A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing
论文原文
1. 提出了一个大规模的多模态的人脸防伪数据集 CASIA-SURF
It consists of 1, 000 subjects with 21, 000 videos and each sample has 3 modalities (i.e., RGB, Depth and IR)
Acquisition details
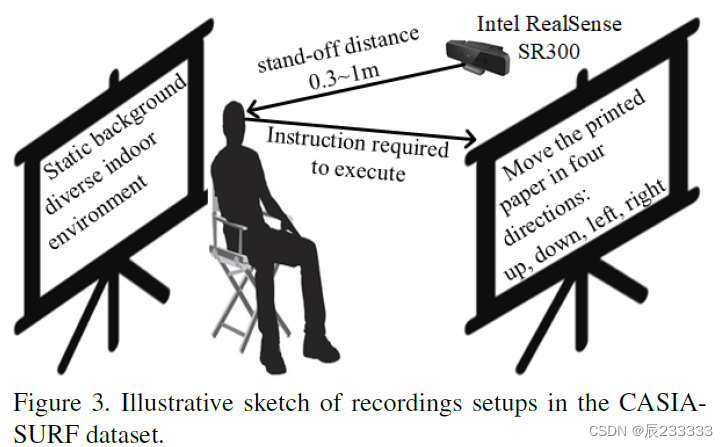
Data preprocessing
Each sample includes 1 live video clip, and 6 fake video clips under different attack ways (one attack way per fake video clip). In the different attack styles, the printed flat or curved face images will be cut eyes, nose, mouth areas, or their combinations.Finally, 6 attacks are generated in the CASIA-SURF dataset.

2. 提出了一种新的多模态融合方法
将人脸防伪视为一个二分类问题,以resnet-18为例进行实验
halfway fusion是常用的融合方法之一,它在第三卷积块(res3)之后,通过特征图级联,融合不同模态的子网络。然而,直接连接这些特征不能充分利用不同模态的特征。论文提出了squeeze and excitation fusion method,该方法使用“Squeeze-and-Excitation” branch,通过显式建模卷积通道之间的相互依赖性,增强不同模态特征的表示能力。
该模块为每个模态新增一个分支,该分支由一个全局平均池层和两个连续的全连接层组成。The squeeze and excitation fusion module执行模态相关特征重加权,以选择信息量更大的信道特征,同时抑制每个模态的不太有用的特征。将这些重加权的特征连接起来,以确定融合的多模态特征集。
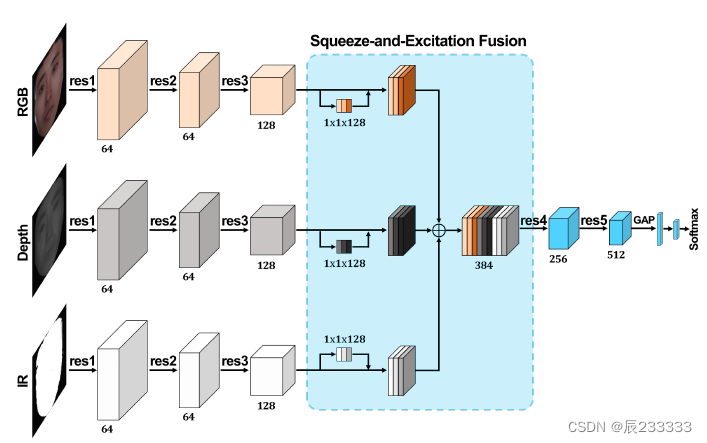
最后
以上就是愤怒抽屉最近收集整理的关于A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing(CVPR2019)A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing的全部内容,更多相关A内容请搜索靠谱客的其他文章。








发表评论 取消回复