node.type + '离开');
indent-=2
}
})
结果
Program进入
ExpressionStatement进入
JSXElement进入
JSXOpeningElement进入
JSXIdentifier进入
JSXIdentifier离开
JSXAttribute进入
JSXIdentifier进入
JSXIdentifier离开
Literal进入
Literal离开
JSXAttribute离开
JSXOpeningElement离开
JSXClosingElement进入
JSXIdentifier进入
JSXIdentifier离开
JSXClosingElement离开
JSXElement进入
JSXOpeningElement进入
JSXIdentifier进入
JSXIdentifier离开
JSXOpeningElement离开
JSXClosingElement进入
JSXIdentifier进入
JSXIdentifier离开
JSXClosingElement离开
JSXText进入
JSXText离开
JSXElement离开
JSXText进入
JSXText离开
JSXElement离开
ExpressionStatement离开
Program离开
转换
当我们转化ast并且可以遍历后,下一步就是转换了。
- 转换就是对ast,进行遍历并且修改,操作ast,可以在同种语言下操作ast,也可以把ast翻译成全新的语言。
- ast有很多相似的元素,每个元素都有type属性,称为ast节点,他们都有若干属性,用来描述ast节点的信息,如
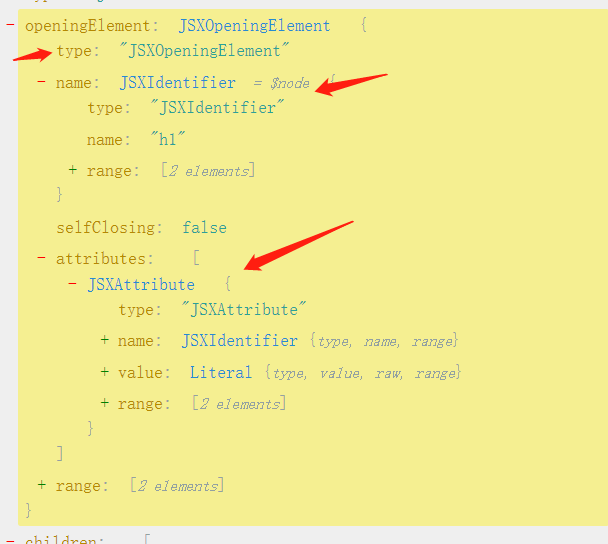
- 当转换ast的时候,可以添加,移动,删除这些节点。
- 最终将ast转换成我们想要的样式
代码生成
- 编译器的最后一个阶段就是代码生成,就是将转换后的ast生成代代码。
这就是编译器的工作流:解析-》转换-》代码生成。
有限状态机
有限状态机( FSM),是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。
- 每一个状态都是一个机器,每个机器都可以接收输入和计算输出
- 机器本身没有状态,每一个机器会根据输入决定下一个状态
通过状态机进行分词操作
分词 10+20
代码
/**
* 分词
* 状态机实现
*/
let tokens = [];
let NUMBERS = /[0-9]/;
//类型
const types = {
Numeric: "Numeric",
Punctuator: "Punctuator",
};
/**
* start表示开始状态函数
* 接受一个字符,返回下一个状态函数
*/
let currentToken;
function start(char) {
//第一个是1
if (NUMBERS.test(char)) {
//如果是数字,就生成新的token
currentToken = { type: types.Numeric, value: "" };
}
//进入下一个状态,收集number状态
return number(char);
}
/**
* number表示number状态的函数
*/
function number(char) {
if (NUMBERS.test(char)) {
// 当前char是number
currentToken.value += char;
//推断下一个还是Number状态
return number;
} else if (char === "+" || char === "-") {
emit(currentToken);
//将这个+/-也收集起来
emit({ type: types.Punctuator, value: char });
currentToken = { type: types.Numeric, value: "" };
return number; //继续准备收集number
}
}
/**
*
*/
function emit(token) {
//当遇到+,-的时候,就表示一个token结束了,该收集了。
tokens.push(token);
currentToken = { type: "", value: "" };
}
function tokenizer(input) {
let state = start;
for (let char of input) {
state = state(char);
}
if(currentToken.value.length > 0){
emit(currentToken)
}
}
tokenizer("10+20+30-10");
console.log(tokens);
// 打印结果是
[
{ type: 'Numeric', value: '10' },
{ type: 'Punctuator', value: '+' },
{ type: 'Numeric', value: '20' },
{ type: 'Punctuator', value: '+' },
{ type: 'Numeric', value: '30' },
{ type: 'Punctuator', value: '-' },
{ type: 'Numeric', value: '10' }
]
成功分词,这就是状态机的原理。比如一开始的start函数,然后第一个char是number,下一个运行的函数就变成了number函数。当前的状态根据当前的char决定下一个机器怎么处理。
实现编译器
转换ast
第一步,词法分析器
首先,定义token的类型
const types = {
leftParenthese: "leftParenthese", // <
jsxIdentifier: "jsxIdentifier", //jsx元素,如span h1等
AttributeKey: "AttributeKey", // 属性key 如id
Equal: "Equal", // =
AttributeStringVlaue: "AttributeStringVlaue", // 属性value, 如id='xx'中的xx
rightParenthese: "rightParenthese",
JsxText: "JsxText",
Punctuator: "Punctuator", // 反斜杠/
};
然后,根据有限状态机,分割token。
const tokens = [];
let currentToken = { type: "", value: "" };
function emit() {
if (currentToken.value.length > 0) {
tokens.push(currentToken);
}
currentToken = { type: "", value: "" };
}
// 开始的函数
function start(char) {
if (char === "<") {
currentToken.type = types.leftParenthese;
currentToken.value = "<";
emit();
//准备接收jsx元素
return foundLeftParenthese; // 找到了 '<'
}
//
