事务:
1)概念:事务就是一个或者多个SQL语句组成的单元,在这个单元中,每个SQL都是相互依赖的。通俗地讲事务就是一个整体,里面的内容要么全部执行成功,要么都不成功,不可能存在部分执行成功的情况。如果执行某一条SQL语句出现异常时,整个事务将会执行回滚,整个事务会回到最初的状态。
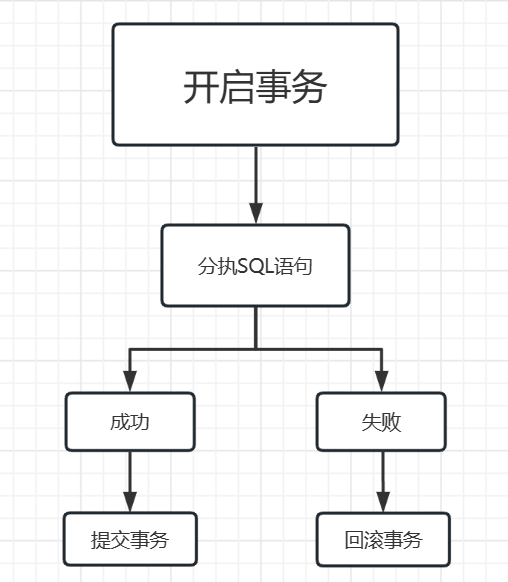
2)事务的四大特征(ACID):
原子性(Atomicity) 每个事务都是一个整体,不可再拆分,事务中所有 的SQL语句要么都执行成功,要么都失败。
一致性(Consistency) 事务在执行数据库的状态与执行后数据库的状态保 持一致。如:转账前2个人的总金额是2000,转账后2个人的总金额也是2000。
隔离性(Isolation) 事务与事务之间不应该相互影响,执行时保持隔离的状态。
持久性(Durability) 一旦事务执行成功,对数据库的修改是持久的。就算关机,也是保存下的。
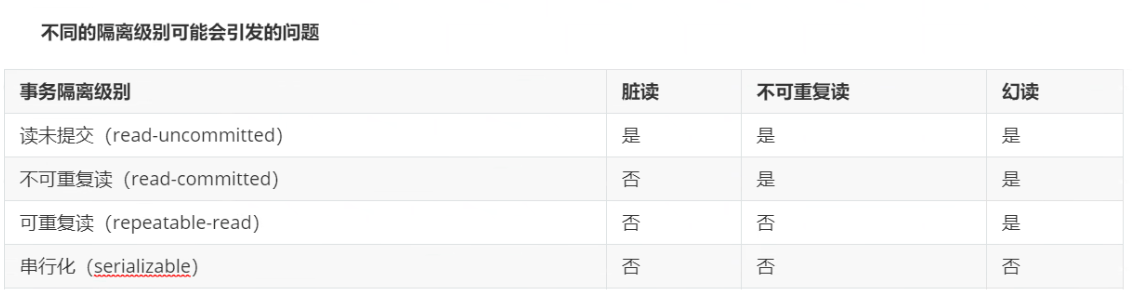
3)事务的隔离级别
当多个事务同时操作一张表时,会出现各种并发问题,并且在不同的事务隔离级别下出现不同的并发问题。
并发问题
并发访问的问题
更新丢失:当当事务A和事务B在操作同一个值1000时,事务A把该值更新成了800了,而此时事务B读取的值还是1000,事务B在1000的基础上进行更新,而不是在800的基础上进行更新。
脏读:事务A把值1000更新成了800,但还没有提交。事务B此时去读取改值时,读取到了800而不是1000。事务B读取到了事务A还没有提交的数据。
不可重复:一个事务将数据进行查询,在第二次查询期间,另一个事务对数据进行了修改,导致第二二次查询的结果不再重复。
幻读:一个事务对全部数据进行了修改,同时另一个事务添加了一条数据。第一-次操作的事务查看数据时,发现有一条没有修改的数据,以为产生了幻觉。
张三给李四转200
1)事物成功提交
开启事务 start transaction/begin
start transaction;
张三转出200
update account set money = money - 200 where name = '张三';
此处发生了错误
李四收入200
update account set money = money + 200 where name = '李四';
select *from account;
提交事务,此时将SQL提交,表中的数据才真正被改变
commit;
2)事物的回滚
start transaction;
张三转出200
update account set money = money - 200 where name = '张三';
此处发生了错误
select dajdiad
李四收入200 此时该操作不能执行
update account set money = money + 200 where name = '李四';
select *from account;
执行回滚,将数据回滚到开启事务时的状态,同时提交事物,此时不会对表数据进行影响。
rollback;
提交事务,此时将SQL提交,表中的数据才真正被改变
commit;
3)事物的回滚点
start transaction;
savepoint test1;
update account set money = money - 100 where name = '张三';
update account set money = money - 100 where name = '张三';
update account set money = money - 100 where name = '张三';
设置回滚点
savepoint test;
update account set money = money - 100 where name = '张三';
update account set money = money - 100 where name = '张三';
update account set money = money - 100 where name = '张三';
select *from account;
回滚到指定回滚点,不会自动提交事物。
rollback to test1;
commit;
存储过程:
将数据库的操作进行一个封装 要使用时,可直接调用使用,理解为函数的声明
存储过程的创建
格式:
create procedure 过程名(in 参数名 参数类型,out 参数名 参数类型) #in:表示形参 out:表示返回值
begin
sql语句
end;
(1)将查询表的操作声明到存储过程中.
create procedure query_table()
begin
select *from emp;
end;
存储过程的调用 call 过程名(参数列表)
call query_table();
(2)创建一个存储过程,通过传递id来查询用户
create procedure query_user(in user_id int)
begin
select *from emp where id = user_id;
end;
调用存储过程
call query_user(1);
call query_user(2);
(3)创建一个存储过程,返回通过id查询到的用户名
create procedure query_name(in user_id int,out user_name varchar(5))
begin
set user_name = (select name from emp where id = user_id);
end;
调用有返回值的存储过程,要给返回值传递一个变量用于接收值,例如@name
call query_name(1,@name);
查询变量name
select @name;
触发器:
概念:发器是指在表insert/update/delete之前或者之后,触发并执行触发器定义的SQL语句结合。
作用:可以协助应用在数据库端保证数据的完整性,日志记录,数据校验等操作。
触发器中的变量:
new:代表即将要新增的数据,或者即将要更新的数据。
old:表示修改之前的旧数据,或者将要删除的数据。
触发器的类型:
insert型触发器
update型触发器
delete型触发器
1)触发器的创建
语法:
create trigger 触发器的名称
(before/after)(insert/update/delete) #指定触发器在什么时候被触发
on 表名
[for each row]#表示为行级触发器
begin
触发器要操作的sql语句
end;
eg:
创建一个触发器,往订单表中添加一条订单数据之后,触发该触发器,执行更新水果表中水果的数据
create trigger order_trigger
after insert
on orders
for each row
begin
触发器执行的操作
update fruit
set f_count = f_count - new.count #new.count表示往订单表中新增的count数据
where f_name = new.name ;#new.name表示订单表中新增的数据
end;
查看触发器
show triggers;
下单10个香蕉
insert into orders values(null,'香蕉',10)
执行该语句时,同时执行了
update fruit
set f_count = f_count - 10 #new.count表示往订单表中新增的count数据
where f_name = 香蕉 ;#new.name表示订单表中新增的数据
表示一旦去更新了水果的数量,就将向日志表中插入一条水果的更新记录
create trigger fruit_update
after update
on fruit
for each row
begin
insert into fruit_log values(null,new.f_name,old.f_count,(old.f_count-new.f_count),new.f_count,now());
end;
update fruit set f_count = f_count + 1000 where f_name = '苹果';
update fruit set f_count = f_count + 11000 where f_name = '梨子';
update fruit set f_count = f_count - 100 where f_name = '香蕉';
update fruit set f_count = f_count - 1000 where f_name = '葡萄';
最后
以上就是直率绿茶最近收集整理的关于MySQL数据库部分 事务,触发器,存储过程的全部内容,更多相关MySQL数据库部分内容请搜索靠谱客的其他文章。








发表评论 取消回复