对于C语言的参数传递都是值传递,当传传递一个指针给函数的时,其实质上还是值传递,除非使用双指针。
在讲双指针之前,还是先讲讲关于C语言函数调用的本质。
函 数调用操作包括从一块代码到另一块代码之间的双向数据传递和执行控制转移。数据传递通过函数参数和返回值来进行,包括局部变量的空间分配与回收,都是通过 栈来实现的。绝大多数CPU上的程序实现使用栈来支持函数调用操作。栈被用来传递函数参数、存储返回信息、临时保存寄存器原有值以备恢复以及用来存储局部 数据。当函数A调用函数B的时候,会把A的变量和参数压入到栈中,然后接着将B的变量和参数,局部变量压入到栈中。然后当A调用B是,B其实是在栈中取得 A传递的参数和值,从而达到值传递的效果。
以一个交换2个数的值的函数调用为例。
- void
- swap ( int *a, int *b ){
- int c;
- c = *a;
- *a = *b;
- *b = c;
- }
- int
- main(int argc, char **argv){
- int a,b;
- a = 16;
- b = 32;
- swap( &a, &b);
- return ( a - b );
- }
那么,这段代码编译成汇编语言之后,除了会有代码段,数据段,堆栈,那么在调用的时候,会把main函数的参数变量压入main函数的栈帧,然后接着会压入swap函数的局部变量和参数
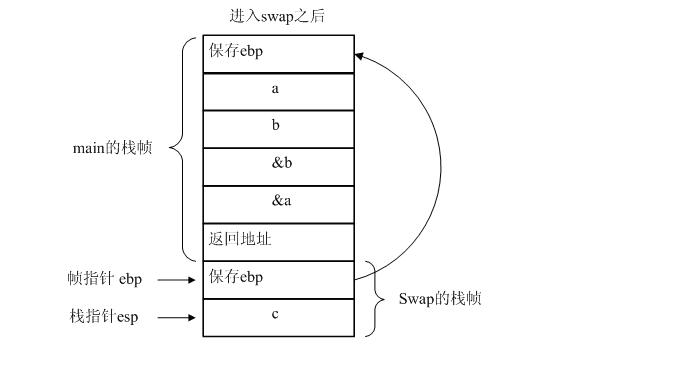
那么按照刚才上述理论,编译成汇编语言以后,这个图就是函数调用的时候内存形态。
大部分现代计算机系统使用栈来给进程传递参数并且存储局部变量。栈是一种在进程映象内存的高地址内的后进先出(LIFO)的缓冲区。当程序调用一个函数时一个新的“栈帧”会被创建。这个栈帧包含着传递给函数的各种参数和一些动态的局部变量空间。“栈指针”记录着当前 栈顶的位置。由于栈指针的值会因为新变量的压入栈顶而经常的变化,许多实现也提供了一种"帧指针"来定位在栈帧的起始位置,以便局部变量可以更容易的被访问。
简单的说就是帧指针可用于子例程参数传输,而栈指针则可用于存储子程序调用的返回地址。
有了上面的图和理论基础,再来讨论双重指针的问题。当定义的时候,只有一个*号的时候,我们叫它一级指针。**个星号的叫二级指针。
当我们使用一级指针的时候,我们试图使用下述错误代码来实现2个数交换
- void
- swap ( int *a, int *b ){
- int *temp;
- temp = NULL;
- temp = a;
- a = b;
- b = temp;
- }
- int
- main ( int argc, char **argv ){
- int a,b;
- a = 16;
- b = 32;
- swap(&a, &b);
- return ( a - b );
- }
这种方式按照理论上来说,是想通过调用swap函数,在swap函数内部,实现将交换&a,&b,即交换a和b的地址来达到目的。这样绝对不可以。因为当把a,b的地址传到swap函数之后,按照上述栈帧图的结构来看,最终swap函数值通过栈指针来实现的,当swap使用的时候,还是把 a,b的地址复制到寄存器中才能运算。那么,大家也许就明白了,swap把a,b的地址复制到寄存器中,然后运算,相当于抱着a,b的副本跑了,然后去操作,这些所有针对a,b副本的操作管main函数中的a,b什么事? 当swap返回之后,这些寄存器或者是栈空间随着swap的返回而释放了,而 main函数的a,b没发生任何变法。所以上述代码是错误的,无法实现你想要的功能。
当我们用二级指针来实现上述功能的时候有就可以达到效果。
- void
- swap ( int **a, int **b ){
- int *tmp = NULL;
- tmp = *a;
- *a = *b;
- *b = tmp;
- }
- int
- main ()
- ....
