迁移学习,简单的说,就是能让现有的模型算法稍加调整即可应用于一个新的领域和功能的一项技术。这个概念目前在机器学习中其实比较少见,但其实它的潜力可以相当巨大。杨强教授在刚刚结束的CCF-GAIR上的演讲中曾提到一个愿景——利用迁移学习,即使是自身没有条件获得大量训练数据的小公司也可以按照自己的需要应用大公司训练出来的模型,从而普及AI的应用。
在目前大家都在努力提高人工智能应用通用性的大背景下,迁移学习的崛起之势已经比较明显。不过杨强教授其实早在2009年之前就开始研究迁移学习了——那时他是国内为数不多的研究迁移学习的学者之一。2010年,杨强教授参与在IEEE Transactions on knowledge and data engineering上发表了一篇详细解释了迁移学习的论文:A Survey on Transfer Learning,其中对迁移学习的概念、与机器学习几个传统方法的区别以及一些常用的迁移学习方法都做出了解释。让我们选取论文中一些比较有代表性的部分(节选+精编),为大家展示这个机器学习新趋势的方法与传统方法到底有什么区别。
A Survey on Transfer Learning
摘要
许多机器学习和数据挖掘算法都会基于一个假设:训练数据和未来将要处理的数据都处在相同的特征空间,并且有着相同的分布规律。但是,在现实世界的很多应用中,这个假设很可能是不成立的。比如,我们经常面临需要在一个领域内完成一项分类任务,却只在另一个领域中有足够的训练数据的情况。两者的数据可能有着不同的特征空间或者遵从不同的数据分布规律。在这种情况下,进行一次成功的知识迁移能极大的提升学习效果,从而避免大量繁重的数据标记的劳动。在最近几年中,迁移学习作为一种新的学习框架被提出来用于解决这个问题。这篇文章聚焦于分类回顾现有的用于解决分类、回归和聚类问题的迁移学习项目的研究进程。在这篇文章中,我们还会讨论迁移学习和其他相关的机器学习技术比如领域适应、多任务学习和样本选择偏差,以及协变量转换。我们也会探索一些未来在迁移学习研究上比较有潜力的方法。
介绍:
数据挖掘和机器学习技术已经在知识工程领域包括分类、回归和聚类等取得了相当大的成功。但是,当数据分布规律改变的时候,大多数统计模型需要使用新的训练数据来重建。在现实世界的许多应用中,这样做付出的代价是非常大的,甚至是不可能的。所以,减小重新收集训练数据的必要性和工作量就成了非常有必要的一件事。也就是说,在不同任务领域间的知识转换或迁移学习能取得令人满意的成效。
在许多知识工程案例中,迁移学习确实是很有用的,比如在网页分类任务中,新创建的网页的数据特征和分布可能同之前用来训练的网页不同,因此这时就会需要用到迁移学习技术来转移模型。
如果训练数据很容易过期,即数据的分布规律在不同的时间段可能会不同,这时也会需要迁移学习来使模型不会失效。比如在室内WiFi定位问题——一种根据收集到的使用者的WiFi使用数据来检测使用者当前位置的技术上,但是,由于WiFi的信号强度完全可能随时间、使用者的设备和一些其他因素的变化而变化,一个静态的模型显然也无法应对这个问题。