throw new Error("第一个字符串必须是<");
}
function tok
enizer(input) {
let state = start; //第一次处于start状态
for (let char of input) {
//遍历所有字符串
if (state) {
state = state(char);
}
}
return tokens;
}
const code = `<h1 id="title"><span>hello</span>world</h1>`;
console.log(tokenizer(code));
- 第一次执行的函数是start,因为解析jsx,所以第一个字符必须是‘<’,接着对第一个字符分词。然后根据第一个字符的状态返回foundLeftParenthese函数。
- 对于<后面的判断,可能是普通值,就表示他是一个jsx标识符,应该返回jsxIdentifier函数。
- 如果<后面是’/’,表示他是一个标签的结束标签,就应该继续判断。
// 找到<后的函数
function foundLeftParenthese(char) {
if (LETTERs.test(char)) {
// h
// char是一个小写字母
currentToken.type = types.jsxIdentifier;
currentToken.value += char;
return jsxIdentifier; //返回的状态是继续收集标识符
} else if (char === "/") {
// </h1>结束标签
currentToken.type = types.Punctuator;
currentToken.value = "/";
emit();
return foundLeftParenthese;
} else {
throw new Error("foundLeftParenthese 找到<后语法报错");
}
}
- 然后依次类推,根据值的不同状态,使用不同函数处理值。
- 全部代码:
//类型
const types = {
leftParenthese: "leftParenthese", // <
jsxIdentifier: "jsxIdentifier", //jsx元素,如span h1等
AttributeKey: "AttributeKey", // 属性key 如id
Equal: "Equal", // =
AttributeStringVlaue: "AttributeStringVlaue", // 属性value, 如id='xx'中的xx
rightParenthese: "rightParenthese",
JsxText: "JsxText",
Punctuator: "Punctuator", // 反斜杠/
};
const LETTERs = /[a-z1-9]/;
const tokens = [];
let currentToken = { type: "", value: "" };
function emit() {
if (currentToken.value.length > 0) {
tokens.push(currentToken);
}
currentToken = { type: "", value: "" };
}
// 开始的函数
function start(char) {
if (char === "<") {
currentToken.type = types.leftParenthese;
currentToken.value = "<";
emit();
//准备接收jsx元素
return foundLeftParenthese; // 找到了 '<'
}
//
throw new Error("第一个字符串必须是<");
}
//结束了
function eof() {
if (currentToken.value.length > 0) {
emit();
}
}
// 找到<后的函数
function foundLeftParenthese(char) {
if (LETTERs.test(char)) {
// h
// char是一个小写字母
currentToken.type = types.jsxIdentifier;
currentToken.value += char;
return jsxIdentifier; //返回的状态是继续收集标识符
} else if (char === "/") {
// </h1>结束标签
currentToken.type = types.Punctuator;
currentToken.value = "/";
emit();
return foundLeftParenthese;
} else {
throw new Error("foundLeftParenthese 找到<后语法报错");
}
}
//找到jsx后的函数
function jsxIdentifier(char) {
if (LETTERs.test(char)) {
// 1
// char是一个小写字母或者数字
currentToken.value += char;
return jsxIdentifier; //返回的状态是继续收集标识符
} else if (char === " ") {
//遇到空格,表示一个jsx收集完毕
emit();
//可能需要收集属性了
return attribute;
} else if (char === ">") {
emit();
// 这个jsx没有属性的
currentToken.type = types.rightParenthese;
currentToken.value = ">";
emit();
return foundRightParenthese;
}
}
// 准备收集属性的函数
function attribute(char) {
// id="xx"
if (LETTERs.test(char)) {
currentToken.type = types.AttributeKey;
currentToken.value += char;
// 需要收集key了
return attributeKey;
}
}
//准备收集属性key的函数
function attributeKey(char) {
if (LETTERs.test(char)) {
currentToken.value += char;
return attributeKey;
} else if (char === "=") {
// key收集完毕
emit();
currentToken.type = types.Equal;
currentToken.value = "=";
emit();
return attributeValue;
}
}
//准备收集属性的value了
function attributeValue(char) {
// "xx"
if (char === '"') {
currentToken.type = types.AttributeStringVlaue;
currentToken.value = "";
return AttributeStringVlaue;
}
}
// 收集属性字符串value
function AttributeStringVlaue(char) {
