Homogeneous transfer learning: 特征空间相同
基于样本的迁移学习:
CP-MDA(probablity based multi-source domain adaptation):通过矫正源域和目标域条件分布的差异—-假设目标域中有一部分有标签数据是可用的。主要思想是使用源域分类器组合(这里的源域是一个或者多个)给目标域中无标签的数据打标签,第一步是为每一个独立的源域建立一个分类器,然后再每一个源域和目标域之间的条件分布中为每一个分类器寻找一个权重值作为源域与目标域接近程度的函数。加权组合的源域分类器通过累加来建立一个学习任务给无标签的目标域数据打上一个伪标签。最后,目标学习器根据有标签的目标域数据和伪标签的目标域数据进行训练。CP-MAD可能更偏向于是一个基于参数的迁移学习策略。
2SW-MDA(two stage weighing framework for multi-souce domain adaptation):该方法是CP-MADA的升级版,它既处理源域和目标域中条件分布的差异,同时还处理边缘分布的差异,该方法可以不使用带标签目标数据,然而,如果目标域中的标签可用的话也可以使用。在这个方法中,会基于源域与目标域之间边缘分布差异为每个源域计算出一个权值。第二步:源域的权值会被调整作为一个关于CP-MDA方法中获取的条件分布差异的函数。最后,目标分类器基于经过加权的源域样本和任何可用的目标域带标签数据进行学习。这个方法的新奇之处在于计算出源域的权值作为一个条件概率函数。
基于特征的迁移学习策略:
Daumé H III. Frustratingly easy domain adaptation. In: Proceedings of ACL. 2007. p. 256–263:该方法只需要十行Perl 脚本和带标签的源域数据和一部分有标签的目标域数据。在迁移学习环境中,存在这样一种情况,在源域中的一个特征也许对于目标域来说会有着不同的意义,这个问题对应于context feature bias(导致源域和目标域之间条件分布不同的原因)的问题。为了解决context feature bias,作者提出了一种方法:使用初始特征集的三次重复拷贝来扩大源域和目标域的特征空间,初始特征集的三次副本在被扩大的源特征空间中代表一个共同特征集、一个特定的源特征集和一个特定的目标特征集,这三个初始特征集一般初始化为0。另外,在被扩大的目标域特征空间中也使用同样的方法,对初始特征集拷贝三次,分别对应一个共同特征集、一个特定的源特征集和一个特定的目标特征集。通过执行特征扩充,这些特征空间被重复了三次。在这个特征扩充结构中,一个分类器为扩充的特征集学习单独的特征权重,以帮助矫正任何特征偏差问题。使用一个文本文档示例进行说明,文档通过词袋建模,像” the “这样一个普通的单词可能会被分配到一个高权重给共同特征集,”monitor”这样一个在源域和目标域中有差异的词可能会被分配一个高权重到对应域的特征集,并且允许最后的分类器去学习优化特征权重。在论文中的实验里,大量不同的自然语言处理应用被测试。有意思的是,当目标域和源域非常接近时,这种方法的表现力不太理想,这可能是因为当源域与目标域十分相似的时候,重复的特征集代表的是不相关的信息或者是噪声信息。
Multiple kernel learning是在传统机器学习算法中常用的一种技术,多内核学习允许以计算有效的方式学习最佳核函数。Duan[27]提出了一种方法来实现一个MKL框架用于迁移学习环境中,叫做domain transfer learning multiple kernel learning(DTMKL)。和学习一个核不同,多核学习设定的核是由多个预先定义的基核的线性组合构成。最终分类器和核函数会被同时学习,这样会在使用有标签数据进行核学习处理的时候有好处。Pan[82]和Huang[51]对这种方法进行了一种提升,他们使用了一个二阶的方法。最终分类器的学习过程会最小化结构风险函数,以及使用最大均值差异(maximum mean discrepancy)度量域间边缘分布。在分类器学习过程中,会为没有标签的目标数据寻找一个伪标签来使用这部分数据。伪标签会被作为基础分类器组合的权重,这些基础分类器使用带标签的源域数据训练。一个正则项会被加入到这个优化问题中,以保证对于无标签的目标数据,最终目标分类器和基础分类器的预测值是接近的。
