ADMM算法学习
- ADMM定义和背景
- ADMM方法
- 问题模型
- 增广拉格朗日函数
- 算法流程
- 算法测试
- 算法扩展
- 参考资料
ADMM定义和背景
交替向乘子法(Alternating Direction Method of Multipliers, ADMM)是一种求解具有可分离的凸优化问题的重要方法,由于处理速度快,收敛性能好,ADMM算法在统计学习、机器学习等领域有着广泛应用。
交替方向乘子法(ADMM)是一种求解优化问题的计算框架, 适用于求解分布式凸优化问题,特别是统计学习问题。 ADMM 通过分解协调(Decomposition-Coordination)过程,将大的全局问题分解为多个较小、较容易求解的局部子问题,并通过协调子问题的解而得到大的全局问题的解。ADMM 最早分别由 Glowinski & Marrocco 及 Gabay & Mercier 于 1975 年和 1976 年提出,并被 Boyd 等人于 2011 年重新综述并证明其适用于大规模分布式优化问题。由于 ADMM 的提出早于大规模分布式计算系统和大规模优化问题的出现,所以在 2011 年以前,这种方法并不广为人知。【7】
ADMM 是ALM算法的一种延伸,只不过将无约束优化的部分用块坐标下降法(block coordinate descent,或叫做 alternating minimization)来分别优化。产生这种方法主要是为了弥补二次惩罚的缺点。在一些问题当中,用二次惩罚来近似约束问题在最优点附近需要惩罚项的系数趋近于无穷,而这种要求会使得海森矩阵很大,因此近似的目标函数很不稳定。为了解决这个问题,引入了线性逼近的部分,通过线性项系数不断的接近最优解(对偶上升),使得在二次惩罚项的系数很小的情况下,也能得到满足要求精度的解。ADMM目前是比较成熟,比较受欢迎的约束问题最优化通用框架。【8】
归根结底,就是解决 loss function + regulation. 当regulation为L1范数的时候没有合适的算法解决这个凸优化问题。原来boyd的老师提出过 最小角方法 方法解决这个问题,但是因为方法不直观并且难以操作。所以,这些大牛们一直在寻找一种比较合适的算法解决这个问题。直至2011年左右提出比较通用和直观的ADMM算法。对于ADMM算法,其实是一种交替求解的方式。不断的将问题分解,进而逐个解决。其中在解决的过程中,发现将恼人的L1 Norm中的变量进行替换,从而形成 L1+L2 norm的形式比较容易求解(proximal algorithm),所以挺好的。而如果我们直接进行Loss function + regulation,求解的话,很难得到解。所以从上面我们可以发现,变量替换成为解决问题的关键。而逐次求解,使问题得到解决。其实只要将最简单的L1 norm的形式理解。对于各种proximal直接查询相关解就可以了。【9】
ADMM方法
问题模型
交替方向乘子法(ADMM)通常用于解决存在两个优化变量的等式约束优化类问题,其一般形式为:
min
x
,
z
f
(
x
)
+
g
(
z
)
s
.
t
.
A
x
+
B
z
=
c
min_{x,z} f(x)+g(z) ~~~~ \ mathrm { s.t.} ~~Ax + Bz = c
x,zminf(x)+g(z) s.t. Ax+Bz=c
其中
x
∈
R
n
,
z
∈
R
m
x in mathbb{R} ^n , z in mathbb{R} ^m
x∈Rn,z∈Rm 为优化变量,等式约束中
A
∈
R
p
×
n
,
B
∈
R
p
×
m
,
c
∈
R
p
A in mathbb{R} ^{ptimes n}, B in mathbb{R} ^{ptimes m}, c in mathbb{R} ^{p}
A∈Rp×n,B∈Rp×m,c∈Rp, 目标函数中
f
,
g
f, ~g
f, g 都是凸函数.
