“手部检测”案例源码详解 (Python)
testhand.py用于检测手部,本案例可与testface对照阅读
- 打开testhand手部检测案例
- 预处理图像
- 在原图上绘制网格和可选的外接矩形
- 检测手部关键点:手腕、手指、手掌
- 指定模型路径和输入形状
- 设置相机并开始读图
- 启动模型,分支处理是否检测到手的情况
打开testhand手部检测案例
在VScode中进入代码编辑状态。
导入相关库
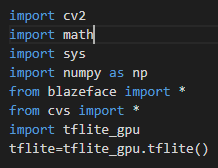
引用模块介绍
- math模块提供了许多对浮点数的数学运算函数。
- cv2模块是OpenCV 2.0的简写,在计算机视觉项目的开发中,OpenCV作为较大众的开源库,拥有了丰富的常用图
像处理函数库,采用C/C++语言编写,可以运行在Linux/Windows/Mac等操作系统上,能够快速的实现一些图像处理和识别的任务。 - remi是一个用于python应用程序的gui库,它将应用程序的接口转换成html并在web浏览器中呈现。这消除了特定于平台的依赖关系,使用户可以轻松地在python中开发跨平台应用程序
- sys模块包括了一组非常实用的服务,内含很多函数方法和变量,用来处理Python运行时配置以及资源,从而可以与前当程序之外的系统环境交互。
- NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。在机器学习算法中大部分都是调用Numpy库来完成基础数值计算的。
- blazeface:来自谷歌的研究人员通过改造mobileNet提出更为紧凑的轻量级特征提取方法、结合适用于移动端GPU高效运行的新型锚框机制,以及代替非极大值抑制的加权方法保证检测结果的稳定性,在移动端上实现了超高速的高性能人脸检测BlazeFace,最快不到一毫秒的检测速度为众多人脸相关的应用提供了更广阔的发展空间。
- cvs图形控件模块
- tflite_gpu,GPU加速代码由AID提供,TensorFlow Lite 支持多种硬件加速器。GPU 是设计用来完成高吞吐量的大规模并行工作的。因此,它们非常适合用在包含大量运算符的神经网络上,一些输入张量可以容易的被划分为更小的工作负载且可以同时执行,通常这会导致更低的延迟。在最佳情况下,用 GPU 在实时应用程序上做推理运算已经可以运行的足够快,而这在以前是不可能的。
预处理图像
#用于tflite32的图像预处理(图像,图像大小)
#返回图像
def preprocess_image_for_tflite32(image, model_image_size=300):
#cv2.cvtColor(p1,p2) 是颜色空间转换函数,p1是需要转换的图片,p2是转换成何种格式。
#cv2.COLOR_BGR2RGB 将BGR格式转换成RGB格式
#cv2.COLOR_BGR2GRAY 将BGR格式转换成灰度图片
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
#cv2.resize(src, dsize, dst=None, fx=None, fy=None, interpolation=None) —— 将原始图像调整为指定大小。
#src是原始图像,dsize输出图像的尺寸(元组方式),这里参数与模型图像保持一致。
image = cv2.resize(image, (model_image_size, model_image_size))
#np.expand_dims通过在指定位置插入新的轴来扩展数组形状,axis=0是最高维度
##设置axis为0,矩阵从二维矩阵变成了三维矩阵,新的维度长度为1
image = np.expand_dims(image, axis=0)
#使用这个函数将RGB值转化成零到一的值
image = (2.0 / 255.0) * image - 1.0
#此处转化类型至三十二位浮点
image = image.astype('float32')
return image
#图式识别方法(传递参数 图像、检测目标、是否描绘关键点==是)
#返回x、y分别的最大最小值(四个数)
def plot_detections(img, detections, with_keypoints=True):
#输出图像
output_img = img
#numpy 创建的数组都有一个shape属性,它是一个元组,返回各个维度的维数。有时候我们可能需要知道某一维的特定维数
#二维情况可以看到y是一个两行三列的二维数组,y.shape[0]代表行数,y.shape[1]代表列数。
#可以看到x是一个包含了3个两行三列的二维数组的三维数组,x.shape[0]代表包含二维数组的个数,x.shape[1]表示二维数组的行数,x.shape[2]表示二维数组的列数。
print(img.shape)
#初始化x、y坐标为
x_min=[0,0]
x_max=[0,0]
y_min=[0,0]
y_max=[0,0]
hand_nums=len(detections)
# if hand_nums >2:
# hand_nums=2
print("Found %d hands" % hand_nums)
#若检测到多余两只手,则只处理两只
if hand_nums >2:
hand_nums=2
for i in range(hand_nums):
ymin = detections[i][ 0] * img.shape[0]
xmin = detections[i][ 1] * img.shape[1]
ymax = detections[i][ 2] * img.shape[0]
xmax = detections[i][ 3] * img.shape[1]
w=int(xmax-xmin)
h=int(ymax-ymin)
h=max(h,w)
h=h*224./128.