Long[69]提出了一个联合域适应方法,旨在同时矫正带标签源域和没有标签的目标域中的边缘分布和条件分布差异。该方法中,主要成分分析(PCA)被用于优化以及降维上。为了解决域间边缘分布的差异,同样使用了最大平均差异距离度量的方式来计算边缘分布的差异,不同的是,最大平均差异度量被集成到PCA优化算法中。该方法的下一步是矫正条件分布差异,这一步需要带标签的目标数据。由于目标数据是无标签的,伪标签会被使用到,伪标签通过带标签的源域数据学习到一个分类器来生成。最大平均差异距离度量会被优化,以测量出(源域和目标域)条件分布之间的距离,然后被集成到PCA优化算法中以最小化条件分布。最后,使用经过修改的PCA算法的特征判定来训练出最终目标分类器。
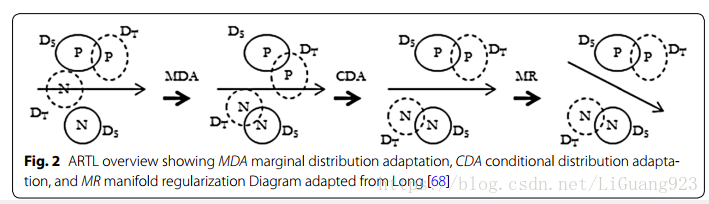
Long[68]针对于源域数据有标签,目标域数据无标签的场景提出了一个基于迁移学习框架的适应性正则化方法(Adaptation Regularization based transfer learning (ARTL) framework)。该迁移学习框架提出矫正源域和目标域之间的边缘分布差异、矫正域间的条件分布差异以及通过多种正则化处理以提高分类器(超平面SVM)性能。该方法的进程如下图所示,ARTL将通过同时执行结构风险最小化、优化域间边缘和条件分布以及优化边缘分布的多样一致性来学习一个分类器。ARTL使用了上一种方法[69]给目标数据寻找伪标签的方法来解决条件分布差异的问题。该方法和上一种方法不同的是当最小化域分布差异的同时,也学习最终分类器,Long声明这是一种更优的解决方案。不幸的是,上一种方法没有包含在该方法设计的实验中。
基于特征的对称迁移学习:
Pan[87]提出了一种特征转换的方法用于域适应,叫做迁移成分分析(transfer component analysis TCA),该方法不需要使用带标签的目标域数据。该方法的目标是为了发现共同潜在特征(common latent features)。这些共同潜在特征对于源域和目标域来说有着相同的边缘分布,同时还保留有初始域数据的内在结构。这种潜在特征通过将源域和目标域映射到再生希尔伯特核空间学习得到,使用最大平均差异作为边缘分布度量标准。一旦潜在特征被发现,就可以使用传统的机器学习方法训练最终目标分类器。Pan[83]还提出了一种谱特征对齐迁移学习方法(spectral feature alignment SFA),通过发现一种新的特征代表来解决源域和特征域之间的边缘分布差异。SFA方法假设有丰富的源域数据和一部分带标签目标域数据。SFA方法识别出特定的域特征和域独立特征,然后使用域独立特征作为桥梁来搭建一个在特定域和域独立特征之间存在共同关系的双边图模型。如果图中显示出两个域的特定域特征连接到共同的域独立特征时,那么就有较高的机会使得这两个特定域特征对齐。然后使用基于图谱理论的谱聚类算法在双边图上来对齐特定域特征和域独立特征到一个代表新特征的聚类集合中。这些集合被用来减小源域和目标域这两个特定域特征之间的差异。所有的数据样本都被投影到新的特征空间中,然后最终目标分类器使用这些新特征代表来进行训练。SFA算法是一种通讯学习(correspondence learning),把域独立特征作为关键点特征。SFA方法比较适合用在文本分类,其中使用词袋模型来定义特征,对于文本分类来说,在所有的域中将会经常出现域独立的词,然后特定域的词将会经常出现在特定的域中。这经常涉及到频率特征偏差(frequency feature bias),频率特征偏差是导致边缘分布差异的原因。比如,特定域单词”sharp”经常出现在源域中而不出现在目标域中,”hooked”单词经常出现在目标域而不出现在源域中。但是这些单词都会连接到一些同样的域独立单词上(比如”good”或者”exciting”)。更进一步说,对当单词”sharp”或者”hooked”出现在文本样本时,他们的标签是一样的。这种思想将这两个特征(在这个例子中是”sharp”和”hooked”)结合起来以至于形成一个新的、单一不变特征。
