--视图
视图是一张虚拟表,它表示一张表的部分数据或多张表的综合数据,其结构和数据是建立在对表的查询基础上
视图在操作上和数据表没有什么区别,但两者的差异是其本质是不同: 数据表是实际存储记录的地方,然而视图并不保存任何记录。
相同的数据表,根据不同用户的不同需求,可以创建不同的视图(不同的查询语句)
视图的目的是方便查询,所以一般情况下不能对视图进行增删改
优点:
1:筛选表中的行降低数据库的复杂程度
2:防止未经许可的用户访问敏感数据
--视图并不存储数据,视图只是将sql语句封装了一下,所以最终执行的还是sql语句,表中的数据发生变化后
--结果也就发生变化,所以通过视图查询的结果自读也就发生了变化。
视图语法:
1 --创建视图 2 create view vw_ViewName 3 4 as 5 6 SQL语句 7 8 --更改视图 9 10 alter view vw_ViewName 11 12 as 13 14 SQL语句 15 16 --删除视图 17 18 drop view vw_ViewName
视图分类:
普通视图:并不存储数据(虚拟表),访问的是真实表中的数据
(*)索引视图:在视图上创建唯一聚集索引,数据会保存在数据库中而不是引用表中的数据。
使用视图注意事项:
1.视图中的查询不能使用order by ,除非指定了top语句。
2.视图被认为是一个虚拟表,表是一个集合,是不能有顺序的。而order by 则返回的是一个有顺序的,是一个游标。
3.在视图中使用select top percent + order by 问题。
4.所有查询的列,必须有列名,且列名必须唯一
5.create view vw_name as 后不能跟begin end.
--通过T-SQL进行编程
1:声明变量
C#: int n = 10;
SQL: declare @n int =10
2.给变量赋值
set @n=@n+1 --当使用set赋值的时候,如果"等号"右边范湖多个值,直接报错!!
select @n=@n+1 --当使用select为变量赋值的时候,如果查询语句返回多条记录,那么将最后一条记录赋值给@n变量
SELECT 以表格的方式输出,可以同时输出多个变量
PRINT 以文本的方式输出,一次只能输出一个变量的值
3.变量的种类
变量分为:
*局部变量:
局部变量必须以标记@作为前缀 ,如@Age int
局部变量:先声明,再赋值
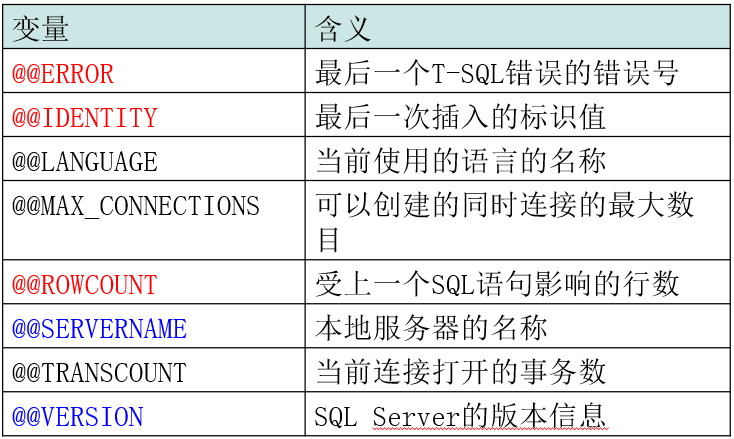
*全局变量(系统变量):
全局变量必须以标记@@作为前缀,如@@version
全局变量由系统定义和维护,我们只能读取,不能修改全局变量的值
凡是以两个@@开头的都叫做系统变量
--事务(Transaction) 参考:Transaction[事务] and Procedure[存储过程]
事务:同生共死
指访问并可能更新数据库中各种数据项的一个程序执行单元(unit)--也就是由多个sql语句组成,必须作为一个整体执行
这些sql语句作为一个整体一起向系统提交,要么都执行、要么都不执行
事务语法步骤:
开始事务:BEGIN TRANSACTION
事务提交:COMMIT TRANSACTION
事务回滚:ROLLBACK TRANSACTION
判断某条语句执行是否出错:
全局变量@@ERROR;
@@ERROR只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计;
例:SET @errorSum=@errorSum+@@error
事务的ACID特性:
事务是作为单个逻辑工作单元执行的一系列操作。一个逻辑工作单元必须有四个属性,称为原子性、一致性、隔离性和持久性 (ACID) 属性,只有这样才能成为一个事务。
1.原子性(Actomicity):事务是一个完整的操作,事务的各步操作是不可分的(原子的):要么执行,要么不执行
2.一致性(Consistency):当数据完成时,数据必须处于一至状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。
事务结束时,所有的内部数据结构(如 B 树索引或双向链表)都必须是正确的。
3.隔离(Isolation):对数据进行修改的所有并发事务时彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务。
由并发事务所作的修改必须与任何其他并发事务所作的修改隔离。事务识别数据时数据所处的状态,要么是另一并发事务修改它之前的状态,
要么是第二个事务修改它之后的状态,事务不会识别中间状态的数据。
