OGB数据集
之前一直在几个玩具数据集上跑模型,发现了很多问题。看了OGB论文里的一些描述,我也深有体会,感觉很多东西都说到我心里去了。预计再发展几年吧,OGB也能像ImageNet那样,成为图表示学习领域中的一个统一的标准。
Hu W, Fey M, Zitnik M, et al. Open graph benchmark: Datasets for machine learning on graphs[J]. arXiv preprint arXiv:2005.00687, 2020.
数据集是模型的根基,而OGB数据集我认为又是相当重要的,所以必须要好好整理整理笔记。结合毕设,一直在做引文网络相关的节点分类任务,所以看的时候也有一些自己的侧重点,主要看了1、2、3、4、7这几部分。
文章目录
- OGB数据集
- Abstract
- 1 Introduction
- 现有的数据集的问题
- 当前OGB数据集的工作
- 2 Shortcomings of Current Benchmarks
- 引文网络小数据集的问题
- 一些大一些的数据集的问题
- 3 OGB: Overview
- 4 OGB Node Property Prediction
- 4.1 ogbn-products: Amazon Products Co-purchasing Network
- 4.3 ogbn-arxiv: Paper Citation Network
- 4.4 ogbn-papers100M: Paper Citation Network
- 7 OGB Package
- 7.1 OGB Data Loaders
- 7.2 OGB Evaluators
- 总结
Abstract
简要介绍了OGB数据集。我觉得最主要的还是两点:
- 推出了OGB数据集 + 特定且现实的数据集划分方式。
- 提供了一套基于PyG/DGL的标准化OGB数据集训练和评估流程(以及相关代码库)。
第一点给现有的模型带来了挑战;第二点为数据集的使用提供了便利。正因如此,OGB数据集才能够得到更多研究者的青睐。
1 Introduction