Glorot[41]提出了一个深度学习算法来进行迁移学习,叫做堆栈去噪自编码器(stacked denoising autoencoder),该方法用于解决边缘分布差异,使用带标签的源域数据和不代表签的目标域数据。深度学习算法学习到两个数据域之间的不变中间量,然后通过这个不变中间量来找一个共同特征集。算法的第一步使用源域和目标域中的无标签数据训练一个栈去噪自编码器。这个编码器将把输入空间转化以发现共同不变的潜在特征空间(common invariant latent feature space)。下一步是使用已转换的潜在特征和标记的源数据来训练分类器。在论文中,作者将该方法用于文本评论情感分析,baseline为SVM,以及和上面的算法进行比较,作者的方法性能表现最好。
Gong[42]的论文中提出了一种域适应技术,叫做geodesic flow kernel(GFK),这种方法通过找到一个低维的特征空间来减少边缘分布差异,使用的数据域为带标签的源域以及不带标签的目标域。为了实现这一点,使用源和目标输入特征数据构建测地线流内核,测地线流内核投射位于地理流动曲线上的大量子空间。地理流动曲线代表了源域和目标域之间统计学和几何学上的差异量。通过选择那些域不变的地理流动曲线特征得到的测地线流内核学习一个分类器。Gong通过估计、微调参数以及提高计算效率,直接提升了Gopalan的工作。另外,一个域等级度量(rank of domain ROD)被提出用来估计在众多源域之间,哪一个源域是最能和目标域匹配的。ROD是一个关于在域之间几何对齐,以及被映射的源域和目标域子空间之间KL散度的函数。该方法被用在图像分类上,选用没有使用迁移学习的方法作为baseline,另外,与Gopalan的方法进行了对比,方法中使用了一个最近邻分类器,效果分别是Gong>Gopalan>baseline。论文中还发现:被测试的不同源域和目标域对之间的ROD测量值与实际测试结果具有高度相关性,这意味着与ROD测量值更相关的域具有更高的分类准确度。
Shi[106]提出discriminative clustering process(DCP)用来均衡源域和目标域的边缘分布。DCP被用于发现一个共同潜在的域不变特征空间,并同时学习最终目标分类器。该方法的动机假设是两个域中的数据形成对应到唯一类标签的明确定义的集群,如果源域中的集群共享相同的标签,则它们在几何上接近目标集群。通过聚类,源域标签可以被用来估计目标数据的标签。一阶解决方案被制定为最小化边缘分布差异,同时使用一个最近邻分类器来最小化目标域中的预测分类误差。文中设计的实验针对于物体识别和情感分类。通过和没有使用迁移学习的方法以及一些使用了迁移学习的方法,比如上面提到的Pan[87],Gopalan[43]等的方法进行对比。在物体识别的六项对比测试中,Shi的方法有五项的表现都是最好的。而在文本分类测试中,Shi的方法在所有项中都表现的最好。值得注意的一点是,在所有的测试中,baseline的方法(未使用迁移学习的Weinberger的方法)表现的比Pan和Gopalan的方法要好。Pan和Gopalan方法都是两阶段域自适应过程,其中第一阶段减少域之间的边缘分布,第二阶段训练具有适应域数据的分类器。这个论文中提供了一个假说,即:二阶的解决方案实际上对于迁移学习来说可能是不利的(导致了负迁移)。该论文中呈现的一阶学习处理是一种新奇的方法。二阶迁移学习处理创建了低效率学习器的假说与Gopalan和Pan以及其他之前被展示的结果不一致。
卷积神经网络在传统数据挖掘环境中有着很成功的应用。然而,CNN需要很大数量的带标签数据,使得网络变得有效,然而数据集中的标签也可能是不可用的。由Qquab[81]提出的论文中阐述了一种通过带标签源域数据训练的CNN,然后提取出CNN的内部层(中级特征表示)给目标学习器的迁移学习方法。这种方法被称为迁移卷积神经网络(TCNN)。为了矫正源域和目标域之间的更进一步的分布差异,在目标CNN学习器中加入了一个适应层,该适应层通过有限带标签的目标数据训练。在论文中,作者设计的实验针对于物体图像识别分类。
基于参数的迁移学习