# ymin-=0.08*h
# xmin-=0.25*w
# xmax=xmin+1.5*w;
# ymax=ymin+1.0*h;
x=(xmin+xmax)/2.
y=(ymin+ymax)/2.
xmin=x-h/2.
xmax=x+h/2.
ymin=y-h/2.-0.18*h
ymax=y+h/2.-0.18*h
# if w<h:
# xmin=xmin-(h+0.08*h-w)/2
# xmax=xmax+(h+0.08*h-w)/2
# ymin-=0.08*h
# # ymax-=0.08*h
# else :
# ymin=ymin-(w-h)/2
# ymax=ymax+(w-h)/2
# h=int(ymax-ymin)
# ymin-=0.08*h
# landmarks_xywh[:, 2:4] += (landmarks_xywh[:, 2:4] * pad_ratio).astype(np.int32) #adding some padding around detection for landmark detection step.
# landmarks_xywh[:, 1:2] -= (landmarks_xywh[:, 3:4]*0.08).astype(np.int32)
x_min[i]=int(xmin)
y_min[i]=int(ymin)
x_max[i]=int(xmax)
y_max[i]=int(ymax)
p1 = (int(xmin),int(ymin))
p2 = (int(xmax),int(ymax))
# print(p1,p2)
#画矩形()
cv2.rectangle(output_img, p1, p2, (0,255,255),2,1)
# cv2.putText(output_img, "Face found! ", (p1[0]+10, p2[1]-10),cv2.FONT_ITALIC, 1, (0, 255, 129), 2)
# if with_keypoints:
# for k in range(7):
# kp_x = int(detections[i, 4 + k*2 ] * img.shape[1])
# kp_y = int(detections[i, 4 + k*2 + 1] * img.shape[0])
# cv2.circle(output_img,(kp_x,kp_y),4,(0,255,255),4)
return x_min,y_min,x_max,y_max
#preprocess_img_pad,预处理图像外边缘,以免丢失边缘和角落的信息。
def preprocess_img_pad(img,image_size=128):
# fit the image into a 128x128 square
# img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
#img.shape 参数不写的话默认读入三通道图片,例如(640,640,3)
#这里相当于把元组(640,640,3)转换为一维数组[640,640,3]
shape = np.r_[img.shape]
#shape [640 480 3]
#uint32型为无符号32位整数,占4个字节,取值范围在0~4,294,967,295之间
#shape.max()最大值为640, shape[:2]的结果为[640,480],所以pad_all的值为[0,160]
pad_all = (shape.max() - shape[:2]).astype('uint32')
#执行除法并向下取整
#pad指图像边缘需要补的长度和宽度,pad的值为[0,80]
pad = pad_all // 2
# print ('pad_all',pad_all)
#pad(array, pad_width, mode, **kwargs)
#返回值:数组
#在卷积神经网络中,为了避免因为卷积运算导致输出图像缩小和图像边缘信息丢失,常常采用图像边缘填充技术,
# 即在图像四周边缘填充0,使得卷积运算后图像大小不会缩小,同时也不会丢失边缘和角落的信息。在Python的numpy库中,常常采用numpy.pad()进行填充操作
#在卷积神经网络中,通常采用constant填充方式
#‘constant’——表示连续填充相同的值,每个轴可以分别指定填充值,constant_values=(x, y)时前面用x填充,后面用y填充,缺省值填充0,
#img_pad_ori保存填充后的图,填充原始彩色图像外边缘
img_pad_ori = np.pad(
img,
((pad[0],pad_all[0]-pad[0]), (pad[1],pad_all[1]-pad[1]), (0,0)),
mode='constant')
#处理完变成黑白图片
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#img_pad填充黑白图外边缘
img_pad = np.pad(
img,
((pad[0],pad_all[0]-pad[0]), (pad[1],pad_all[1]-pad[1]), (0,0)),
mode='constant')
#src是原始图像,dsize输出图像的尺寸(元组方式),这里默认参数是128*128,和模型保持一致。,改变填充后的黑白图像的大小为128*128
img_small = cv2.resize(img_pad, (image_size, image_size))
#np.expand_dims:用于扩展数组的形状,np.expand_dims(a, axis=0)表示在0位置添加数据
#img_small.shape=(128,128,3),3是3通道
img_small = np.expand_dims(img_small, axis=0)
# img_small (1, 128, 128, 3)在0的位置添加数据,也就是最前面
# img_small = np.ascontiguousarray(img_small)
#把img_small 0——255的像素变到-1——1范围
img_small = (2.0 / 255.0) * img_small - 1.0
#将img_small转换为float32类型
img_small = img_small.astype('float32')
# img_norm = self._im_normalize(img_small)
#pad=[ 0 80]
#pad.shape=pad (2,)
#img_pad_ori是保存填充后的图
#img_small是保存填充缩放后的图并转换成float32格式
#pad指图像边缘需要补的长度和宽度
return img_pad_ori, img_small, pad
在原图上绘制网格和可选的外接矩形
#在原图上绘制网格(图像、网格、网格大小、线宽)
def draw_mesh(image, mesh, mark_size=4, line_width=1):
"""Draw the mesh on an image"""
