1,OVS组件构成
1.1,组件列表
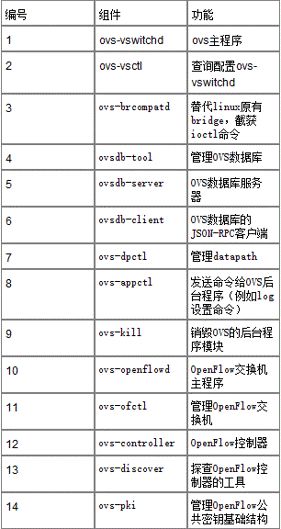
1.2,组件关系
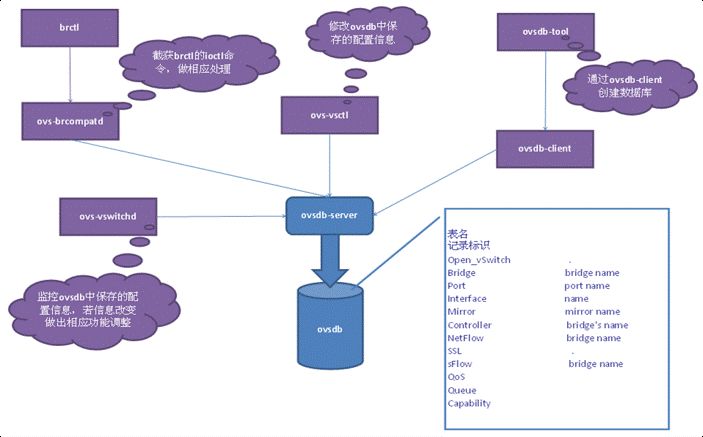
1.3,数据库表
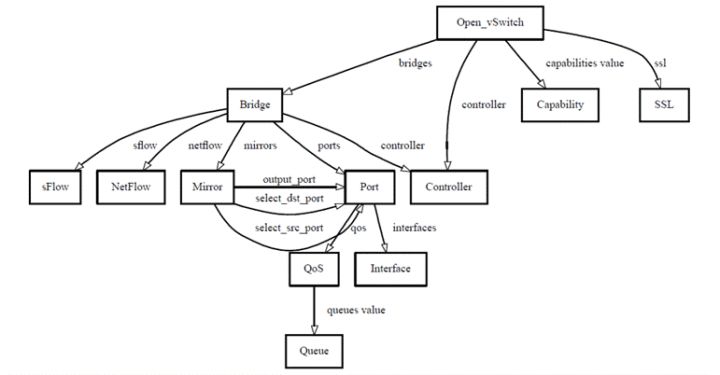
1.4,组件互动
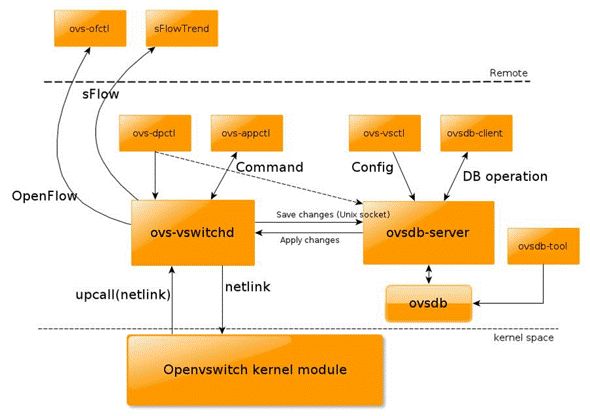
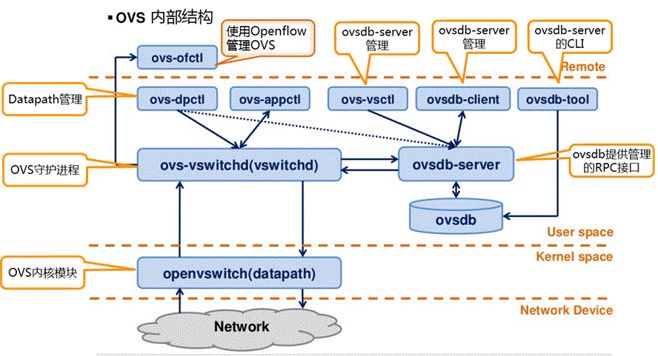
1.5,目录结构
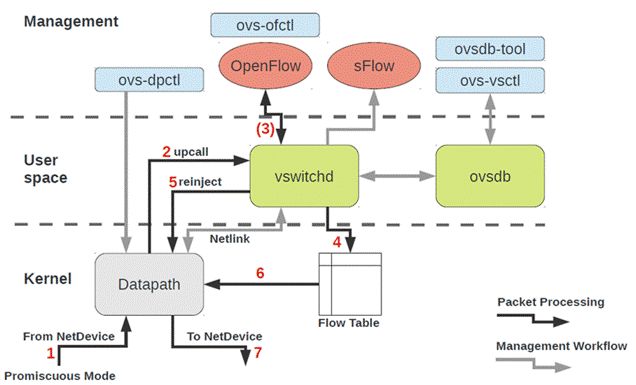
2,总体框架
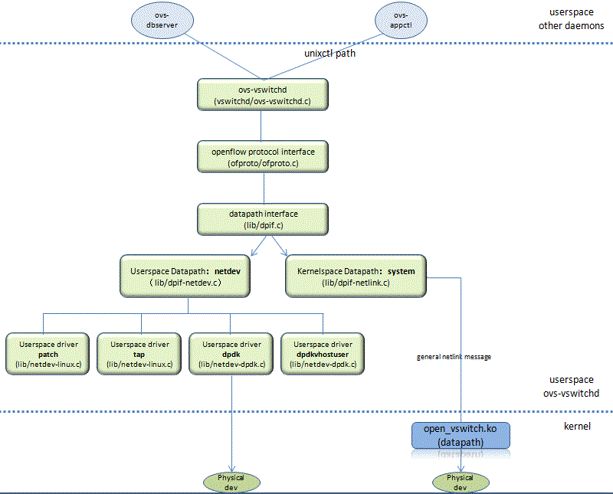
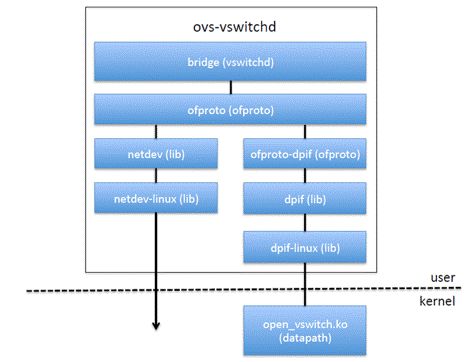
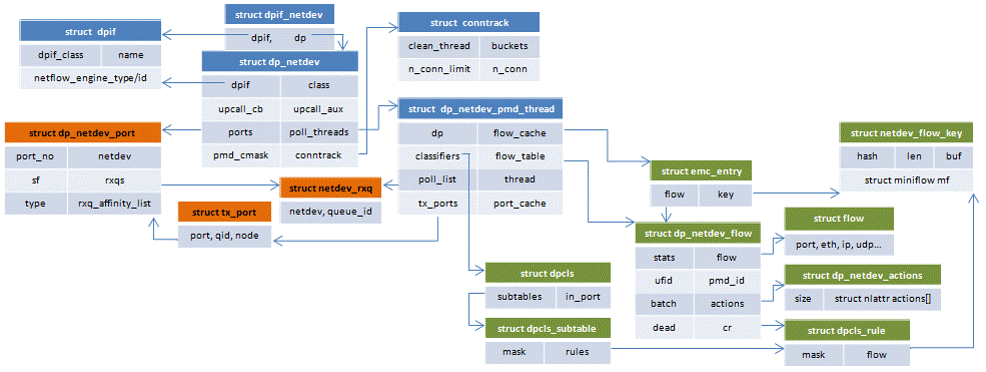
3,数据结构
4,数据包转发流程
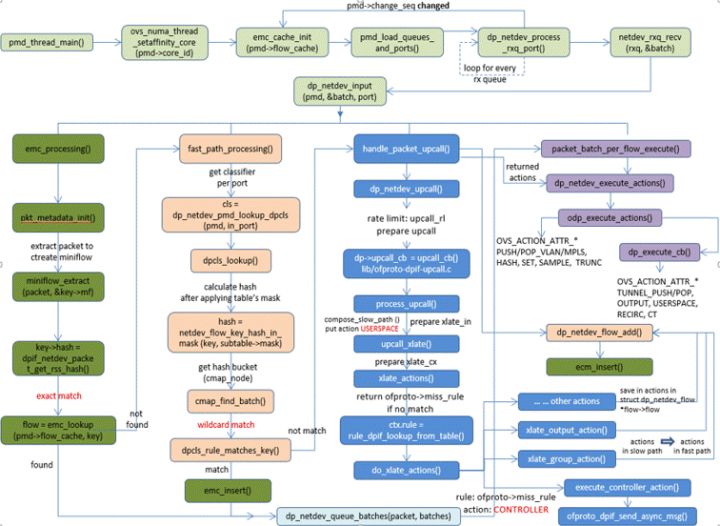
为了兼顾性能与功能,当前OVS被设计成3级转发路径,从快到慢依次为:EMC,Megaflow,openflow。
EMC转发:
包进入的第一个转发路径称为EMC,即用包中所有字段作为key去查找精确匹配缓存,若找到则得到一条flow,其中包含转发需要的所有信息。EMC设计为开放地址的hash表,它用memcpy()进行报文全字段比较,因为不进行额外的判断,因而比较快。
Megaflow转发:
当EMC路径找不到匹配的flow时进入第二级转发路径fast path简称dpcls,每一个端口有一个dpcls。在dpcls中每一种元组分配了一个hash表,一种元组可以认为是一种匹配类型或一个掩码,比如(source IP/24, destination IP/24)是一种元组,(src IP/24, dest IP/24,src port,dest port)是另一种元组。注意(source IP/24, destination IP/24)和(source IP/32, destination IP/32)是两种元组。每个dpcls的hash表有自己的hash算法。找到对应的桶之后进行wildcard匹配即只匹配掩码中为1的字段。fast path实际上也很快,但由于要进行掩码匹配,它比EMC稍慢。