Tommasi[114]处理了这样一种迁移学习环境,目标数据中有一部分带标签数据,有多个带标签的源域并且每一个源域都对应于一种特别的类。在这种个情况中,每一个源域都可以建立一个二分类学习器来预测标签。作者的目的是建立一个目标二分类器对一个新的类进行预测,通过最小化带标签的目标数据和通过多个源域学习器进行的知识迁移。在文中,通过从每一个源域学习器中迁移出SVM超平面信息给目标学习器。为了最小化负迁移的影响,从每个源域中迁移给目标域的信息都会被权重化(例如:最相关的源域信息能有最高的权重),权重通过Cawley定义的省略一个过程来确定。Tommasi的方法也被叫做多模型知识迁移(multi-model knowledge transfer MMKT)。作者设计的实验针对于图像识别,测试的方法中包括了一个与Tommas相同的方法,但是所有权重都相同,以及一个baseline方法,随着带标签目标样本的数量增大,Tommasi的方法和平均权重的方法效果慢慢的趋于相同。这是因为随着目标数据的增多,负迁移的不利影响也变少了。这个结果也显示出了Tommasi的方法对于不相关源数据迁移中产生的负迁移受到更小的影响。
由Duan[28]提出的Domain Selection Machine(DSM)方法与消费者视频中的事件识别应用紧密相关。事件识别是在被给的视频中预测一个特定的事件或者topic发生的概率处理。在这样的场景下,目标域是无标签的,源域信息通过网络搜索找到的注释图像中获得。例如,Photosig.com中图像事件”show”的文本查询代表了一个源域,然而在Filckr.com中一个同样的查询却代表了另一个不同的源域,DSM基于这种情况被提出来。对于每个独立的源域,通过使用SIFT图像特征建立一个SVM分类器。最终的目标分类器由两部分组成,一个部分是对源域分类器输出进行加权,这些分类器的输入是输入视频中关键帧的SIFT特征。第二部分是一个学习函数,这个学习函数的输入是来自输入视频的时空特征,目标域数据中的标签通过源分类器的加权进行估计得到,然后这个学习函数通过这些有标签(伪标签)的目标域数据训练。为了讨论来自不相关源域中负迁移的影响,通过使用一个迭代优化算法(迭代地解决目标决策函数以及源域选择向量)来选择出最相关的源域。实验设计针对于视频中的事件识别,baseline方法为:在每个源域上训练一个独立的SVM分类器,然后将这些分类器平等的结合起来。同时还与之前提到的一些迁移学习方法进行对比,Duan的方法表现最好。除了作者的方法之外,其他的方法效果都比较接近,这意味着使用迁移学习的方法并不比baseline方法要好很多。
Yao[138]的论文首先提出了一种基于实例的转移学习方法,然后是一种分离的基于参数的转移学习方法。在迁移学习过程中,如果源域和目标域没有足够相关,那么就有可能会发生负迁移。由于在任何一个独立的源域和目标域之间是很难测量它们之间的相关性的,Yao提出使用一个提升方法尝试最小化不相关源域负迁移的影响来进行知识迁移。这个提升方法需要一些带标签的目标域数据。Yao有效的扩展了Dai[21]的工作(TrAdaBoost)通过扩展迁移提升算法到多个源域中。在TrAdaBoost算法中,在每个提升迭代期间,一个所谓的弱分类器通过之前权重化的样本数据进行训练。然后,错分类的源域样本重要性降低,而错误分类的目标域数据的重要性却提升。在多源TrAdaboost算法中,开始的每一步迭代都为每一个源域和目标域组合找到一个弱分类器,然后通过找到最小化目标分类误差的那个弱分类器,作为该迭代选择的最终弱分类器。样本重新加权步骤和TrAdaBoost中的一样。一个alternative multi-source boosting方法提出从源域到目标域中迁移出学习器内部的参数信息。这个算法首先,通过在每个源域中执行AdaBoost从每个单独的源域中获取候选弱分类器。然后AdaBoost在有标签的目标域上执行,在每次boosting迭代中,从这些候选弱分类器(前面步骤产生的)中选出一个弱分类器,选出的弱分类器在使用有标签目标域数据时有着最小的分类误差。
基于关系的迁移学习