- ....
这个时候,你会发现就能实现达到交换的目的。
这就是双指针神奇的功能,突破C语言传值的概念。那么,双指针是如何达到效果的呢?
当我们申明 **a之后,其实双指针变量a其实已经存在了。那么在内存中的效果如下图
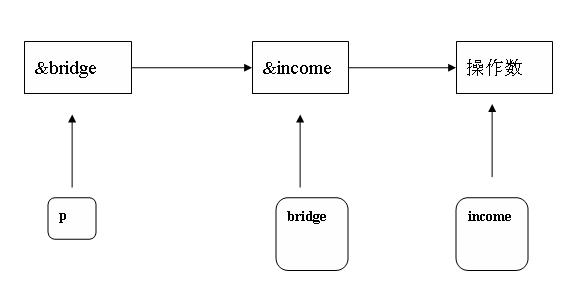
那么,p中放的是中间桥梁bridge的地址&bridge,则*p就是中间桥梁bridge的内容即是目标操作数的地址&income,从而**p就是目标操作数
再来看这个图,p就是这里**a种的a.当我们申明**p之后,p就已经存在了。其实这个bridge也已经存在了,那么我们要做的就是bridge中放 我们要操作的数的地址。也就是&incom;那么,其实这样操作*bridge就是操作&incom也就是&b啊,这个一级指针 没什么区别啊。
请注意,对于一级指针,我们要操作的是就是b,那么按照汇编语言的规则,就要把b放到寄存器或者栈中去操作,我们相当于复制了一个副本去操作,等我们操作完了,返回函数,这些寄存器,栈等都释放了,main中什么也没发生。但是如果我们用双指针,二级指针就不一样了。我们操作的是bridge.我们只是机械的复制一个bridge的内容到寄存器或者到栈中,而没有实际的去复制imcom的内容,我们只是告诉bridge,你要指向一个叫incom的地址, 也就是说,bridge的内容就是incom的地址,即&incom,通过bridge这个中间桥梁,所以,就达到目的了。所以,双指针让参数传递具有穿透力。
双指针主要用在但我们想向一个A函数传递参数的时候,但是我们希望在A内部对参数做任何修改都能保存起来,那么就是用双指针吧。
举个例子;
我们在做链表的时候,我们肯定希望在用一个函数creatLink(...)函数来增加链表节点。那么我们可以有2种方法来实现
第一种,用一级指针
- typedef struct node{
- ...
- ...
- }list;
- node *create(list *l){
- list *head;
- head = l;
- malloc...//为节点申请内存空间
- ...
- ...
- //操作
- return head;
- }
- int main(...){
- ...
- ...
- list *listhead
- createList(listhead);
- ....
- //以后的任何操作,我们都要考虑,我们是否拿到的是链表头指针,到底哪个是链表波的头指针,我们是否要renturn下来返回链表头指针??等。。。。
- }
这样做可以达到删除增加节点的目的,但是,在任何情况下,我们的操作都得死死地抓住头指针,也即是我们增加删除节点后,任何对链表长度的修改,我们都要 链表头指针返回,即 return head;所以,我们要通过这个函数最后获得头指针,抓住他,死死地抓住他,然后操作。
第二种方法:用双指针,也即是二级指针。
- typedef struct node{
- ...
- ...
- }list;
- void
- create(list **l){
- list *head;
- head = l;
- malloc...//为节点申请内存空间
- ...
- ...
- //操作
- }
- int
- main(...){
- ...
- ...
- list *st
- createList(st)
- ....
- ..
- //以后的任何操作,不管是删除还 是插入,我们不需要考虑,我们是否已经return head了,不需要,我们在任何情况下,对链表的操作都只需要使用st来完成,因为,st就是链表的头指针,不变,因为在申明st的时候,已经为st分配 一个地址空间,它是存在的,一直存在,直到main函数结束
- }
转自:http://blog.csdn.net/feiyinzilgd/article/details/5302369
之前我写过一篇博客《深入理解双指针》,最近也再次重温《C++ Primer》读到指针那一章节的时候,度C/C++指针又有了新的领悟。
《C++ Primer》中强调了一个指针解引用的概念。
究竟什么是解引用呢?
