文章目录
- KNN
- 原理
- 优缺点
- 逻辑斯蒂函数
- 原理
- 优缺点
- 决策树
- 原理
- 优缺点
- 朴素贝叶斯
- 原理
- 优缺点
- 支持向量机
- 原理
- 优缺点
- 自适应提升算法
- 原理
- 优缺点
KNN
K-近邻算法(k-Nearest Neighbor,KNN)采用测量
不同特征值之间的距离方法进行分类。
原理
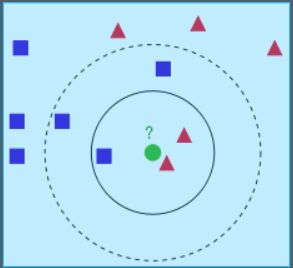
- 已知的数据分为两类:一类是蓝色的正方形,一类是红色的三角形。绿色圆形是待分类的数据。当K=3和K=5时,得到的分类结果不同。
KNN本质是基于一种数据统计的方法。
- 度量空间中点之间的距离,常见的曼哈顿距离计算,欧式距离计算等等。不过通常KNN算法中使用的是欧式距离。
二维空间两个点的欧式距离计算公式如下:
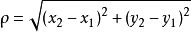
拓展到多维空间,则欧式距离计算公式变成这样:
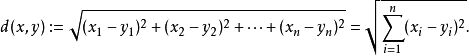
优缺点
优点
- 简单易用,相比其他算法,简洁明了的算法。
- 模型训练时间快,KNN算法是
惰性的。 - 预测效果好。
- 对异常值不敏感
惰性:没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类
缺点
- 对内存要求较高,因为该算法存储了所有训练数据
- 预测阶段可能很慢
- 对不相关的功能和数据规模敏感
简单得说,当需要使用分类算法,且数据比较大的时候就可以尝试使用KNN算法进行分类了.
逻辑斯蒂函数
Logistics回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。
“回归” 一词源于最佳拟合,表示要找到最佳拟合参数集
原理
回归问题转化为分类问题
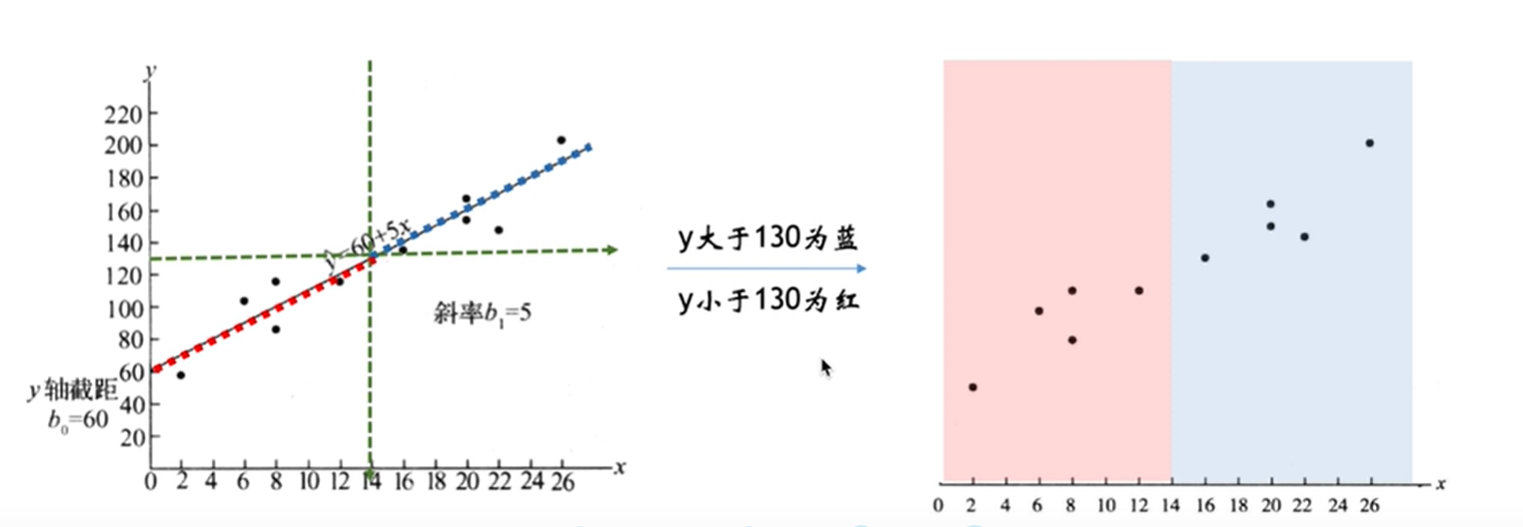
- 逻辑回归 = 线性回归 + sigmiod函数
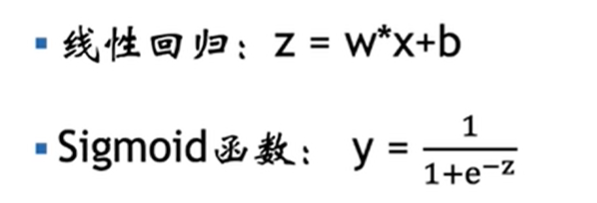