Li[62]提出了一个特别的方法用来把一个文本文档分类到三个个类别中的一个(例如:情感,主题,或者其它)。在这种场景里,一个特定主题上存在标记的文本源域,在不同的主题上存在未标记的文本目标域。主要思想是在源域和目标域之间,情感词汇保持不变。通过学习语法和源域的句子结构模型,建立一个关系模型。情感词汇表现为在源域和目标域之间的一个共同连接或者桥梁。一个双边词汇图被用来表示和评价句子结构模型。一个引导算法被用来迭代的在两个域之间建立一个目标分类器。引导过程从定义种子开始,种子指的是那些和目标有高度匹配的源域样本。然后通过这些种子信息和被提取的目标信息训练一个交叉域分类器(在第一次迭代中没有目标信息)。分类器被用来预测目标标签,然后最高置信度的目标样本被选出来重构双向词汇图。双向词汇图用来选择一个新的目标样本,这个新的目标样本会被添加到种子列表中。引导过程会被限定迭代次数,在引导过程中学习到的交叉域分类器现在可以被用来预测目标样本。这种方法被称为Relational Adaptive bootstraPping(RAP)方法。但是该算法与其潜在的文本应用紧密相关,这使得它很难泛化到其他非文本应用上。
基于样本和参数的迁移学习
Xia[132]提出了一个两个步骤的方法来处理边缘分布差异和条件分布差异,被称为 the sample selection and feature ensemble(SSFE)。使用经过修改的主成分分析进行样本选择,用来选取带标签的源域样本,使得源域和目标域的边缘分布均衡。下一步,使用一个特征集合,尝试解决条件分布差异。定义了四个单独的分类器,对应于名词,动词,副词、形容词等的词性。这四个分类器只使用了与该部分对应的特征。训练数据是在前一步样本选择中选出的一部分的有标签目标数据和有标签的源域数据。这四个分类器使用有限的带标签目标数据被权重化为一个关于最小化分类误差的函数。四个分类器的加权输出被用来作为最终目标分类器。
对于同构迁移学习的讨论
以上调查的同构迁移学习工作阐述了很多不同的特点和特性。那么哪一个同类迁移学习方法对于某个特定的应用来说是最好的呢?在选择方法的一个重要的评估特性是在被给的源域和目标域之间的差异是哪种类型。以上调查的解决方案通过矫正边缘分布差异和条件分布差异或者两个都有来处理域适应。Duan [27], Gong [42], Pan [87], Li [62], Shi [106], Oquab [81], Glorot [41], and Pan[83]主要集中在解决边缘分布差异。Daumé [22], Yao [138], Tommasi主要集中在解决条件分布差异上。最后,Long [68], Xia [132], Chattopadhyay [14], Duan [28], and Long集中在既矫正边缘差异又矫正条件分布差异。校正源域和目标域之间的条件分布差异可能是有问题的,因为迁移学习环境的本质是要具有最小量的带标签目标数据。为了补偿有限的带标签目标数据,最近的很多迁移学习解决方案给无标签的目标数据创建了伪标签来促进条件分布矫正处理。为了进一步帮助决定哪一个方案对于具体的迁移学习应用来说是最好的,表2的信息可以被用来与想要应用的环境匹配相应特性选择迁移学习方法。如果需要应用的情形中包含了多个源域并且这些源域之间并不是相互均匀分布的,那么选择一个防止负迁移效果较好的方法可能会更有利一些。迁移学习最近的一个发展趋势是同时处理条件和边缘分布差异。与两阶段过程的迁移学习方法相比,另一个新兴的解决方案是实现一阶过程的迁移学习。在Long [68], Duan [27], Shi [106], and Xia [132]最近的研究工作中,采用一阶段过程,在学习最终分类器的同时进行域适应。在二阶过程的迁移学习中,首先执行的是域适应处理,然后独立的学习最终分类器。Long提出一阶的解决方案可以提升性能,因为域适应和分类同时求解建立了相互强化。调查的同构迁移学习并没有具体的应用在大数据解决方案中,然而,这并不妨碍将他们应用在大数据环境中。
Heterogeneous transfer learning
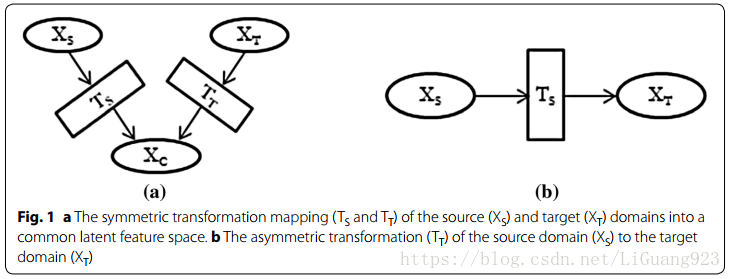
异构迁移学习的场景是:源域和目标域的特征空间不同。异构迁移学习在很多应用中是有益的。本节介绍的异构迁移学习应用场景包括图像识别,多语言文本分类,单语言文本分类,药物疗效分类,人类活动分类和软件检测分类。异构迁移学习也可直接应用到大数据环境中。随着大数据的存储资源库变得越来越多,存在一种需求去使用这些富足的资源来进行机器学习任务,以避免新数据采集上时间和潜在的花费。如果存在一个派生于目标域的可用数据集有着与另一个目标数据集(同样从同一个目标域中派生出的)不同的特征空间,那么异构迁移学习可以被用来桥接特征空间差异性并且为这样的目标域建立一个预测模型。异构转移学习仍然是一个相对较新的研究领域,大多数涉及该主题的工作已在过去5年中发表。