我是靠谱客的博主 爱听歌银耳汤,这篇文章主要介绍Pandas(五):数据统计函数+数据排序准备工作一、汇总类统计二、唯一去重和按值计数三、相关系数和协方差四、数据排序,现在分享给大家,希望可以做个参考。
文章目录
- 准备工作
- 一、汇总类统计
- 二、唯一去重和按值计数
- 三、相关系数和协方差
- 四、数据排序
- 1.series的排序
- 2.DataFrame的排序:
准备工作
# 读取天气
import pandas as pd
df = pd.read_csv("beijing_tianqi_2018.csv")
# 读取前三行
df.head(3)
# 更改温度后缀,替换为数字型
# 替换掉温度的后缀℃
df.loc[:, "bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')
df.loc[:, "yWendu"] = df["yWendu"].str.replace("℃", "").astype('int32')
df.head(3)
一、汇总类统计
# 一下子提取所有数字列统计结果
df.describe()
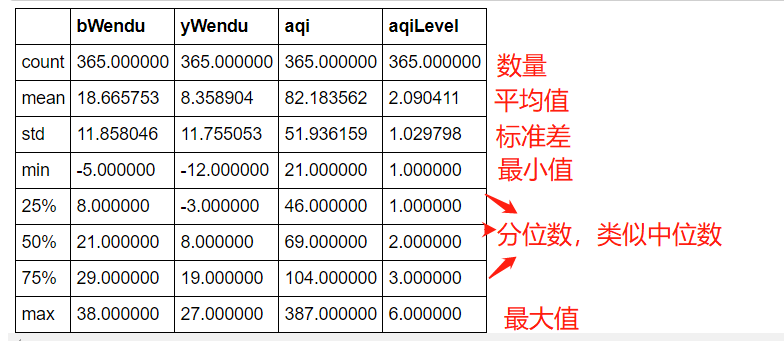
根据这些属性,我们也可以单独的获取某个series的数据值
df["bWendu"].mean()
df["bWendu"].max()
df["bWendu"].min()
df["bWendu"].std()
二、唯一去重和按值计数
| 函数名 | 作用 |
|---|---|
| df[“xx”].unique() | 以 数组形式(numpy.ndarray)返回列的所有唯一值,即查询出xx列 的唯一值 |
| df[“xx”].nunique() | 查询出xx列的唯一值的数量 |
| df[“xx”].value_counts() | 查询出xx列每个值出现的个数 |
举例
df["fengxiang"].unique()
# array(['东北风', '北风', '西北风', '西南风', '南风', '东南风', '东风', '西风'], dtype=object)
df["fengxiang"].nunique()
# 8
df["fengxiang"].value_counts()

三、相关系数和协方差
- 两只股票,是不是同涨同跌?程度多大?正相关还是负相关?
- 产品销量的波动,跟哪些因素正相关、负相关,程度有多大?
来自知乎,对于两个变量X、Y:
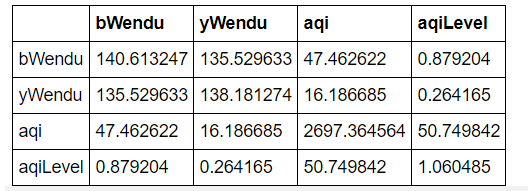
协方差:衡量同向反向程度,如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高。