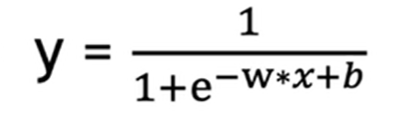
逻辑回归通过 logistic (Sigmoid)函数将一个范围不定的连续值映射到 (0, 1) 的区间内,然后划定一个阈值,输出值大于这个阈值的是一类,小于这个阈值的是另一类。阈值会根据实际情况选择,一般会选择 0.5。
公式
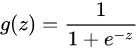
函数图像
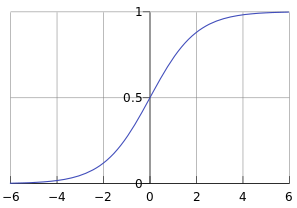
- 当线性回归的结果 z=0 时,逻辑回归的结果 y=0.5,这可以视为一个分界点:
- 当 z>0 时,y>0.5,此时逻辑回归的结果就可以判为正例;
- 当 z<0 时,y<0.5,逻辑回归的结果就可以判为反例。
优缺点
优点
- 实现简单,广泛的应用于工业问题上;
- 分类时计算量非常小,速度很快,存储资源低;
- 便利的观测样本概率分数;
- 对逻辑回归而言,多重共线性并不是问题,它可以结合
L2正则化来解决该问题; - 计算代价不高,易于理解和实现;
缺点
- 当特征空间很大时,逻辑回归的性能不是很好;
- 容易欠拟合,一般准确度不太高
- 不能很好地处理大量多类特征或变量;
- 只能处理两分类问题,且必须线性可分;
- 对于非线性特征,需要进行转换;
决策树
决策树(Decision Tree)是采用包含根节点、内部节点和叶节点的树形结构,通过判定不同属性的特征来解决分类问题。其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
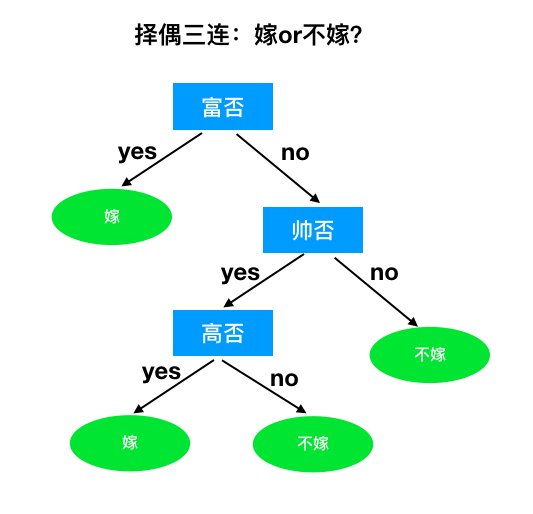
- 给你两条新数据,你能预测出它的结果吗?
| 序号 | 富否 | 帅否 | 高否 | 嫁否 |
|---|---|---|---|---|
| 1 | 富 | 不帅 | 不高 | ? |
| 2 | 不富 | 帅 | 不高 | ? |
决策树算法的核心是要解决两个问题:
- 1)如何从数据表中找出最佳节点和最佳分枝?
- 2)如何让决策树停止生长,防止过拟合?
