1.事务
1.1定义:一个具有明确开始、结束标记的,并且是有序的一段执行过程(例如:张三给李四转账)。
1.2作用:解决多个操作作为一个整体向系统提交时,要么执行、要么都不执行,事务是一个不可分割的工作逻辑单元。
1.3特性
- 原子性:事务执行的步骤是不可能或缺的。
- 一致性:事务执行的结果,这个变化在执行前和执行后是一致的。
- 隔离性:事务和事务之间是相互隔离,互不影响。
- 持久性:事务执行的结果,其效果是持久的。|
1.4概念
- 存盘点:savepoint 名称。
- 回滚:rollback恢复以前执行过的操作。比如:原来除了一行数据,现在就把恢复回来。发生在事务提交失败之后。
- 回滚到存盘点:rollback to 名称;主要针对某些执行时间较长的步骤。
- 提交:commit把事务执行的结果持久化(把数据写在硬盘上)。
1.5事务控制语句
1.5.1 begin或start transaction:显式地开启一个事务;
1.5.2 commit:也可以使用commit work,不过二者是等价的。commit会提交事务,并使已对数据库进行的所有修改称为永久性的;
1.5.3 rollback:也可以使用rollback work,不过二者是等价的。回滚会结束用户的事务,并搅撒销正在进行的所有未提交的修改;
1.5.4 savepoint identifier:savepoint允许在事务中创建一个保存点,一个事务中可以有多个savepoint;
1.5.5 release savepoint identifier:制除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
1.5.6 rollback to identifier:把事务回滚到标记点;
1.5.7 set transaction:用来设置事务的隔离级别。innodb存储引擎提供事务的隔离级别有read uncommitted、read committed、repeatable read和serializable。
2.视图
2.1概念:视图可以看作定义在MySQL上的虚拟表。视图正如其名字的含义一样,是另一种查看数据的入口。常规视图本身并不存储实际的数据,而仅仅存储一个select语句和所涉及表的MetaData。
2.2语法
2.2.1创建视图
create view 视图名 as select 字段名列表 from table;-- 创建视图
2.2.2删除视图
drop view 视图名;--删除视图2.2.3查询
select * from 视图名 [where子句];2.3视图的作用
- 数据保护,将敏感数据隐藏出来。
- 数据安全,对外使用视图,即使字段名泄露,也不影响到真实数据表。
- 提高查询小笼包,某些统计数据需要耗时比较久,九八统计好的数据生成一个视图提供给用户查询,避免每次查询进行统计。
3.索引
3.1概念:索引的本质就是通过特定的算法,将数据进行排序处理,进而能够更加快速地找到对应的数据。
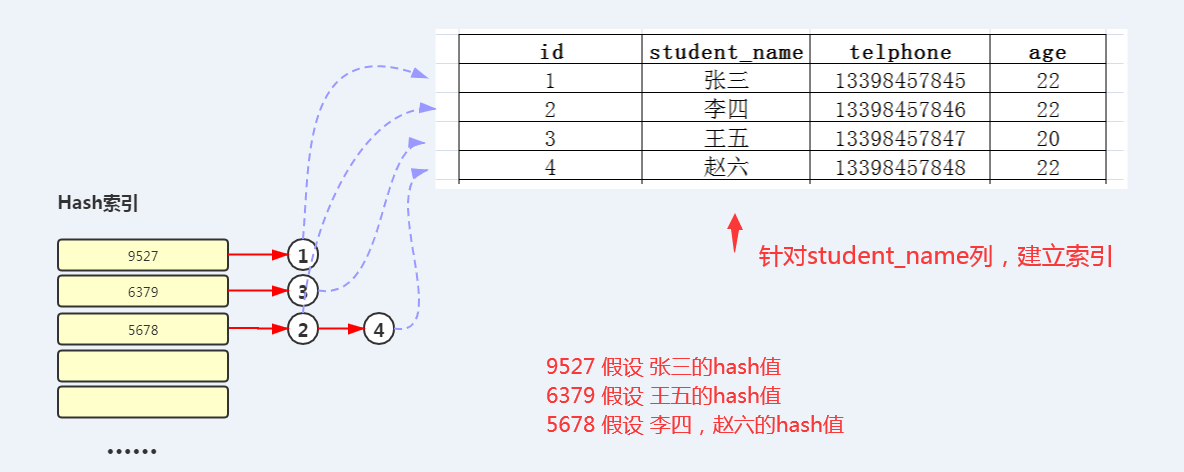
3.2Hash索引
MySQL中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B+Tree索引。hash索引把数据的索引以hash形式组织起来,因此当查找某一条记录的时候,速度非常快。当时因为是hash结构,每个键只对应一个值,而且是散列的方式分布。所以他并不支持范围查找和排序等功能。
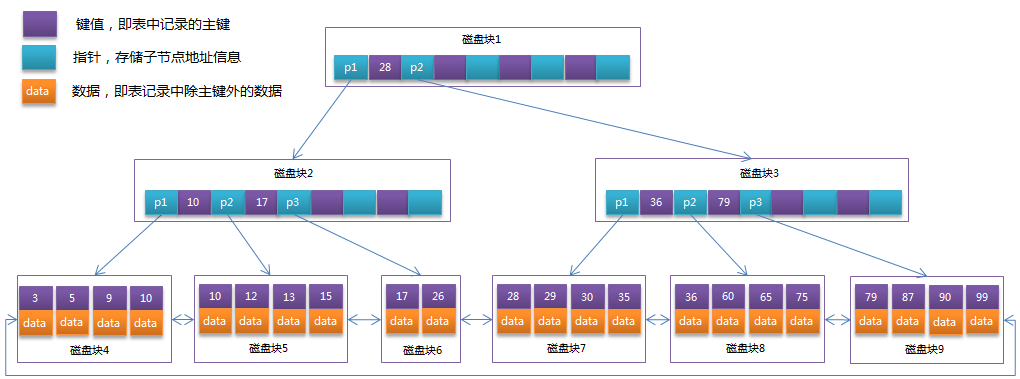
3.3B+Tree索引
B+tree从MySQL5.5之后,就是使用最频繁的一个索引数据结构,是InnoDB和MyISAM存储引擎模式的索引类型。相对Hash索引,B+树在查找单条记录的速度比不上Hash索引,但是因为更适合排序等操作,所以他更受用户的欢迎。毕竟不可能只对数据库进行单条记录的操作
3.4常见的索引类型
- primary key(主键索引) alter table table name add primary key ( col )
- unique(唯一索引) alter table table_name add unique ( col )
- index(普通索引) alter table table_name add index index_name ( col )
- fulltext(全文索引) alter table table_name add fulltext ( col )
- 组合索引 alter table table_name add index index_name ( col1 , col2 , col3 )
3.5执行计划explain