openflow转发:
当fast path也找不到匹配的flow时进入第三级转发路径upcall。upcall首先会进入openflow协议层查找其内部的流表,若找得到则执行其中的动作。openflow协议层内的流表查找也是基于掩码的查找,因为它是openflow协议的全面实现,包含了table,group,meter等EMC, fast path所不包含的元素,所以会比较慢。如果在openflow协议层内还找不到匹配的flow则需要把包发送给远程的controller,以期它在收到packet in消息后添加一条flow到本地openflow switch。同时controller也应该用packet out消息把包发回到本地openflow switch基于更新后的流表进行再转发。upcall路径因为涉及到远程消息交换,因而是最慢的。
在这3层转发路径中,在慢路径找到flow时会在快路径插入一条新流,以在下一次走快路径。比如在openflow路径找到流时会将流插入megaflow和EMC,在megaflow找到流时会将流插入到EMC。
5,流表生成
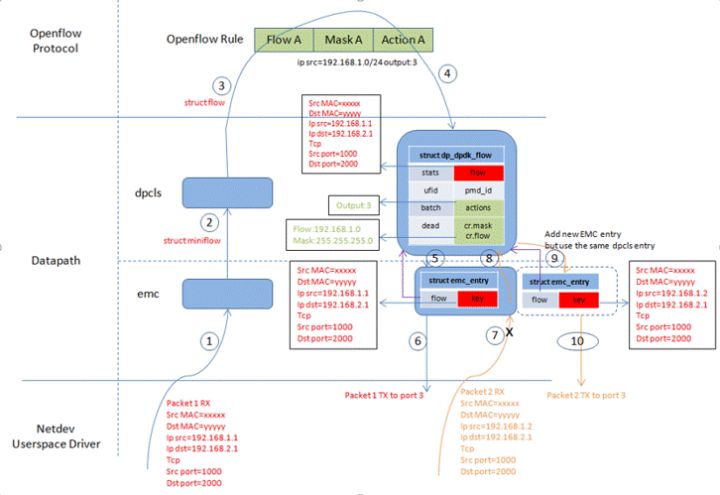
我们假设ofproto层有一条规则:将源IP在子网192.168.1.0/24内的包送往3号端口我们假设ofproto层有一条规则:将源IP在子网192.168.1.0/24内的包送往3号端口。初始时EMC和dpcls均为空。
- 1->2->3 : 此时收到一个源IP为192.168.1.1的包,因为EMC和dpcls均为空,故走到upcall流程,上ofproto层。此时会命中openflow层的规则。
- 4: upcall 流程走完后会在dpcls里添加一个dpcls entry,其中的flow取自于包的全部信息,可见dpcls->flow.ip_src=192.168.1.1。action取自于ofproto层返回的action。dpcls->cr.mask取自于ofproto层返回的mask。dpcls->cr.flow是dpcls->flow与dpcls->cr.mask互与的结果,因此是192.168.1.0。
