题目要求
(一)题目要求
以下是一个西瓜的数据,其中x1是密度,x2是含糖率,y标签:1好瓜,0坏瓜
x1=[0.697,0.774,0.634,0.608,0.556,0.403,0.481,0.437,0.666,0.243,0.245,0.343,0.639,0.657,0.360,0.593,0.719]
x2=[0.460,0.376,0.264,0.318,0.215,0.237,0.149,0.211,0.091,0.267,0.057,0.099,0.161,0.198,0.370,0.042,0.103]
y=[1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0]
具体要求如下:
需要随机将数据集分割成训练集和测试集,在x1-x2坐标系用散点图区分好瓜和坏瓜,任意选用一种分类模型,用训练集进行训练,然后对测试集预测,并计算预测准确率。
1.实现数据集的读取(2分)
2.导入库函数及数据,将数据集按一定比例分割成训练集和测试集。(3分)
3.用散点图可视化显示好瓜和坏瓜(5分)
4.建立适当模型(5分)
5.用训练集进行训练,然后对测试集预测 (2分)
计算预测准确率及输出(3分)
题目分析
本题重点是对数据的处理,将题目中的x1和x2进行拼接,然后进行特征缩放,特征缩放是必要的部分,因为我在对数据观察的时候,看到数量级其实差别不大,所以开始做的时候并没有进行特征缩放,但后续导致的结果就是无论更换什么样的模型,拟合程度都很低,浪费了很多时间。
接下来就是模型的选择,这种开放型题型,更注重我们对数据分布的观察,先画出数据分布以后,发现这个数据集并不能用一条直线分开。如图:
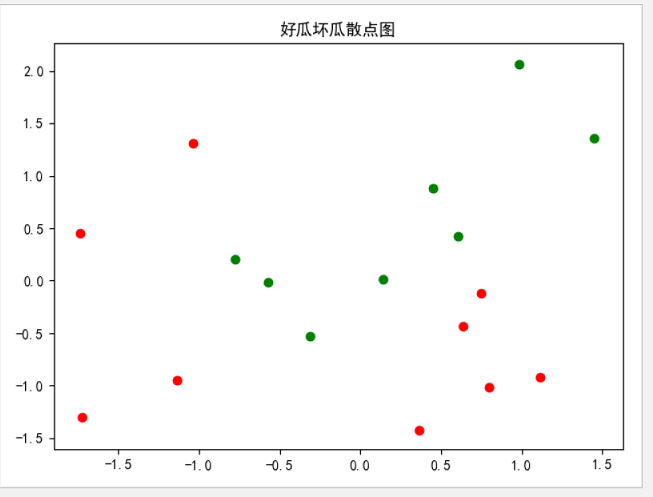
所以我起手选择SVM,这种算法库,可以有很大的可调性,对于线性可分或不可分,都可以处理的很好。
代码如下
import numpy as np
from matplotlib import pyplot as plt
from sklearn.svm import SVC
# 设置中文字体和负号正常显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 原始数据如下
x1=[0.697,0.774,0.634,0.608,0.556,0.403,0.481,0.437,0.666,0.243,0.245,0.343,0.639,0.657,0.360,0.593,0.719]
x2=[0.460,0.376,0.264,0.318,0.215,0.237,0.149,0.211,0.091,0.267,0.057,0.099,0.161,0.198,0.370,0.042,0.103]
y=[1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0]
# 特征拼接
X = np.c_[x1,x2]
# print(X)
y = np.c_[y]
# 特征缩放
X -= np.mean(X,axis=0)
X /= np.std(X,axis=0,ddof=1)
# 洗牌
m = len(X)
# 确定随机种子
np.random.seed(3)
# 生成随机序列
o = np.random.permutation(m)
# 洗牌
X = X[o]
y = y[o]
# 数据初始化
X = np.c_[np.ones(len(X)),X]
# 数据切割
d = int(0.7 * m)
X_train,X_test = np.split(X,[d])
y_train,y_test = np.split(y,[d])
# 3.用散点图可视化显示好瓜和坏瓜(5分)
plt.title('好瓜坏瓜散点图')
plt.scatter(X[y[:,0]==0,1],X[y[:,0]==0,2],c='r')
plt.scatter(X[y[:,0]==1,1],X[y[:,0]==1,2],c='g')
plt.show()
# 创建svm模型
model_svm = SVC(C=10,kernel='rbf',max_iter=10000,gamma='auto')
# 跑模型
model_svm.fit(X_train,y_train.ravel())
# 计算预测准确率及输出(3分)
print('训练集的准确率是:',model_svm.score(X_train,y_train))
print('测试集的准确率是:',model_svm.score(X_test,y_test))
效果如下:

最后
以上就是感性学姐最近收集整理的关于机器学习1笔试月度解析(一)的全部内容,更多相关机器学习1笔试月度解析(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复