引言部分其实把作者想说的都说了,后面的部分都是进行细化和展开论述的。这部分虽然比较烦杂,但是只要紧紧抓住「问题+解决」这个思路,就能够比较清楚地发现作者到底在表达什么。
现有的数据集的问题
现有的数据集最大的特点就是「小」。因为规模比较小,它和现实世界中web规模的图相差甚远,这对数据驱动的模型的研究以及解决实际问题来说都是不利的。
- 模型区分度低。这就导致大部分GNN模型在这些玩具数据集上的统计结果都差不多,只能区分出好的模型和差的模型,无法真正区分出「一般好的模型」和「更好的模型」。
- 模型可扩展性差。因为一直在针对小数据集研究,不使用采样手段或minibatch都可以又好又快的进行训练,这就会导致这些模型无法扩展到大型图上面,比如之前发生的GPU内存溢出。目前也就是以GraphSAGE、GraphSAINT为代表的的模型在关注可扩展性,其他的基本上还都是出于full-batch的阶段。
- 没有统一的实验标准。这是相当可怕的,因为「数据集的划分方式」、「评估和验证标准」不同,我们根本无法公平的去评判模型的好坏。好坏都分不清楚,还怎么去进行下一步的工作啊。我之前做实验的时候,发现很多模型paper里面都采用了不同的数据集划分方式。。想强行统一划分,又会发现某些模型在此种划分方式下,acc不升反降。。
总之,在做了一些实验之后,我自己是有点苦不堪言。归根结底,还是之前的数据集太垃圾了。
当前OGB数据集的工作
和之前的数据集相比,最大的特点当然就是「大」。当然,除此之外,还有一些其他的考虑和改进。
- 大规模。比之前的几个玩具数据集大了几个数量级,之前是用ogbn-products进行了实验,下载下来直接1.xGB。小型数据集适用于计算密集型模型,不怎么吃GPU内存,一般full-batch就可以跑;中型、大型数据集用于可扩展的模型,为防止内存溢出,必须使用minibatch或分布式算法来跑。
- 多领域。不同领域的数据集可以检验模型的通用性。此外,不同的领域,根据现实情况进行特定的数据集划分也是一大看点,这要比随机划分更有意义。
- 多任务。针对节点级、边级、图级任务都有相应的数据集,我主要关注的是节点级任务ogbn-数据集。