// xx"
if (LETTERs.test(char)) {
currentToken.value += char;
return AttributeStringVlaue;
} else if (char === '"') {
//收集结束
emit();
//继续收集下一个属性或者是 '>'
return tryLeaveAttribute;
}
}
// 试图离开属性收集
function tryLeaveAttribute(char) {
if (char === " ") {
//后面是空格,表明是一个新的属性
return attribute;
} else if (char === ">") {
//结束收集
currentToken.type = types.rightParenthese;
currentToken.value = ">";
emit();
// 状态到了找到'>的状态
return foundRightParenthese;
} else {
throw new TypeError("不是合法的字符串");
}
}
// 遇到了>的状态
function foundRightParenthese(char) {
if (char === "<") {
//开启新的元素
return start(char);
} else {
//否则就是jsx文本
currentToken.value += char;
currentToken.type = types.JsxText;
return jsxText;
}
}
// 遇到了jsxText后的状态
function jsxText(char) {
if (char) {
//结束jsxText收集
if (char === "<") {
emit();
// 开启新元素的收集
currentToken.type = types.leftParenthese;
currentToken.value = "<";
emit();
return foundLeftParenthese;
} else {
currentToken.value += char;
return jsxText;
}
} else {
currentToken.value += char;
return jsxText;
}
}
function tokenizer(input) {
let state = start; //第一次处于start状态
for (let char of input) {
//遍历所有字符串
if (state) {
state = state(char);
}
}
return tokens;
}
const code = `<h1 id="title"><span>hello</span>world</h1>`;
console.log(tokenizer(code));
module.exports = {
tokenizer,
};
最后的结果是:
使用exprima分词
[
{ type: 'Punctuator', value: '<' },
{ type: 'JSXIdentifier', value: 'h1' },
{ type: 'JSXIdentifier', value: 'id' },
{ type: 'Punctuator', value: '=' },
{ type: 'String', value: '"title"' },
{ type: 'Punctuator', value: '>' },
{ type: 'Punctuator', value: '<' },
{ type: 'JSXIdentifier', value: 'span' },
{ type: 'Punctuator', value: '>' },
{ type: 'JSXText', value: 'hello' },
{ type: 'Punctuator', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'JSXIdentifier', value: 'span' },
{ type: 'Punctuator', value: '>' },
{ type: 'JSXText', value: 'world' },
{ type: 'Punctuator', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'JSXIdentifier', value: 'h1' },
{ type: 'Punctuator', value: '>' }
]
使用自己编写的tokenizer
[
{ type: 'leftParenthese', value: '<' },
{ type: 'jsxIdentifier', value: 'h1' },
{ type: 'AttributeKey', value: 'id' },
{ type: 'Equal', value: '=' },
{ type: 'AttributeStringVlaue', value: 'title' },
{ type: 'rightParenthese', value: '>' },
{ type: 'leftParenthese', value: '<' },
{ type: 'jsxIdentifier', value: 'span' },
{ type: 'rightParenthese', value: '>' },
{ type: 'JsxText', value: 'hello' },
{ type: 'leftParenthese', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'jsxIdentifier', value: 'span' },
{ type: 'rightParenthese', value: '>' },
{ type: 'JsxText', value: 'world' },
{ type: 'leftParenthese', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'jsxIdentifier', value: 'h1' },
{ type: 'rightParenthese', value: '>' }
]
可以看到分词成功。
总结:
- 有限状态机( FSM),是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。
- 分词就是使用有限状态机的概念,根据传入的值,返回不同的状态(函数)进行处理。比如遇到<,就返回处理<后的函数。遇到了>,就返回处理>后的函数。通俗的讲,就是少写点if else。通过状态函数取而代之。(个人理解,方便记忆)
最后
以上就是平淡钢铁侠最近收集整理的关于ast编译原理-1-词法分析的全部内容,更多相关ast编译原理-1-词法分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。





![[数字电子技术期末95+]考前突击总结一遍易错点、难点、重点、遗漏点](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)


发表评论 取消回复