相关系数:衡量相似度程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大
1. 协方差矩阵:
df.cov()
2. 相关系数矩阵
df.corr()
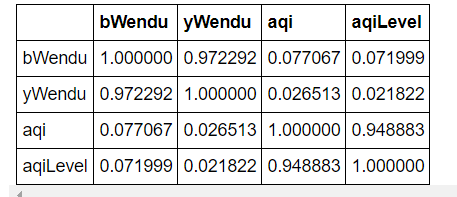
3.单独查看series的相关系数
单独查看空气质量和最高温度的相关系数
df["aqi"].corr(df["bWendu"]) #0.07706705916811077
# 空气质量和温差的相关系数
df["aqi"].corr(df["bWendu"]-df["yWendu"]) #0.21652257576382047
四、数据排序
1.series的排序
Series.sort_values(ascending=True, inplace=False)
参数说明:
- ascending:默认为True升序排序,为False降序排序
- inplace:是否修改原始Series,True修改原始数据
注意: 中文也可以排序
举例:
df["aqi"].sort_values(ascending=False)

2.DataFrame的排序:
DataFrame.sort_values(by, ascending=True, inplace=False)
参数说明:
- by:字符串或者List<字符串>,单列排序或者多列排序
- ascending:bool或者List
- inplace:是否修改原始DataFrame
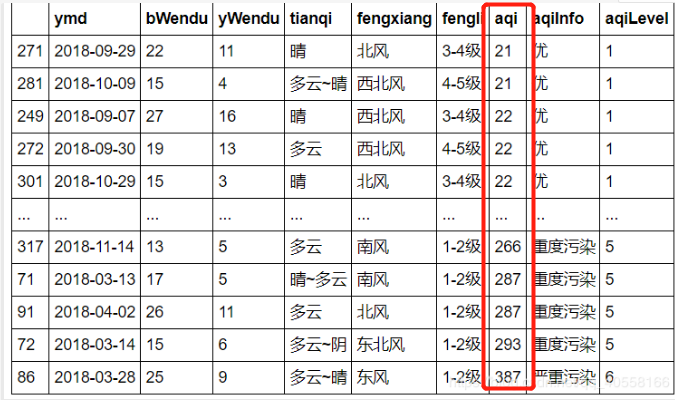
①单列排序
df.sort_values(by="aqi")
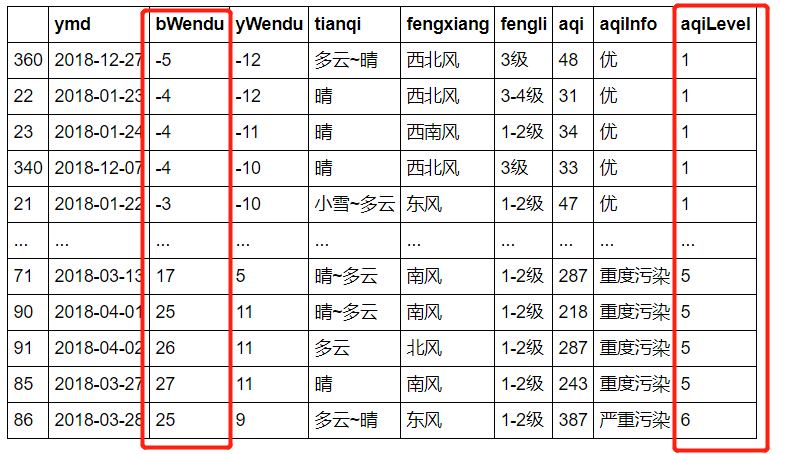
②多列排序
# 按空气质量等级、最高温度排序,默认升序
df.sort_values(by=["aqiLevel", "bWendu"])
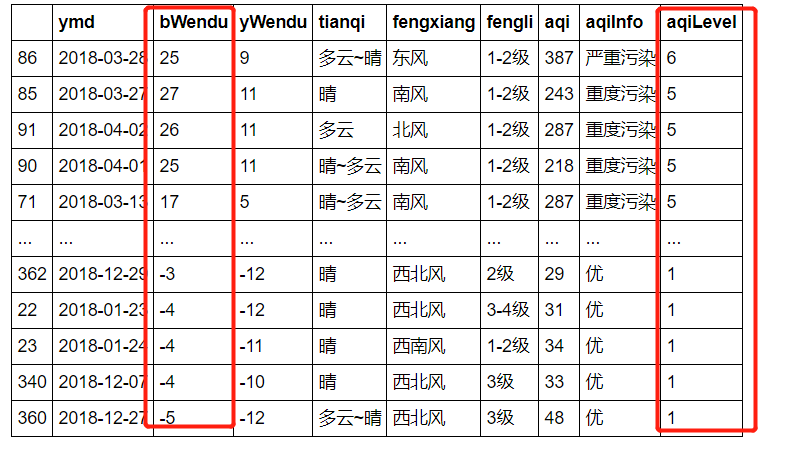
# 两个字段都是降序
df.sort_values(by=["aqiLevel", "bWendu"], ascending=False)
# 分别指定升序和降序
df.sort_values(by=["aqiLevel", "bWendu"], ascending=[True, False])
最后
以上就是爱听歌银耳汤最近收集整理的关于Pandas(五):数据统计函数+数据排序准备工作一、汇总类统计二、唯一去重和按值计数三、相关系数和协方差四、数据排序的全部内容,更多相关Pandas(五)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复