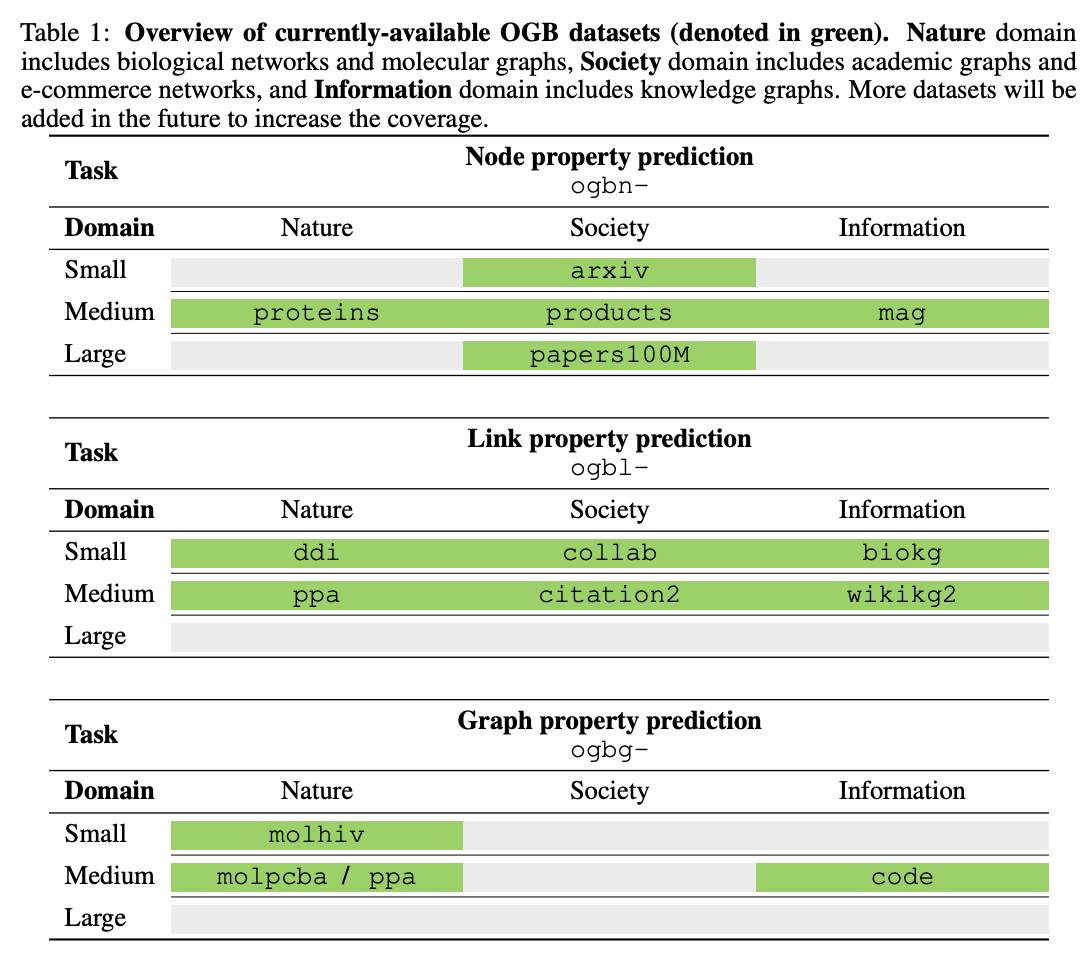
新的数据集给图表示学习领域带来了新的挑战。
- 可扩展性。如何设计应用于大型图的可扩展的模型。
- 表达能力。在更真实的数据划分下,如何提高测试集上的表现、减小泛化差距。
最后,OGB提供了一套标准化流程,这个对于实验来说很重要。通俗来说,我们按照这个流程,照猫画虎/照葫芦画瓢,实验也能够很快的跑起来了。

主要是前4个步骤,最后一个是鼓励大神们开源代码的,里面有很多参考代码,不过之前如果已经有PyG基础了,基本上直接看官方示例就ok了。流程很简单,大致是这样的:首先选择一个数据集,然后调包侠载入数据集并返回一个PyG或DGL的dataset对象,之后作为model的输入进行训练。训练完成之后,用数据集专属测试器进行测试和验证,得到acc等表现结果。
2 Shortcomings of Current Benchmarks
针对不同级别的任务,分别分析了这些数据集的缺点和现状,我这里只关注了节点级任务。
引文网络小数据集的问题
之前一直用的引文网络数据集:Cora、Citeseer、Pubmed,真的是一言难尽。这几个数据集的规模都很小,并且它的标准划分的训练集是每个类别随机抽取20个节点(默认),这样训练集一共就百八十个节点,这还训练啥啊。。
- 首先还是模型的区分度,用Cora一跑,大部分模型都是80%左右的准确率,根本分不出好坏。
- 然后就是数据集的划分,直接每个类别拿出20个节点是有点草率了,并且我仔细研究了一下是怎么弄得。以Cora为例,索引前140是训练集,再往后取500个是验证集,索引后1000是测试集。。确实有点草率,这和随机划分又有什么区别呢!并且,不同的模型会有不同的划分,为了能让结果好看一点,有的按照标准准划分,有的拼命去增加训练节点数。。
- 最后是数据集本身的质量堪忧,我之前就在实验中发现Citeseer数据集居然有15个孤立的啥信息也没有的节点。。此外,这几个数据集还存在节点重复等数据质量问题。
一些大一些的数据集的问题
