摘要
本文探讨了一种多智能体强化学习方法来解决多智能体协作传输的通信和控制策略设计问题。典型的端到端深度神经网络策略可能不足以覆盖通信和控制;这些方法不能决定通信的时间,只能工作在固定速率的通信。因此,我们的框架采用了七触发架构,即一个反馈控制器,计算通信输入,以及一个触发机制,决定输入何时必须再次更新。利用多智能体深度确定性策略梯度,可以有效地优化此类事件触发控制策略。通过数值模拟,我们证实了我们的方法可以平衡传输性能和通信节省。
引语
应用
协同运输是多智能体系统中的一个重要任务,在配送服务、工厂物流、搜救等领域有着广泛的应用。特别是,对于传输大型或沉重的有效负载,多智能体系统的利用比单一智能体具有优势,包括可伸缩性、灵活性和对单个智能体故障的健壮性。
当今工作
- 大多数使用多智能体[1]-[3]的合作传输都依赖于无线通信来共享观测结果。在这种情况下,随着代理和数据数量的增加,由于丢包和通信延迟,它们的性能会下降。此外,在电池驱动的通信场景中,如果每个代理的通信频率较高,则寿命会缩短。因此,尽量减少交流是至关重要的。
- 尽管可以为简单任务或具有很强假设[4]-[7]的任务推导出合适的通信拓扑,但在一般情况下,很少有原则性的方法来推导最小通信策略。这可能是因为最小通信策略的设计问题与多智能体系统控制策略的设计问题是密不可分的。因此,这些问题需要同时解决[8],[9]。
本文
- 探索一种多智能体强化学习(MARL)方法[10]来解决多智能体协作传输的通信与控制策略设计的同步问题。
- 采用了七触发架构[11],即一个计算通信输入的反馈控制器和一个决定输入何时必须再次更新的触发机制。
- 受到前人[8]工作的启发,在[8]中,策略模型被用来减少从单个代理的网络控制器到其执行器的控制信号。我们将他们的策略模型扩展到多智能体设置中,以减少通信的频率、数量和数据。
实验
为了验证我们方法的有效性,我们进行了两个合作传输仿真。我们通过合作传输来确认我们的框架的有效性,代理被严格地附加到负载上,其最小通信拓扑可以派生出来。此外,我们还通过执行器故障下的协同推送来验证框架的通用性,而执行器故障下的最小通信拓扑是一个难以解决的问题。
本文贡献
- 我们提出了一个在多智能体设置中使用事件触发通信和控制的学习框架,以平衡传输性能和通信节省。
- 我们通过合作传输仿真实验验证了我们的框架的有效性和通用性。
- 我们在使用多个地面机器人的合作运输实验中演示了我们的框架。
行文流程
- 第二节介绍了相关工作。
- 第三节描述了多智能体通信的合作传输问题。
- 第四节介绍了MARL设置的数学公式和事件触发通信与控制的策略模型。
- 第五节通过数值仿真验证了算法的有效性。
- 第六节展示了在仿真中学习到的多智能体策略。
- 第七节讨论了未来的工作和本研究的局限性。
- 第八章对全文进行了总结。
有效载荷是指航天器上装载的为直接实现航天器在轨运行要完成的特定任务的仪器、设备、人员、试验生物及试件等。
相关工作
- 之前协作方法在真正的机器人实验中取得了成功,但它们有一个显著的缺点,即需要精确的有效载荷特性,包括质量、转动惯量或重心。
- Franchi等人[4],[5]提出了一种存在估计不确定性的分散估计和鲁棒控制[6]。然而,这些算法需要频繁地与相邻代理进行通信来进行估计。
- 在不需要通信的情况下,Culbertson等人提出了分布式自适应控制,利用向所有代理广播的有效载荷的当前状态和期望状态。