这称为可串行性,因为它能够重新装载起始数据,并且重播一系列事务,以使数据结束时的状态与原始事务执行的状态相同。
4.持久性(Durability):事务完成之后,它对于系统的影响是永久性的。该修改即使出现系统故障也将一直保持。
SET IMPLICIT_TRANSACTIONS { ON | OFF }
如果设置为 ON,SET IMPLICIT_TRANSACTIONS 将连接设置为隐式事务模式。如果设置为 OFF,则使连接恢复为自动提交事务模式。
--事务分三种
1.显示事务
我们手动begin transaction ...... commit transaction/rollback transaction
上面这种写法叫做“显示事务”
2.隐式事务
SET IMPLICIT_TRANSACTIONS { ON | OFF }隐式事务
3.自动提交事务,SQL Server默认使用的是自动提交事务.
我们每次执行一条sql语句的时候,sql server都会自动帮我们打开一个事务
如果该sql语句执行不出错,则sql server自动提交该事务commit
如果该sql语句执行出错了,那么sql server则自动回滚该事务。rollback
--使用事务(银行转账Demo)
1 --1.开始事务 2 begin transaction 3 declare @error int 4 set @error = 0 5 update bank set balance=balance-1000 where cid='0001' 6 set @error = @error + @@error 7 update bank set balance=balance + 1000 where cid='0002' 8 set @error = @error + @@error 9 if @error != 0 10 begin 11 --2.回滚事务 12 rollback transaction 13 end 14 else 15 begin 16 --3.提交事务 17 commit transaction 18 end 19 go 20 --查询bank数据 21 select * from bank
分布式事务
1: 事务(Transaction)有一个特征是"原子性",也就是"要么全部成功,要么全部失败"。事务实现有很多方法,最常见的就是使用连接相关SqlTransaction,
但是无法实现分布式事务/嵌套事务,编写麻烦。
2: TransactionScope用来实现分布式事务
2.1: 需要首先在服务中开启MSDTC(Distributed Transaction Coordinator),调用ADO.NET的客户端,数据库服务器都需要开启。
2.2: 项目添加对System.Transactions的引用,操作完成后调用TransactionScope的Complete方法
3: TransactionScope可以实现嵌套式事务,也就是A调用B,B中声明了TransactionScope,A中也声明了TransactionScope,这样如果B没错,但是A中调完了B后出错了,则B中的数据库操作也回滚。
--存储过程 参考:Transaction[事务] and Procedure[存储过程]
存储过程---就像数据库中运行方法(函数)
和C#里的方法一样,由存储过程名/存储过程参数组成/可以有返回结果。
前面学的if else/while/变量/insert/select 等,都可以在存储过程中使用
优点:
1: 执行速度更快 – 在数据库中保存的存储过程语句都是编译过的
2: 允许模块化程序设计 – 类似方法的复用
3: 提高系统安全性 – 防止SQL注入
4: 减少网络流通量 – 只要传输 存储过程的名称
系统存储过程:由系统定义,存放在master数据库中,名称以“sp_”开头或”xp_”开头,自定义的存储过程可以以usp_开头。
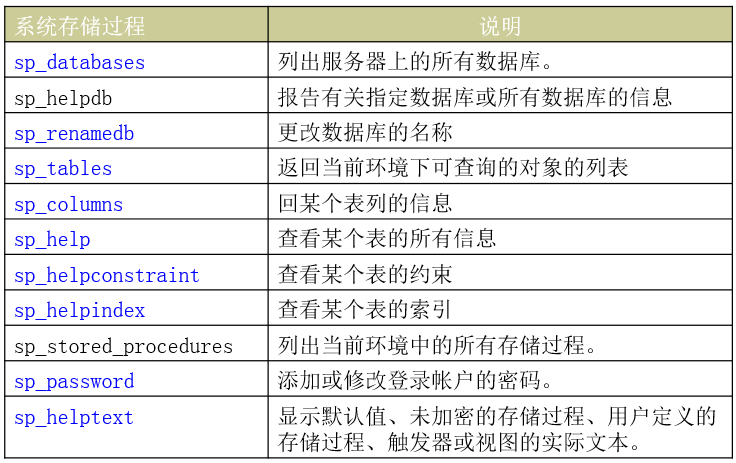
自定义存储过程:由用户在自己的数据库中创建的存储过程usp
存储过程语法:
1 --定义存储过程的语法 2 CREATE PROC[EDURE] 存储过程名 3 @参数1 数据类型 = 默认值 OUTPUT, 4 @参数n 数据类型 = 默认值 OUTPUT 5 AS 6 SQL语句 7 --参数说明: 8 --参数可选 9 --参数分为输入参数、输出参数 10 --输入参数允许有默认值 11 12 EXEC 过程名 [参数]
--ADO.NET调用存储过程和普通SQL区别
