什么是数据结构?下面是维基百科的解释
数据结构是计算机存储、组织数据的方式数据结构意味着接口或封装:一个数据结构可被视为两个函数之间的接口,或者是由数据类型联合组成的存储内容的访问方法封装
我们每天的编码中都会用到数据结构,因为数组是最简单的内存数据结构,下面是常见的数据结构:
- 数组(Array)
- 栈(Stack)
- 堆(Heap)
- 队列(Queue)
- 链表(Linked List)
- 树(Tree)
- 图(Graph)
- 散列表(Hash)
其中,栈和队列是一种类似数组的数据结构,它们之间的区别仅仅体现在数据项的插入和移除的方式上。链表、树和图则是另一种节点与节点之间维持引用关系的数据结构。散列表(也称哈希表)依赖散列函数来保存和定位数据。
就复杂性而言,栈和队列是最简单的两种,并且二者都可以通过链表来进行构造。树和图则是最复杂的,因为它们继承了链表的概念。散列表需要利用这些数据结构来可靠地执行。就执行效率而言,链表在对数据的记录和排序上表现最好,同时散列表也更加擅长查找和提取数据。
栈、堆、队列
详见
集合
一种无序且唯一的数据结构。
ES6中有集合 Set类型
字典
与集合类似,一个存储唯一值的结构,以键值对的形式存储。
js中有字典数据结构 就是 Map 类型
链表
多个元素组成的列表,元素存储不连续,通过 next 指针来链接, 最底层为 null。
就类似于 父辈链接关系 吧, 比如:你爷爷的儿子是你爸爸,你爸爸的儿子是你,而你假如目前还没有结婚生子,那你就暂时木有儿子。
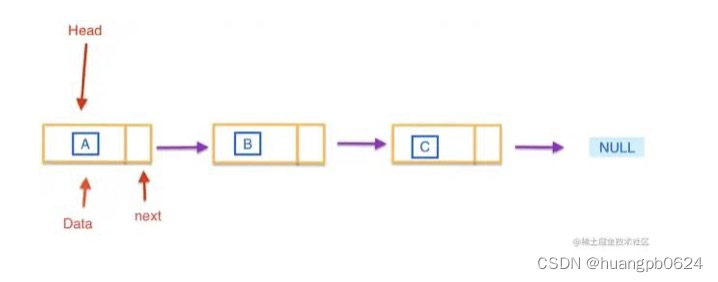
js中类似于链表的典型就是原型链, 但是js中没有链表这种数据结构,我们可以通过一个object来模拟链表
const a = {
val: "a"
}
const b = {
val: "b"
}
const c = {
val: "c"
}
const d = {
val: "d"
}
a.next = b;
b.next = c;
c.next = d;
// const linkList = {
// val: "a",
// next: {
// val: "b",
// next: {
// val: "c",
// next: {
// val: "d",
// next: null
// }
// }
// }
// }
// 遍历链表
let p = a;
while (p) {
console.log(p.val);
p = p.next;
}
// 插入
const e = { val: 'e' };
c.next = e;
e.next = d;
// 删除
c.next = d;树
树(Tree)类似于链表,但不同的是树在不同的层级下引用多个子节点。换句话说,每个节点最多只能有一个父节点。文档对象模型(DOM)就是这样的结构,有一个根节点 html, html 中的分支都包含在 head 和 body 节点中,然后进一步细分为所有我们熟悉的 HTML 标签。在 JS 内部,原型继承和与 React 组件的组合也会产生树结构。当然,React 中作为代表内存中 DOM 结构的虚拟 DOM,同样也是一个树结构。
二叉树是一种比较特殊的树,因为二叉树中的每个节点最多只能有两个子节点。左子节点的值必须小于或等于其父节点的值,同时右子节点的值必须大于其父节点的值。以这种方式组织和平衡树结构,由于每次迭代中我们可以忽略二分之一的分支,所以就可以在对数时间内查找任意值。插入和删除操作同样也在对数时间内完成。除此之外,可以轻松地最左叶节点中和最右叶节点中,分别找到最小值和最大值。
对树的遍历可以以垂直或水平过程进行。深度优先遍历(DFT)是在垂直方向上,其递归算法相较于迭代算法来说更加优雅。可以通过前序、中序、后序来遍历节点。如果需要先访问根节点,然后再检查子节点,应该选择前序遍历。如果需要先访问子节点,然后再检查根节点,则应选择后序遍历。顾名思义,中序遍历就是按照左、根、右的顺序遍历节点。这些性质使得二叉查找树非常适合排序。
广度优先遍历(BFT)是在水平方向上,其迭代算法相较于递归算法来说更加优雅。广度优先遍历需要使用队列来跟最每次迭代的所有子节点。但是,此类队列所需的内存可能并不小。如果树的形状更宽,则广度优先遍历是更好的选择。同样,广度优先遍历在任何两个节点之间采用的路径是最短的路径。
图
如果一棵树可以拥有多个父节点,那么它就变成了一张图(Graph)。在图中连接每个节点的边,可以是有方向的,也可以是无方向的,可以是有权重的,也可以是无权重的。既有方向也有权重的边类似于向量。
社交网络和互联网本身也是图。自然界中最复杂的图是我们人类的大脑。现在,我们试图将神经网络复制到机器中,期望使机器具有「超级智能」。
散列表
散列表是一种包含键值(Key-Value)对的,类似字典的数据结构。在内存中的每对键值都通过散列函数(Hash Function)来确定其位置,散列函数接受键(Key)作为参数,并返回该键值对应当插入或读取的地址。如果两个或者多个键返回的地址是相同的,则会发生冲突(Collision)。为了健壮起见,getter 和 setter 应该预见到这些事件,以确保可以恢复所有的数据,并且不会覆盖任何数据。通常,可以使用链表来实现最简单的解决方案,或者搞一个超大的表也是可行的。
参考:[译] JavaScript 中的数据结构:写给前端软件工程师 - 掘金
最后
以上就是酷酷战斗机最近收集整理的关于js数据结构的全部内容,更多相关js数据结构内容请搜索靠谱客的其他文章。








发表评论 取消回复