- id:选择标识符
- select_type:表示查询的类型
- table:输出结果集的表
- partitions:匹配的分区
- type:表示表的连接类型
- possible_keys:表示查询时,可能使用的索引;指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段 上若存在索引,则该索引将被列出,但不一定被查询使用(该查询 可以利用的索引,如果没有任何索引显示 null)。
- key:表示实际使用的索引;key列显示MySQL实际决定使用的键(索引),必然包含在 possible_keys中,如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
- key_len:索引字段的长度
- ref:列与索引的比较
- rows:扫描出的行数(估算的行数);估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数。
- filtered:按表条件过滤的行百分比
- Extra:执行情况的描述和说明

 4.触发器
4.触发器
4.1触发器的概念:是与表事件相关的特殊的存储过程
4.2机制:不是手工启动,由事件来触发。比如我们对数据表进行操作(insert、delete、update)时就会被激活
4.3创建触发器的语法
create trigger 触发器名 触发时机 触发事件 on 表 for each row
begin
语句块;
end- 触发器名:和存储过程的命名规范一样
- 触发时机:before,after
- 触发事件:insert、delete、update
- 构成六种触发器
- 特别关键字:new:代表新的数据记录;old:代表数据表中原来的数据记录。insert事件具有new记录;update具有new和old;delete具有old记录。newheold本质上是一行记录,一个实体,可以通过new.字段名来获取记录中对应字段的值。
最后
以上就是缥缈含羞草最近收集整理的关于事务、索引、触发器1.事务2.视图3.索引 4.触发器的全部内容,更多相关事务、索引、触发器1内容请搜索靠谱客的其他文章。








发表评论 取消回复