1:设置cmd.CommandType = CommandType.StoredProcedure
2: 输出参数:new SqlParameter("@state",SqlDbType.Bit){ Direction=ParameterDirection.Output}
3: 调用输出参数,必须等到ExecuteNonQuery/ExecuteScalar/ExecuteReader执行完毕之后,使用pms[3].Value 获取value
存储过程Demo:
1 --1:创建第一个简单的存储过程 2 CREATE PROC usp_helloworld 3 AS 4 BEGIN 5 PRINT 'hello world!' 6 END 7 8 EXEC usp_helloworld
1 --2:带参数的存储过程 2 CREATE PROC usp_showmsg 3 @msg nvarchar(300) ---多个参数使用,隔开。 4 AS 5 BEGIN 6 PRINT @msg 7 END 8 9 10 EXEC usp_showmsg N'XXX' 11 12 EXEC usp_showmsg @msg=N'11111111111'
1 --3:简单的加法存储过程 2 CREATE PROC usp_add 3 @n int, 4 @m int 5 AS 6 BEGIN 7 PRINT @n+@m 8 END 9 10 EXEC usp_add 100,200 11 12 --删除存储过程 13 DROP PROC usp_add
1 --4:带默认值的存储过程 2 ALTER PROC usp_add 3 @num1 int = 100, --为参数加默认值 4 @num2 int = 200 5 AS 6 BEGIN 7 PRINT @num1 + @num2 8 END
1 --5:部分带默认值的存储过程 2 ALTER PROC usp_add 3 @num1 int = 100, --为参数加默认值 4 @num2 int 5 AS 6 BEGIN 7 PRINT @num1 + @num2 8 END 9 10 exec usp_add @num2=50
1 --6:存储过程中的输出参数 2 SELECT * FROM TblStudent 3 4 ALTER PROC usp_selectByAge 5 @age int, 6 @count int OUTPUT -- 输出参数 7 AS 8 BEGIN 9 --1. 根据@age进行查询 10 SELECT * FROM TblStudent where tSAge>@age 11 12 --2.返回一共查询出了多少条数据 13 SET @count=(SELECT COUNT(*) FROM TblStudent where tsage>@age) 14 END 15 16 --执行带OutPut 参数的存储过程 17 DECLARE @c int 18 EXEC usp_selectByAge @age=20,@count=@c OUTPUT 19 PRINT @c
经典写法:转账使用存储过程来编写
1 --7:经典写法:转账使用存储过程来编写 2 --存储过程 3 CREATE PROC usp_transfer 4 @from char(4), 5 @to char(4), 6 @money money, 7 @state bit OUTPUT --1表示转账成功,0表示转账失败! 8 AS 9 BEGIN 10 DECLARE @balance money,@sum int=0 11 SET @state=0 12 --1.查询@from中的余额 13 SET @balance=(SELECT balance FROM bank WHERE bank.cId=@from) 14 --2.检查余额是否充足 15 IF @balance-@money>10 BEGIN 16 ----3.开始事务进行转账 17 --打开事务 18 BEGIN TRANSACTION 19 --1.减钱 20 UPDATE bank SET balance=bank.balance-@money where bank.cId=@from 21 SET @sum=@sum+@@error 22 --2.加钱 23 UPDATE bank SET balance=bank.balance+@money where bank.cId=@to 24 SET @sum=@sum+@@error 25 26 IF @sum=0 BEGIN 27 SET @state=1 --设置转账成功 28 COMMIT TRAN 29 END 30 ELSE 31 ROLLBACK TRAN 32 33 END 34 END 35 --调用存储过程 36 DECLARE @ok bit 37 EXEC usp_transfer @from='0002',@to='0001',@money=800,@state=@ok OUTPUT 38 SELECT @ok 39 40 SELECT * FROM bank
