前言:深度Q网络,又叫DQN
传统的强化学习中存储状态价值或者Q函数都是使用的表格(比如之前的Q表格),学名叫查找表(lookup table)。这个有什么问题吗?一个大问题就是只有离散情况(可穷尽)能够被存在于表格中。对于==连续的状态空间怎么办呢?==最气人的就是,现实中还总是连续的状态空间。这个时候就不能够用表格对价值函数进行存储。这时候需要价值函数近似来解决这个问题。
价值函数近似(value function approximation):为了在连续的状态和动作空间中计算Q函数,使用另一个函数来金希表示,成为价值函数近似。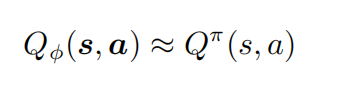
这个价值函数近似有多种形式,其中一种我们比较关注的就是用神经网络来表示。它的输出会是一个实数,称这个神经网络为Q网络(Q-network)。深度Q网络指的就是这个神经网络用到了深度学习的相关内容,是基于深度学习的Q学习算法。
DQN本身是基于价值的方法,在这儿回顾一下两种价值函数:状态价值函数和动作价值函数。
对于状态价值函数来讲,它是直接对策略进行更新。它本身就像一个评论家一样(后面会再次出现这样的说法),对同一个状态经过不同策略后的价值进行判断,选择价值高的对应的策略进行更新。具体实现的时候两种形式:MC和TD
从MC+网络介绍state-value function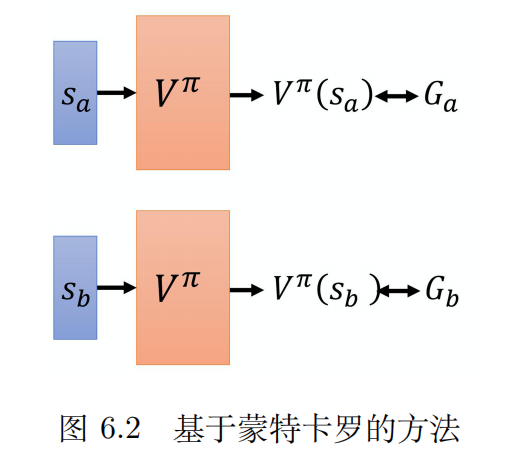
如果使用网络化的角度看待,把这个策略计算价值函数认定为一个网络,输入是状态,输出是状态的价值。对于MC来说,可以获取真实轨迹值,设为G(a)。而网络会有一个输出,二者指向的东西相同,但因为网络的原因有一定差值。那么只要改进网络让输出向G靠齐就可以了,这个问题逐渐变成了一个采样回归训练参数的问题了。
不过回想一下,为什么这个可以抽象为一个回归问题?原因在于MC的特殊性,有了一个真实G,这就相当于一个标签,可以反向让网络进行训练,类似于监督学习。
从TD+网络介绍state-value function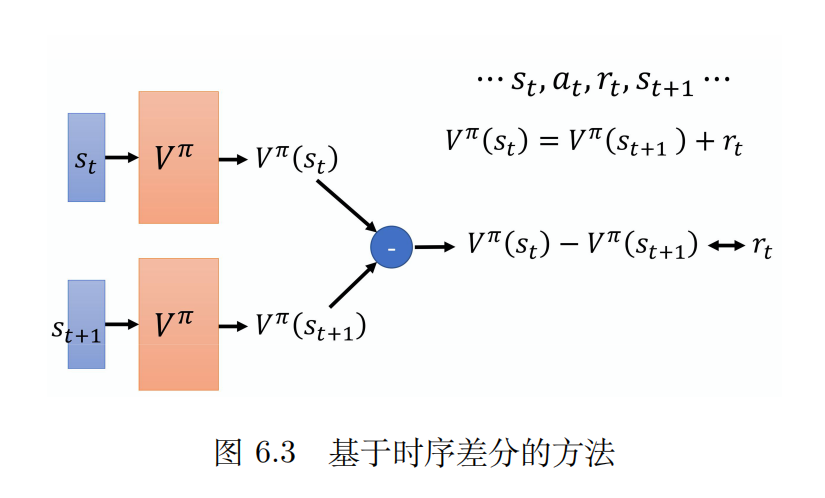
从之前对于TD的了解中知道,TD只发生在两个连续状态之间,它的迭代关系满足下面的等式:
现在已经把V当成一个网络去看待了,那怎么去训练这个网络呢?采用的是这样的方法:根据上面那个式子做一下变形,让两个V做差,理论上应该等于单步的奖励。状态s(t)和s(t+1)已知,带入网络中会得到两个V值,做减法会得到一个数,这个数会逼近r。并且可以通过训练达到这个目的,这就类似于监督学习的网络训练了。
那一个问题就是:TD和MC有什么区别吗?