原理
-
信息熵(information entropy)是度量样本集合纯度的一种常用指标。信息熵越低,纯度越高。
-
基尼值反映了从数据集中随机抽取两个样本,其类别标记不一致的概率,因此基尼值越小,则数据集纯度越高。选择划分属性时,应该选择那个使得划分之后基尼指数最小的属性作为划分属性。
-
熵、条件熵、信息增益
决策树是怎样来防止过拟合呢?一般的措施是将生产的决策树进行剪枝,预剪枝或者后剪枝。
优缺点
优点
- 易于理解和解释,因为树可以画出来被看见
- 需要很少的数据准备。其他很多算法通常都需要数据规范化,需要删除空值等。
- 能够同时处理数字和分类数据,既可以做回归又可以做分类。
- 是一个白盒模型,结果很容易能够被解释。如果在模型中可以观察到给定的情况,则可以通过布尔逻辑轻松解释条件。
- 可以使用统计测试验证模型,这让我们可以考虑模型的可靠性。
- 即使其假设在某种程度上违反了生成数据的真实模型,也能够表现良好。
缺点
- 决策树学习者可能创建过于复杂的树,这些树不能很好地推广数据。这称为
过度拟合。修剪,设置叶节点所需的最小样本数或设置树的最大深度等机制是避免此问题所必需的,而这些参数的整合和调整对初学者来说会比较晦涩 - 决策树可能不稳定,数据中微小的变化可能导致生成完全不同的树,这个问题需要通过
集成算法来解决。 - 决策树的学习是基于贪婪算法,它靠优化
局部最优(每个节点的最优)来试图达到整体的最优,但这种做法不能保证返回全局最优决策树。这个问题也可以由集成算法来解决,在随机森林中,特征和样本会在分枝过程中被随机采样。 - 如果标签中的某些类占主导地位,决策树学习者会创建偏向主导类的树。因此,建议在拟合决策树之前平衡数据集。
朴素贝叶斯
朴素贝叶斯的基本思想在于分析待分类样本出现在每个输出类别中的后验概率,并以取得最大后验概率的类别作为分类的输出。
原理
贝叶斯的公式
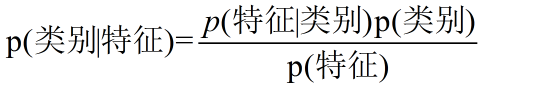
- 最终我们要求的就是 p(类别|特征)
朴素贝叶斯的公式
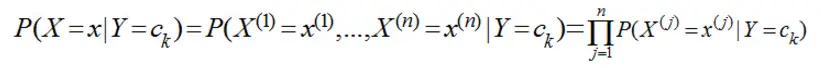
-
假设各个特征之间是独立不相关的,对于给出的待分类样本特征x,求解在此样本出现的条件下各个类别出现的概率,哪个最大,就认为此待分类样本属于哪个类别。
-
怎样用非数学语言讲解贝叶斯定理(Bayes’s theorem)?
优缺点
优点
- 算法逻辑简单,易于实现
- 分类过程中时空开销小
缺点
- 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
- 在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
支持向量机
支持向量机是一种二分类算法,通过在高维空间中构造超平面实现对样本的分类。
原理
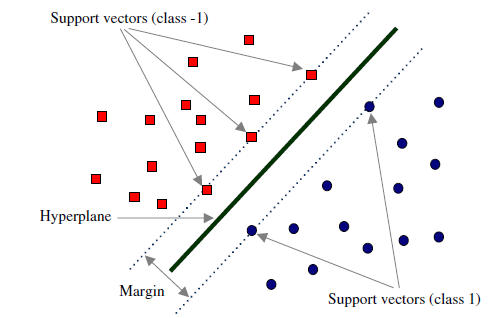
- 线性可分支持向量机就是在给定训练数据集的条件下,根据间隔最大化学习最优的划分超平面的过程。
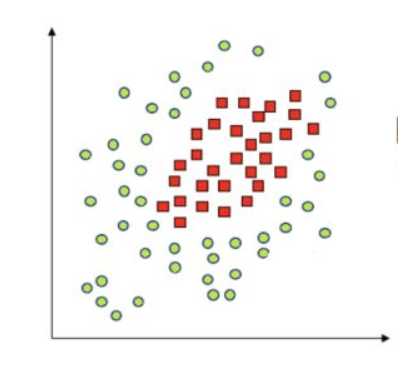
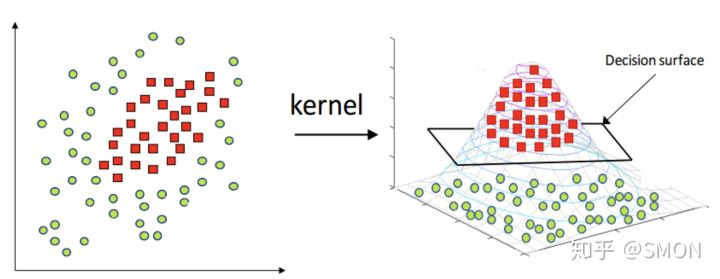
核函数
- 非线性的问题(例如异或问题),此时就需要用到核技巧(kernel trick)将线性支持向量机推广到非线性支持向量机。
将原始低维空间上的非线性问题转化为新的高维空间上的线性问题,这就是核技巧的基本思想。
常用的核函数包括以下几种
