线性判别分析
之前分析了主成分分析,是一种线性的降维方法,今天再来分析一下线性判别分析。
PCA和LDA都是线性的降维方法,PCA是无监督的,它没有考虑样本数据的标签;LDA是有标签的,它考虑样本的标签,并致力于让样本数据可分性最大化。二者都用于数据降维,而且经常一起使用。
原理
在做分类算法的时候,我们的准则是要让类间距离尽可能大,类内距离尽可能小。LDA用于分类问题,假设我们现在有一个分类问题,共有C个类,每个类有
N
i
N_i
Ni个m维的样本,对于
ω
i
omega_i
ωi类而言,它的数据集定义如下:
{
x
1
,
x
2
,
.
.
.
,
x
N
i
}
{x^1,x^2,...,x^{N_i}}
{x1,x2,...,xNi}
我们希望能够找到一种映射,将原始数据X映射到Y,Y位于一个C-1维的超平面上。
以两类问题为例,
ω
1
:
{
x
1
,
x
2
,
.
.
.
,
x
N
1
}
omega_1:{x^1,x^2,...,x^{N_1}}
ω1:{x1,x2,...,xN1},
ω
2
:
{
x
1
,
x
2
,
.
.
.
,
x
N
2
}
omega_2:{x^1,x^2,...,x^{N_2}}
ω2:{x1,x2,...,xN2}
利用变换矩阵w,我们希望将x投影到一维坐标上,也就是一个数值,对此,我们有
y
=
w
T
x
y=w^Tx
y=wTx
w是m*1的列向量,我们需要将y的可分性最大化。
对于x,我们有
μ
i
=
1
N
i
∑
x
∈
ω
i
x
mu_i=frac{1}{N_i}sum_{xinomega_i}x
μi=Ni1x∈ωi∑x
对于y,我们有
μ
~
=
1
N
i
∑
y
∈
ω
i
y
=
1
N
i
∑
x
∈
ω
i
w
T
x
=
w
T
1
N
i
∑
x
∈
ω
i
x
=
w
T
μ
i
tilde{mu}=frac{1}{N_i}sum_{yinomega_i}y=frac{1}{N_i}sum_{xinomega_i}w^Tx=w^Tfrac{1}{N_i}sum_{xinomega_i}x=w^Tmu_i
μ~=Ni1y∈ωi∑y=Ni1x∈ωi∑wTx=wTNi1x∈ωi∑x=wTμi
投影后的类间均值距离为
J
(
w
)
=
∣
μ
1
~
−
μ
2
~
∣
=
∣
w
T
μ
1
−
w
T
μ
2
∣
=
∣
w
T
(
μ
1
−
μ
2
)
∣
J(w)=|tilde{mu_1}-tilde{mu_2}|=|w^Tmu_1-w^Tmu_2|=|w^T(mu_1-mu_2)|
J(w)=∣μ1~−μ2~∣=∣wTμ1−wTμ2∣=∣wT(μ1−μ2)∣
这个距离存在一定的局限性,因为它没有考虑类内的方差,改进的办法是引入类内标方。
对于投影后的y,我们有
s
i
~
2
=
∑
y
∈
ω
i
(
y
−
μ
i
~
)
2
tilde{s_i}^2=sum_{yinomega_i}{(y-tilde{mu_i})}^2
si~2=y∈ωi∑(y−μi~)2
我们用
s
1
~
2
tilde{s_1}^2
s1~2和
s
2
~
2
tilde{s_2}^2
s2~2来衡量投影后类间的方差。
修正后的类间距离为
J
(
w
)
=
∣
μ
1
~
−
μ
2
~
∣
2
s
1
~
2
+
s
2
~
2
J(w)=frac{|tilde{mu_1}-tilde{mu_2}|^2}{tilde{s_1}^2+tilde{s_2}^2}
J(w)=s1~2+s2~2∣μ1~−μ2~∣2
这和我们的直觉是相符合的,我们需要让投影后的类间距离最大,而类内距离最小,这和上式的分子和分母是相对应的。
类内协方差矩阵如下:
S
i
=
∑
x
∈
ω
i
(
x
−
μ
i
)
(
x
−
μ
i
)
T
S_i=sum_{xinomega_i}(x-mu_i)(x-mu_i)^T
Si=x∈ωi∑(x−μi)(x−μi)T
类内散布矩阵如下:
S
w
=
S
1
+
S
2
S_w=S_1+S_2
Sw=S1+S2
基于此,有
s
i
~
2
=
∑
y
∈
ω
i
(
y
−
μ
~
)
2
=
∑
x
∈
ω
i
(
w
T
x
−
w
T
μ
i
)
2
=
∑
x
∈
ω
i
w
T
(
x
−
μ
i
)
(
x
−
μ
i
)
T
w
=
w
T
(
∑
x
∈
ω
i
(
x
−
μ
i
)
(
x
−
μ
i
)
T
)
w
=
w
T
S
i
w
tilde{s_i}^2=sum_{yinomega_i}(y-tilde{mu})^2\=sum_{xinomega_i}(w^Tx-w^Tmu_i)^2\=sum_{xinomega_i}w^T(x-mu_i)(x-mu_i)^Tw\=w^T(sum_{xinomega_i}(x-mu_i)(x-mu_i)^T)w\=w^TS_iw
