监控是整个运维乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供详实的数据用于追查定位问题;运维自动化最重要的就是标准化一切,而监控是运维自动化体系的一环。
一、 监控运维
一般公司里的运维,大致可以分为基础运维、应用运维、运维开发、监控组四大部分,而监控是所有运维的基础。
- 基础运维,负责IDC运维,服务器上下架,网络设备等。
- 应用运维,也就是system administrator,系统管理员。
- 运维开发,负责运维工具的开发,系统开发等,例如开发监控系统,代码发布系统。
- 监控组,也就是24小时值班的人员,需要时刻关注服务器,网站的状况,出现问题后,第一时间联系相关运维以及研发人员。
二、 监控目标
监控贯穿应用的整个生命周期。即从程序设计、开发、部署、下线,监控是需要站在公司的业务角度去考虑,而不是针对某个监控技术的使用。监控的目标包括:
- 对系统不间断的实时监控。
- 实时反馈系统当前状态。
- 保证服务可靠性安全性。
- 保证业务持续稳定运行。
三、 监控方法
- 健康检查。健康检查是对应用本身健康状况的监控,检查服务是否还正常存活。
- 日志。日志是排查问题的主要方式,日志可以提供丰富的信息用于定位和解决问题。
- 调用链监控。调用链监控可以完整的呈现出一次请求的全部信息,包括服务调用链路、所耗时间等。
- 指标监控。指标是一些基于时间序列的离散数据点,通过聚合和计算后能反映出一些重要指标的趋势。
四、 监控思路
- 了解监控对象:我们要监控的对象你是否了解呢?比如CPU到底是如何工作的?
- 性能基准指标:我们要监控这个东西的什么属性?比如CPU的使用率、负载、用户态、内核态、上下文切换。
- 报警阈值定义:怎么样才算是故障,要报警呢?比如CPU的负载到底多少算高,用户态、内核态分别跑多少算高?
- 故障处理流程:收到了故障报警,我们怎么处理呢?有什么更高效的处理流程吗?
五、 监控流程
- 发现问题:当系统发生故障报警,我们会收到故障报警的信息
- 定位问题:故障邮件一般都会写某某主机故障、具体故障的内容,我们需要对报警内容进行分析,比如一台服务器连不上:我们就需要考虑是网络问题、还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等等,我们就需要去分析故障具体原因。
- 解决问题:当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障。
- 总结问题:当我们解决完重大故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现。
六、 监控流程
基于Zabbix来构建整个监控体系生态圈。下面我们就来监控系统的整个流程:
- 数据采集:Zabbix通过SNMP、Agent、ICMP、SSH、IPMI等对系统进行数据采集;
- 数据存储:Zabbix存储在MySQL上,也可以存储在其他数据库服务;使用数据库是必备技能。
- 数据分析:当我们事后需要复盘分析故障时,Zabbix能给我们提供图形以及时间等相关信息,方面我们确定故障所在;
- 数据展示:Web界面展示、(移动APP、java_php开发一个Web界面也可以);
- 监控报警:电话报警、邮件报警、微信报警、短信报警、报警升级机制等(无论什么报警都可以);
- 报警处理:当接收到报警,我们需要根据故障的级别进行处理,比如:重要紧急、重要不紧急,等。根据故障的级别,配合相关的人员进行快速处理。
七、 监控指标
- 硬件监控
可以通过IPMI对硬件详细情况进行监控,并对CPU、内存、磁盘、温度、风扇、电压等设置报警设置报警阈值(自行对监控报警内容编写合理的报警范围)
IPMI工具无法获取到硬件的状态,可以借助MegaCli工具探测Raid磁盘队列状态 zabbix提供IPMI监控模板:Zabbix
IPMI Interface,系统自带的IPMI模板只能监控,风扇,电源,和部分温度
- 系统监控
中小型企业基本全是Linux服务器,固需要监控系统资源的使用情况,系统监控是监控体系的基础。 监控主要对象:
CPU有几个重要的概念:上下文切换、运行队列和使用率。这也是我们CPU监控的几个重点指标。通常情况,每个处理器的运行队列不要高于3,CPU
利用率中“用户态/内核态”比例维持在70/30,空闲状态维持在50%,上下文切换要根据系统繁忙程度来综合考量。针对CPU常用的工具有:htop、top、vmstat、mpstat、dstat、glances
zabbix提供系统监控模板:Zabbix Agent Interface 负载状态
内存:通常我们需要监控内存的使用率、SWAP使用率、同时可以通过zabbix描绘内存使用率的曲线图形发现某服务内存溢出等。
针对内存常用的工具有: free、top、vmstat、glances 内存使用率
IO分为磁盘IO和网络IO。除了在做性能调优我们要监控更详细的数据外,那么日常监控,只关注磁盘使用率、磁盘吞吐量、磁盘写入繁忙程度,网络也是监控网卡流量即可。