经典:分页存储过程
1 --8:经典:分页存储过程 2 SELECT * FROM Customers order by Customers.CustomerID asc 3 4 --创建存储过程 5 --参数: 6 --每页大小pagesize 7 --当先用户要查看第几页 8 --总页数 9 --总条数 10 CREATE PROC usp_get_customers_by_page 11 @pagesize int=5, --每页多少条 12 @pageindex int=1, --用户当前要看第几页 13 @recordcount int OUTPUT, --总记录条数,输出参数 14 @pagecont int OUTPUT --总页数,输出参数 15 AS 16 BEGIN 17 --1. 分页查询语句 18 SELECT 19 T.CustomerID, 20 T.CompanyName, 21 T.City, 22 T.[Address], 23 T.Phone 24 FROM (SELECT *,rn=ROW_NUMBER()OVER(ORDER by CustomerID ASC) FROM Customers) AS T 25 WHERE T.rn BETWEEN @pagesize*(@pageindex-1)+1 and @pagesize*@pageindex 26 27 --2.返回总条数 28 SET @recordcount=(SELECT COUNT(*) FROM Customers) 29 30 --3.计算总页数,并返回 31 SET @pagecont=CEILING(@recordcount*1.0/@pagesize); 32 END 33 34 --调用存储过程 35 DECLARE @pc int,@rc int 36 EXEC usp_get_customers_by_page 7,13,@rc OUTPUT,@pc OUTPUT 37 PRINT @pc 38 PRINT @rc
CRUD Procedure Demo
1 --9:增删改查:存储过程 2 --insert 3 CREATE PROC usp_insert_newperson 4 @name nvarchar(50), 5 @age int 6 AS 7 BEGIN 8 INSERT into NewPerson VALUES(@name,@age) 9 END 10 ------------------------------ 11 --delete 12 CREATE PROC usp_delete_newperson 13 @autoId int 14 AS 15 BEGIN 16 DELETE from NewPerson where NewPerson.autoId=@autoId 17 END 18 ------------------------------ 19 --update 20 CREATE PROC usp_update_newperson 21 @autoId int, 22 @name nvarchar(50), 23 @age int 24 AS 25 BEGIN 26 UPDATE NewPerson set uName=@name,age=@age WHERE NewPerson.autoId=@autoId 27 END 28 --------------------------------------- 29 --select 30 CREATE PROC usp_select_newperson 31 AS 32 BEGIN 33 SELECT * FROM NewPerson 34 END 35 ------------------------------------- 36 CREATE view vw_newperson 37 AS 38 SELECT * FROM NewPerson
--触发器
触发器的作用:自动化操作,减少了手动操作以及出错的几率。