- 5:在dpcls添加条目的同时也会在EMC添加一个条目,EMC条目的flow指向了上面新创建的dpcls entry,而key则是取自于包的全部信息,因此ip src=192.168.1.1。
- 6:第一个包完成所有动作,从3号口发出去。
- 7->8:此时再收到一个源IP为192.168.1.2的包,虽然此时EMC不为空,但EMC条目的key是ip src=192.168.1.1,所以它并不匹配第二个包,因此继续走到dpcls进行fast path查找。
- 9:虽然第二个包的源IP 192.168.1.2并不匹配dpcls->flow里的ip src 192.168.1.1,但是它匹配dpcls->cr.flow与dpcls->cr.mask的结果192.168.1.10/24,所以第二个包还是会命中dpcls中唯一的条目,而不会走到upcall流程。
- 10:走完fast path后会在EMC添加一个条目,EMC条目的flow指向了上面新创建的dpcls entry,而key则是取自于包的全部信息,因此ip src=192.168.1.2。
第二个包完成所有动作,从3号口发出去。
4.1,emc entry是如何生成的?
包开始进行EMC查找时会从包解析出一个miniflow的结构,这也是EMC和fast path的搜索key。EMC中找不到条目时会走到fast path即dpcls,这时会找到一个struct dpcls_rule。根据包生成的miniflow搜索key + struct dpcls_rule cast转换成的struct dp_netdev_flow就构成了EMC entry。由此可见emc entry里的key是根据包的具体内容抽取出来的,它包含了一个包的所有信息(src mac, dst mac, src ip, dst ip, src port, dst port),甚至是meta data。搜索emc表时需要全部信息匹配才能命中,这也就是为什么EMC叫extact match cache。
4.2,dpcls entry是如何生成的?