其实很多人早就发现之前的引文网络数据集不太行了。所以后面又出现了大一些的数据集:PPI、Reddit、Amazon2M。
- 首先还是数据集的划分。按照这几个数据集给出的划分,很快啊,一些模型就在这些数据集上面取得了特别好的表现(F1分数超过90甚至95),导致了性能上的饱和,后面再研究已经没多少意义了。
- 然后是数据集的规模问题。虽然已经比引文网络大不少了,但是和真实世界中web规模的图相比,还是小了不少,所以依然可以算作是玩具数据集。
综上,因为数据规模、数据集划分等原因,现有的数据集并不适合作为benchmark dataset。
3 OGB: Overview
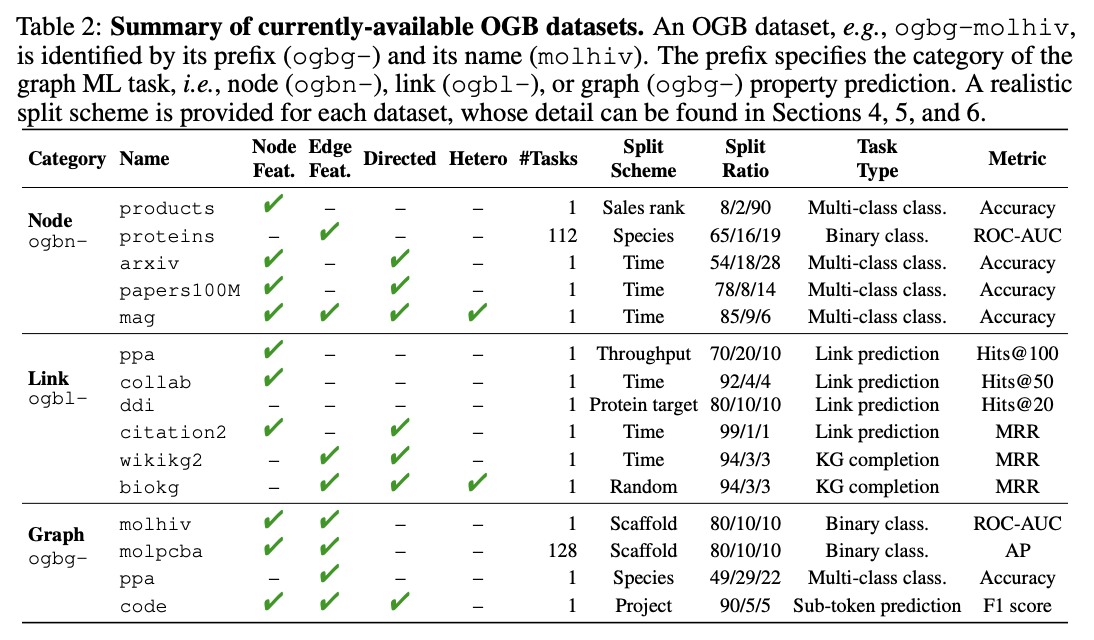
可用的数据集信息,包括数据集划分依据和比例、任务类型、包含的属性信息等等。
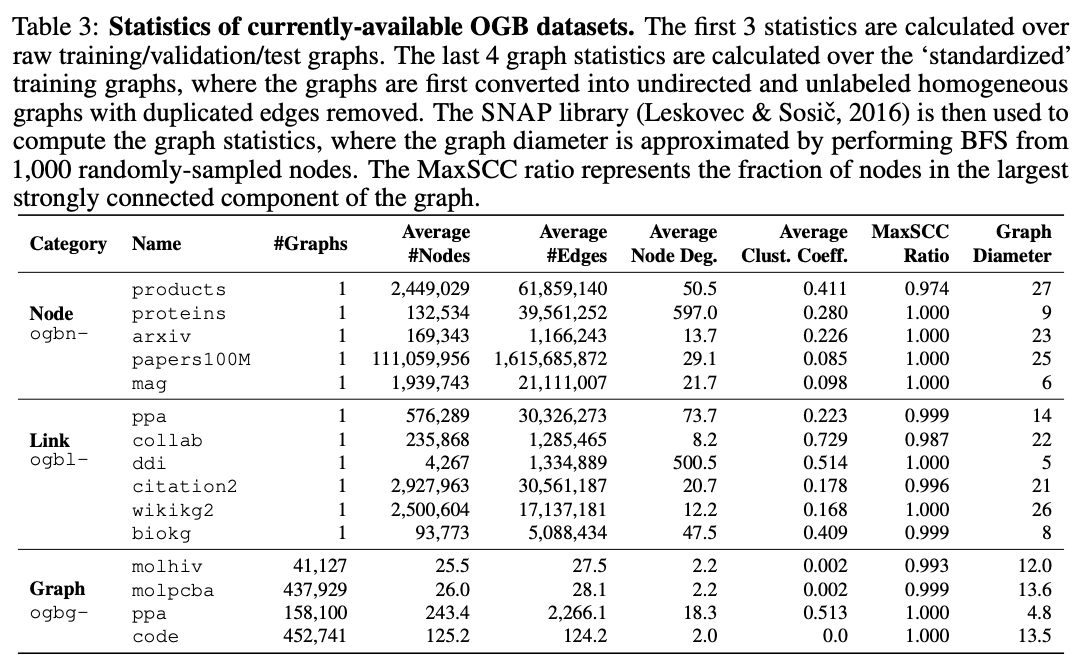
可用数据集的图统计信息,包括图的个数、节点数、边数、节点的平均度、聚类系数、图直径等等。
文档和项目地址汇总:
- OGB官网:https://ogb.stanford.edu/
- github项目地址:https://github.com/snap-stanford/ogb
- baseline实验代码地址:https://github.com/snap-stanford/ogb/tree/master/examples
ogbn-是节点级任务的数据集,后面会主要关注这一类。
此外,文章中还提到了另一个数据集TUDataset:https://chrsmrrs.github.io/datasets/。
4 OGB Node Property Prediction
这一部分是对ogbn-这一类数据集的详细介绍。
ogbn-主要包含了5个数据集。但是由于ogbn-proteins没有节点特征X(并且是2分类问题),ogbn-mag是异构图(含有多种类型的节点和边),这2个数据集并不在我的考虑范围之内。而剩下的3个正好也是Society这一类的小型(ogbn-arxiv)、中型(ogbn-products)、大型(ogbn-papers100M)数据集,其中ogbn-arxiv和ogbn-papers100M是引文网络(Citation Network)。