# The mesh are normalized which means we need to convert it back to fit
# the image size.
image_size = image.shape[0]
mesh = mesh * image_size
for point in mesh:
cv2.circle(image, (point[0], point[1]),
mark_size, (255, 0, 0), 4)
# Draw the contours.
# Eyes
# left_eye_contour = np.array([mesh[33][0:2],
# mesh[7][0:2],
# mesh[163][0:2],
# mesh[144][0:2],
# mesh[145][0:2],
# mesh[153][0:2],
# mesh[154][0:2],
# mesh[155][0:2],
# mesh[133][0:2],
# mesh[173][0:2],
# mesh[157][0:2],
# mesh[158][0:2],
# mesh[159][0:2],
# mesh[160][0:2],
# mesh[161][0:2],
# mesh[246][0:2], ]).astype(np.int32)
# right_eye_contour = np.array([mesh[263][0:2],
# mesh[249][0:2],
# mesh[390][0:2],
# mesh[373][0:2],
# mesh[374][0:2],
# mesh[380][0:2],
# mesh[381][0:2],
# mesh[382][0:2],
# mesh[362][0:2],
# mesh[398][0:2],
# mesh[384][0:2],
# mesh[385][0:2],
# mesh[386][0:2],
# mesh[387][0:2],
# mesh[388][0:2],
# mesh[466][0:2]]).astype(np.int32)
# # Lips
# cv2.polylines(image, [left_eye_contour, right_eye_contour], False,
# (255, 255, 255), line_width, cv2.LINE_AA)
def calc_palm_moment(image, landmarks):
image_width, image_height = image.shape[1], image.shape[0]
palm_array = np.empty((0, 2), int)
for index, landmark in enumerate(landmarks):
landmark_x = min(int(landmark[0] * image_width), image_width - 1)
landmark_y = min(int(landmark[1] * image_height), image_height - 1)
landmark_point = [np.array((landmark_x, landmark_y))]
if index == 0: # 手首1
palm_array = np.append(palm_array, landmark_point, axis=0)
if index == 1: # 手首2
palm_array = np.append(palm_array, landmark_point, axis=0)
if index == 5: # 人差指:付け根
palm_array = np.append(palm_array, landmark_point, axis=0)
if index == 9: # 中指:付け根
palm_array = np.append(palm_array, landmark_point, axis=0)
if index == 13: # 薬指:付け根
palm_array = np.append(palm_array, landmark_point, axis=0)
if index == 17: # 小指:付け根
palm_array = np.append(palm_array, landmark_point, axis=0)
M = cv2.moments(palm_array)
cx, cy = 0, 0
if M['m00'] != 0:
cx = int(M['m10'] / M['m00'])
cy = int(M['m01'] / M['m00'])
return cx, cy
#计算外接矩形()
#返回一个shape为4的列表,表示结果的外接矩形
def calc_bounding_rect(image, landmarks):
image_width, image_height = image.shape[1], image.shape[0]
landmark_array = np.empty((0, 2), int)
for _, landmark in enumerate(landmarks):
landmark_x = min(int(landmark[0] * image_width), image_width - 1)
landmark_y = min(int(landmark[0] * image_height), image_height - 1)
landmark_point = [np.array((landmark_x, landmark_y))]
landmark_array = np.append(landmark_array, landmark_point, axis=0)
x, y, w, h = cv2.boundingRect(landmark_array)
return [x, y, x + w, y + h]
#画外接矩形(是否使用外接矩形,图像,外接矩形)
#输出绘制完毕后的图像
def draw_bounding_rect(use_brect, image, brect):
if use_brect:
# 画外接矩形
cv2.rectangle(image, (brect[0], brect[1]), (brect[2], brect[3]),
(0, 255, 0), 2)
return image
检测手部关键点:手腕、手指、手掌
def draw_landmarks(image, cx, cy, landmarks):
image_width, image_height = image.shape[1], image.shape[0]
landmark_point = []
# 关键点
for index, landmark in enumerate(landmarks):