在emc和fast path中都找不到条目时,会走到upcall流程,去查找ofproto层的rule。走upcall流程上ofproto层时会带一个search key:一个struct flow结构,这个结构是从miniflow扩展得来。我们已经知道这个miniflow实际包含从包抽取出来的所有信息。查找的结果是返回一个mask和一系列的actions, 当然也包含早就准备好的flow。dpcls entry即struct dp_netdev_flow结构包含4个关键信息:
- flow->flow:它就是上面已经构造好的struct flow,包含包抽取出来的全部信息,由miniflow扩展而来。
- flow->actions:这个是由ofproto层将ofproto层的action翻译为dpif层的action得来。
- flow->cr.flow:这个是由flow->flow和ofproto层返回的mask互与之后的结果,所以它只包含mask中没有屏蔽的字段,并没有包含数据包的全部信息。
- flow->cr.mask:这个就是ofproto层返回的mask。
4.3,miniflow和flow的区别
struct flow {
struct flow_tnl tunnel;
ovs_be64 metadata;
... ... ...
struct eth_addr dl_dst, dl_src;
ovs_be32 nw_src, nw_dst;
... ... ...
};
struct miniflow {
struct flowmap map;
/* Followed by "uint64_t values[n]", where 'n' is miniflow_n_values(miniflow). */
};miniflow是flow的稀疏表示形式,flow通常比较大且大部分域为0,这样会占用比较多的内存,搜索匹配时也会耗费更多时间。miniflow通过增加一个map指明flow中哪些字段(以uint64_t为单位)不为0,从而只需要保存那些非0的字段。所以miniflow一般用来搜索匹配,而flow用于保存完整包信息。
6,upcall
6.1,基本概念
6.1.1 dpif层和dpif-upcall层的区别和联系
区别:dpif层代表的是快速转发路径,它依赖于EMC快表和fast path快速路径,在dpif层只有端口概念没有bridge概念,dpif-upcall层代表的慢速转发路径,它依赖的是openflow流表,在dpif-upcall层有bridge概念。
联系:虽然dpif层和dpif-upcall层在转发数据包的速度上有区别,但它们对包所做的动作是一样的,即它们所完成的逻辑功能完全一样。所以从更高层的用户视角看dpif层和dpif-upcall层都是一种datapath,即数据转发路径。数据包在走完一次慢速路径即dpif-upcall之后会把慢速路径对包做的所有动作转换为快速路径的动作,同时在快速路径添加一条快流表,这样同一条流的后续包下次就可以不走慢速路径而直接走快速路径。
6.1.2 Revalidator
Revalidator检查快速路径中的流缓存(pmd->flow_table),检查流及其action是否还继续有效。若继续有效则保留它不做修改。若能对流及其action做部分修改后保持其有效则修改后保留它。若流已完全无效则从快速路径的流缓存中删除流。
6.1.2.1 为什么要做revalidator重验证?
真正的流表是在openflow协议层,快速路径中的流缓存(pmd->flow_table)是upcall被openflow协议层处理之后再安装到快速路径(pmd->flow_table)的。这类似于内存与cache的关系。相应的,也面临内存与cache之间类似的同步问题。
openflow协议层中的流表是由controller下发的,如果流表规则在安装到快速路径缓存(pmd->flow_table)之后又被controller改变了,那么同一个流表规则在openflow协议层和快速路径缓存(pmd->flow_table)之间就是不一致的,需要同步它们。
这种同步的结果要么就是从快速路径缓存(pmd->flow_table)中删除流表规则,要么就是修改快速路径缓存(pmd->flow_table)中的流表规则使其与openflow协议层一致。前一步似于cache的invalidate操作,后一步类似于reload操作。
类似于memory与cache,当cache快要满时,我们需要换出一些cache line以加载另外的内存区到cache上。所以当快速路径缓存(pmd->flow_table)快要满时我们要删除其中一些流表规则,以缓存后续的流。一个删除缓存流的策略是删除最长时间不被使用的缓存流,这也类似于cache机制。
6.1.2.2 ukey
快速路径缓存很大(8k),并且revalidator是一个周期性的动作,这意味着revalidator要在短时间内重验证大量的流表规则,工作量很大。这里采取的第一个优化是为每条流分配一个唯一的ukey,这样除第一次外后续的查找仅需比较ukey而不再要进行掩码wildcard匹配。
ukey起什么作用?