- 标准的ADMM算法解决的是一个等式约束的问题,且该问题两个函数 f f f 和 g g g 是成线性加法的关系。这意味着两者实际上是整体优化的两个部分,两者的资源占用符合一定等式,对整体优化贡献不同,但是是简单加在一起的。
- 事实上分布式中的一致性优化问题(consensus),分享问题(sharing problem)等等都很好写成这样的形式,因为每个节点的变量还要跟周围节点变量产生关联、
增广拉格朗日函数
ADMM算法的核心是原始对偶算法的增广拉格朗日法(ALM)。拉格朗日函数是解决了多个约束条件下的优化问题,这种方法可以求解一个有n个变量与k个约束条件的优化问题。原始对偶方法中的增广拉格朗日法(Augmented Lagrangian)是加了惩罚项的拉格朗日法,目的是使得算法收敛的速度更快。
L
ρ
(
x
,
z
,
u
)
=
f
(
x
)
+
g
(
z
)
+
u
T
(
A
x
+
B
z
−
c
)
+
ρ
2
∥
A
x
+
B
z
−
c
∥
2
2
L_{rho}(x,z,u) = f(x)+g(z)+u^T(Ax+Bz-c)+frac{rho}{2}| Ax+Bz-c|^2_2
Lρ(x,z,u)=f(x)+g(z)+uT(Ax+Bz−c)+2ρ∥Ax+Bz−c∥22
增广拉格朗日函数就是在关于原问题的拉格朗日函数【4】之后增加了一个和约束条件有关的惩罚项,惩罚项参数 ρ > 0 rho > 0 ρ>0 .惩罚项参数影响迭代效率。
增广拉格朗日函数对min是+对偶项和惩罚项,对max是 - 对偶项和惩罚项。
- 原问题 min x , z f ( x ) + g ( z ) min_{x,z} f(x)+g(z) minx,zf(x)+g(z),对偶问题 max u min x , z L ρ ( x , z , u ) max_{u}min_{x,z} L_{rho}(x,z,u) maxuminx,zLρ(x,z,u),两个问题的最优解等价,并且没有了约束条件。
算法流程
每一步只更新一个变量而固定另外两个变量,如此交替重复更新。
- Step 1: x ( i ) = a r g m i n x L ρ ( x , z ( i − 1 ) , u ( i − 1 ) ) x^{(i)} = mathrm {argmin}_x ~L_{rho}(x,z^{(i-1)},u^{(i-1)}) x(i)=argminx Lρ(x,z(i−1),u(i−1))
- Step 2: z ( i ) = a r g m i n z L ρ ( x ( i ) , z , u ( i − 1 ) ) z^{(i)} = mathrm {argmin}_z ~L_{rho}(x^{(i)},z,u^{(i-1)}) z(i)=argminz Lρ(x(i),z,u(i−1))
- Step 3: u ( i ) = u ( i − 1 ) + ρ ( A x ( i ) + B z ( i ) − c ) u^{(i)} = u^{(i-1)} + rho (Ax^{(i)}+Bz^{(i)}-c) u(i)=u(i−1)+ρ(Ax(i)+Bz(i)−c) %Ascend
不断重复以上三步直到收敛。
- 使用和增广拉格朗日类似的对偶上升方法,固定其中两个变量,去更新第三个变量的值。
- ADMM 算法提供了一个将多优化变量问题转化为单优化变量问题的转化方式(即,交替方向),并未涉及具体的下降方法,其中关于 x x x 和 z z z 的更新过程需要结合具体的下降类算法,如梯度下降算法等。
- ADMM的另一种形式:

算法测试
求解例子
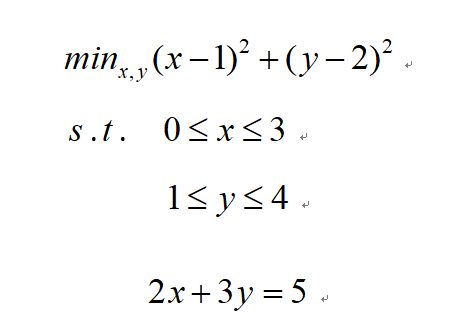
构造出该目标函数的增广拉格朗日表达式
L
(
x
,
y
,
λ
)
=
f
(
x
)
+
g
(
y
)
+
λ
T
(
2
x
+
3
y
−
5
)
+
ρ
2
∥
2
x
+
3
y
−
5
∥
2
2
L(x,y,lambda) = f(x)+g(y)+lambda^T(2x+3y-5)+frac{rho}{2}|2x+3y-5|^2_2
L(x,y,λ)=f(x)+g(y)+λT(2x+3y−5)+2ρ∥2x+3y−5∥22
使用 Matlab 编码【5】求解如下:
- 主函数
%% 定义参数
% x0,y0都是可行解
param.x0
= 1;
param.y0
= 1;
param.lambda
= 1;
param.maxIter = 30;
param.beta
= 1.1;
% a constant
param.rho
= 0.5;
[Hx,Fx] = getHession_F('f1');