& emsp;其实MC最大的一个问题就是方差比较大,因为游戏本身也有随机性,同样是s(a)最后的G(a)还可能不同,或者换种思路解释就是G因为是总回报,因为随机性后面的轨迹不一定相同,自然回报也就差距比较大。相比下TD单步,差距就会小很多。但TD也有自己的缺点,TD的V是通过网络计算的,这本身就是估计值,网络不好的时候估计值的误差也会比较大。
有个例子,在李宏毅老师的课程上就讲了。当时第一遍没听懂,现在复盘后才明白。这个例子说明了对于同一个问题,MC和TD估计出的结果可能不一样。
有8个回合,有状态变化和奖励给出。
对于s(b)来说,8个回合都有,其中有6个回合有奖励,所以它的奖励期望就是6/8=3/4。
& emsp;现在的问题是s(a)的期望是多少呢?
先用MC来算,最后均值统计,就是0/8=0
再用TD来算,S(a)和S(b)之间有状态切换,用TD算时会有下面这个等式成立:
有两个数据已知V(s(b))之前算的3/4,状态切换时奖励为0,所以S(a)的期望应该是3/4。最终的结果就不一样了。当然从各自的角度出发,计算都是正确的。只是两种方法对于状态的看待标准不同,MC看到S(a)变成S(b)的那条轨迹时,看到r为0。这条轨迹会认为S(b)的期望也为0。其实后面还有很多组轨迹。所以不同的方法做了不同的假设,运算结果也会不同。
动作价值函数也是一样的啦。因为后面还会介绍到DQN,那里也涉及Q函数,再此就不再赘述了。
在DQN中有三个技巧会被用到,下面来简单介绍一下目标网络、探索、经验回放
1)目标网络
看到这个名词,应该有两个问题:
(1)啥是目标网络?
(2)目标网络可以干啥?
Q函数,了解到有下面这个等式成立: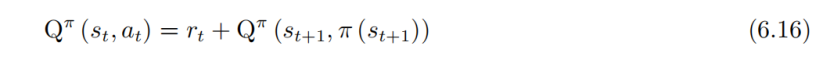
这个看上去和价值状态的TD+网络的单步更新很像,这里只是换成了Q函数。不过换汤不换药,训练的目的还是让差值尽可能接近r。等式左边是输出,右边是目标。要清晰的意识到只有一个模型,只不过是两组输入。对于一个模型来说,左右都发生变动(Q值重新计算),特别是模型目标在变,这样的模型不好训练。
一种思路是把其中一个网络固定住(通常是右边的),训练时只更新左边Q网络的参数。因为保持右边的目标不动,所以被称为目标网络。右边的目标网络不动,只调整左边的参数,就变成了一个回归问题。
不过通常实现的时候还是会偶尔更新下右边的网络,这样精度会高。不过右边的网络更新频率远远小于左边,而且两边不可以同时进行更新。并且每次目标网络变了之后都需要进行整体的重新训练。整体计算流程图如下: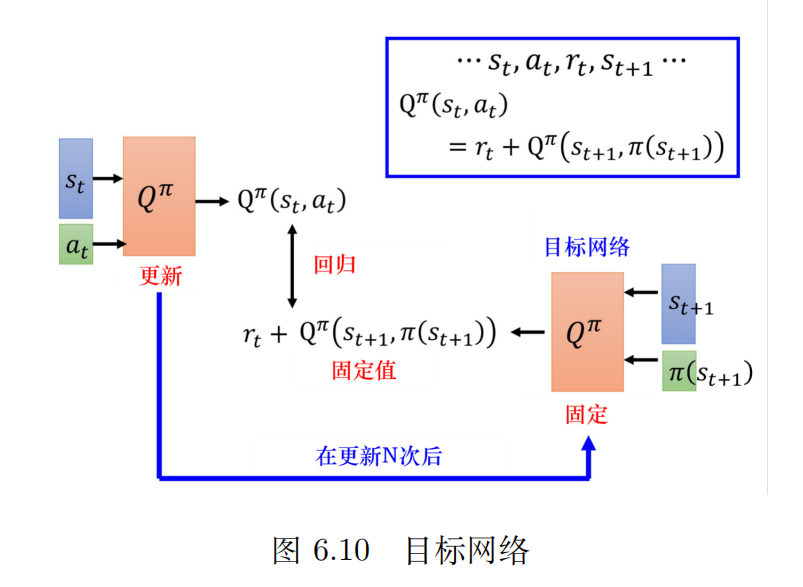
2)探索