- 他们为简单任务或具有强假设的任务推导出合适的通信拓扑。然而,在一般情况下,很少有原则性的方法来推导最小的沟通策略。
- 作者提出了一种基于事件触发架构的新方法,通过该方法,每个代理都可以最小化从相邻代理接收末端执行器位置和速度的频率。
- 在不需要动态模型的情况下,一些作者提出了DRL方法来同时学习通信和控制策略[8],[9]。
多智能体通信的合作传输问题
- 在二维无障碍环境中使用一组N个代理的合作运输问题。
- x—位置,θ—偏航角,v—速度,ω—角速度, x∗—有效载荷的期望位置,u—控制输入
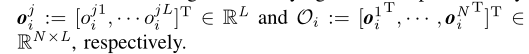
- 这个问题的前提条件是:
- 载荷的质量和惯性矩是未知的;
- 每个代理可以决定进行通信的代理、数据和时间。
- 本研究的目的是控制有效载荷到其期望的位置,同时减少每个控制时间步长的通信代理和数据数量。
- 假设
事件触发的交流和控制的深度强化学习
马尔可夫决策过程
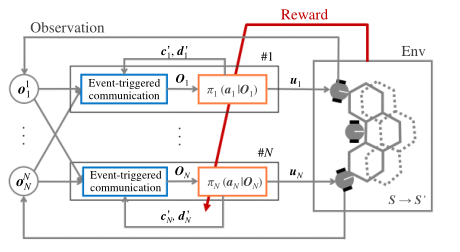
- 根据当前观测O,S基于决策策略PI采取动作A获得奖励R
- A包括控制输入以及用于确定通信和接收数据的代理的变量
- R带有折扣因子、通信代价、传输表现
事件触发的通信与控制学习框架
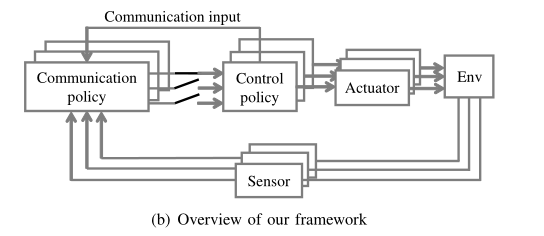
- 提出了一种多智能体协作传输的事件触发通信和控制学习框架。我们的框架采用了事件触发的通信架构和通信与控制的联合策略
- 如图2(a)所示。在事件触发通信体系结构中,每个代理决定每个控制步骤的agent和接收的数据,
- 如图2(b)所示。在通信与控制的联合策略中,每个代理计算当前控制步骤的控制输入和下一个控制步骤的通信输入。
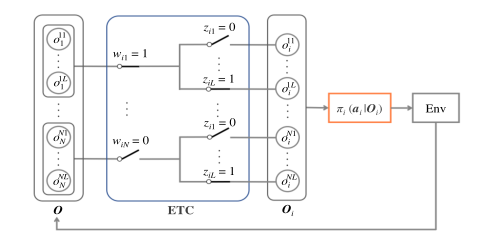
策略模型
- Wij表示代理i是否与代理j交流
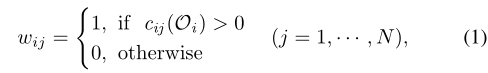
- Zil表示代理i能否观测到代理j
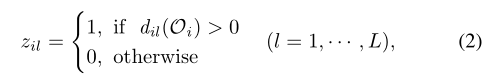
- c、d表示通信输入
- O的更新
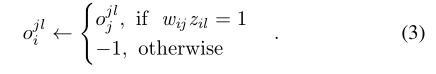
- 交流和控制的联合策略
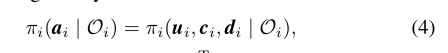
- 通信输入用于更新下一个控制步骤(2)-(4)中的观测值
奖励设计
- 为了平衡控制性能和通信节省
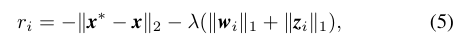

协作运输仿真
- 高固定速率通信:每个座席每0.25秒接收一次所有数据,与控制周期相同。
- 没有通信:在整个事件中,每个代理都没有从其他代理接收数据。
- 低固定速率通信:每个agent每5秒接收一次所有数据,这比我们方法中通信成本相同的速率要高。
代理严格附着于有效载荷的合作运输
- 其最小通信拓扑是分析上可处理的[7]。利用向所有agent广播的当前和期望的负载位置,就可以将负载位置控制为期望的位置。
- 结论
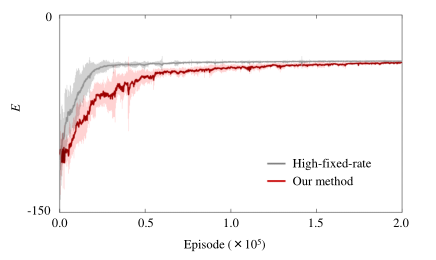
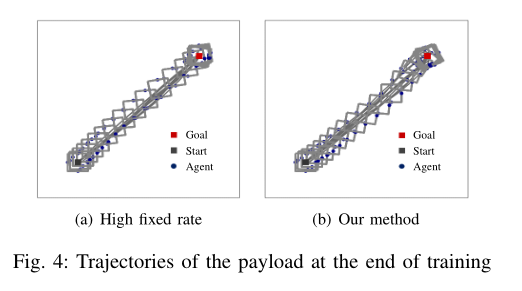