触发器是一种特殊类型的存储过程,它不同于前面介绍过的一般的存储过程。【在SQL内部把触发器看做是存储过程但是不能传递参数】
一般的存储过程通过存储过程名称被直接调用,而触发器主要是通过事件进行触发而被执行。
触发器是一个功能强大的工具,在表中数据发生变化时自动强制执行。触发器可以用于SQL Server约束、默认值和规则的完整性检查,还可以完成难以用普通约束实现的复杂功能。
那究竟何为触发器?在SQL Server里面也就是对某一个表的一定的操作,触发某种条件,从而执行的一段程序。触发器是一个特殊的存储过程。
--inserted--deleted
(1)deleted表存放由于执行delete或update语句而要从表中删除的所有行。
在执行delete或update操作时,被删除的行从激活触发器的表中被移动(move)到deleted表,这两个表不会有共同的行。
(2)inserted表存放由于执行insert或update语句而要向表中插入的所有行。在执行insert或update事物时,新的行同时添加到激活触发器的表中和inserted表中,
inserted表的内容是激活触发器的表中新行的拷贝。
说明:update事务可以看作是先执行一个delete操作,再执行一个insert操作,旧的行首先被移动到deleted表,让后新行同时添加到激活触发器的表中和inserted表中。
不能对视图定义 AFTER 触发器。
--常见的触发器
DML触发器:Insert、delete、update(不支持select)
after触发器(for)、instead of触发器(不支持before触发器)(程序开发人员常用)
DDL触发器:Create table、create database、alter、drop…. (数据库管理人员常用)
After触发器:
在语句执行完毕之后触发
按语句触发,而不是所影响的行数,无论所影响为多少行,只触发一次。
只能建立在常规表上,不能建立在视图和临时表上。(*)
可以递归触发,最高可达32级。
update(列),在update语句触发时,判断某列是否被更新,返回布尔值。
instead of触发器:
用来替换原本的操作
不会递归触发
可以在约束被检查之前触发
可以建在表和视图上(*)
触发器语法:
1 CREATE TRIGGER triggerName ON 表名 2 after(for)(for与after都表示after触发器) 3 |instead of 4 UPDATE|INSERT|DELETE(insert,update,delete) 5 AS 6 begin 7 … 8 end
触发器Demo
1 --创建 触发器Trigger 2 CREATE TRIGGER tri_customers_after_delete ON Customers 3 AFTER DELETE 4 AS 5 BEGIN 6 INSERT INTO CustomersBak SELECT * FROM DELETED 7 END 8 9 --更新 触发器Trigger 10 ALTER TRIGGER tri_customers_after_delete ON Customers 11 AFTER DELETE 12 AS 13 BEGIN 14 INSERT INTO CustomersBak SELECT * FROM DELETED 15 END 16 17 --删除 触发器Trigger 18 Drop TRIGGER tri_customers_after_delete
触发器使用建议:
1.尽量避免在触发器中执行耗时操作,因为触发器会与SQL语句认为在同一个事务中。(事务不结束,就无法释放锁)
2.避免在触发器中做复杂操作,影响触发器性能的因素比较多(如:产品版本、所使用架构等等)
要想编写高效的触发器考虑因素比较多(编写触发器容易,编写复杂的高性能触发器难!)。
3.触发器编写时注意对多行触发时的处理。(一般不建议使用游标,性能问题!)
转载于:https://www.cnblogs.com/DrHao/p/5227931.html
最后
以上就是腼腆丝袜最近收集整理的关于MSSQL 视图/事务(TRAN[SACTION])/存储过程(PROC[EDURE])/触发器(TRIGGER )的全部内容,更多相关MSSQL内容请搜索靠谱客的其他文章。




![MSSQL 视图/事务(TRAN[SACTION])/存储过程(PROC[EDURE])/触发器(TRIGGER )](https://www.shuijiaxian.com/files_image/reation/bcimg10.png)



发表评论 取消回复