来源: AINLPer 微信公众号(每日更新…)
编辑: ShuYini
校稿: ShuYini
时间: 2021-11-16
Paper: RP-DNN: A Tweet level propagation context based deep neural networks for early rumor detection in Social Media.
该篇是英国谢菲尔德大学发表的一篇关于舆论分析检测防控的文章,该篇文章主要针对当前舆论检测算法的不足(当前算法主要是对已经引起的舆论进行级别检测,而没有去提前分析可能引起舆论的言论,进而错失掌控舆论发酵的最佳时机),为此本文一种新的混合神经网络结构来解决该问题。
关注AINLPer 微信公众号(每日更新…)回复:RP-DNN 获取论文
文章摘要
针对谣言分析,当前大多数方法主要是对事件级别进行检测,事件级别检测需要收集与特定事件相关的帖子,比较依赖用户发表的内容。它们不适合在事件发展传播的早期阶段进行谣言检测。在本文我们在消息级别解决了Early rumor detection(ERD)的任务。提出了一种新的混合神经网络结构,它结合了基于任务特征的双向语言模型和堆叠式长短期记忆(LSTM)网络来表示文本内容和输入源推文的社会时态上下文,用于模拟谣言在其发展初期的传播模式。我们应用多层注意模型在多个上下文输入上联合学习注意力上下文嵌入。 本文实验对七个公开的现实生活中的谣言事件数据集进行了严格的LOO-CV评估设置。本文模型实现了先进的(SoA)性能。
文章背景介绍
为了理解谣言事件的发生和发展,当前针对对社交媒体谣言的研究也变得越来越流行,为了限制谣言的传播并使其影响最小化,需要一种自动有效的方法来及早识别谣言。
一个典型的谣言解决过程可以包括四个子任务:谣言检测、跟踪、立场分类和验证。 谣言检测是谣言解决的基础工作,其目的是识别言论是谣言还是非谣言。一旦确定了谣言,就要跟踪其随时间的演变,确定其来源,执行立场检测,并最终确定其准确性。最近对网络谣言的研究主要集中在过程的后期阶段,即立场分类和验证。虽然这些对于谣言的解决至关重要,但是在谣言被识别之前,我们不能对其进行处理。一些研究跳过了这个初步的任务,所以在本文我们提出了开发自动化的ERD系统贯穿整个谣言解决过程。