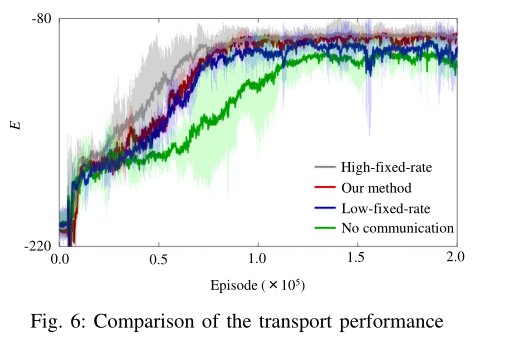
- 两种方法在各时段的传输性能如图3所示。结果表明,该方法使传输性能收敛到几乎与高固定速率通信相同的值。每次训练结束后,两种方法均可将有效载荷的位置控制在其期望位置附近,如图4所示。
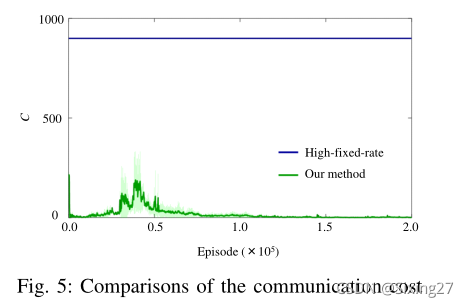
- 该方法使通信成本几乎等于零。这表明在应用我们的方法时,每个agent都没有从其他agent那里获得位置、速度或力。
- 我们的框架既可以推导出实现任务的控制策略,也可以推导出具有刚性负载的代理组的协作传输问题的无通信拓扑结构。
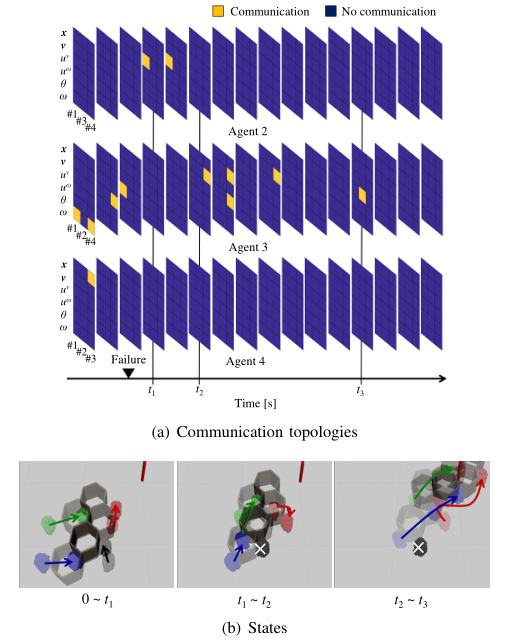
协同推动执行器故障
- 每个agent不能直接知道故障发生的时间和位置,故障发生的时间和位置在每一集都在变化。
- 结论
- 表6中每种方法的运输性能。结果表明,该方法使传输性能收敛到与高固定速率通信几乎相同的值。
- 为了定量比较通信拓扑结构,我们将训练后的策略执行1000次,并评估最后一步有效载荷位置距离期望位置0.2m以内的成功率。从结果来看,我们的方法获得了与高固定率通信相同的成功率,如表3所示。

- 同时,我们的方法使得通信成本小于高固定率和低固定率通信,如表四所示。

- 我们的算法经过训练后得到的通信拓扑和状态如图7所示。就在agent 1执行器失效后,agent 2收到了agent1的速度输入,并剧烈地改变了其推动位置。这表明agent 2根据速度输入知道故障的发生,从而选择其动作。此外,在任务结束时,agent3接收速度输入,而agent 3试图使有效载荷的位置收敛到期望的位置
- 总之,与其他通信拓扑相比,我们的框架可以实现更多的通信节省,同时保持与高固定速率通信相同的良好传输性能,即使是对于那些最小通信拓扑在分析上难以解决的复杂任务
- 表6中每种方法的运输性能。结果表明,该方法使传输性能收敛到与高固定速率通信几乎相同的值。
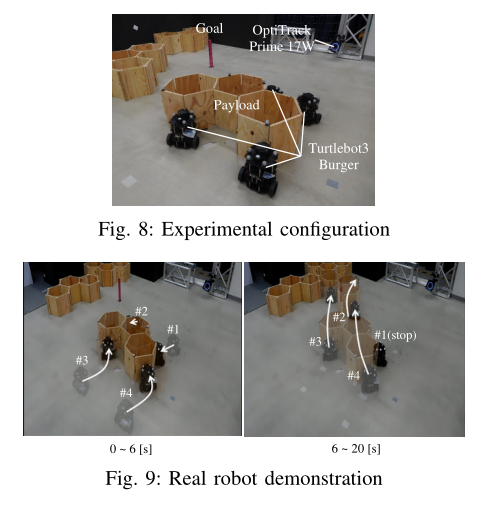
真实场景
- 利用120 Hz的运动捕捉系统观察了有效载荷和药剂的位置和偏航角。利用测量的位置和偏航角计算速度和角速度。控制输入是在带有8核IntelCore i7 (2.80 GHz)、32gbRAM的控制PC中计算的,使用从这些测量中模拟学习到的策略,并通过Wi-Fi通信以4hz的频率发送给每个机器人。
展望
- 在未来的工作中,我们计划将我们的算法应用于协同操作系统的设计。
- 让我们考虑一个在代理与其安装的传感器之间需要最少通信的合作传输问题。
- 通过应用该算法,我们可以推导出具有最小观测值的控制策略,并确定协同操作所需的最小传感器配置。
- 由于仿真模型的物理参数与实验模型的物理参数不同,训练后的多智能体策略在实际实验中的表现较差。为了解决这个问题,我们计划使用域随机化[27]使多智能体策略更稳健,并定量评估训练后的策略。
- 我们应该使用[28]中提出的递归多主体深度确定性策略梯度模型来检验我们的算法在部分可观测环境下是如何工作的。
最后
以上就是自由小虾米最近收集整理的关于多智能体协同传输的事件触发通信与控制的深度强化学习(ICRA-2021)的全部内容,更多相关多智能体协同传输内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复