在进行revalidate的时候需要从dpif层的流内提取很多信息,比如key/mask/actions/stats等,用于判断是否删除流和进行ofproto / dpif层的action翻译,而revalidate是一个很频繁的操作,如果每次都实际提取这些信息就会相当耗时,所以设计了一个terse精简模式:每次从dpif层dump流时只读取一个ufid,在给流分配ukey时再调用dpif_flow_get()以DPIF_OP_FLOW_GET命令执行dpif_dpdk_operate()以获取流的全部信息,包括key/ mask/ actions/stats等。一旦ukey被分配后,后续的dump将会很简洁,仅需根据从dpif层获取的ufid查找udpif->ukeys得到流的ukey,再更新ukey中的stats和used。这样xlate_actions()需要的很多信息就被缓存在ukey里了,包括上一次翻译后的actions,而不需要每次revaliadte都去重新获取。
6.1.2.3 主从线程
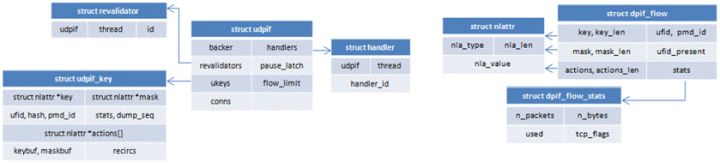
上面介绍了revalidator要验证大量的流表规则,工作量很大。这里采取的第二个优化是启用多线程,每个线程只负责快速路径缓存中的一部分流表规则。一个udpif会启动多个revalidator线程,其中第一个线程称为主leader线程。
6.1.2.4 dump
revalidator线程每次从快速路径缓存中取出一部分流表规则,然后逐个验证其是否还有效。这样一个过程称为一次dump,每次dump有一个序列号dump_seq。
6.1.2.5 Revalidator的2阶段工作
Revalidator线程搜集流的统计信息,当发现一条流长时间没有被使用时删除流。 Revalidator工作在2个阶段"dump","sweep"中的任何一个。
在"dump"阶段,Revalidator线程读取流为每条流创建一个唯一的ukey,将流的统计信息 保存在以ukey为关键字的表中。Revalidator也会在发现一条流长时间没有被使用时删除流。 因为有多个Revalidator线程,每个线程都可能会去处理同一条流,为避免冲突,在这一阶段 不会删除流的ukey,当流的ukey在一个Revalidator线程内能找到时流只在这个线程处理。
在"sweep"阶段,所有流被划分为几个段,每个revalidator负责不同的段。 revalidator检查每条流的统计信息以确定其是否应该被删除。
6.1.3 处理upcall的2种方式:线程模式 和 callback模式
线程模式:
thread模式,即起若干个线程处理upcall,在这种模式中快速转发路径和慢速转发路径是2条不同的执行流,分别在不同的线程中处理,它们可以并行处理。这种模式的好处是,如果upcall开销很大,则分开线程处理upcall可以让upcall不影响快速路径转发。对应的坏处是upcall响应比较慢。内核system datapath采用这种模式,因为它的upcall需要从内核态切换到用户态,开销非常大。目前dpdk datapath也采用了upcall线程分离的模式。
callback模式:
callback模式,即需要处理upcall时直接调用dpif-upcall层处理upcall的callback在当前线程中处理upcall。在这种模式中,快速路径和慢速路径在同一个执行流中,属同一个线程,二者为顺序执行,不能并行。当快速路径切换到慢速路径开销比较小时(比如用户态datapath)可以采用这种模式快速响应upcall。目前用户态datapath netdev采用了这种模式。
如果处理upcall的代价比较小,比如在用户空间datapath:netdev和dpdk中,转发路径可能不想使用单独的线程处理upcall,而是将EMC,fast path,upcall这3条转发路径运行在同一个执行线程中。
在这种模式下dpif-upcall层调用API:dpif_register_upcall_cb()向dpif层提供处理upcall的callback。
这种模式的问题当前面的慢包(走upcall路径)过多时,会抢占后面快包(走EMC或Fast path路径)的时间。从而导致整体的性能下降。
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !
6.2,数据结构
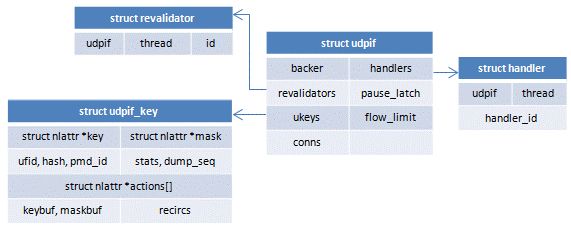
6.3,框架结构
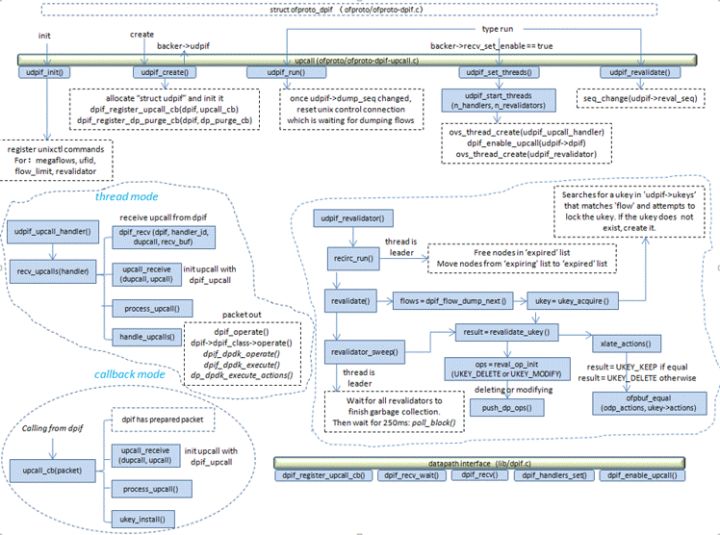
6.4,udpif_revalidator
系统在初始化时会启动多个revalidator线程,存放在udpif->revalidators[x]数组中。其中的第一个线程称之为leader线程。
6.4.1 dump_seq和reval_seq的作用
revalidation实际上有2种触发机制:
一是周期性触发,这是通过leader线程每500ms改变一次udpif->dump_seq进行的在revalidate(revalidator)函数中会检查ukey->dump_seq是否等于udpif->dump_seq相等时不验证。因为leader线程会周期性改变udpif->dump_seq,所以流也会被周期性验证每一轮revalidation之后,ukey->dump_seq会被赋值为udpif->dump_seq。
另一种是主动通知。当ofproto层改变了流表规则,会调用udpif_revalidate()主动改变udpif->reval_seq。在revalidate_ukey()中会检查ukey->reval_seq是否等于udpif->reval_seq,如果不相等则必须重验证流。reval_seq不相等的另一层含义是我们不能再使用之前创建的ukey->xcache,而必须新创建一个。一般来说,udpif->reval_seq由某些上层的事件触发,它的变化频率没有udpif->dump_seq那么高在revalidate_ukey()中验证完流以后会把ukey->reval_seq 赋值为udpif->reval_seq。
6.4.2 第一阶段工作(仅leader线程参与)
6.4.2.1 recirc_run()回收释放struct recirc_id_node内的struct recirc_state结构
struct recirc_id_node内嵌了一个struct recirc_state结构,struct recirc_state用于存储flow translation时需要的一些临时信息,struct recirc_id_node用来组织struct recirc_state。
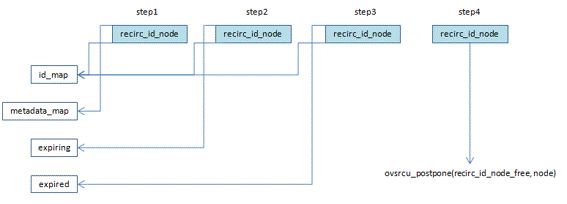
- 1,struct recirc_id_node及其内嵌的struct recirc_state在初始化分配后被放在id_map和metadata_map这两个cmap中
- 2,当recirculation节点因为xxx原因引用计数减为0时从metadata这个cmap移出到expiring链表
- 3,当recirculation节点在expiring链表待了超过500ms后被leader线程移出到expired链表,
- 4,当recirculation节点在expired链表待了超过500ms后被leader线程移出expired链表,同时也从id_map这个cmap移出,至此,recirculation节点将无法再被查找到,所以可以安全的以ovsrcu_postpone()形式释放了
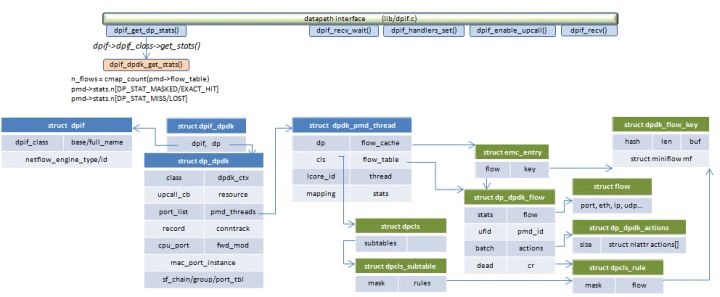
6.4.2.2 udpif_get_n_flows()在dpif层(datapath)读取流的总数
读取datapath中流的总数是一个频繁的操作,所以需要给它限定一个时间间隔:100ms。udpif->n_flows_timestamp记录了上一次读取操作的时间,udpif->n_flows记录了上一次读取的值,如果当前时间与上一次读取操作的时间间隔不超过100ms,则继续使用上一次读取的值。否则执行一次新的读取操作:dpif_get_dp_stats()。
6.4.2.3 检查是否需要暂停revalidator线程(udpif->pause)
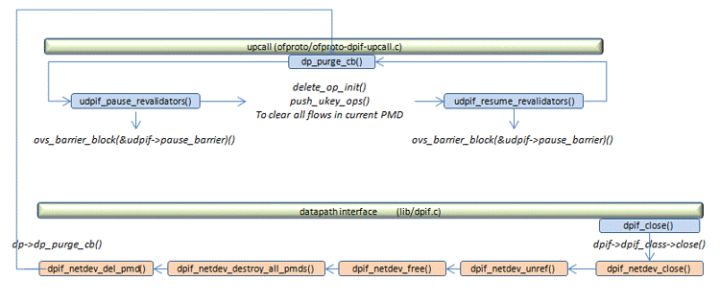
当要停止并删除某个pmd线程时需要暂停所有revalidator线程以删除此pmd中的所有流,暂停revalidator线程是为了避免revalidator dump flow而pmd同时delete flow。
6.4.2.4 检查revalidator线程是否需要退出(udpif->reval_exit)
6.4.2.5 调用dpif_flow_dump_create()创建一个dump上下文:udpif->dump
6.4.3 第二阶段工作(leader/worker线程都参与)
6.4.3.1 如果udpif->pause == 1则暂停revalidator线程。如果udpif->reval_exit == 1则退出当前线程,也即停止revalidate过程。