第三个例子是:情感分类的问题。在这个问题中收集数据的方法是收集大量设备使用者的叙述并将其分类,但是由于不同产品产生的数据分布结果可能会非常不同,如果想要使用传统方法有足够好的分类结果,可能需要针对不同的设备建立不同的模型,然而这样做的代价显然太大了。所以最好有一种能建立通用于各设备间的模型的方法。
迁移学习历史简介、以及与传统方法的比较:
传统数据挖掘和机器学习算法可以使用用之前的标记过或未标记过的数据训练出来的统计学模型做出对未来数据的预测。半监督学习可以通过使用少量标记的数据和大量未标记的数据训练的方法解决可用来建立可用分类器的数据量过少的问题。用来处理不完美的训练数据的监督学习和半监督学习的变种方法已经被详细研究过了。也得出了许多不错的成果,但是它们中的很多都基于标记和未标记的数据都有相同的分布规律。而与之相比,迁移学习则允许用来训练和测试的数据集的领域、任务和分布规律有所不同。在现实世界中,我们观察到了许多迁移学习的案例。比如,我们认知苹果的过程可能对我们认知梨子也有帮助。类似的,学习弹电子琴可能会对学习弹钢琴也有很大帮助。展开对迁移学习的研究,是因为我们发现了人类拥有这种使用之前学到的知识来更快或更好的解决新问题的能力的事实。机器学习中研究迁移学习的根本动力来源于一次在研讨会上主题为“学会学习”的,以开发一种可以保持并重新利用现有知识的“终极”机器学习方法的讨论。
对迁移学习的研究从1995年开始兴起,在换了一个又一个名字的同时也开始吸引越来越多的注意力:学会学习(learning to learn)、终身学习(life-long learning)、知识转移(knowledge transfer)、归纳转移(inductive transfer)、多任务学习(multi-task learning)、知识巩固(knowledge consolidation)、上下文学习(context-sensitive learning),基于知识的归纳偏差(knowledge-based inductive bias),元学习(meta learning)以及增值/累积学习。在这其中,一个与迁移学习密切相关的技术是多任务学习框架,这个框架的目标是同时学习多个任务,哪怕它们之间是互不相同的。一个典型的多任务学习的实现方法是发现这些各自独立的任务之间的一些(潜在的)共同规律。
2005年,美国国防部高级研究计划局(DARPA)的信息处理技术办公室(IPTO)发布的通告(BAA)让迁移学习有了一个新的使命:一个能认知并且将在之前的任务中学习到的知识应用到新的任务中去的系统。在这个定义下,迁移学习的目标即为从一个或多个任务中提取出知识并应用到另一个目标任务中去。与多任务学习更注重于同时学习所有来源相比,迁移学习更关注于目标任务。在迁移学习中源和目标的关系不再对等了。
图1展示了传统技术和迁移学习之间的处理过程的区别。我们可以看到,在高质量训练数据不够的时候,传统机器学习技术更多是通过随机测试来从任务中学习,而迁移学习则是通过从之前的任务中学习来训练。
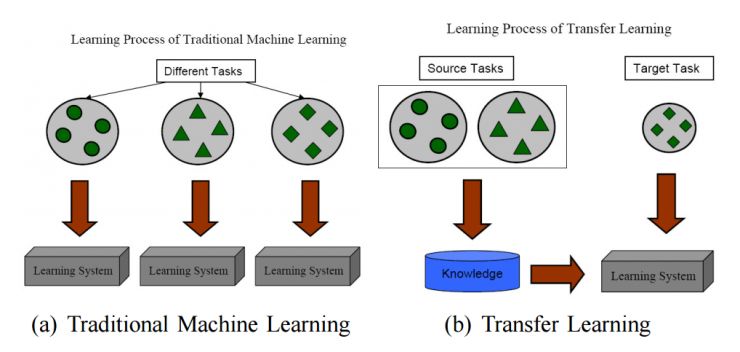
如今,迁移学习方法已经在几个高端领域中得到了应用。尤其是在数据挖掘、机器学习和其应用中。
