前情回顾
特斯拉的辅助驾驶一直贯彻纯视觉方案,环绕车身共配有 8 个摄像头,视野范围达 360 度,对周围环境的监测距离最远可达 250 米。12 个新版超声波传感器作为整套视觉系统的补充,可探测到柔软或坚硬的物体,增强版前置雷达通过发射冗余波长的雷达波,能够穿越雨、雾、灰尘,甚至前车的下方空间进行探测,为视觉系统提供更丰富的数据。
- 车头6个、车尾6个,共12个超声波传感器;
- 前挡风玻璃下内后视镜上端长焦、标准、短焦共3个前视摄像头;
- 外后视镜前端翼子板后端两侧2个后侧视摄像头;
- 前后门中柱靠上端两侧共2个侧视摄像头;
- 后窗上部中间1个后视摄像头;
- 后车牌位置上一个倒车摄像头;
- 前保险杠中部1个毫米波雷达。
下图是AP2.5版本的传感器配置图:
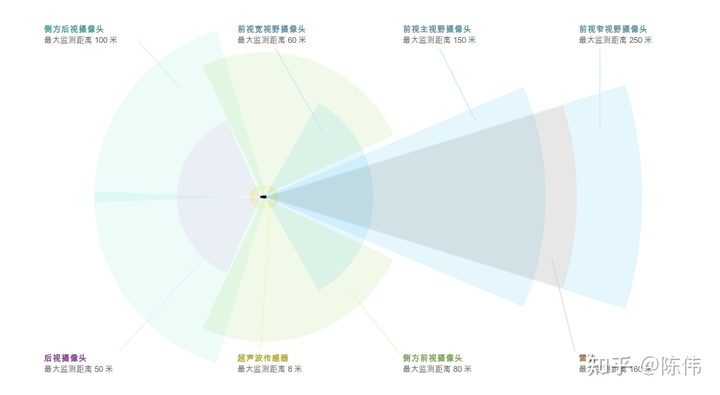
细心的小伙伴会发现不是说纯视觉方案嘛,怎么还有一颗前雷达?
不得不说特斯拉早期的纯视觉路线还是应用了毫米波雷达的,只是当它们的视觉感知越来越成熟以后才对纯视觉路线进行一次“提纯”,彻底舍弃掉毫米波雷达。

而在今年五月份,特斯拉又宣布在北美市场售卖的 Model 3/Y将不再配超声波雷达,仅标配摄像头。再次将纯视觉方案提纯到极致。用Andrej的理念来说,人类依赖视觉开车,通过大脑理解周围环境。那么摄像头+深度网络也行~~~
不过小编不敢苟同,有点过于激进,是否最终完美性能的达成将踩在多少次事故的积累之上。毕竟相比人脑的学习模式,深度学习技术还是有其天然硬伤。
本篇主要是来说说在这次的Tesla AI Day中从FSD视觉感知的角度给我们带来了哪些可以学习的方向。还是回归正题,不diss马斯克的纯视觉之路了。
感知源泉
小编接触过不少做视觉算法的小伙伴,不管是在给图像打标签,还是在设计算法模块,或者在评估某张图片中的物体是否应该被检测到。这其中都带有一定的主观成分,经常会去类比:
- 人眼去看这个物体是否能识别它是什么?
- 人眼是如何测量物体到我之间的距离?
- 人类是如何加深对场景的认知能力?
- 人类是如何应对特殊场景的突发状况?