[Hy,Fy] = getHession_F('f2');
param.Hx = Hx;
param.Fx = Fx;
param.Hy = Hy;
param.Fy = Fy;
%% solve problem using admm algrithm
[x,y] = solve_admm(param);
%% disp minimum
disp(['[x,y]:' num2str(x) ',' num2str(y)]);
- ADMM求解函数:solve_admm
function [x,y] = solve_admm(param)
x
= param.x0;
y
= param.y0;
lambda
= param.lambda;
beta
= param.beta;
rho
= param.rho;
Hx
= param.Hx;
Fx
= param.Fx;
Hy
= param.Hy;
Fy
= param.Fy;
%%
xlb
= 0;
% the lower bound of x
xub
= 3;
% the upper bound of x
ylb
= 1;
yub
= 4;
maxIter = param.maxIter;
i
= 1;
funval
= zeros(maxIter-1,1);
iterNum = zeros(maxIter-1,1);
while 1
if i == maxIter
break;
end
% solve x
Hxx = eval(Hx);
Fxx = eval(Fx);
x
= quadprog(Hxx,Fxx,[],[],[],[],xlb,xub,[]);
% Quadratic programming function
% solve y
Hyy = eval(Hy);
Fyy = eval(Fy);
y
= quadprog(Hyy,Fyy,[],[],[],[],ylb,yub,[]);
% update lambda
lambda = lambda + rho*(2*x + 3*y -5); % ascend
funval(i)
= compute_fval(x,y);
iterNum(i) = i;
i = i + 1;
end
plot(iterNum,funval,'-r');
end
- 求解函数的 Hessian 矩阵和导数的函数:getHession_F
function [H,F] = getHession_F(fn)
% fn : function name
% H
: hessian matrix
% F
: 一次项数系数
syms x y lambda rho;
if strcmp(fn,'f1')
% 判断输入函数是 f1 的话
f = (x-1)^2 + lambda*(2*x + 3*y -5) + rho/2*(2*x + 3*y -5)^2;
H = hessian(f,x);
% 计算函数的 Hessian 矩阵
F = (2*lambda + (rho*(12*y - 20))/2 - 2);
% x 的系数
fcol = collect(f,{'x'}); % 固定y,默认x为符号变量
disp(fcol);
elseif strcmp(fn,'f2')
% 判断输入函数是 f2 的话
f = (y-2)^2 + lambda*(2*x + 3*y -5) + rho/2*(2*x + 3*y -5)^2;
H = hessian(f,y);
F = (3*lambda + (rho*(12*x - 30))/2 - 4); % y 的系数
fcol = collect(f,{'y'}); % 固定x,默认y为符号变量
disp(fcol);
end
end
- 计算 ( x , y ) (x,y) (x,y) 对应的目标函数值函数:compute_fval
function
fval
= compute_fval(x,y)
fval = (x-1)^2 + (y-2)^2;
end
算法扩展
这里写一些关于ADMM算法扩展应用的个人理解:
在通信优化问题中,联合优化问题存在多个优化变量(比如,
{
x
,
y
,
z
}
{x, y, z}
{x,y,z}),等式或不等式约束中的多变量耦合导致问题直接求解的复杂度过大(尤其是当变量的维度过大时),但是由于占用了共同的资源约束又不可以直接进行变量分解,这时候为了利用ADMM并行求解的思想来处理较大规模的问题,就需要某种办法来引入等式约束将问题变成可以分解的形式。
ADMM方法就是通过 decomposition-coordination 的过程,通过连续协调规模小的局部的子问题的解来找到一个大规模的全局问题的解。