为了解释解引用这个概念,我引用《C++ Primer》中的一段话:
When we dereference a pointer, we obtain the object to which the pointer points
从上面这段话可以看出解引用的对象是指针,当我们对指针解引用的时候,我们得到的是指针所指向的对象。按照C语言的习惯,当我们队指针解引用的时候,我们得到的是该指针所指向的结构。
举个例子:
- int idata = 24;
- int *ptr = &idata;//定义一个指针指向idata
- /**这里就是对指针ptr解引用
- 解引用之后得到ptr所指向的结构,也就是idata,赋值给getdata
- */
- int getdata = *ptr//“*”星号就是用来解引用的
- 一级指针:
C/C++中,变量或者结构都有一个作用域。
要想在作用域B中修改作用域A中的非指针变量的值(比如 int 数据),就必须将该变量的指针传入到作用域B中,
然后对指针解引用,然后作出任何修改都会反馈到该指针所指向的数据,否则值传递无法反馈修改结果,即修改是无效的。
- //version 1
- void swap(int param1, int param2){
- int tmp = param1;
- param1 = param2;
- param2 = tmp;
- }
- void funcA(){
- int a = 24;
- int b = 12;
- swap(a, b);
- }
上面version1代码,作用于funcA中的变量直接值传递到作用域swap中,由于param1,param2的作用域仅限于swap。
所以,对param1, param2的任何修改都不会反馈到funcA中,所以,a和b不会有任何变化。
所以,为了使非指针变量的值能够在不同的作用域中进行修改并反馈结果到不同域中,那就是用一级指针(为了区别后面要重点讲述的双指针)吧,然后对指针解引用,之后修改的任何结果都会被反馈到不同的域中。
- //version 2
- /**
- 对指针ptr1和ptr2解引用之后,作出的任何修改都会反馈到指针所指向的数据中去
- */
- void swap(int *ptr1, int *ptr2){
- int tmp = *ptr1;
- *ptr1 = *ptr2;
- *ptr2 = tmp;
- }
- void funcA(){
- int a = 24;
- int b = 12;
- swap(&a, &b)//传入a和b的指针
- }
上面version 2中,就是用了一级指针,对指针解引用之后,对其作出的任何修改都会反馈到指针所指向的数据。
所以,a和b的数据发生了变化。
- 双指针
- //version 3
- /**
- getbufer函数想让getmemory函数申请一块内存并将内存起始指针赋值给
- buffer这个指针
- */
- void getmemory(char *ptr){
- ptr = (char *)malloc(20);//这个地方对ptr解引用没有任何意义。因为我们是为了修改指针本身,而不是修改指针所指向的值
- }
- void getbuffer(){
- char *buffer = NULL;
- getmemory(buffer);
- }
上面version 3的代码,我们想要修改buffer本身这个指针的值,但是getmemory(buffer)之后,buffer的值还是NULL,并不是所希望的那个molloc之后堆中那个起始地址。
分析如下:
ptr的作用于在getmemory中,虽然我们传入了buffer这个指针,但是由于ptr是局部变量,对ptr做修改无法反馈到getbuffer域中
所以,为了使指针变量的值(不是指针变量所指向的值)能够在不同作用域中进行修改并反馈修改结果,使用双指针吧,然后传入需要修改的指针的地址,然后对解引用作出的任何修改都将反馈到该指针。
双指针定义和申明:
int **p从这个申明中就可以知道,指针的指针,p所指向的值也是一个指针,即p指向的值也是一个地址。
然后对P解引用: *p
之后,对*p的任何操作都将反馈到p所指向的地址的值,从而达到对指针本省的修改
- //version 4
- void getmemory(char **p){
- *p = (char *)malloc(10);
- }
- void getbuffer(){
- char *buffer;
- getmemory(&buffer);
- }
- 对指向非指针变量的指针[指针的内容是非指针变量的地址](其实就是该变量的地址)进行解引用,作出的修改可以反馈到该指针所指向的值,这里的值是非指针变量。
- 对指向指针变量的指针[指针的内容指针变量的地址]进行解引用,作出的任何修改可以反馈到该指针所指向的值,这里这个值是指针变量本身的值(不是指向的值)。
综合1和2可以得出一个结论:对解引用之后的任何操作,都将反馈给该指针所指向的值。而这个值可以分为指针变量和非指针变量。
- 什么时候使用双指针?
回答:当我们需要修改指针变量本身的值的时候,可以使用双指针
很多情况下,双指针都可以通过其他途径,比如使用return来反馈结果。
转自:http://blog.csdn.net/feiyinzilgd/article/details/6138438
最后
以上就是忧伤眼神最近收集整理的关于理解双指针的全部内容,更多相关理解双指针内容请搜索靠谱客的其他文章。








发表评论 取消回复