
向AI转型的程序员都关注了这个号????????????
大数据挖掘DT机器学习 公众号: datayx
最近遇到一个项目需求,需要进行拍照,并且识别图片中的文字,其实该项目也可以改成其他图像识别,比如人脸识别、图像分类等。
完整项目代码:
关注微信公众号 datayx 然后回复“ 摄像头”即可获取。
打开摄像头拍照,并识别图片中的文字(java)
1、打开摄像头
关于打开摄像头这个功能,我们知道HTML5出现以后可以
navigator.getUserMedia
打开我们的摄像头,其核心代码如下:

2、拍照
进行拍照我们可以通过HTML中提供的video标签和canvas实现,通过获取到canvas上下文和video的DOM,然后通过drawImage方法,就可以实现拍照功能
context.drawImage(oVideo, 0, 0, 640, 480);
3、图片上传
关于图片上传这一块,主要思路是先想办法把canvas绘制的图形转化为图片,但是canvas只提供了toDataURL()方法,通过该方法可以获取到图形的base64。然后根据base64转化为图片并保存在本地。
3.1、获取canvas图像的base64(核心代码)
// base64的长度在8000以上
var base64 = oCanvas.toDataURL();3.2、后台获取base64字符串
需要注意的是,我们在获取base64的时候,通过ajax方法请求,会把base64中的+换为空格,因此我们在后台获取到base64以后需要替换回来。
3.3、根据base64转化为图片(核心代码)

4、图片中的文字识别
