什么是联邦学习?
联邦学习(Federated Learning)是一种分布式机器学习技术 ,其核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练,在不需要交换本地个体或样本数据的前提下,仅通过交换模型参数或中间结果的方式,构建基于虚拟融合数据下的全局模型,从而实现数据隐私保护和数据共享计算的平衡,即“数据可用不可见”、“数据不动模型动”的应用新范式 。
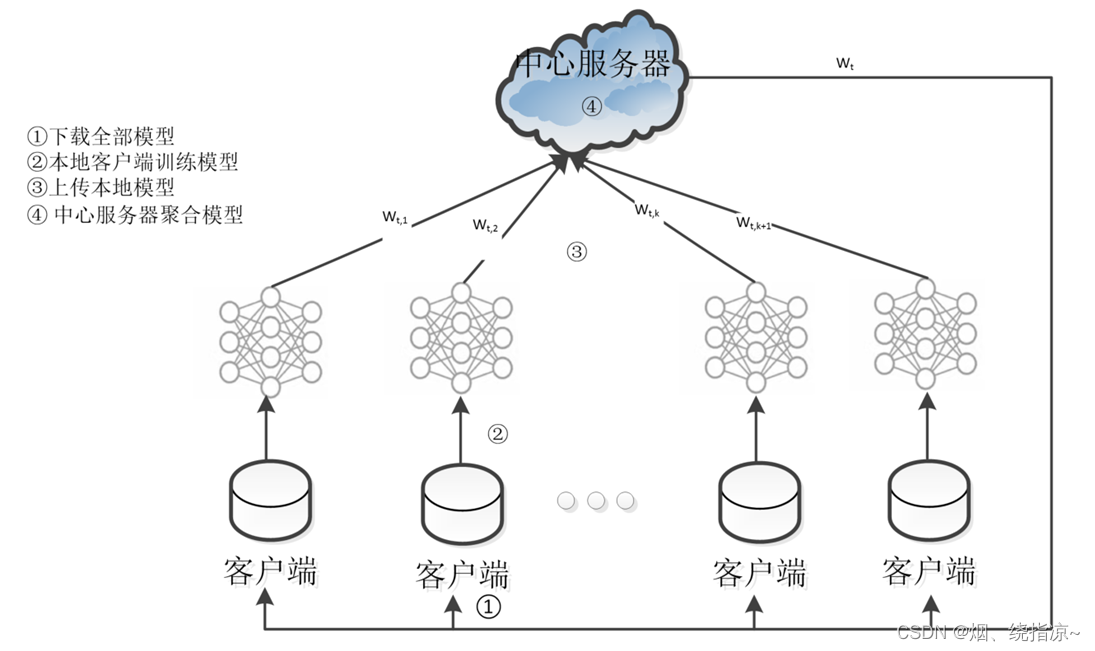
联邦学习的过程?
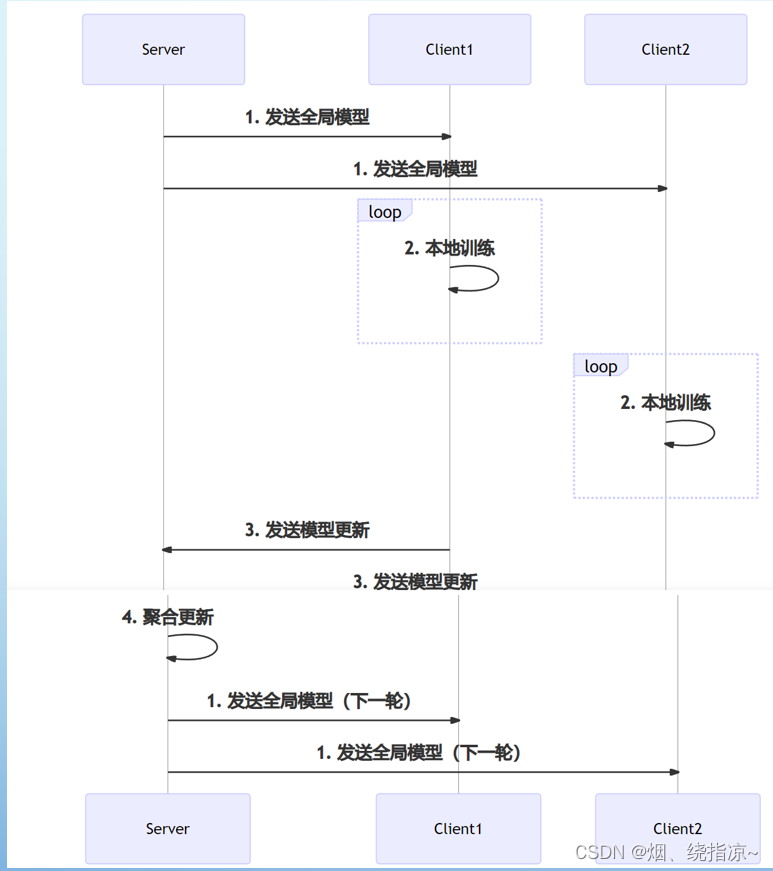
在联邦学习中中央服务器将训练模型下发至客户端,客户端分别使用其私人数据训练其本地深度神经网络 (DNN) 模型。然后将局部模型更新发送到中央服务器,而私有数据保留在客户端上。收集所有局部模型后,中央服务器负责聚合新的全局模型,该模型将交付给客户端以进行下一轮模型训练。重复此分布式训练迭代,直到全局模型收敛到令人满意的精度为止。
参考文献
Adaptive Federated Learning in Resource Constrained Edge Computing Systems