6.4.3.2 revalidate(revalidator):
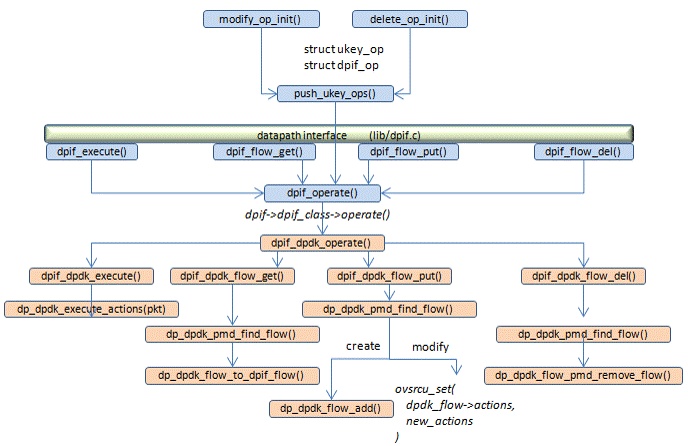
*首先创建一个thread dump上下文,即一个struct dpif_flow_dump_thread结构。
*批量dump流:
n_dumped = dpif_flow_dump_next(dump_thread, flows, ARRAY_SIZE(flows))
dpif->dpif_class->flow_dump_next()
dpif_dpdk_flow_dump_next() 需要注意的是并不是一个revalidator线程处理一个pmd内的流,而是所有revalidator线程先处理同一个pmd内的流,这个pmd内的流都处理完毕了,所有revalidator线程再转向处理另一个pmd内的流。
需要dump的是pmd->flow_table内的流。在dpif-dpdk这一层dump的是struct dp_dpdk_flow结构,但是upcall这一层需要的是struct dpif_flow结构,因此需要进行转换。
dp_dpdk_flow_to_dpif_flow() 将datapath层的struct dp_dpdk_flow结构转换为dpif层的struct dpif_flow结构 注意在terse精简模式下,并不真的读取key/mask/actions,这些信息会延迟到为流分配ukey时(ukey_acquire())才读取。
*ukey_acquire()对于dump的每一条流,lock它的ukey,如果流还没有ukey就为它分配一个
struct udpif_key *ukey = ukey_lookup(udpif, &flow->ufid)每条流的ukey挂在udpif->ukeys中,这个hash表的每个桶是一个struct cmap,流的ufid进行hash后插入对应的桶,ukey的比较也是通过ufid进行的,ufid相同则ukey相同。
如果根据struct dpif_flow的ufid找不到流的ukey则需要为其创建一个ukey_create_from_dpif_flow(udpif, flow, &ukey) -> ukey_create__()struct udpif_key的内容绝大部分来自于struct dpif_flow,比如key/mask/actions/ufid/pmd_id/keybuf/maskbuf/stats,但是actions翻译时需要用到的ukey->xcache被置为空。
如果开启了terse精简模式则调用ukey_create_from_dpif_flow()时dump的struct dpif_flow内实际上是没有key/mask/actions等信息的,这时就需要以一个DPIF_OP_FLOW_GET命令去执行dpif_dpdk_operate()以获取这些信息。这一步是通过调用dpif_flow_get()实现的。
ukey_install_start(udpif, ukey)新创建的ukey需要根据其ufid挂接到udpif->ukeys上去。
*leader线程在每一轮revalidation后递增ukey->dump_seq每条流被revalidate后其ukey->dump_seq 赋值为 dump_seq如果ukey->dump_seq等于udpif->dump_seq表示流已经被dump过了,因此跳过这条流。
*根据流空闲的时间判断是否需要删除这条流
正常情况下如果一条流连续空闲10s(没有包命中这条流)则需要删除这条流,但如果流的总条目数超过2 * udpif->flow_limit,则不考虑流的空闲时间而无条件删除流,但如果流的总条目数超过udpif->flow_limit但不超过2 * udpif->flow_limit,则将流的最大允许空闲时间降低为100ms,这样会加速删除流,而不至于让dpcls内的流表充满。
*revalidate_ukey()如果根据空闲时间流还不需要删除,那么就要重验证这条流是否能继续保留或修改之后能保留
每一轮dump,udpif->reval_seq会加1,每个ukey也有一个ukey->reval_seq表示上一次验证时的序号当两者不同时说明需要对流进行重验证了。
有一些简单的判断条件可以用来快速判断流是否需要删除:如果命中这条流的数据包的速率不超过5pps则删除它,如果自上次重验证以来还没有包经过这条流则保留这条流,如果自上次重验证以来ukey->xcache还没有超时删除则保留这条流。
开始重验证过程
1,首先需要将ukey转换为struct flow结构
2,查找ofproto上层结构,也就是要找到进行action翻译的实体
3,创建并初始化ukey->xcache = xlate_cache_new()