文字的识别技术,翻译过来以后就是(Optical Character Recognition)光学字符识别,即电子设备通过检测暗、亮的模式确定其形状,然后用字符识别的方法把形状翻译成计算机文字的过程。OCR可以自己搭建神经网络训练出模型,也可直接调用第三方借口,看效果选择吧。
4.1、百度AI开发平台
百度这一块做的比较好了。这里要安利一波(http://ai.baidu.com/)

4.2、文字识别
下面是最自己封装的一个文字识别的方法,在创建应用成功以后,会为你提供APP_ID 、API_KEY 、SECRET_KEY 。

识别效果:
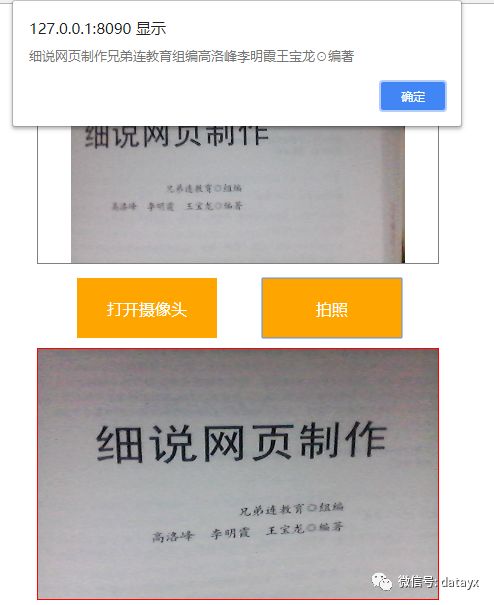
通过摄像头捕获图像用tensorflow做手写数字识别(python)
先在mnist数据集上训练好网络,并保存模型。
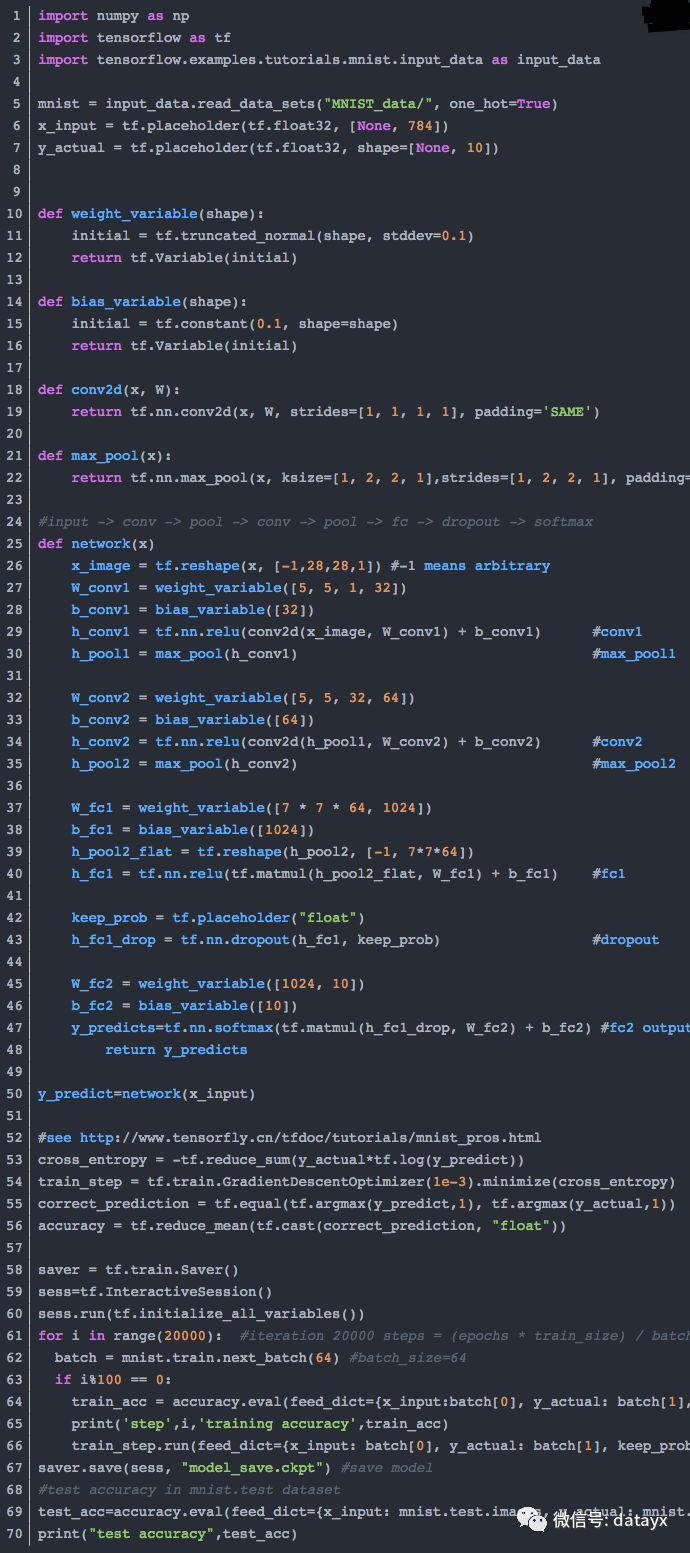
预测时使用opencv来打开摄像头捕获图像,设置ROI区域,将ROI区域图像输入加载好参数的cnn网络来识别。
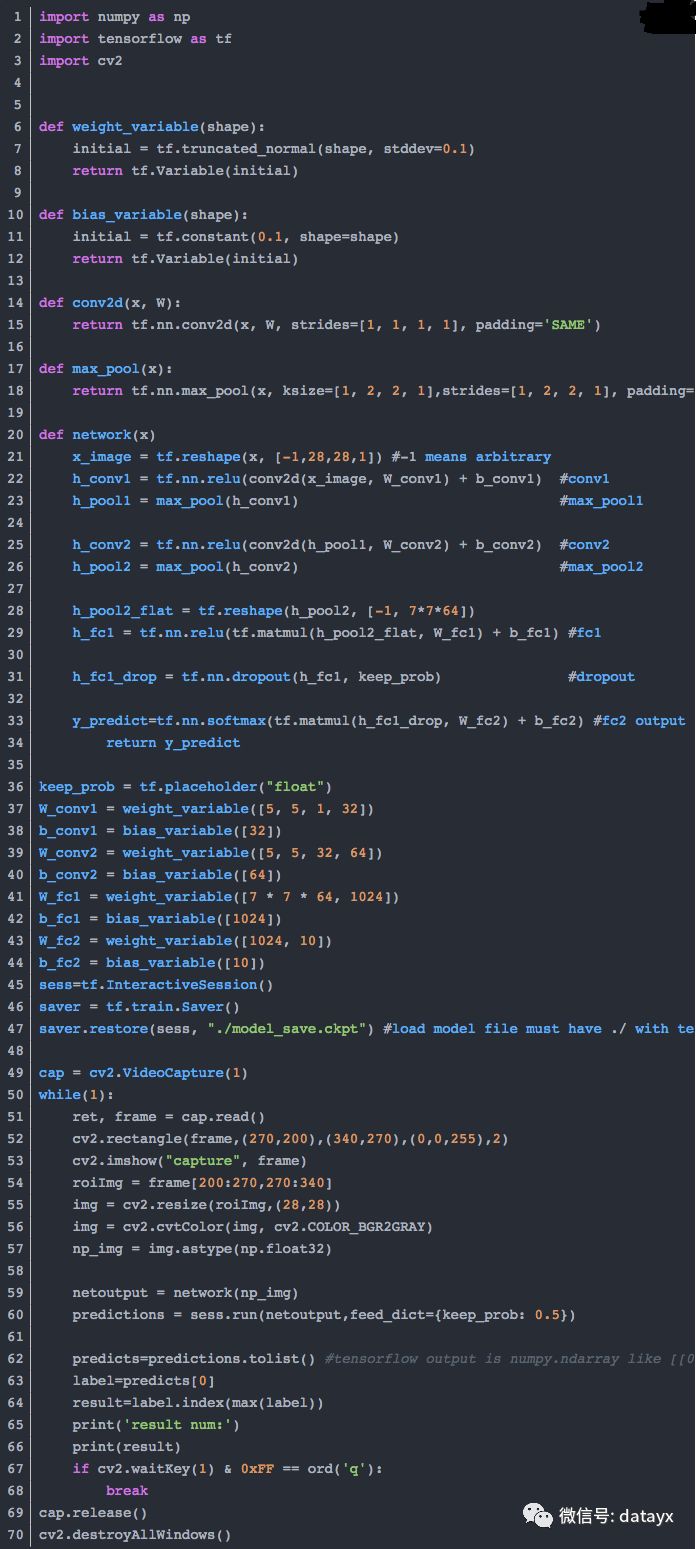
https://blog.csdn.net/gzydominating40/article/details/70171774
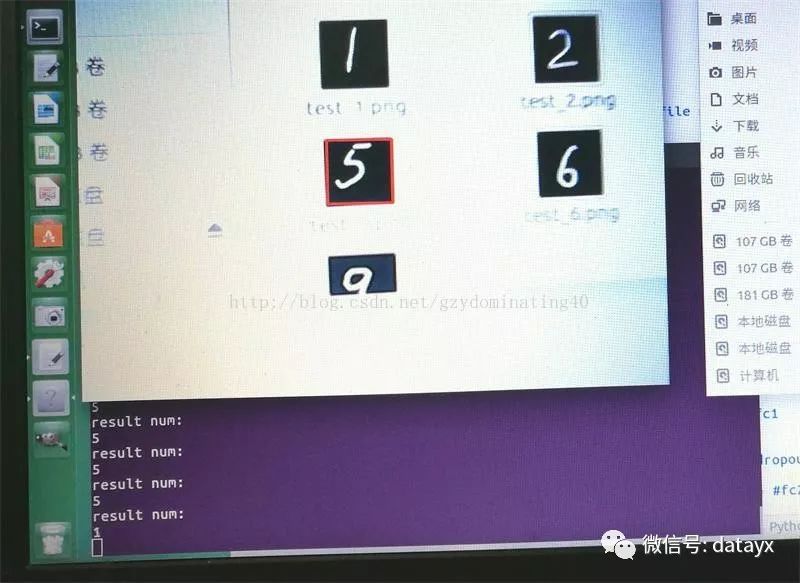
识别结果:
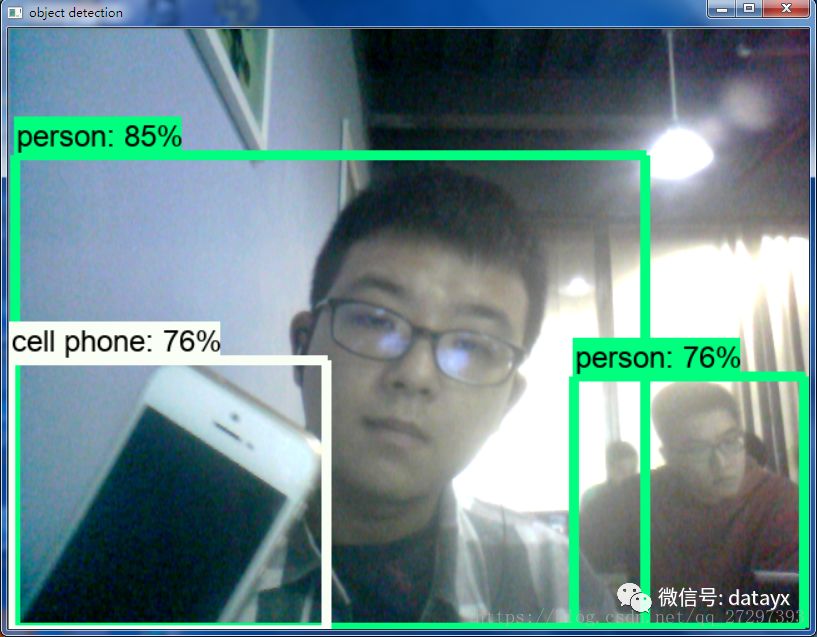
Tensorflow + 摄像头实时目标检测
官方源码提供了图片的检测,但是实用性不高,所以对源码进行了修改,使用笔记本自带摄像头或者usb摄像头进行实时检测。