摘要:由于带宽、存储和隐私方面的考虑,将所有数据发送到集中位置通常是不切实际的。在本文中,我们考虑了从分布在多个边缘节点的数据中学习模型参数的问题,而不将原始数据发送到一个集中的地方。我们的重点是使用基于梯度下降的方法训练的一类通用机器学习模型。从理论角度分析了分布式梯度下降的收敛界,在此基础上提出了一种控制算法,该算法确定了在给定资源预算下局部更新和全局参数聚合之间的最佳折衷,使损失函数最小。通过在网络原型系统和更大规模的模拟环境中使用真实数据集进行大量实验,评估了所提算法的性能。实验结果表明,在不同的机器学习模型和不同的数据分布情况下,该方法的性能都接近最佳。
关键字:分布式机器学习,联邦学习,移动边缘计算,无线网络
边缘计算的架构:
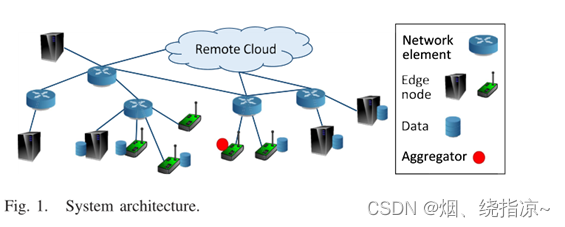
局部更新
每个边缘节点执行梯度下降来调整局部模型参数,以最小化在自己数据集上定义的损失函数。
全局更新
从不同边缘节点获得的模型参数被发送到聚合器。聚合器聚合这些参数(例如,通过取加权平均),并将更新后的参数发送回边缘节点,以便进行下一轮迭代。
全局聚合的频率是可配置的,可以以一个或多个本地更新为间隔进行聚合。
每一次本地更新都会消耗边缘节点的计算资源,每一次全局聚合都会消耗网络的通信资源。
资源消耗量可能随时间变化,且全局聚合频率、模型训练精度和资源消耗之间存在复杂关系。