几个迁移学习的分类表格、图表
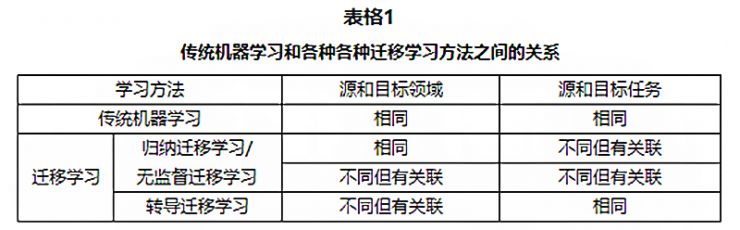
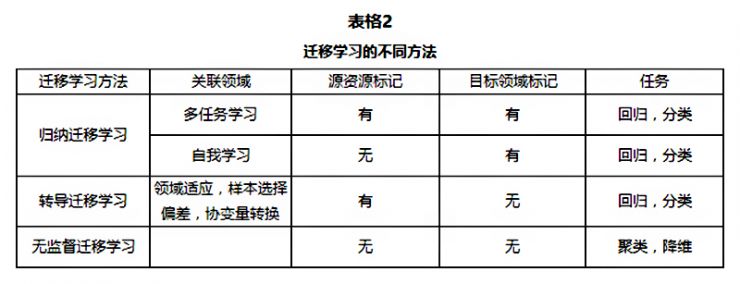
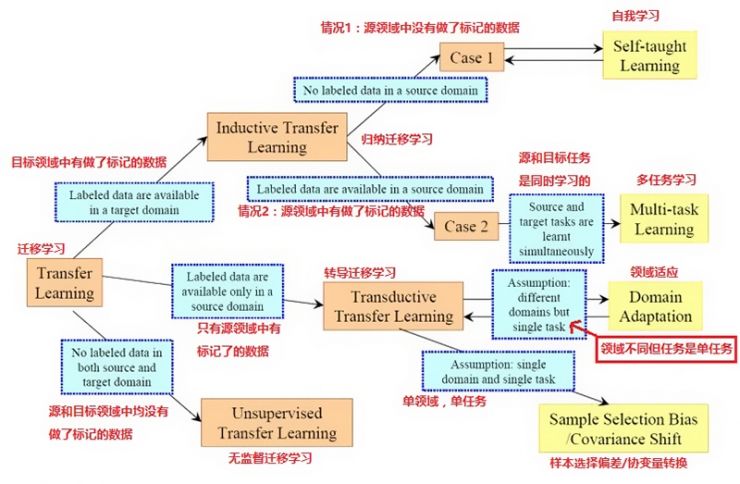

结论:
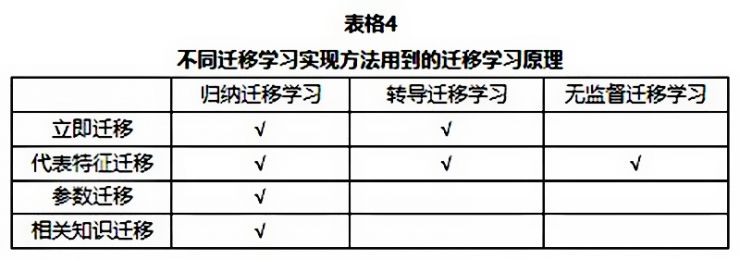
在这篇文章中,我们回顾了几种目前迁移学习领域的趋势:迁移学习有三种不同的类型:归纳迁移学习、转导迁移学习和无监督迁移学习,之前的工作大多数聚焦于前两类。不过在未来无监督迁移学习可能会得到越来越多的注意。不仅如此,具体实现的迁移学习的方法还能按照“迁移了什么”来分为四类:立即迁移、代表特征迁移、参数迁移和相关知识迁移。前三种的环境中的数据满足i.i.d假设,而最后一种则关注与迁移学习中的相关数据。这些方法大多数都假设选定的源领域和目标领域是有关联的。
在未来,仍有几个重要的问题需要在研究中加以解决。第一:如何避免消极转移仍然是个悬而未决的问题,目前的许多迁移学习算法都假设源领域和目标领域有着某种程度的关联。但是如果这个假设不成立的话,就有可能会发生消极转移的问题。着可能会导致转移后的算法会表现得比转移前还差。因此这是迁移学习中非常有必要解决的一个问题。目前要避免这种情况的发生,我们要先对源领域到目标领域的可转移性进行评估。要定义两个领域间的可转移性,我们可以用相应的方法进行测量,也需要一个测量源领域和任务之间相似性的方法。而一个与之相关的问题是:如果一个领域的整体不能用于迁移学习,我们是否仍然有机会转移领域中的一部分用来帮助新领域中的学习?
另外,大部分现有的迁移学习算法都聚焦于提升不同源和目标领域或任务的分布之间的一般化迁移方法。为了做到这一点,他们会假设源领域和目标领域的特征空间是相同的。但是在很多实际应用中,我们都可能会需要在拥有不同特征空间的源领域和目标领域间进行转移,而且有可能需要从多个这样的源领域中同时转移。我们管这种迁移学习叫做“多相迁移学习”(heterogeneous transfer learning)。
最终,目前的迁移学习技术主要在变量有限的小规模应用中使用,比如说像基于传感器网络的定位,文字分类和图像分类问题等,在未来迁移学习将被广泛应用于解决其他有挑战性的应用中,比如视频分类、社交网络分析和逻辑推理等。
完美的迁移学习是否也是AI的一种?
正如前文所说,目前的AI的研究,大多数都是以让AI具备更强大的适应能力、乃至具备真正的学习能力为目的而进行的。而迁移学习正是一种能在很大程度上达到这个目的技术。想象一下,如果一个AI具备了同人一样的学习能力,能将在旧事物上学到的经验完美应用于新事物,那即使这个AI一开始很笨,它应该也能通过不断的学习变得越来越聪明。这是否也是一种智能呢?
不过无论怎么说,迁移学习看起来都是一种极具潜力的方法。相信能在不远的将来大放异彩。
最后
以上就是苗条保温杯最近收集整理的关于迁移学习简介的全部内容,更多相关迁移学习简介内容请搜索靠谱客的其他文章。








发表评论 取消回复