其实之前已经介绍过探索了。使用Q函数时,执行的动作完全取决于Q函数。那么如果Q函数不够好的话,就会比较被动。这个时候更激进一点儿选择一些新策略反而可能效果更好。如果没有好的探索的话,智能体就会按照之前的Q函数选择动作。举个贪吃蛇的例子,如果蛇向上运动时得分。没有探索的情况下,贪吃蛇就会认定向上走就会得分。那么最后的效果就是不停向上去,最后撞壁。所以需要有探索的机制,虽然之前的策略,动作a好像不错,但也尝试一下新策略。要在探索和利用之间找到平衡,也就是探索-利用窘境(exploration-exploration dilemma)
探索的常见方法有两个:
(1)ε-贪心
(2)玻尔兹曼探索(Boltzmann exploration)
ε-贪心之前已经介绍过了,这里主要介绍一下后者。其实这个思路就是尝试一些Q值比较差的动作。策略梯度中,网络的输出是一个概率分布,然后根据概率分布去做采样。也可以从Q值去定义一个概率分布,可能Q值有正有负,不过可以概率化再归一化。概率的计算是下面这个等式: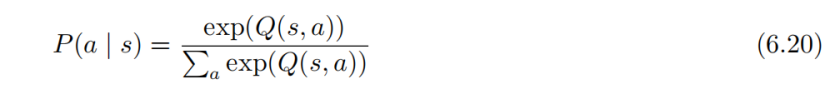
再详细一点儿的东西,我也不了解了。如果后续有需要的话会再来补充的哈
3)经验回放
当智能体去和环境按照某种策略做交互时会产生数据,把这种数据保存下来是有价值的。经验回放就是构建一个回放缓冲区(又叫回放内存)。它最重要的一点是会保存不同策略的数据。而且只有在装满的时候会扔掉一些旧数据。 一般情况下回放缓冲区内存储的会有多种策略的数据。
那现在有一个问题是:有了数据缓冲区后,如何训练Q的模型/怎么估计Q函数呢?
& emsp;其实整个流程和神经网络的训练很像了,从缓冲区里取数据,可能是一个batch。利用经验来更新Q函数: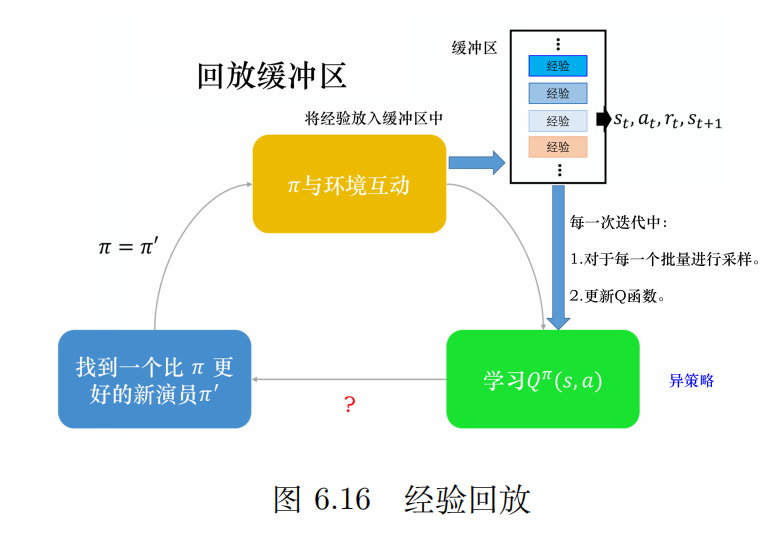
而且当这么做的时候,就变成了一个异策略的做法。因为本来是想找Π的,但是数据中还有其他策略的。利用其他策略更新当前策略符合异策略的思想。
把数据保存有什么优点呢?
其实RL的DQN中,最花时间的步骤是和环境做互动。训练网络反而很快。利用存储区就可以减少和环境互动的次数,加快训练次数。
还可能有的人会有问题:要观察策略A的值,其中混杂了策略B的值会不会有问题?
& emsp;其实没关系的,存储区存储的只是经验(一小段),而不是轨迹。不会产生影响(解释的可能不透彻,但目前还没找到好的说法~)
说了这么多,终于可以介绍我们的主角——DQN
其实把前面所有的东西串起来就组成了DQN,初始化两个网络Q(其中一个是目标网络),智能体和环境做互动。由Q函数决定每次的动作,但不绝对,还要包含探索机制(以上介绍的两种探索方法)。每收到一笔数据都放到数据缓存中,根据数据去算目标(目标网络来算):
让y和Q尽可能接近,就是回归问题。偶尔用Q更新下目标网络Q bar。整体的算法流程图如下:
讲了DQN,讲了Q学习,有什么不同呢?