本文主要提出了一种混合的、上下文感知的深层神经网络框架,用于推特级的ERD,它不仅能够学习谣言的文本内容,更重要的是能够学习谣言传播的社会时间背景。 大量关于谣言检测的SoA研究只利用单词级别的语言建模来处理tweet源及其上下文的内容(通常是回复)。相比之下,我们更注重在社会环境层次上的建模。社交上下文信息通常是指源tweet的会话线程,例如Twitter中的回复和转发。会话线索提供了时间序列信息,说明散布谣言如何改变人们的观点,以及社交媒体如何允许自我纠正。
文章主要内容
(1)本文提出了一种混合的深度学习架构来检测单个推文级别的谣言,而最近的大部分工作都集中在事件级别的分类。它在推特级ERD上提高了SoA性能。
(2)通过谣言任务特定的神经语言模型和多层时间注意力机制,我们开发了一个上下文感知模型,该模型从包括SC、CC和CM在内的多个相关上下文输入中学习统一的、抗噪声的谣言表示。
(3)利用最近发布的一个大型的、增强的谣言数据集来训练我们提出的模型。在消融研究和looc - cv的基础上进行了大量的实验,以检验其有效性和可推广性。实验发现本文模型在推特级别的谣言检测方面优于SoA模型,并达到了与SoA事件级别的谣言检测模型相当的性能。
模型介绍
本文提出的基于推特谣言传播的深度神经网络(RP-DNN)的总体架构下图所示。
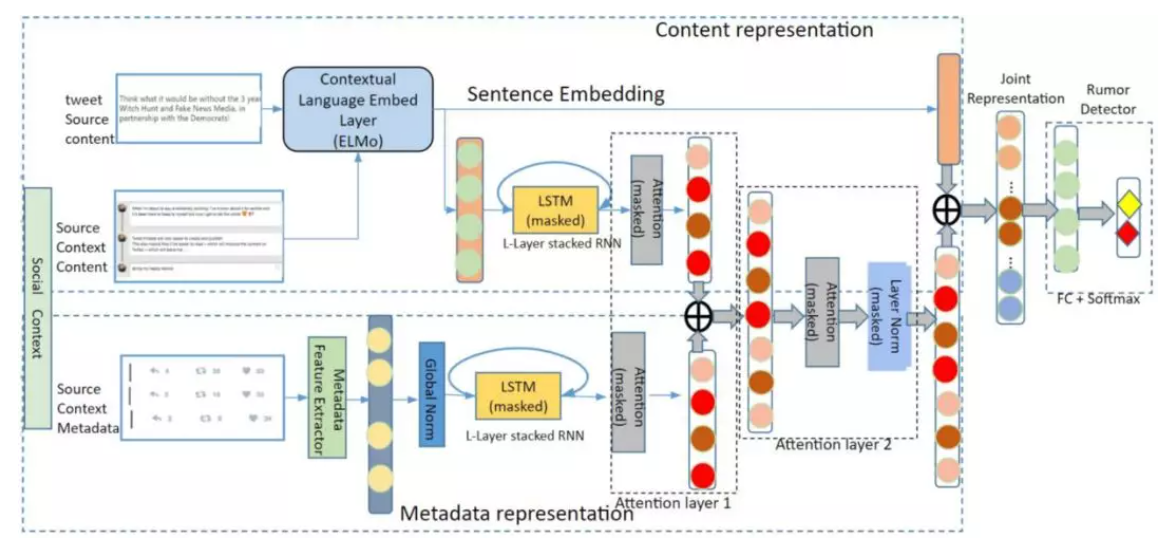
基本上,本文神经网络模型需要推特原文及其相应的上下文( 图片 和 图片 )作为输入来预测输出图片 。神经网络RP-DNN由四个主要部分组成:1)数据编码层,2)叠加RNN层,3)叠加注意力模型,4)分类层。
使用RP-DNN的Tweet-level EDR遵循四个关键阶段:
阶段一、 一旦加载并预处理了tweet候选源 X和相关上下文输入( 图片 和 图片 ),这两种原始上下文输入将在数据编码层中进行编码。这些重要的层将tweet源和会话上下文转换为后续RNN层的上下文输入。它由一个内容嵌入层和一个元数据编码层组成。前者的目标是将tweets转换为embeddings 图片 ,后者的目标是使用元数据特征提取器(MFE)从相应的tweets元数据中提取特征,这些特征主要描述了其传播模式。MFE的输出被表示为特征向量 图片 ,通过应用从训练数据计算得到的全局均值和方差对其进行归一化。
阶段二、 随后,编码的上下文输入将被输入到一个由堆叠的RNN层和堆叠的注意力模型组成的社会-时间上下文表示层。这里将多个LSTM堆叠在一起,形成一个堆叠的LSTM,该LSTM接受输入表示并按时间顺序排列。设层数为L。L-layer LSTMs(在本例中为L = 2)分别用于处理这两种类型的上下文数据。