在Andrej介绍Tesla视觉感知部分的开篇为我们引入了仿生学的理念,将人眼视网膜对应摄像头,复杂的视觉皮层对深度神经网络的关系。如下图所示:
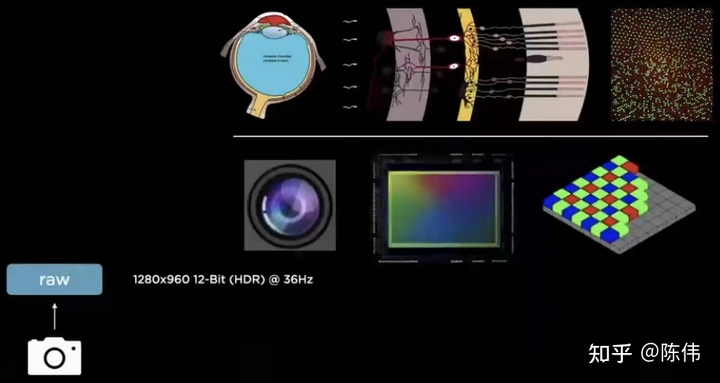
静下来想想我们会察觉到许多视觉算法模块和生活周遭惊人的相似,举几个不恰当的例子:
当你王者荣耀打多了,眼睛近视看东西模糊了怎么办?去眼镜店会给你检查度数配一个眼镜。标定:摄像头安装在车上时间久了发生偏移了怎么办?我们会设计静态和动态标定算法,得到摄像头的内外参,最后通过参数的矩阵变换来调整畸变的图像。
当你在路上开车遇到这个图标的车cut in到你前面了。这时候别人会告诉你,离它远点暂时还碰不起~~~,这就是一个学习的过程。识别:当摄像头第一次看到躺在地上的人时可能也不认识,这时候就要多采集几张图片打个标签告诉计算机它是什么。

当你在打羽毛球时,看到对面打算跳起扣杀时,你是否要预判球的飞行轨迹以及落球点在哪里,以便能接住。跟踪:自动驾驶车辆行驶在道路上,当检测前方路口处有行人时,往往需要通过滤波等算法预测出行人的运动轨迹,从而判断是否需要停靠等待或者减速通过。

丹炉设计
模型设计这个话题,在这次分享中抛出了几个方向:
- 如何从低层级特征图中提炼出比较好的特征信息
- 如何通过网络实现感知算法中多种任务
- 如何解决图像感知中缺乏的信息连贯性
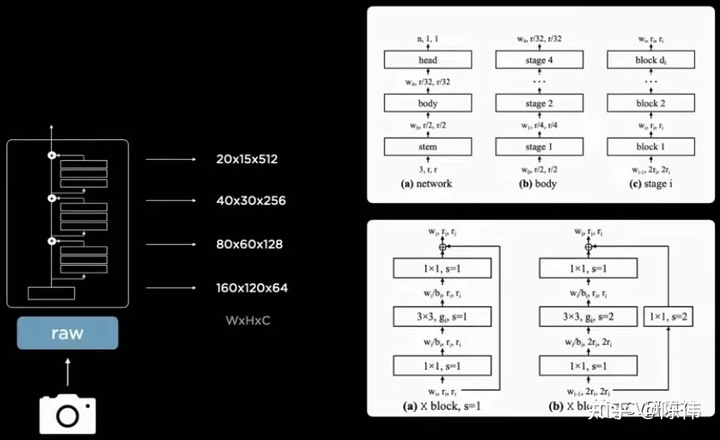
在特征提取部分给出的理念还算比较大众化,毕竟炼丹是项技术活,纵使同一个丹炉不同火候练出来丹药也会乘次不齐,原则上就是:
- 主干网络的特征共享机制
- 残差模块权衡延迟和准确性
- 顶层和底层上下文特征融合
- 多尺度信息的相互补充
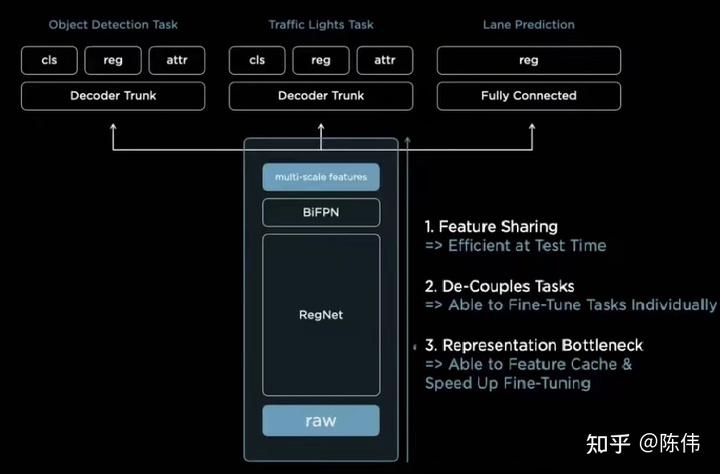