# if landmark.visibility < 0 or landmark.presence < 0:
# continue
landmark_x = min(int(landmark[0] * image_width), image_width - 1)
landmark_y = min(int(landmark[1] * image_height), image_height - 1)
# landmark_z = landmark.z
landmark_point.append((landmark_x, landmark_y))
if index == 0: # 手腕
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 1: # 手腕
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 2: # 拇指:指根
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 3: # 拇指:第一指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 4: # 拇指:指尖
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
cv2.circle(image, (landmark_x, landmark_y), 12, (0, 255, 0), 2)
if index == 5: # 食指:指根
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 6: # 食指:第二指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 7: # 食指:第一指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 8: # 食指:指尖
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
cv2.circle(image, (landmark_x, landmark_y), 12, (0, 255, 0), 2)
if index == 9: # 中指:指根
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 10: # 中指:第二指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 11: # 中指:第一指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 12: # 中指:指尖
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
cv2.circle(image, (landmark_x, landmark_y), 12, (0, 255, 0), 2)
if index == 13: # 无名指:指根
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 14: # 无名指:第二指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 15: # 无名指:第一指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 16: # 无名指:指尖
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
cv2.circle(image, (landmark_x, landmark_y), 12, (0, 255, 0), 2)
if index == 17: # 小指:指根
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 18: # 小指:第二指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 19: # 小指:第一指关节
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
if index == 20: # 小指:指尖
cv2.circle(image, (landmark_x, landmark_y), 5, (0, 255, 0), 2)
cv2.circle(image, (landmark_x, landmark_y), 12, (0, 255, 0), 2)
# 接続線
if len(landmark_point) > 0:
# 拇指
cv2.line(image, landmark_point[2], landmark_point[3], (0, 255, 0), 2)
cv2.line(image, landmark_point[3], landmark_point[4], (0, 255, 0), 2)
# 食指
cv2.line(image, landmark_point[5], landmark_point[6], (0, 255, 0), 2)
cv2.line(image, landmark_point[6], landmark_point[7], (0, 255, 0), 2)
cv2.line(image, landmark_point[7], landmark_point[8], (0, 255, 0), 2)
# 中指
cv2.line(image, landmark_point[9], landmark_point[10], (0, 255, 0), 2)
cv2.line(image, landmark_point[10], landmark_point[11], (0, 255, 0), 2)
cv2.line(image, landmark_point[11], landmark_point[12], (0, 255, 0), 2)
# 无名指
cv2.line(image, landmark_point[13], landmark_point[14], (0, 255, 0), 2)
cv2.line(image, landmark_point[14], landmark_point[15], (0, 255, 0), 2)
cv2.line(image, landmark_point[15], landmark_point[16], (0, 255, 0), 2)
# 小指
cv2.line(image, landmark_point[17], landmark_point[18], (0, 255, 0), 2)