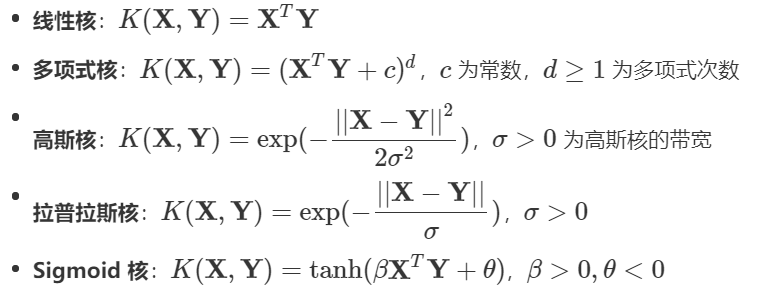
优缺点
优点
- 由于SVM是一个凸优化问题,所以求得的解一定是全局最优而不是局部最优。
- 不仅适用于线性线性问题还适用于非线性问题(用核技巧)。
- 拥有高维样本空间的数据也能用SVM,这是因为数据集的复杂度只取决于支持向量而不是数据集的维度,这在某种意义上避免了“维数灾难”。
缺点
- 二次规划问题求解将涉及m阶矩阵的计算(m为样本的个数), 因此SVM不适用于超大数据集。(SMO算法可以缓解这个问题)
- 只适用于二分类问题。(SVM的推广SVR也适用于回归问题;可以通过多个SVM的组合来解决多分类问题)
自适应提升算法
AdaBoost全称为Adaptive Boosting,中文名称叫做自适应提升算法;什么叫做自适应,就是这个算法可以在不同的数据集上都适用。提升方法是指:分类问题中,通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类器的性能。
原理
- 在解决分类问题时,提升方法遵循的是循序渐进的原则。先通过改变训练数据的权重分布,训练出一系列具有粗糙规则的弱个体分类器,再基于这些弱分类器进行反复学习和组合,构造出具有精细规则的强分类器。
AdaBoost 要解决两个主要问题:训练数据权重调整的策略和弱分类器结果的组合策略。
-
在训练数据的权重调整上,AdaBoost 采用专项整治的方式。在每一轮训练结束后,提高分类错误的样本权重,降低分类正确的样本权重。因此在下一轮次的训练中,弱分类器就会更加重视错误样本的处理,从而得到性能的提升。这就像一个学生在每次考试后专门再把错题重做一遍,有针对性地弥补不足。虽然训练数据集本身没有变化,但不同的权重使数据在每一轮训练中发挥着不同的作用。
-
在 AdaBoost 的弱分类器组合中,每一轮得到的学习器结果都会按照一定比例叠加到前一轮的判决结果,并参与到下一轮次权重调整之后的学习器训练中。当学习的轮数达到预先设定的数目 T 时,最终分类器的输出就是 T 个个体学习器输出的线性组合。每个个体学习器在最终输出的权重与其分类错误率相关,个体学习器中的分类错误率越低,其在最终分类器中起到的作用就越大。但需要注意的是,
所有个体学习器权重之和并不必须等于 1。 -
算法的特点:随着训练过程的深入,弱学习器的训练重心逐渐被自行调整到的分类器错误分类的样本上,因而每一轮次的模型都会根据之前轮次模型的表现结果进行调整,这也是 AdaBoost 的名字中“自适应”的来源。
优缺点
优点
- Adaboost是一种有很高精度的分类器。
- 可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
- 当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。
- 简单,不用做特征筛选。
- 不用担心过拟合。
缺点
- 在Adaboost训练过程中,Adaboost会使得难于分类样本的权值呈指数增长,训练将会过于偏向这类困难的样本,导致Adaboost算法易受噪声干扰。
- Adaboost依赖于弱分类器,而弱分类器的训练时间往往很长。
你知道的越多,你不知道的越多。
最后
以上就是瘦瘦美女最近收集整理的关于机器学习常用算法分享KNN逻辑斯蒂函数决策树朴素贝叶斯支持向量机自适应提升算法的全部内容,更多相关机器学习常用算法分享KNN逻辑斯蒂函数决策树朴素贝叶斯支持向量机自适应提升算法内容请搜索靠谱客的其他文章。








发表评论 取消回复