检测效果:
参考源
视频:https://www.youtube.com/watch?v=COlbP62-B-U&list=PLQVvvaa0QuDcNK5GeCQnxYnSSaar2tpku
源码:https://github.com/tensorflow/models/tree/master/research/object_detection
其他包:https://github.com/google/protobuf/releases
I:AnacondaStudyTensorflowmodelsresearch>I:/Anaconda/librl/protoc-3.4.0-win32/bin/protoc object_detection/protos/*.proto --python_out=.
环境变量设置:
(https://blog.csdn.net/RobinTomps/article/details/78115628?locationNum=5&fps=1)
在指定的环境中的目录下
(D:ProgramDataAnaconda3envstensorflowLibsite-packages
),添加tensorflow_model.pth文件,内容如下:
I:AnacondaStudyTensorflowmodelsresearchslim
I:AnacondaStudyTensorflowmodelsresearch
Opencv对应的python 3.5版本下载地址
https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
文件名:opencv_python-3.4.1-cp35-cp35m-win_amd64.whl
安装:pip install opencv_python-3.4.1-cp35-cp35m-win_amd64.whl
视频监控识别的替换和更改:
180度旋转:
image_np = cv2.flip(image_np, 0)
添加判断:
第一部分为旧版,比较流畅
第二部分为新版,有些卡顿
下面的代码可以放到目标文档直接运行(此代码名object_detection_converted.py)
文件路径:./models/research/object_detection/object_detection_converted.py

https://blog.csdn.net/qq_27297393/article/details/80556833
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
最后
以上就是失眠百合最近收集整理的关于【深度学习项目】打开摄像头拍照,并做图片识别打开摄像头拍照,并识别图片中的文字(java)通过摄像头捕获图像用tensorflow做手写数字识别(python)Tensorflow + 摄像头实时目标检测的全部内容,更多相关【深度学习项目】打开摄像头拍照,并做图片识别打开摄像头拍照,并识别图片中的文字(java)通过摄像头捕获图像用tensorflow做手写数字识别(python)Tensorflow内容请搜索靠谱客的其他文章。








发表评论 取消回复