cv2.line(image, landmark_point[18], landmark_point[19], (0, 255, 0), 2)
cv2.line(image, landmark_point[19], landmark_point[20], (0, 255, 0), 2)
# 手掌
cv2.line(image, landmark_point[0], landmark_point[1], (0, 255, 0), 2)
cv2.line(image, landmark_point[1], landmark_point[2], (0, 255, 0), 2)
cv2.line(image, landmark_point[2], landmark_point[5], (0, 255, 0), 2)
cv2.line(image, landmark_point[5], landmark_point[9], (0, 255, 0), 2)
cv2.line(image, landmark_point[9], landmark_point[13], (0, 255, 0), 2)
cv2.line(image, landmark_point[13], landmark_point[17], (0, 255, 0), 2)
cv2.line(image, landmark_point[17], landmark_point[0], (0, 255, 0), 2)
# 重心 + 左右
if len(landmark_point) > 0:
# handedness.classification[0].index
# handedness.classification[0].score
cv2.circle(image, (cx, cy), 12, (0, 255, 0), 2)
# cv2.putText(image, handedness.classification[0].label[0],
# (cx - 6, cy + 6), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0),
# 2, cv2.LINE_AA) # label[0]:只取第一个字
return image
指定模型路径和输入形状
#图片的尺寸大小,深度学习不需要尺寸过大的图片,128*128就能满足需求
input_shape=[128,128]
#输入数据数量的单位是字节
#语义:rgb3通道 1个float是32位也就是4字节,每个数据4个字节
inShape =[1 * 128 * 128 *3*4,]
#4代表4个字节;896指896个框;896*16指明每个框的置信度;这16个数具体意指什么、顺序如何,只有看作者训练时曾怎样定义。若无法找到定义便只能猜测和尝试。
#outShape就是输出数据的数据量 单位是字节,896是值人脸关键点448*2;16代表鼻子,嘴巴,眼睛的x,y坐标点,8个点,每个点都有x,y,所以是16
#outShape输出图像
outShape= [1 * 896*16*4,1*896*1*4]
#人脸正面检测模型的路径,第一个模型是找8个点
model_path="face_detection_front.tflite"
print('gpu:',tflite.NNModel(model_path,inShape,outShape,4,1))
#人脸关键点网格模型的路径,第二个模型找448个点
model_path="face_landmark.tflite"
#tflite.NNModel(model_path,inShape,outShape,4,0) # 4表示4个cpu线程,0表示gpu,-1表示cpu,1表示GPU和CPU共同使用,2表示高通专有加速模式,1表示NNAPI 线程数我在aid上设置的4线程,
# 你可以灵活设置线程数和是否使用gpu+cpu模式;
#NNAPI (神经网络API)是 NDK中的一套API。由C语言实现。NNAPI设计的初衷是扮演底层平台的角色,
# 支撑上层的各种机器语言学习框架(TensorFlow List, Caffe2等)高效的完成推理计算,甚至是构建/训练模型。
# NNAPI有两个显著特点:
#1. 内置于Android系统,从Android8.1系统开始出现在NDK中。
#2. 能够利用硬件加速,使用Android设备的GPU/DSP或各种专门人工智能加速芯片完成神经网络的推理运算,大大提高计算效率。
#NNAPI会根据Android设备的硬件性能,适当的将这些繁重的计算部署到合适的计算单元(CPU & GPU &DSP &神经网络芯片). 从而使用硬件加速功能完成推理运算。
#切换到模型1
tflite.set_g_index(1)
#图片尺寸192*192,3通道,4个字节
inShape1 =[1 * 192 * 192 *3*4,]
#468*3
outShape1= [1 * 1404*4,1*4]
print('cpu:',tflite.NNModel(model_path,inShape1,outShape1,4,1))
设置相机,开始读图,并用不同的模型处理有无手的图像
#图片的尺寸大小,深度学习不需要尺寸过大的图片,128*128就能满足需求
input_shape=[128,128]
#输入数据数量的单位是字节
#语义:rgb3通道 1个float是32位也就是4字节,每个数据4个字节
inShape =[1 * 128 * 128 *3*4,]
#4代表4个字节;896指896个框;896*18指明每个框的置信度;这18个数具体意指什么、顺序如何,只有看作者训练时曾怎样定义。若无法找到定义便只能猜测和尝试。
#outShape就是输出数据的数据量,单位是字节。896是手部关键点448*2;18代表landmark_point中的关键点手腕、手指、手掌等9个点,每个点都有x,y坐标,所以是18。
#outShape输出图像
outShape= [1 * 896*18*4,1*896*1*4]
#手部检测模型的路径,第一个模型,找9个点
model_path="models/palm_detection.tflite"
print('gpu:',tflite.NNModel(model_path,inShape,outShape,4,0))
#手部关键点网格模型的路径,第二个模型,找448个点
model_path="models/hand_landmark.tflite"
tflite.set_g_index(1)
inShape1 =[1 * 224 * 224 *3*4,]
outShape1= [1 * 63*4,1*4,1*4]
print('cpu:',tflite.NNModel(model_path,inShape1,outShape1,4,0))
