Adversarial Attacks on deep learning阅读笔记
- 简单说说Adversarial attack
- Adversarial Attacks on Deep-Learning Based Radio Signal Classification
- 简单介绍 adversarial attack
- White-box algorithm
- Formation of universal adversarial perturbation (UAP)
- Something about black box
- Intriguing properties of neural network
- Explaining and harnessing adversarial example
本文中会记录多个与adversarial attack相关的阅读以及个人的理解。有偏差的地方还希望各位指正。文中同样会借鉴csdn、知乎等网站上的帖子,特此感谢。同样,这是笔者第一次在论坛平台上发布文章,可能有诸多问题,还希望各位不吝指教。 本文会在发布的同时不断更新完善,希望各位看到的朋友帮助我指出错误。
简单说说Adversarial attack
不得不承认,以往在讨论到关于深度学习的时候,笔者多数考虑的是使用诸多不同的模型实现功能。通过阅读adversarial attack的相关文章,才开始认识到另一个学习deep learning的角度。近年来关于deep learning的应用在分类中表现出不俗的效果。然而即使训练之后表现很好的网络,在对其输入的过程中添加一个很难察觉,很小的扰动(perturbation)都会严重影响网络的分类能力。因此,很多基于深度学习的应用,其安全性和准确性都受到严重的威胁。这种针对于神经网络,导致其工作能力严重下降的样本被称之为对抗性样本(adversarial examples)。为了解决该问题,诸多研究者展开了对于如何生成adversarial example 的研究。
Adversarial Attacks on Deep-Learning Based Radio Signal Classification
本文主要将adversarial attack的论文应用于无线电信号分类的情景中。关于Adversarial Attacks通俗来讲就是,在样本输入网络中进行分类等问题时,一个很小的对抗性扰动(adversarial perturbation)会使得训练好的神经网络出现错误分类。虽然扰动可能很小,但对深度学习网络的影响却是毁灭性的。
简单介绍 adversarial attack
通常,对于扰动大小的描述可以用其p范数来描述,即
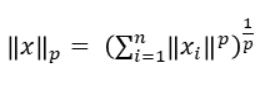
本文中使用l-2 范数来描述扰动的大小,即
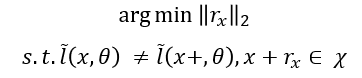
从限制条件中可以看出,我们期望一个足够小的扰动使得输入加上扰动后仍然符合输入集合的特征,但是扰动后的输入最终会被错误分类,以上也是adversarial attack的基本思路。
对于adversarial attack有多种分类方法,对系统模型及输入表现为已知状态的可以被成为white box。其中有目的的将输入错误分类为
y
t
a
r
g
e
t
y^{target}
ytarget的情况可以称之为targeted attack;对于无目的性的,将任意输入错误分类为其他不同于正确分类
y
t
r
u
e
y^{true}
ytrue的情况称之为non-targeted attack。对于两种不同的攻击方式,对于损失函数L的操作正好相反,前者希望将对于目标标签的损失函数最小化,后者希望将对于正确标签的损失函数最大化,即:
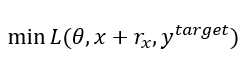
和
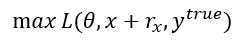
类似于文章Intriguing properties of neural networks中描述的fast gradient sign method (FGSM), 本文使用fast gradient method(FGM). 两种方法获得的扰动可分别表述为:
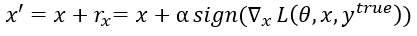
和
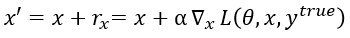
同理,本文对于损失函数的描述(targeted attack)可以表示为:
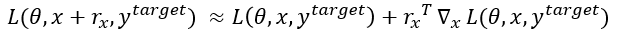
这里简单描述一下对于FGM的理解,其原理可简单解释为:对于输入的改变,当其改变方向是沿着梯度方向时,对于最终函数值的影响是最大的。对于上述理论,知乎上姚远的[梯度的方向为什么是函数值增加最快的方向?][5]有着详细的解释。
White-box algorithm
本文提出的white-box 算法如图所示:

其大致过程可以描述为对于就全部类别的情况进行adversarial perturbation 的寻找, 该算法结合了targeted和non-targeted的特征,循环中不断缩小perturbation norm,最终找出使得分类出错的最小perturbation norm。
对于算法部分仍有不确定的地方,比如最后计算扰动
r
x
r{_x}
rx为什么scaling factor为perturbation的norm除以梯度的2-norm, 然而在Goodflow的文章中factor是一个给定值。
Formation of universal adversarial perturbation (UAP)
上述的算法其输入包含单一的信号,以及对应的标签。其扰动是针对特定的输入而生成的,换句话说,这种算法生成的扰动是与输入同步对应的。然而在现实生活中,为了生成一个adversarial example,攻击者很难了解到输入是什么。因此本文又提出了第二种算法,该算法的输入信息为:
- 任意一组输入信号的子集及对应的标签
- 待攻击的系统 f ( . , θ ) f(.,theta) f(.,θ)
- 最大允许perturbation norm:
p
m
a
x
p_{max}
pmax

这里引进了perturbation direction,一组对于每一个输入的梯度方向矩阵。该矩阵主要是为最大限度更改函数值提供方向依据。然而,现实的计算量,将会对硬件造成极大的负担。为了解决这个问题,本文使用了主成分分析(PCA),经过奇异值分解(SVD),仅保留可以最大限度代表X的主成分,由于我们期望获得对应的方向向量,因此提取V矩阵的第一列(对应X的行方向)。
在 Universal adversarial perturbations 中的UAP获取方法 :

Something about black box
事实上,现实世界中,也存在与对于模型完全了解的情况。这种情况被称之为black box。对于black box的情况,其对抗样本的生成需要借助于前面提到的算法:PCA -based approach for crafting a UAP. 由于adversarial example 的可转移性质(transferability)。根据这条性质,针对某一网络生成的对抗性样本同样可以对其他的网络造成影响。另一条对抗性样本的性质是转移不变性(shift invariant),该条性质可以消除生成扰动对于输入的同步性。
Intriguing properties of neural network
Explaining and harnessing adversarial example
最后
以上就是忧郁鞋子最近收集整理的关于Adversarial Attacks on deep learning阅读笔记简单说说Adversarial attackAdversarial Attacks on Deep-Learning Based Radio Signal ClassificationIntriguing properties of neural networkExplaining and harnessing adversarial example的全部内容,更多相关Adversarial内容请搜索靠谱客的其他文章。








发表评论 取消回复