进一步,在实验中,由于GPU显存和算力的限制,大型数据集ogbn-papers100M暂时还跑不了,所以实验主要用了ogbn-arxiv和ogbn-products这两个数据集。
官方使用「baseline」对OGB数据集进行了实验。这几个baseline比较有代表性,这里需要提一下。
- MLP。没有用到图的结构信息。
- node2vec。用(X ⊕ oplus ⊕node2vec嵌入)作为特征向量来进行训练。
- GCN。full-batch算法。
- GraphSAGE。full-batch算法+skip-connection。
- NeighborSampling。GraphSAGE模型的minibatch算法。sample操作为采样邻居节点。
- ClusterGCN。minibatch算法。sample操作为采样固定节点数量的子图。
- GraphSAINT。minibatch算法。sample操作为随机游走采样。
可以发现,GNN模型主要分为2种——full-batch和minibatch。full-batch可以跑一些小型数据集(11GB显存能放下),但是中型和大型数据集就必须使用minibatch(划分+采样–>子图)了,否则GPU显存装不下。model的隐藏层维数为256,使用2-3层图卷积层,dropout为0.5。
4.1 ogbn-products: Amazon Products Co-purchasing Network
ogbn-products是一个无向无权图,它来自亚马逊商品的联合采购网络,是中型数据集。节点代表商品,边代表联合采购。节点特征X为商品描述的降维词袋向量。
主要是预测商品的类别,这是一个47分类问题。
数据集按照「销售排名」进行划分。排名前8%的用来train,再往后2%是valid,剩下的用来test(8/2/90),这样划分更贴近真实世界。
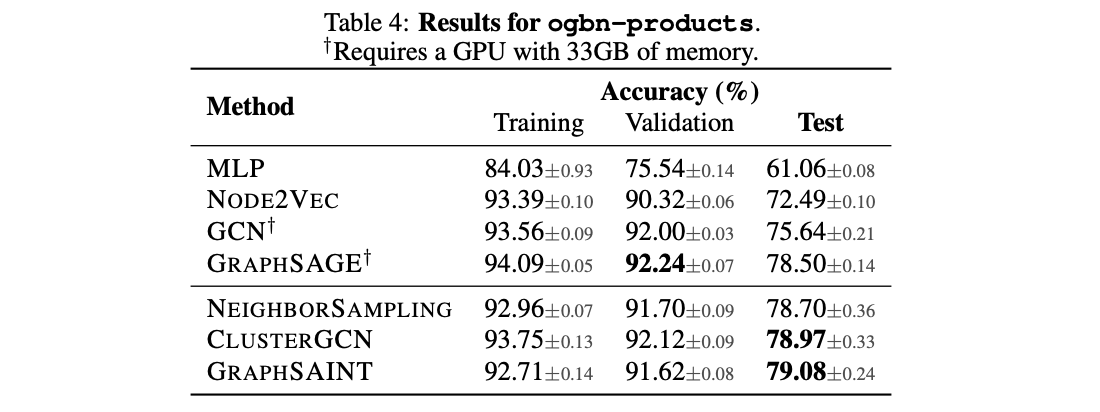
注意,full-batch需要至少33GB的GPU显存!