从一个高层次的视角来看,存在两个主要的方法来解决异构特征空间差异。第一种方法,对应于图1a中的对称迁移。源域和目标域独分别迁移到一个共同的潜在特征空间中,尝试统一这些域的输入空间。第二种方法,对应于图1.b中的非对称迁移,迁移源域特征空间到目标特征空间上来对齐输入特征空间。在没有环境特征偏差,目标域和源域的同构样本可以被迁移的情况下,非对称迁移方法的表现效果最好。很多调查的异构迁移学习解决方法中,隐式或者显式的假设源域和目标域样本都是派生至相同域空间。根据这一假设,域间不应存在显著的分布差异。因此,只要输入特征空间的差异被解决,甚至不需要进行更进一步的域适应处理。
与同构迁移学习解决方法一样,源域和目标域是否包含带标签数据驱动着异构迁移的划分。在文中调查到的解决方法中有着不同的带标签数据需求。为了使转移学习可行,源域和目标域必须以某种方式相关。一些异构解决方案需要显式映射源域和目标域之间的关系或对应关系。例如 Prettenhofer [91] and Wei [125]定义的解决方法需要手动定义源域和目标域的对应关系。
基于特征的对称迁移学习
由Prettenhofer [91]提出的迁移学习方法中,处理了这样的场景:源域包含了带标签和不带标签的数据,目标域包含了不带标签的数据。将Blitzer [5]的结构对应学习技术应用到了这个问题上。结构应用学习依赖于手动定义关键函数,关键函数用于捕获源域和目标域之间的对应关系。有效的关键函数应该使用那些在所有域中频繁出现并且具有较好预测效果的特征。每个关键函数被来自源域和目标域的数据转化为一个线性分类器。从这些关键分类器中,特征之间的对应关系将被发现并且一个潜在的特征空间将被学习。这个潜在的特征空间被用来训练最终目标分类器。Prettenhofer [91]提出的论文中使用到了这种解决方法来处理文本分类中源域和目标域为不同语言的问题。在涉及到的交叉语言结构对应学习(cross-language structural correspondence learning CLSCL)的具体实现中,关键函数通过成对的词汇定义,在这成对的词汇中,一个来自源域,一个来自目标域,这表示从一种语言到另一种语言的直接词汇翻译。实验应用在文本情感分类和文档主题分类中。英语文档被用于源域,其他语言的文档被用于目标域。baseline方法使用的是在带标签的源域文档中训练一个学习器,然后翻译目标文档为源语言,然后测试被翻译的译本。通过使用带标签的目标文档训练一个学习器,然后使用目标文档进行测试来建立一个上限方法。平均结果显示出上限方法表现的最好,Prettenhofer的方法表现的比baseline好。使用结构对应学习存在一个问题就是很难归纳出关键函数。对于这个解决方法,关键函数需要手动并且唯一的为一个特定的应用定义,这使得该方法很难扩展到其他应用中。
Shi [105]的论文中,提出了一种异构谱映射方法,用来处理特定的迁移学习场景:输入特征空间不同,边缘分布不同,并且输出空间也不同。该方法中使用了有标签的源域数据,该源域数据与目标域是相关的,以及部分有标签的目标数据。方法的第一步是使用谱映射的方法寻找一个共同的潜在特征空间。谱映射技术被建模用于优化目标,使其保持数据的原始结构,同时最小化两个域之间的差异。下一步是应用基于样本选择的聚类方法来选出相关的样本作为新的训练数据,这样解决了潜在输入空间中边缘分布的差异。最终,一个基于贝叶斯的方法被用来寻找输出空间的关系和解决输出空间的差异。实验被设计在图像识别和药物疗效预测上。该方法的效果比baseline的方法要好,但是,关于baseline方法的详细信息没有写出来,并且没有其他的迁移学习方法被测试。
由Wang [121]提出的域适应流型对齐算法,使用了流形对齐处理来进行域输入空间上的对称迁移。在该方法中,共有K个域,存在多个带标签的源域和有限带标签的目标域,其中所有K个域共享相同的输出标签空间。为每个域创建一个独立的映射函数来将异构输入空间转换到一个共同的潜在输入空间上,该潜在输入空间保留了每个域的底层结构。每个域被建模为流形。为了创建出潜在输入空间,建立了一个更大的矩阵模型,表示并捕获所有输入域的联合流形并集。在这个流形模型中,每个域都被一个拉普拉斯矩阵代表,拉普拉斯矩阵捕获了共享相同标签的样本之间相似度。具有相同标签的样本被放在一起,同时具有不同标签的样本被分开。