4,将ofproto层的action翻译为dpif层的action:xlate_actions(&xin, &xout);
5,调用xlate_in_init()初始化struct xlate_in xin
6,调用xlate_actions(&xin, &xout)将ofproto层的actions翻译为dpif层的actions
7,翻译好的actions存放在xin->odp_actions内
所谓重验证就是比较翻译好的actions(xin->odp_actions)和ukey内的actions(ukey->actions)如果相同则保留流,如果不同则修改流。actions的比较是纯粹的ofpbuf中的内存比较memcmp()。
将ukey->reval_seq 设置为 udpif->reval_seq。
*上面revalidate_ukey()返回的结果只有UKEY_KEEP / UKEY_DELETE / UKEY_MODIFY三种:
- 对于UKEY_KEEP实际上不需要做任何处理
- 对于UKEY_DELETE我们需要以DPIF_OP_FLOW_DEL命令去执行dpif_dpdk_operate
- 对于UKEY_MODIFY我们需要以DPIF_OP_FLOW_PUT命令去执行dpif_dpdk_operate
6.4.3.3 ovs_barrier_block(&udpif->reval_barrier)等待所有revalidator线程完成第一阶段dump过程
6.4.3.4 revalidator_sweep(revalidator)
leader线程在每一轮revalidation后递增ukey->dump_seq每条流被revalidate后其ukey->dump_seq 赋值为 dump_seq在revaliadtion的第一个步奏dump中,只能重验证那些现在存在于datapath中的流,但是有很多情况下流可能已经从datapath中删除了,但是它的ukey还保存在udpif->ukeys中,这时就需要对这些残余的ukey进行清理了,这就是revaliadtion的第二个步奏seep。
如果一条流在revaliadtion的第一个步奏dump中已经被验证过了,那么其ukey->dump_seq 已赋值为 udpif->dump_seq,同时其ukey->reval_seq 也已赋值为 udpif->reval_seq此时这条流就不需要在revaliadtion的第二个步奏sweep中再次验证了。
残余的ukey可能很多,每个revalidator线程只负责清理其中的一部分这里把所有的ukey按照udpif->n_revalidators大小分成很多区块,在每个区块中,revalidator线程只负责自己索引(index = revalidator - udpif->revalidators)对应的umap,即umap = udpif->ukeys[index]。
清理的动作实际上跟第一步类似,只不过少了从datapath层dump流的过程,所以它也是通过调用revalidate_ukey()来对ukey进行验证,验证后的结果如果不是UKEY_KEEP则需要以DPIF_OP_FLOW_DEL或DPIF_OP_FLOW_PUT命令去执行dpif_dpdk_operate。
6.4.3.5 ovs_barrier_block(&udpif->reval_barrier)等待所有revalidator线程完成第二阶段sweep过程
6.4.4 第三阶段工作(仅leader线程参与)
seq_change(udpif->dump_seq)递增dump_seq以触发下一轮revalidation。根据dump时间调整下一次dump flow的条数udpif->flow_limit。注册timer唤醒事件:poll_timer_wait_until(500ms)。注册序列号变化唤醒事件:seq_wait(udpif->reval_seq, last_reval_seq)等待udpif->reval_seq的序列号变化,注意ofproto-dpif里的type_run()函数会周期性的调用udpif_revalidate(backer->udpif)以改变udpif->reval_seq序列号。注册latch等待事件:latch_wait(&udpif->exit_latch),当udpif->exit_latch置为1时唤醒线程。注册latch等待事件:latch_wait(&udpif->pause_latch),当udpif->pause_latch置为1时唤醒线程。poll_block()进入等待,直至上述timer/seq/latch唤醒事件发生。
原文链接:https://zhuanlan.zhihu.com/p/541699224
最后
以上就是淡淡石头最近收集整理的关于ovs简介的全部内容,更多相关ovs简介内容请搜索靠谱客的其他文章。








发表评论 取消回复