si~2=y∈ωi∑(y−μ~)2=x∈ωi∑(wTx−wTμi)2=x∈ωi∑wT(x−μi)(x−μi)Tw=wT(x∈ωi∑(x−μi)(x−μi)T)w=wTSiw
然后,
s
1
~
2
+
s
2
~
2
=
w
T
S
1
w
+
w
T
S
2
w
=
w
T
(
S
1
+
S
2
)
w
=
w
T
S
w
w
=
S
w
~
tilde{s_1}^2+tilde{s_2}^2=w^TS_1w+w^TS_2w\=w^T(S_1+S_2)w\=w^TS_ww\=tilde{S_w}
s1~2+s2~2=wTS1w+wTS2w=wT(S1+S2)w=wTSww=Sw~
∣
μ
1
~
−
μ
2
~
∣
2
=
(
w
T
μ
1
−
w
T
μ
2
)
2
=
w
T
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
=
w
T
S
B
w
=
S
B
~
|tilde{mu_1}-tilde{mu_2}|^2=(w^Tmu_1-w^Tmu_2)^2\=w^T(mu_1-mu_2)(mu_1-mu_2)^Tw\=w^TS_Bw\=tilde{S_B}
∣μ1~−μ2~∣2=(wTμ1−wTμ2)2=wT(μ1−μ2)(μ1−μ2)Tw=wTSBw=SB~
S
B
S_B
SB为类间散布矩阵。
J
(
w
)
=
∣
μ
1
~
−
μ
2
~
∣
2
s
1
~
2
+
s
2
~
2
=
w
T
S
B
w
w
T
S
w
w
J(w)=frac{|tilde{mu_1}-tilde{mu_2}|^2}{tilde{s_1}^2+tilde{s_2}^2}=frac{w^TS_Bw}{w^TS_ww}
J(w)=s1~2+s2~2∣μ1~−μ2~∣2=wTSwwwTSBw
为了使J(w)最小,我们需要对其进行求导,我们要找到一个w,使得上式最大
d
d
x
J
(
w
)
=
d
d
w
{
w
T
S
B
w
w
T
S
w
w
}
=
0
frac{mathrm{d}}{mathrm{d}x}J(w)=frac{mathrm{d}}{mathrm{d}w}{frac{w^TS_Bw}{w^TS_ww}}=0
dxdJ(w)=dwd{wTSwwwTSBw}=0
即需要让求导后的分子为0,
{
w
T
S
w
w
}
d
d
w
{
w
T
S
B
w
}
−
{
w
T
S
B
w
}
d
d
w
w
T
S
w
w
=
0
{w^TS_ww}frac{mathrm{d}}{mathrm{d}w}{w^TS_Bw}-{w^TS_Bw}frac{mathrm{d}}{mathrm{d}w}{w^TS_ww}=0
{wTSww}dwd{wTSBw}−{wTSBw}dwdwTSww=0
即,
(
w
T
S
w
w
)
2
S
B
w
−
(
w
T
S
B
w
)
2
S
w
w
=
0
(w^TS_ww)2S_Bw-(w^TS_Bw)2S_ww=0
(wTSww)2SBw−(wTSBw)2Sww=0
两边同时除以
2
w
T
S
w
w
2w^TS_ww
2wTSww,得到
w
T
S
w
w
w
T
S
w
w
S
B
w
−
w
T
S
B
w
w
T
S
w
w
S
w
w
=
0
frac{w^TS_ww}{w^TS_ww}S_Bw-frac{w^TS_Bw}{w^TS_ww}S_ww=0
wTSwwwTSwwSBw−wTSwwwTSBwSww=0
→
S
B
w
−
J
(
w
)
S
w
w
=
0
rightarrow S_Bw-J(w)S_ww=0
→SBw−J(w)Sww=0
→
S
w
−
1
S
B
w
−
J
(
w
)
w
=
0
rightarrow S_w^{-1}S_Bw-J(w)w=0
→Sw−1SBw−J(w)w=0
解上式得,
S
w
−
1
S
B
w
=
λ
w
S_w^{-1}S_Bw=lambda w
Sw−1SBw=λw
这就是我们熟悉的特征值了。
于是,
w
∗
=
arg
max
w
J
(
w
)
=
arg
max
w
{
w
T
S
B
w
w
T
S
w
w
}
w^*= arg max _wJ(w)=arg max _w{frac{w^TS_Bw}{w^TS_ww}}
w∗=argwmaxJ(w)=argwmax{wTSwwwTSBw}
w是
S
w
−
1
S
B
S_w^{-1}S_B
Sw−1SB的最大特征值对应的特征向量。
多类的情况
之前我们讨论了两类时的情况,下面我们将扩展到多类时的情形,分析是类似的。
假定我们目前有C个类,我们需要C-1个向量,将原始数据映射到C-1维的超平面上。转换矩阵为
W
=
[
w
1
,
w
2
,
.