方法中通过广义特征值分解来进行降维以及消除特征冗余。最终的学习器通过两步建立。第一步是在使用潜在特征空间的源域数据上训练出一个线性回归模型。第二步也是一个线性回归模型,与第一阶段相加。第二步当使用带标签目标数据时,使用一个流形正则处理来保证预测误差被最小化。第一步只在源域数据上训练,第二阶段补偿由第一阶段引起的域差异,以实现增强的目标预测。实验主要应用在文本分类上,分类的准确度被用于性能度量。测试的方法包括典型相关分析方法和流形正则化方法,这也被认为是baseline方法。baseline方法使用了有限制带标签的目标与数据,但是没有使用源域信息。论文中呈现的方法比baseline方法有大幅的提升。然而,这些方法没有直接引用,因此,很难理解测试结果的重要性。这篇论文的独特之处是在heterogeneous解决方案中使用多源域的模型。
在某些情况下,可以使用大量未标记的异构源数据,这些数据可用于提高特定目标学习器的预测性能。Zhu[146]提出的论文中呈现了一种叫做Herogeneous transfer learning image classification(HTLIC)的方法,论文中假设可以访问足够大的标记目标数据,来解决这种情况。论文的目标是使用大量可用的无标签源域数据来创建一个共同潜在特征输入空间,这将提升在目标分类器上的预测性能。Zhu提出来的解决方案与图像分类的应用紧密联合,描述如下。目标域中带标签的图片是可用的,为了获得源域数据,从Flickr上执行网络搜索,以查找与标记类别“相关”的图像。例如,对于”狗”这一类,单词dog,doggy以及greyhound也许会被用于Flickr搜索上。其中把来自Flickr的被标注图像作为无标签源域数据的想法是由Yang[137]首次提出的。从Flickr检索的图像具有与每个图像相关联的一个或多个单词标签,然后使用被标记的图像词汇通过Google搜索来搜寻文本文档。接下来,构建了一个两层的双边图,其中第一层代表源域图像和图像标签之间的联系。第二层代表了图像标签和文本文档之间的联系。如果一个图像标签出现在一个文本文档中,那么一个链接就会被创建,否则,就没有链接被创建。源域和目标域的图像最初都会被一个输入特征集代表,输入特征集是从使用SIFT描述符的像素信息中衍生出来的。使用初始源图像特征和仅从源图像标签和文本数据导出的二分图表示,一个共同潜在语义特征集通过利用Latent Semantic Analysis学习。现在使用被转化的带标签目标实例来训练学习器。实验在被提出的方法上执行,其中有19类不同的图像被选取。执行二进制分类测试不同的图像类别对。使用SVM分类器作为baseline方法,其中只使用带标签的目标域数据训练。Raina和Wang提出的方法也被测试。Zhu的方法表现的最好。通过互联网搜索使用大量未标记数据来提高预测性能的想法是一个非常诱人的前提。然而,这种方法非常适用于图像分类,并且通过拥有像Flickr这样的网站来实现,该网站基本上提供了无限制的标记图像数据。 但是这种方法很难移植到其他应用上。
Qi [92]提出的迁移学习解决方案是解决特定图像分类应用方法的另一个例子。在Qi的论文中,作者称图像分类的应用本质比文本分类更难,因为图像特征并没有与类标签的语义概念有直接联系。图像特征是从像素信息中衍生出来的。这与类标签在语义上没有关系,相反对于单词特征来说,与类标签有着语义可解释性。另外,带标签的图像数据相比于带标签的文本数据更缺乏。因此,有着丰富的带标签文本数据(源)被用来提高一个在有限带标签图像数据(目标)上训练的学习器对于图像分类的迁移学习环境来说是被期望的。在这个解决方案中,文本文档通过执行在类标签上的网页搜索(例如来自维基)被确定。为了执行从文本文档(源)到图像域(目标)的知识迁移,一个共生矩阵形式的桥被用来关联文本和图像信息。共生矩阵包含具有在该特定文本文档中找到的对应图像实例的文本实例。共生矩阵可以以编程的方式通过爬取网页并且提取出相关文本和图像特征信息获取。使用共生矩阵,在文本和图像特征之间找到共同的潜在特征空间,其用于学习最终目标分类。这种方法被叫做文本到图像的方法(TTI),类似于Zhu。然而,Zhu没有使用有标签的源域来提升知识迁移,当带标签目标数据是有限的时候,这导致了性能下降。实现使用Qi[92],Dai[20],Zhu[146]提出的方法以及一个通过受限带标签目标数据训练的标准SVM分类器baseline方法执行。文本文档通过Wiki收集,并且分类错误率被性能矩阵测量。结果显示Zhu的方法在15%的试验中表现的最好,Dai的方法在10%的方法中表现的最好,Qi的方法在75%的试验中表现的最好。在Zhu的情况下,这个方法比较适合应用在图像分类中,而不太适合应用在其他应用。