- 观察变量耦合的等式或不等式约束,看是引入“辅助变量”还是“复制变量”合适;
- 辅助变量可以替代原来的变量或约束,比如UAV集群轨迹优化中的防碰撞约束 ∥ q i [ t ] − q j [ t ] ∥ 2 ≥ d min |q_i[t]-q_j[t]|_2 geq d_{min} ∥qi[t]−qj[t]∥2≥dmin,可以通过引入辅助变量 z i , j [ t ] = q i [ t ] − q j [ t ] z_{i,j}[t]=q_i[t]-q_j[t] zi,j[t]=qi[t]−qj[t] 来替代防碰撞约束中的 q i [ t ] q_i[t] qi[t] 和 q j [ t ] q_j[t] qj[t] 以差值方式耦合的情况,原问题中增加了辅助变量 z i , j z_{i,j} zi,j, 防碰撞约束可以被等式约束 A q = Z Aq=Z Aq=Z 替代,通过该方法可以将优化问题根据不同的UAVs进行分解,即 q i [ t ] q_i[t] qi[t] 和 q j [ t ] q_j[t] qj[t]以并行方式求解。再比如某个UAV轨迹在相邻时隙之间的最大距离约束 ∥ q [ t ] − q [ t − 1 ] ∥ 2 ≤ v max δ |q[t]-q[t-1]|_2 leq v_{max}delta ∥q[t]−q[t−1]∥2≤vmaxδ,也可以引入辅助变量 z [ t ] = q [ t ] − q [ t − 1 ] z[t]=q[t]-q[t-1] z[t]=q[t]−q[t−1] 来将优化问题在不同的slot的上进行分解, q [ t ] q[t] q[t] 和 q [ t − 1 ] q[t-1] q[t−1]以并行方式求解。
- 复制变量就是增加原全局优化变量的一个局部替代变量,通过引入变量的复制变量来保证相同的变量最多出现在一个不等式约束中。比如,全局变量 x x x 和 y y y 的线性组合让问题不可分解,通过引入全局变量 x x x 的局部 copying variables x ˉ bar x xˉ 来替代原优化问题中的原变量 x x x 在目标函数和约束的位置,注意此时也引入了等式约束 x = x ˉ x=bar x x=xˉ。这样变量 x x x 和 y y y 就可以以并行的方式求解了,同前面标准ADMM的 x 和 z 中的更新类似。
- 注意,一般而言原变量(global variables)和引入变量(local variables: 辅助变量、复制变量)的更新虽然都是基于 min/max (增广拉格朗日函数)实现,但二者的更新都是基于对方本次迭代中的值已知的前提下的,所以这样可以进行问题分解;local variables, global variables 和 lagrange multiples 是交替进行更新的。
参考资料
【1】http://www.stat.cmu.edu/~ryantibs/convexopt/lectures/admm.pdf (CMU凸优化课件-admm)
【2】https://www.cnblogs.com/wildkid1024/p/11041756.html
【3】Boyd S, Parikh N, Chu E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers[J]. Foundations and Trends® in Machine learning, 2011, 3(1): 1-122.
【4】https://zhuanlan.zhihu.com/p/103961917 (拉格朗日对偶(Lagrange duality)、KKT条件)
【5】https://zhuanlan.zhihu.com/p/286235184 (matlab实例代码)
【6】直接在matlab中搜索 doc quadprog,会显示该二次规划函数的使用方法.
【7】https://www.zhihu.com/question/36566112/answer/82474155
【8】https://www.zhihu.com/question/36566112/answer/79535746
【9】https://www.zhihu.com/question/36566112/answer/213686443
【10】ADMM的一些参考文献
最后
以上就是爱听歌银耳汤最近收集整理的关于ADMM算法学习ADMM定义和背景ADMM方法算法测试算法扩展参考资料的全部内容,更多相关ADMM算法学习ADMM定义和背景ADMM方法算法测试算法扩展参考资料内容请搜索靠谱客的其他文章。








发表评论 取消回复