一、Tesla
八个摄像头
首先是基于单个图像
使用Regnets作为backbone
使用了BiFPNs特征金字塔
使用了yolo作为head
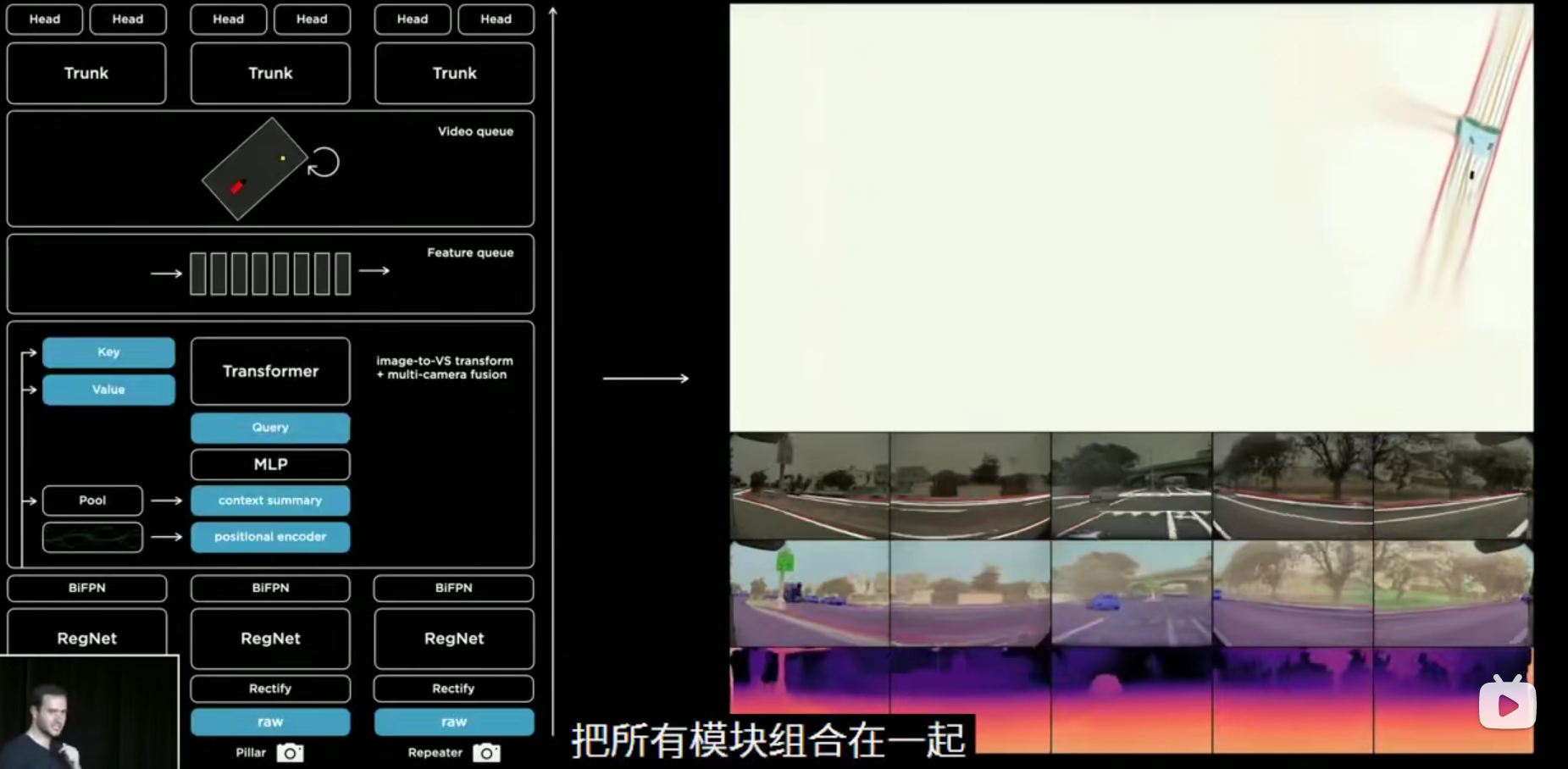
以多任务网络形式布置,但是主干只有一个,在尾部加入多个解码器以完成不同任务
但是当存在多个摄像头的时候
多个摄像头的时候要记住很重要的一点,是在向量空间去训练和标注的。
值得说一句,特斯拉并不是舍弃了Lidar,Lidar被特斯拉用来矫正数据。此外也有一个pseudo lidar部分,日后再说。
你需要在每个摄像头中都完成检测,以及还要把这些结果拼接起来,这两点都很困难
困难的原因主要包括:每个摄像头单独检测只能分别找到一个物体的每个部分;以及单独检测之后无法拼接起来;拼接时受深度影响(图片的每个像素上准确的预测深度比较困难)拼接得不准确;多个相机种类不同,内外参的差别也会很大。
解决方案:一次性获得多个图像,将他们分别送入各自的主干网络后由某种组件将它们融合在一起,之后总入加码器解码出一个准确的融合后的结果。但是存在两个问题:1.如何设计这个组件? 2.向量空间的标签?
对于第一个问题可以使用Transformer来解决这个,将每个相机的图片输入,然后将其看做是一个key-query(self-attention)的查询问题。
这里相机的参数被一个统一的卷积层给代替了,层自己去学习内外和矫正参数。
对于第二个问题,所谓的向量空间指的是特斯拉不在图片层面去输出结果,而是构建类似一个高精地图的“向量空间”(后面我们也会提到,这个向量空间也可以用来做仿真),在这个向量空间来做标注。这也为后续除人工标注外的自动标注和仿真环境标注提供了可行性。
仿真模块
上面也提到了建立向量空间用来标注和训练。很多人看到那个向量空间的第一反应是是否可以用来做高精地图,特斯拉没有选择这个方案,个人觉得可能是因为数据量太大,维护和使用成本过于大,这违背了使用纯视觉方案的初衷。
特斯拉汽车在运行的时候也是会产生向量空间的,这很容易理解,即记录并针对一些新情况重新训练。其次这些向量空间也会被用来构建逼真的仿真环境,当特斯拉遇到一些自动驾驶失败的场景会记录下来并在仿真环境中通过修改场景,衍生出很多的类似环境加入训练,即不仅将出现错误的地方修正还会增强以预防出错。
仿真模块也能创造出那些小概率但并非不可能的环境事件,比如高速公路上奔跑的一家三口和商业街上出现的大象。
视频模块
引入一个视频模块,可以记录一段时间内的空间特征,该模块使用Spatial RNN来解决短暂遮挡对检测造成的影响,大概在被遮挡时使用被记录的特征去做检测(RNN有一定时间内的记忆功能)。
总结
从底层输入图像(多分支)--校正层进行矫正,并将所有图像拼接到一个通用的虚拟相机中(多分支)--RegNet主干网络将他们处理成不同尺度的多个特征(多分支)--将多尺度信息与BiFBN融合-(多分支)--通过一个Transformer模块将其重新表示到向量空间中(通用分支中)--结果输入到一个基于时间或空间的特征队列中--队列由视频模块处理即空间RNN--然后进入多任务解码器解码(多分支)--以用于不同的任务
二、Waymo
参考链接:谷歌Waymo自动驾驶详解
最后
以上就是发嗲钥匙最近收集整理的关于随记(7):自动驾驶解决方案-已更新Tesla,Waymo一、Tesla二、Waymo的全部内容,更多相关随记(7):自动驾驶解决方案-已更新Tesla内容请搜索靠谱客的其他文章。








发表评论 取消回复