Q-Learning小结
近期学习了一下Q-Learning相关的内容,重点总结一下学习的难点,即Q-Learing的更新部分。
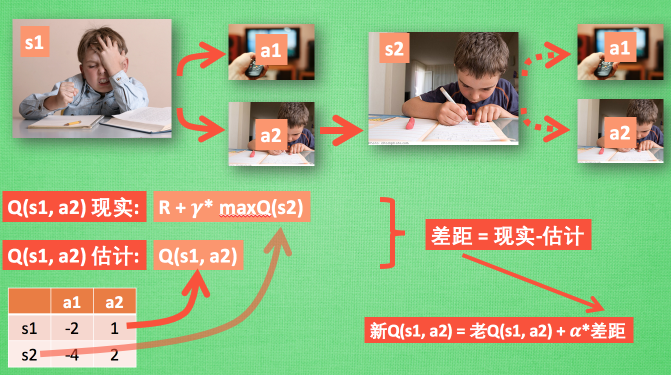
如莫烦大神的图解,在我们学习的状态下,有两种可行的动作,actionList如下:
表1
| a1 | 继续学习 |
|---|---|
| a2 | 去看电视 |
相应的在当前状态下,如果采取对某一动作,那么会对我们产生一定的影响,即受到惩罚还是奖励。我们设当前状态,即我们在学习的状态S1下,执行相应的action的奖惩情况:
表2
| a1 | a2 | |
|---|---|---|
| S1 | -2 | 1 |
此表表示在S1状态下,如果采用a1则会收到惩罚,采用a2会奖励。聪明的娃娃会在S1 状态下选择a2,那么Q-Learning的思想也大体一致。
Q-Learning的思想假如我们现在在S1状态下,选择的a2,到达状态S2,S2的Q表如下:
表3
| a1 | a2 | |
|---|---|---|
| S1 | -2 | 1 |
| S2 | -4 | 2 |
那么在当前S2状态,当前的a1总收益为-4,a2总收益为2,现在我们继续往下,在S2状态下,Q-Learning首先会在当前的实际情况下选择a2,因为a2带给我们的收益是大于a1的,因此会假设我们执行了a2,即我们在当前状态的Q表中选择收益最大的action,MaxQ(a2),且执行了a2后会有奖励R(但R在当前状态并不一定存在),因此将[R+γMaxQ(a2)]称之为Q(S1,a2)的现实值(因为含有R),γ为衰减系数。之后将Q(S1,a2)称之为Q(S1,a2)的估计值。
这里可以这样理解,就是在S1的状态下,执行a2,会到达S2状态,但是此时此刻,我们就处在S2状态,什么action也不选择,但是Q-Learning回去模拟去估计,因此由表2到了表3。其实S2的那一行是实际没有的。
因此实际上的更新如下:
S2=Q(S1,a2)=Q(S1,a2)+alpha[R+γ*MaxQ(a2)]
alpha为学习率
参考:https://morvanzhou.github.io/
最后
以上就是强健机器猫最近收集整理的关于Q-Learning参数更新部分详解的全部内容,更多相关Q-Learning参数更新部分详解内容请搜索靠谱客的其他文章。








发表评论 取消回复