常用工具有:iostat、iotop、df、iftop、sar、glances 其它的系统监控还有运行的进程端口、进程数、登陆用户、Open
File等(详细查看zabbix自带OS Linux模板)
- 应用监控
应用服务监控也是监控体系中比较重要的内容,例如:LVS、Haproxy、Docker、Nginx、PHP、Memcached、Redis、MySQL、Rabbitmq等等,相关的服务都需要使用zabbix监控起来。
zabbix提供应用服务监控:Zabbix Agent UserParameter zabbix提供的Java监控:Zabbix JMX Interface percona提供MySQL数据库监控:percona-monitoring-plulgins
- 网络监控
微服务都是通过网络调用或被调用,一旦网络出现问题,整个微服务集群都是不可用的,所以网络监控需要细化到流量、数据包、丢包、错报、连接数等指标。我们需要借助于网络监控工具Smokeping。
Smokeping 是rrdtool的作者Tobi Oetiker的作品,是用Perl写的,主要是监视网络性能,www服务器性能,dns查询性能等,使用rrdtool绘图,而且支持分布式,直接从多个agent进行数据的汇总。
同时,由于自己监控点比较少,还可以借助很多商业的监控工具,比如监控宝、听云、基调、博瑞等。同时这些服务提供商还可以帮助你监控CDN的状态。
- 流量分析
网站流量分析对于运维人员来说,更是一门必须掌握的知识了。百度统计、google分析、站长工具等等,只需要在页面嵌入一个js即可。但是,数据始终是在对方手中,个性化定制不方便,于是google出一个叫piwik的开源分析工具
- 日志监控
通常情况下,随着系统的运行,操作系统会产生系统日志,应用程序会产生应用程序的访问日志、错误日志,运行日志,网络日志,我们可以使用ELK来进行日志监控。
对于日志监控来说,最见的需求就是收集、存储、查询、展示,开源社区正好有相对应的开源项目:logstash(收集) +elasticsearch(存储+搜索) + kibana(展示) 我们将这三个组合起来的技术称之为ELK Stack,所以说ELK Stack指的是Elasticsearch、Logstash、Kibana技术栈的结合。
- 安全监控
虽然Linux开源的安全产品不少,比如四层iptables,七层WEB防护nginx+lua实现WAF,最后将相关的日志都收至Elkstack,通过图形化进行不同的攻击类型展示。但是始终是一件比较耗费时间,并且个人效果并不是很好。这个时候我们可以选择接入第三方服务厂商。
三方厂商提供全面的漏洞库,涵盖服务、后门、数据库、配置检测、CGI、SMTP等多种类型,全面检测主机、Web应用漏洞自主挖掘和行业共享相结合第一时间更新0day漏洞,杜绝最新安全隐患
- API监控
由于API变得越来越重要,很显然我们也需要这样的数据来分辨我们提供的
API是否能够正常运作。监控API接口GET、POST、PUT、DELETE、HEAD、OPTIONS的请求
可用性、正确性、响应时间为三大重性能指标。
- 性能监控
全面监控网页性能,DNS响应时间、HTTP建立连接时间、页面性能指数、响应时间、可用率、元素大小等 zabbix提供URL监控:Zabbix
Web 监控 第三方监控监控大盘。各类图表一目了然,全面体现网页性能健康状况。
- 业务监控
主要是监控一些核心业务执行情况,对业务有一定的侵入性。没有业务指标监控的监控平台,不是一个完善的监控平台,通常在我们的监控系统中,必须将我们重要的业务指标进行监控,并设置阈值进行告警通知。
八、 监控告警
故障报警通知的方式有很多种,当然我们最常用的还是短信,邮件。
九、 告警处理
在处理故障之前,需要先清晰的认识是什么样的故障,然后再采取什么样的措施。所以我们就需要对故障等级做一个划分。例如将系统故障等级按照《信息系统安全等级保护基本要求》具体划分为四个等级,一级和二级故障为重大故障;三级和四级故障为一般性故障。我们通常根据故障的级别,故障的业务,来指派不同的运维人员进行处理。
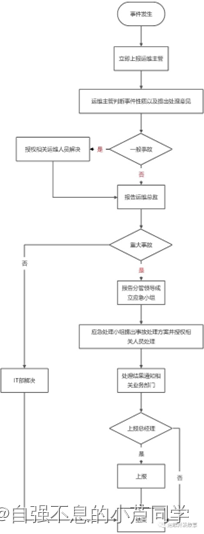
- 故障处理程序
- 故障发现:工作人员在发现故障或接收到故障报告后,首先要记录故障发生时间和发现时间,及发现部门,发现人及联系电话,对故障的等级进行初步判定,并报告相关人员进行处理。
- 故障处理:发生故障的系统通知到运维人员,运维人员应先询问了解设备和配置近期的变更情况,查清故障的影响范围,从而确定故障的等级和发生故障的可能位置;对于一般性故障按照规定的故障升级上报要求进行上报,并在处理过程中及时向主管领导通报故障处理情况;对于重大故障按照规定的故障升级上报要求进行上报,并在处理过程中及时向主管领导通报故障处理情况。
- 故障上报:根据故障等级和发生的时限,要对故障的情况进行及时的上报,并对报告人,告知人际时间内容进行记录。重大故障由故障处理组领导负责上报,一般性故障由故障处理人员负责上报。
- 故障处理流程图
最后
以上就是清脆老鼠最近收集整理的关于运维监控资料总结的全部内容,更多相关运维监控资料总结内容请搜索靠谱客的其他文章。








发表评论 取消回复