.
.
,
w
C
−
1
]
W=[w_1,w_2,...,w_{C-1}]
W=[w1,w2,...,wC−1],
y
i
=
w
i
T
x
y_i=w_i^Tx
yi=wiTx,x是m1的向量,y是c1的向量,W是m*(C-1)的矩阵。
假设数据集大小为n,每组数据有m个特征,则上式可以表示如下:
Y
=
W
T
X
Y=W^TX
Y=WTX
X
m
∗
n
=
[
x
1
1
x
1
2
⋯
x
1
n
⋮
⋮
⋮
⋮
x
m
1
x
m
2
⋯
x
m
n
]
X_{m*n}=left[begin{matrix} x_1^1 &x_1^2 &cdots &x_1^n\ vdots &vdots &vdots &vdots\ x_m^1 &x_m^2 &cdots &x_m^n end{matrix} right]
Xm∗n=⎣⎢⎡x11⋮xm1x12⋮xm2⋯⋮⋯x1n⋮xmn⎦⎥⎤
Y
C
−
1
∗
n
=
[
y
1
1
y
1
2
⋯
y
1
n
⋮
⋮
⋮
⋮
y
C
−
1
1
y
C
−
1
2
⋯
y
C
−
1
n
]
Y_{C-1*n}=left[begin{matrix} y_1^1 &y_1^2 &cdots &y_1^n\ vdots &vdots &vdots &vdots\ y_{C-1}^1 &y_{C-1}^2 &cdots &y_{C-1}^n end{matrix} right]
YC−1∗n=⎣⎢⎡y11⋮yC−11y12⋮yC−12⋯⋮⋯y1n⋮yC−1n⎦⎥⎤
W
m
C
−
1
=
[
w
1
,
w
2
,
.
.
.
,
w
C
−
1
]
W_{m}^{C-1}=[w_1,w_2,...,w_{C-1}]
WmC−1=[w1,w2,...,wC−1]
类内散布矩定义如下:
S
w
=
∑
i
=
1
C
S
i
S_w=sum_{i=1}^{C}S_i
Sw=i=1∑CSi
S
i
=
∑
x
∈
ω
i
(
x
−
μ
i
)
(
x
−
μ
i
)
T
S_i=sum_{xinomega_i}(x-mu_i)(x-mu_i)^T
Si=x∈ωi∑(x−μi)(x−μi)T
μ
i
=
1
N
i
∑
x
∈
ω
i
x
mu_i=frac{1}{N_i}sum_{xinomega_i}x
μi=Ni1x∈ωi∑x
类间散布矩阵定义如下:
S
B
=
∑
i
=
1
C
N
i
(
μ
i
−
μ
)
(
μ
i
−
μ
)
T
S_B=sum_{i=1}^{C}N_i(mu_i-mu)(mu_i-mu)^T
SB=i=1∑CNi(μi−μ)(μi−μ)T
μ
=
1
N
∑
∀
x
x
=
1
N
∑
i
=
1
C
N
i
μ
i
mu=frac{1}{N}sum_{forall x}x=frac{1}{N}sum_{i=1}^{C}N_imu_i
μ=N1∀x∑x=N1i=1∑CNiμi
μ
i
=
1
N
i
∑
x
∈
ω
i
x
mu_i=frac{1}{N_i}sum_{xinomega_i}x
μi=Ni1x∈ωi∑x
同样的,对于y,我们有
μ
i
~
=
1
N
i
∑
y
∈
ω
i
y
tilde{mu_i}=frac{1}{N_i}sum_{yinomega_i}y
μi~=Ni1y∈ωi∑y
μ
~
=
1
N
∑
∀
y
y
tilde{mu}=frac{1}{N}sum_{forall y}y
μ~=N1∀y∑y
S
w
~
=
∑
i
=
1
C
S
i
~
=
∑
i
=
1
C
∑
y
∈
ω
i
(
y
−
μ
i
~
)
(
y
−
μ
i
~
)
T
tilde{S_w}=sum_{i=1}^{C}tilde{S_i}=sum_{i=1}^{C}sum_{yinomega_i}(y-tilde{mu_i})(y-tilde{mu_i})^T
Sw~=i=1∑CSi~=i=1∑Cy∈ωi∑(y−μi~)(y−μi~)T
S
B
~
=
∑
i
=
1
C
N
i
(
μ
i
~
−
μ
~
)
(
μ
i
~
−
μ
~
)
T
tilde{S_B}=sum_{i=1}^{C}N_i(tilde{mu_i}-tilde{mu})(tilde{mu_i}-tilde{mu})^T