阶段三、 递归结构模型以序列数据为特征,利用软层次注意力模型(第一注意层)进行最优表示。然后,将来自两个递归层(隐藏状态)输出( 图片 和 图片 )的上下文嵌入进行临时组合,形成联合表示( 图片 )。第三个注意模型(第二注意层)在联合隐藏顺序嵌入 图片 上执行,最终产生上下文序列 图片 的紧凑表示,然后进行掩蔽层归一化。
阶段四、 最后,我们将SC和context的两个嵌入通过拼接的方式组合在一起,在分类层形成最终的谣言源表示。最终的输出层,提供了谣言检测的结果。通过计算交叉熵损失来优化整个网络。一个三层的全连接神经网络(带有Leaky ReLu激活和softmax函数),最终的表现形式产生输出。
实验结果
SoA性能 如表4和表5所示,我们提出的模型产生了SoA性能,其测试数据更大,可与两种不同评估技术下的所有基线模型相比,而我们的体系结构提供了更抽象的上下文表示,并且没有特别对真实性的许多方面建模。
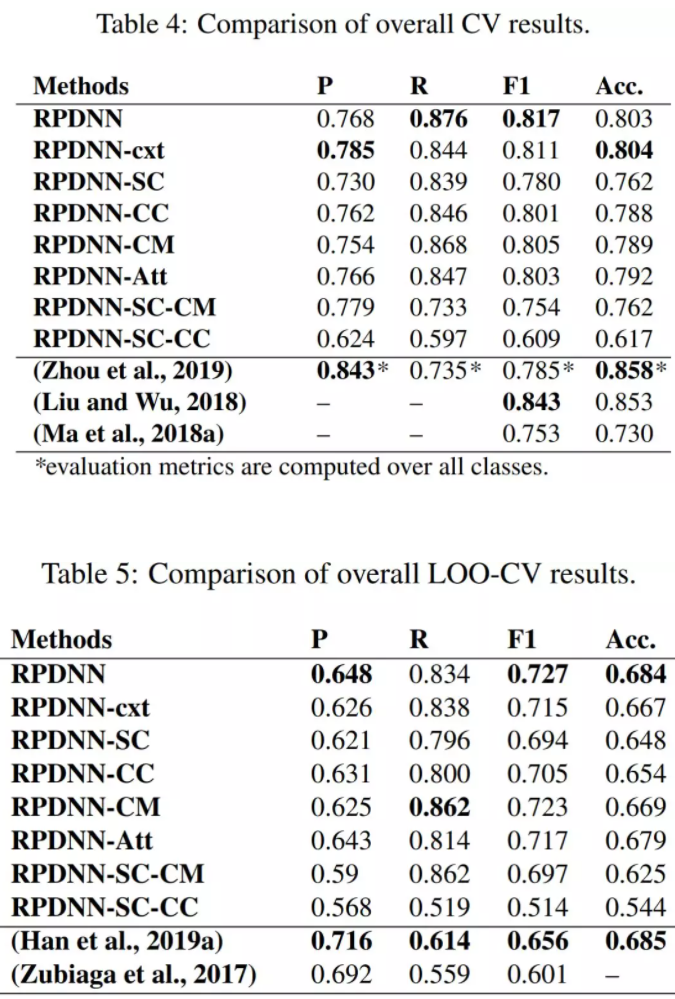
消融研究:1)源内容:候选源tweets的内容可以被认为是ERD中最重要和最具影响力的因素。2)会话语境:tweets源的语境可以提供额外有效的信息来检测谣言。3)上下文注意机制:通过比较完整模型和排除注意模型的性能,我们进一步证明了将叠加的注意力机制合并到上下文模型中的好处。
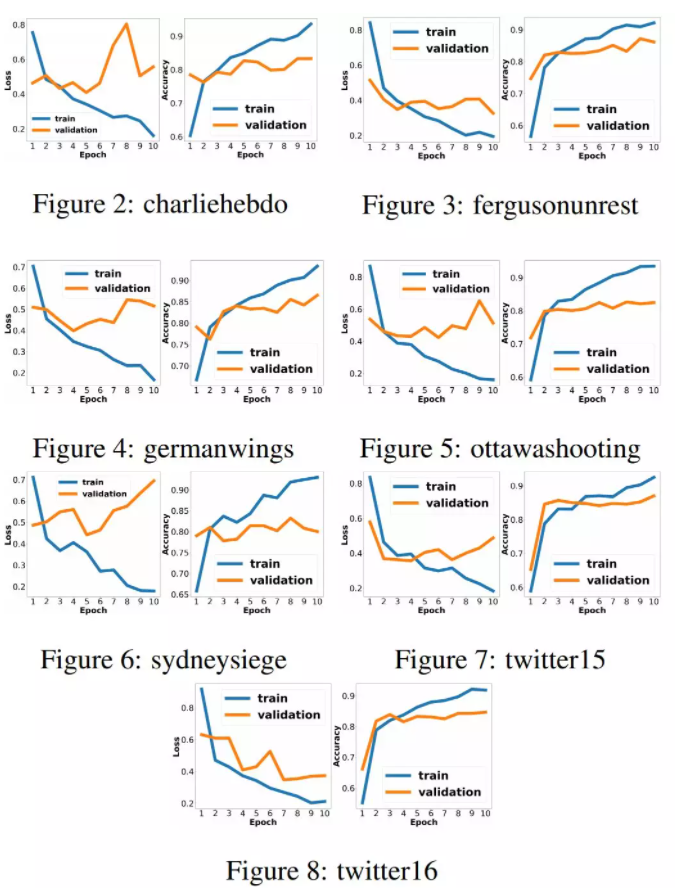
训练性能表现: 在实验的基础上,为了避免过拟合,我们将epoch的数量设置为10。下图为“RPDNN”模型在7倍lu - cv训练过程中,训练损失和10个epoch随时间变化的精度曲线。7个LOO模型的数据显示,训练损耗在前5个epoch内稳定下降,在第10个epoch后有过度拟合的趋势。相比之下,我们发现所有LOO模型的训练集和验证集的准确性都在不断提高。
推荐阅读
1、必看!!【AINLPer】自然语言处理(NLP)领域知识&&资料大分享
2、【硬核干货,请拿走!!】历年IJCAI顶会论文整理(2016-2021)
3、【EMNLP2021&&含源码&&中科院+腾讯PCG】跨度提取QA形式算法改进!!
4、【EMNLP2021&&含源码】当“Attention“遇到”Fast Recurrence“,强大的语言训练模型!!
最后
以上就是瘦瘦长颈鹿最近收集整理的关于(含源码)「自然语言处理(NLP)」社交媒体舆论控制(RP-DNN)的全部内容,更多相关(含源码)「自然语言处理(NLP)」社交媒体舆论控制(RP-DNN)内容请搜索靠谱客的其他文章。








发表评论 取消回复