anchors = np.load('models/anchors.npy').astype(np.float32)
camid=1
cap=cvs.VideoCapture(camid)
启动模型,并分支处理是否检测到手的情况
#初始化bHand为false, 即置手部检测标志为否
bHand=False
x_min=[0,0]
x_max=[0,0]
y_min=[0,0]
y_max=[0,0]
fface=0.0
#use_brect变量作为是否使用外接矩形的标志,初始化为真
use_brect=True
#量化过的模型,用高通模式更快,例如小车,为量化的模型用1gpu快,高通对浮点型的支持要弱些,google对浮点型的支持要好些
#1gpu加速是google的模型 2是高通的模型
#cvs.VideoCapture(1)是调用手机前置摄像头,如果是cvs.VideoCapture(0)就是调用手机后置摄像头。
while True:
#读取摄像头的图片
frame=cvs.read()
#一直尝试读取,直到读取到摄像头的图像为止
if frame is None:
continue
#flip()的作用是使图像进行翻转,cv2.flip(filename, flipcode)
#filename:需要操作的图像,flipcode:翻转方式,1水平翻转,0垂直翻转,-1水平垂直翻转
#如果是前置摄像头,需要翻转图片,想象照镜子的原理
if camid==1:
# frame=cv2.resize(frame,(240,480))
frame=cv2.flip(frame,1)
#记录invoke启动的时间
start_time = time.time()
#这里对读取到的帧进行图像预处理,转为128的大小
img = preprocess_image_for_tflite32(frame,128)
# interpreter.set_tensor(input_details[0]['index'], img[np.newaxis,:,:,:])
#分支处理——若未检测到手
if bHand==False:
#通过指定索引,进行模型切换,这个模型用于尚未检测到手的情况
tflite.set_g_index(0)
#由于fp16的值区间比fp32的值区间小很多,所以在计算过程中很容易出现上溢出(Overflow,>65504 )和下溢出(Underflow,<6x10^-8 )的错误,溢出之后就会出现“Nan”的问题
#分配内存并传入数据
tflite.setTensor_Fp32(img,input_shape[1],input_shape[1])
#启动模型
tflite.invoke()
# t = (time.time() - start_time)
# # print('elapsed_ms invoke:',t*1000)
# lbs = 'Fps: '+ str(int(1/t))+" ~~ Time:"+str(t*1000) +"ms"
# cvs.setLbs(lbs)
#outshape里把输出列出来了 指的是输出的序号
#一个是框的位置
#raw_boxes: 14336
#这个算法简单叙述如下:预先在图上选很多区域,检测这些区域是否有手
#输出可以看作是一堆数据 通过outshape把输出分成了2部分
#0和1就是指取第一部分和第二部分
raw_boxes = tflite.getTensor_Fp32(0)
classificators = tflite.getTensor_Fp32(1)
detections = blazeface(raw_boxes, classificators, anchors)
x_min,y_min,x_max,y_max=plot_detections(frame, detections[0])
if len(detections[0])>0 :
bHand=True
#分支处理——若检测到手
if bHand:
hand_nums=len(detections[0])
if hand_nums>2:
hand_nums=2
for i in range(hand_nums):
print(x_min,y_min,x_max,y_max)
xmin=max(0,x_min[i])
ymin=max(0,y_min[i])
xmax=min(frame.shape[1],x_max[i])
ymax=min(frame.shape[0],y_max[i])
roi_ori=frame[ymin:ymax, xmin:xmax]
# cvs.imshow(roi)
roi =preprocess_image_for_tflite32(roi_ori,224)
tflite.set_g_index(1)
tflite.setTensor_Fp32(roi,224,224)
# start_time = time.time()
tflite.invoke()
mesh = tflite.getTensor_Fp32(0)
# ffacetmp = tflite.getTensor_Fp32(1)[0]
# print('fface:',abs(fface-ffacetmp))
# if abs(fface - ffacetmp) > 0.5:
bHand=False
# fface=ffacetmp
# print('mesh:',mesh.shape)
mesh = mesh.reshape(21, 3)/224
cx, cy = calc_palm_moment(roi_ori, mesh)
draw_landmarks(roi_ori,cx,cy,mesh)
# brect = calc_bounding_rect(roi_ori, mesh)
# draw_bounding_rect(use_brect, roi_ori, brect)
# draw_mesh(roi_ori,mesh)
frame[ymin:ymax, xmin:xmax]=roi_ori
t = (time.time() - start_time)
# print('elapsed_ms invoke:',t*1000)
lbs = 'Fps: '+ str(int(100/t)/100.)+" ~~ Time:"+str(t*1000) +"ms"
cvs.setLbs(lbs)
cvs.imshow(frame)
sleep(1)
import apkneed
最后
以上就是任性蛋挞最近收集整理的关于AidLux“手部检测”案例源码详解 (Python) “手部检测”案例源码详解 (Python) 的全部内容,更多相关AidLux“手部检测”案例源码详解内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复