完结,撒花~ 哦原来还有课后题:

因为第八章的内容不多,而且直接相关。所以就统一写在后面了,第八章的题目是:针对连续动作的深度Q网络。
上面讨论的主要是针对连续状态空间,但一旦状态确定,生成的动作还是离散的。那为什么连续动作难以求解呢? 回想下之前的动作是如何确定的:
在DQN中,当估计出一个Q函数后,要寻找到一个a让Q(s,a)最大,对于a的处理是按照下面这个等式完成的:
对于这个式子,如果a是离散的,那么就可以穷举。哪怕多,只是花时间就可以解决。但如果a是连续的,那就代表有无穷多动作。所以,在连续动作情况下不能使用这个等式来求解a。
那如何用DQN解决连续动作呢? 书中提出了四个方案:
方案一:采样
虽然a有无穷多个,但可以采样部分数据。然后以这组数据来代替整体的a
方案二:迭代梯度上升
把a作为参数,把最大化Q函数变成一个优化问题,不断迭代得到结果。不过这种方法未必能找到真正的最大值,可能陷入局部最优。而且迅速量也会很大。
方案三:设计网络
这种方案的思想在于修改网络结构,特别设计Q函数来使得解argmax问题变容易。网络结构图如下: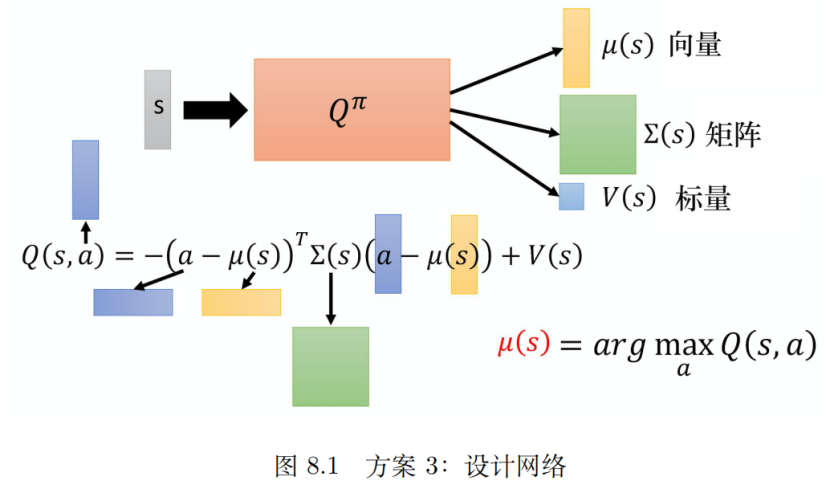
这个网络结构,使状态s经过网络的输出变成了三部分。并且用新的表达式来表示Q(s,a):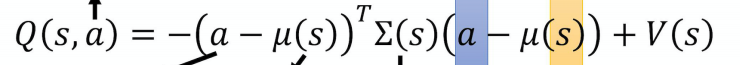
按照等式如果想最大化Q,那么前一个项绝对值应该尽可能小(因为正定性,前面一项是负的)。最极端的情况就是a等于μ(s)。所以如果知道了μ(s)那么就可以确定最优的a了。
方案四:不使用DQN
这种方法有点儿无赖的嫌疑了,但确实很聪明。既然DQN处理连续动作麻烦。就不用DQN了,那用什么呢?将基于策略的方法PPO和基于价值的方法DQN结合在一起就形成演员-评论员方法: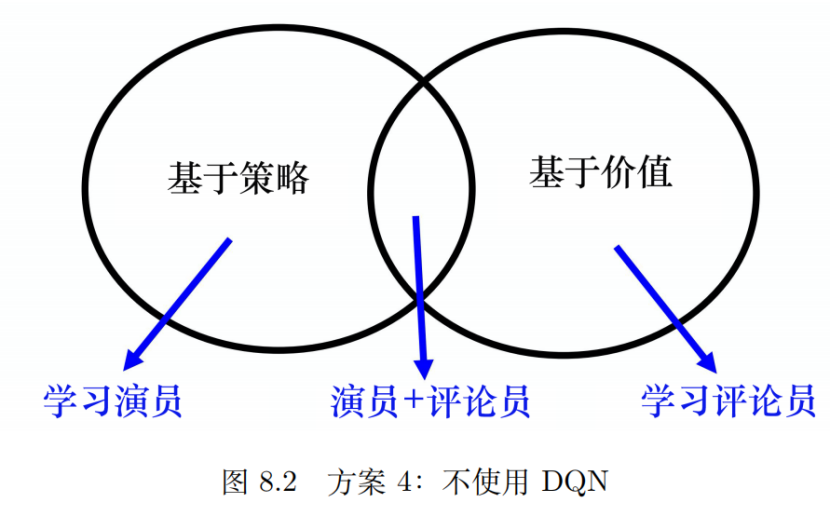
这一章也有一些习题:
因作者水平有限,如有错误之处,请在下方评论区指正,谢谢!
最后
以上就是傲娇咖啡豆最近收集整理的关于(六)深度Q网络的全部内容,更多相关(六)深度Q网络内容请搜索靠谱客的其他文章。








发表评论 取消回复