感知模块的多任务算是一个常态:通用检测,信号灯检测,车道线检测,可行驶区域分割,深度估计等等,所以在设计网络模型时都会分出不同的任务头。为了避免共享特征层中的权重在训练时收到多任务竞争而造成的不可控因素,小编猜测在后期的迭代过程中可能需要冻结共享阶段的权重,可训练参数只针对当前任务。
针对单帧图像无法包含物体运动的速度,加速度,轨迹等信息,Tesla指出它们将单帧的输入替换成了视频片段的形式:
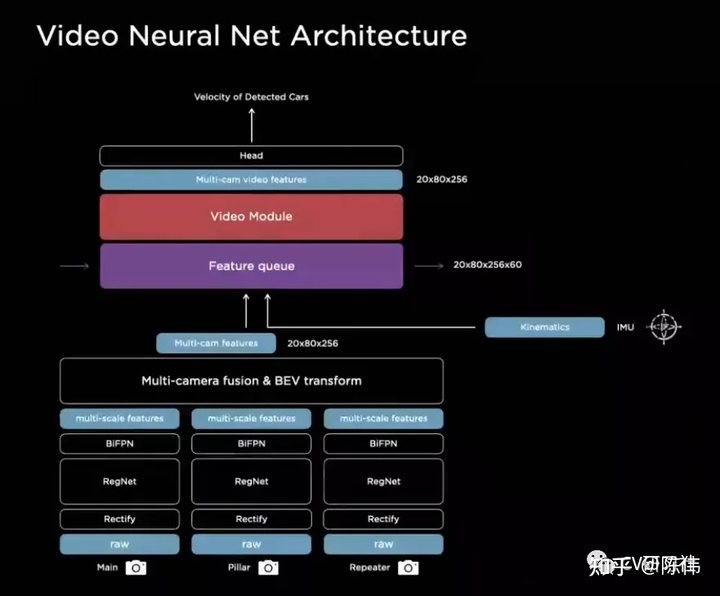
众所周知对连续帧的处理通常采用3D卷积或者循环卷积等方式,另外加上今年很火的Transformer(本质就是注意力+循环卷积)。
但其实有很大一部分研究人员还是用的单帧+跟踪的方式解决上述问题,将时间维度加入神经网络中一来增大了运算开销,二来硬件对这些算子的支持程度不太友好。
数据形式
Andrej这次着重介绍的还有数据的空间形式,虽然业内都知道Tesla的感知是投影到鸟瞰图视角做的,但是对于为什么这么做?以及如何做?这么做有什么好处等方面听了主讲人的介绍还是颇有启发。下图是会议展示的Demo中提到的从左侧多相机视角的图像空间转换到右侧仪表盘上的向量空间:

Tesla为什么坚定的在鸟瞰图空间搞事情,主要还是因为多相机感知结果的融合太困难,当一个大货车出现在3个甚至4个视角中,即使每个视角的相机都检测到目标,但是当根据相机内外参、地面方程等外部约束转换到空间坐标后,很难在多个图像空间同一目标的结果统一到矢量空间中,更糟糕的是距离越近的物体朝向角就越发抖动。
同时Tesla给出的图像空间——>矢量空间的转换方式,也并非简单的像素投影,因为逐像素投影的做法对参数依赖过于强烈,实际场景很难达到精度要求。
Tesla将这一块空间转换的过程集成到了神经网络中,构建栅格并利用上下文、位置编码、键值查表等信息通过Tranformer模块实现:
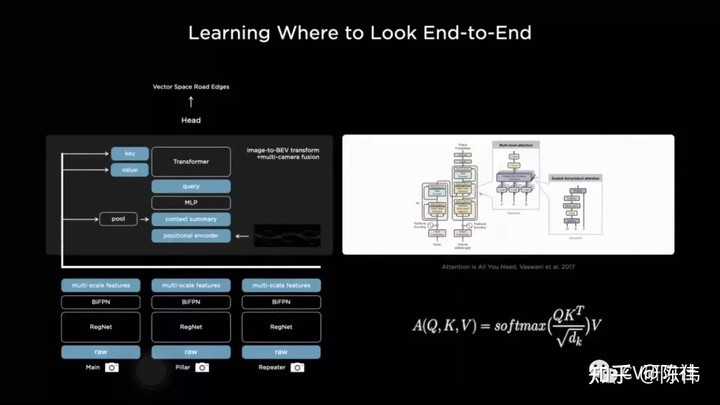
基于官方提供的对比图,确实这种模型操作(右下)得到的矢量空间优于逐点投影出(左下)的效果。

虚拟相机
这里主要是将多个相机得到的图像空间进行投影视角的统一,至于为什么要怎么做?小编猜测和神经网络的学习能力有关,如果每个相机的透视投影程度不同,是否网络在融合不同相机得到的图像过程中就需要多一层矩阵转换,更有甚者可能难以收敛。比如我们在做数据处理时会对不同维度的数据进行参数归一化统一量纲,就是为了避免不同维度数据范围差距较大而引发梯度震荡。
下图给出了由不同相机统一到虚拟相机的三个过程:
- 畸变校正
- 旋转变换
- 畸变还原
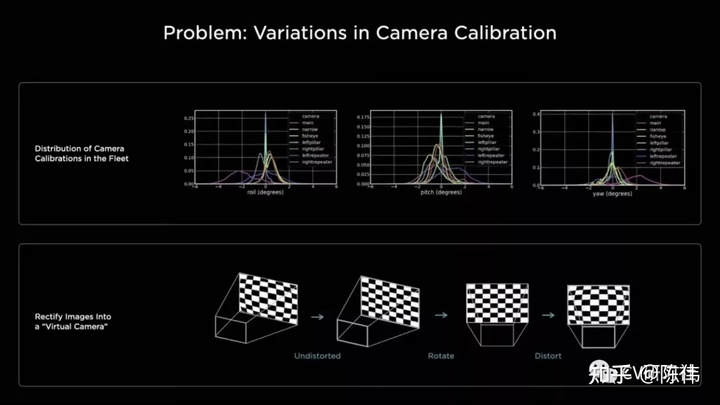
总的来说,当涉及多个相机数据,需要输入到同一个神经网络做黑盒训练时,类似虚拟相机等Tricks还是为了得到更好更一致的数据空间,来提升模型预测的效果。
最终形态
最后献上官方的整体结构图:
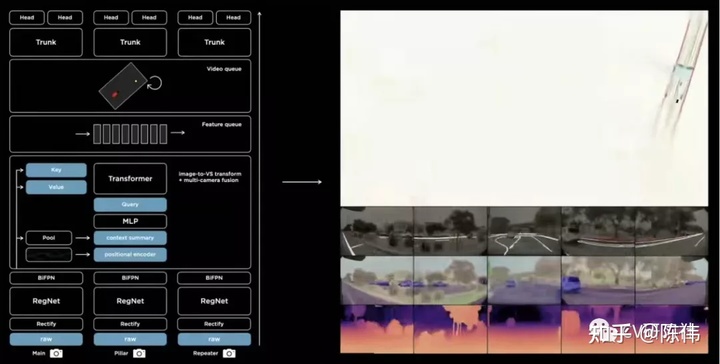
我们从下往上看,先将多个相机的图像数据统一到虚拟相机,然后输入残差模块提取基础特征,再将高层级和低层级特征进行上下文融合,输入Transformer模块转换到矢量空间,将中间层压入队列,用于构建后续的连续视频特征,最后就是输到不同的子任务做各自的训练处理。
欢迎关注小编公众号,每周分享关于计算机视觉或无人驾驶感知方面的内容。
http://weixin.qq.com/r/GR1udl-EvQLCrRsV90gL (二维码自动识别)
最后
以上就是紧张小霸王最近收集整理的关于特斯拉AI日的感知之旅的全部内容,更多相关特斯拉AI日内容请搜索靠谱客的其他文章。








发表评论 取消回复