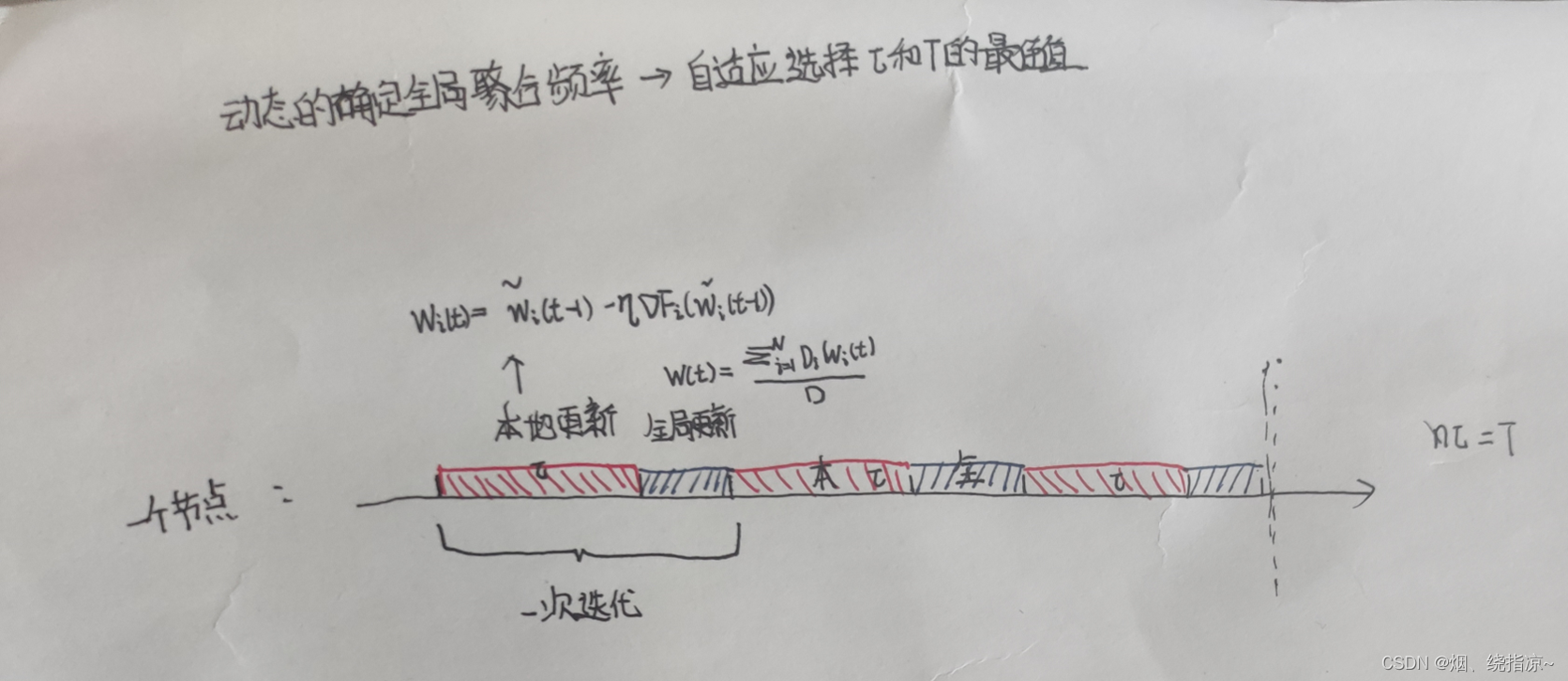
 分布式梯度下降算法
分布式梯度下降算法

聚合器的过程算法(全局聚合)

边缘各个节点的局部更新过程算法

结论
在本文中,我们关注基于梯度下降的联邦学习,包括局部更新和全局聚合步骤。本地更新和全局聚合的每一步都要消耗资源。分析了具有非同一性的联邦学习的收敛界。数据分布。利用这一理论界限,提出了一种控制算法,以实现在资源预算约束下局部更新和全局聚合之间的理想权衡,使损失函数最小。大量的实验结果证实了该算法的有效性。未来的工作可以研究如何最有效地利用异构资源进行分布式学习,以及代表深度神经网络的某种形式的非凸损失函数的理论收敛性分析。
最后
以上就是大胆面包最近收集整理的关于联邦学习在边缘计算中的应用什么是联邦学习?联邦学习的过程?参考文献 结论的全部内容,更多相关联邦学习在边缘计算中内容请搜索靠谱客的其他文章。








发表评论 取消回复