SB~=i=1∑CNi(μi~−μ~)(μi~−μ~)T
再来计算J(w),
S
w
~
=
W
T
S
w
W
tilde{S_w}=W^TS_wW
Sw~=WTSwW
S
B
~
=
W
T
S
B
W
tilde{S_B}=W^TS_BW
SB~=WTSBW
J
(
w
)
=
∣
S
B
~
∣
∣
S
w
~
∣
=
∣
W
T
S
B
W
∣
∣
W
T
S
w
W
∣
J(w)=frac{|tilde{S_B}|}{|tilde{S_w}|}=frac{|W^TS_BW|}{|W^TS_wW|}
J(w)=∣Sw~∣∣SB~∣=∣WTSwW∣∣WTSBW∣
此时的类间散布矩阵已经不是数值了,所以我们取了它的行列式的值。
依然用求导的方法,我们可以得到,
S
w
−
1
S
B
w
i
=
λ
i
w
i
S_w^{-1}S_Bw_i=lambda_iw_i
Sw−1SBwi=λiwi
λ
i
=
J
(
w
i
)
lambda_i=J(w_i)
λi=J(wi)
于是,转换矩阵W是由
S
w
−
1
S
B
S_w^{-1}S_B
Sw−1SB的前C-1大的特征值对应的特征向量组成的。
局限性
- LDA也有它自身的局限性,它最多只能提供C-1维的特征映射,如果需要更多的特征就不能采用LDA了。
- LDA假定样本数据服从的是高斯分布,如果样本服从的不是高斯分布,则LDA不再成立。
- 当样本的判别信息不是均值而是方差的时候,LDA会失效。举个极端的例子就是当不同类别的样本数据的均值相同的时候,这是它们的类间距离都为0,经过线性映射后的Y的类间距离也为0,J(w)就没有意义了。
实验效果
python sklearn中有LDA的模块,可以直接利用它来进行线性判别分析,我们采用鸢尾花数据进行测试。
代码如下:
from sklearn.datasets import load_iris
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
import numpy as np
iris_data=load_iris()
X=iris_data['data']
y=iris_data['target']
#print(X.shape) # (150,4)
#print(y.shape) #(150,)
# print(y)
lda=LinearDiscriminantAnalysis()
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0,stratify=y)
# print(X_train.shape)
# print(X_test.shape)
lda.fit(X_train,y_train)
print(lda.coef_)
print(lda.intercept_)
print(lda.score(X_test,y_test))
X_transformed=np.dot(X_train,lda.coef_.transpose(1,0))
# print(X_transformed.shape) #(150,3)
fig=plt.figure()
ax=Axes3D(fig,rect=[0,0,1,1],elev=30,azim=20)
colors=['r','g','b','yellow']
for i in range(X_transformed.shape[0]):
ax.scatter(X_transformed[i][0],X_transformed[i][1],X_transformed[i],color=colors[y_train[i]],marker='*')
plt.show()
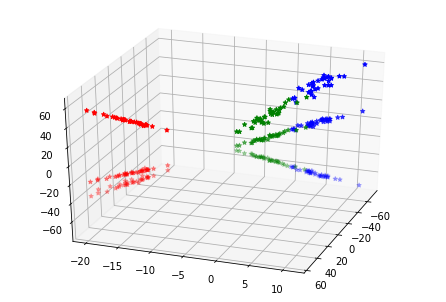
采用的是jupyter notebook,降维后的样本分布如下:
参考资料
- pdf文件
最后
以上就是整齐钢铁侠最近收集整理的关于数据分析与处理(二)线性判别分析(LDA)线性判别分析多类的情况局限性实验效果的全部内容,更多相关数据分析与处理(二)线性判别分析(LDA)线性判别分析多类内容请搜索靠谱客的其他文章。








发表评论 取消回复