从实验结果中可以看出,train和test之前的泛化差异还是很大的,从9x直接到7x了。这个其实是因为数据集划分导致的。这种现实的划分方式和之前的随机划分不同,现实划分会导致不同的节点分布,对模型来说更有挑战性。
minibatch的效果要比full-batch好,这可能是因为minibatch在采样的过程中其实是在进行正则化的操作——噪声和丢弃边。如何进行sample才能得到最好的正则化效果?以及对于需要大感知域的模型应该如何去sample?这些都是需要去研究的问题。
4.3 ogbn-arxiv: Paper Citation Network
ogbn-arxiv是一个有向的引文网络,是MAG的一个子集,也是一个小型数据集。节点代表论文,边代表引用关系。节点特征是一个128维的向量,由单词嵌入表示的平均值组成,每个单词的embedding使用word2vec模型生成。
主要是预测论文的类别,是一个40分类问题。
数据集是根据「发表日期」进行划分的。2017年以及之前的用来train,2018年用来valid,2019用来test(54/18/28)。这也是一种比较现实的划分方式。
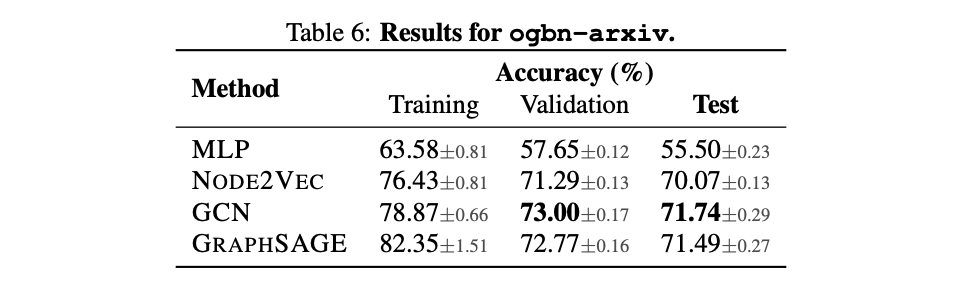
实验中,一般把有向的引文网络处理成无向图。和MLP相比有很大的提升,说明图结构信息是有用的。这种现实的数据集划分方式更具有挑战性,我们也可以去想想如何去利用边的方向信息和节点的时间信息。
4.4 ogbn-papers100M: Paper Citation Network
ogbn-papers100M是一个大型的引文网络数据集,有1.11亿个节点(包括150万个arxiv论文节点),它比现有的OGB数据集还要大几个数量级!
主要是来预测arxiv论文的类别,是一个172分类问题。
数据集是根据「发表日期」进行划分的。对于Arxiv论文的节点,2017年以及之前的用来train,2018年用来valid,2019用来test(78/8/14)。

在实验中,由于这个数据集过于庞大,大多数GNN模型都跑不了。baseline只跑了MLP和SGC(简化版的GCN),并且SGC需要100GB的显存来存储节点嵌入表示。。
此外,准确率也不高,说明SGC严重的欠拟合,我们需要去想办法将更先进的GNN模型扩展到Web规模的图上面,以提高表达能力。
7 OGB Package
这一部分是关于OGB代码库及其使用方法的介绍,我觉得有必要单独出一期来实践一下,这里就先简单提一下吧。
实验当中,一定要把握住之前的标准化流程,包括数据加载、模型评估等等。OBG是支持PyG和DGL的,所以调包侠们可以很轻松的一行代码就得到dataset对象。
7.1 OGB Data Loaders
主要是负责数据集的下载、处理(包括数据集的划分)、存储以及返回dataset对象,一条龙服务,不需要自己手工处理。在处理当中会进行数据集的标准划分,一般来说也不用特意去管他,默认就好。之后就可以按照PyG的套路去训练模型了。
7.2 OGB Evaluators
在训练结束之后,我们不需要手工计算准确率之类的,只需要调用具体数据集所适配的evaluatior,传入固定格式的参数(一般是传入一个字典dict,y_true和y_pred的信息),就可以得到模型的表达能力了,也是十分方便。
总结
关于OGB数据集的介绍就到这了。
今天是大年三十,提前祝大家新年快乐!
最后
以上就是真实故事最近收集整理的关于OGB数据集《Open Graph Benchmark: Datasets for Machine Learning on Graphs》OGB数据集的全部内容,更多相关OGB数据集《Open内容请搜索靠谱客的其他文章。








发表评论 取消回复