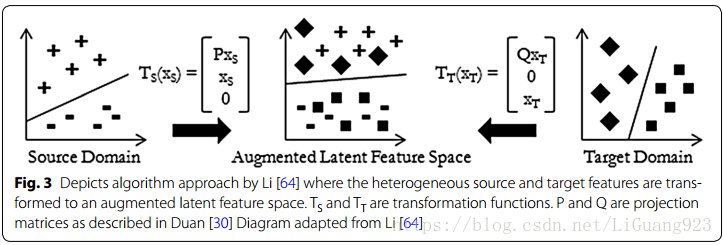
Duan在论文[30]中处理的情景集中于带有一个有标签源域和一个带部分标签样本的目标域的异类域适应。提出的解决方案被叫做heterogeneous feature augmentation(HFA)。一个转换矩阵P被定义给源以及一个转换矩阵Q被定义给目标域来将特征空间映射到一个共同潜在空间。在适当的情况下,使用初始源和目标特征集以及零来增加潜在特征空间。这意味着源输入数据投影具有共同的潜在特征,初始源特征和初始目标特征的零。 目标输入数据投影具有共同的潜在特征初始源特征的零和初始目标特征。这种特征扩增方法首先被Daumé [22]介绍,然后被用来矫正域之间的条件分布差异。为了简化计算,P和Q矩阵并不直接被计算,而是由H矩阵组合和表示。通过最小化SVM的结构风险函数[117]作为H矩阵的一个函数来定义优化问题。利用交替优化算法找到最终目标预测函数,同时解决SVM和最优变换H矩阵的对偶问题。实验执行在图像分类和文本分类的应用上。源域包括带标签的图像数据,目标域包含部分带标签的图像数据。对于图像特征,通过像素信息提取SURF特征,然后将其聚类为不同维度特征空间,从而创建异构的源域和目标域环境。对于文本分类实验,目标域包括西班牙语言的文档,源域包括四种不同语言的文档。实验测试使用了一个baseline方法,为通过在有限带标签的目标数据上训练的一个SVM学习器。其他的异构适应性方法被测试包括Wang[121], Shi[105]和Kulis[58]. 对于图像分类测试,HFA方法在分类准确度方面优于所有方法。Kulis方法和baseline的方法效果接近(可能由于数据集上的一些独特性), Wang的方法比baseline方法效果稍微好点(可能是因为数据集中的弱流型结构)。对于文本分类测试,HFA方法优于所有测试方法,平均值为1.5标准偏差,在这次测试中,Kuilis的方法效果仅次域HFA,然后是Wang提出的方法,最后是baseline方法。Shi的方法比baseline方法效果还差。出现这样的结果一个可能的原因是当执行对称变换时,Shi的方法没有专门使用带标签的目标信息,这将导致分类效果下降。
Li[64]的工作中,提出了一种叫做半监督异构特征扩增方法(SHFA)来处理有着丰富带标签源域数据和部分目标数据的异构情况,然后直接扩展了Duan的工作。其中,由上面Duan所描述的H转换矩阵被分解为一组秩为1的正半定矩阵的线性组合,正半定矩阵允许多核学习求解器(由Kloft[57]定义)被用于求解。在学习H转换矩阵的过程中,没有标签的目标域数据的标签被估计出来(创建伪标签),然后在学习最终目标分类器的时候被使用。给没有标签的目标数据标签是从一个训练在受限带标签目标数据上的SVM分类器得到的。高层级域适应展示在图3中。实验被执行在三个应用上,包括图像分类(其中定义了31个不同的类),多语言文本文档分类(其中定义了6个不同类),以及多语言文本语义分类。分类准确度是作为性能指标来衡量的。Li的方法使用了一个SVM学习器作为基线方法,并且训练在受限的带标签目标数据。另外,其他异构方法包括Duan[30], Shi[105], Wang[121], 和Kulis[58]也被测试。通过平均三个不同应用的测试结果,效果表现次序(从好到坏)为: Li, Duan, Wang, baseline和Kulis, 以及Shi。
非对称特征迁移
Kulis的工作[58],称为非对称正则化跨域变换(ARC-t), 提出了一个非对称变换算法解决域之间的异构特征空间问题。对于这样的情况,存在一个丰富的带标签源域数据集合和受限的带标签目标数据。首先,一个目标函数被定义用于学习变换矩阵。目标函数包括一个正则化项和一个代价函数项,它应用于每对跨域实例和学习的转换矩阵。目标函数的构造负责域不变转换过程。目标函数的优化目的在于最小化正则化矩阵和代价函数项。转换矩阵在一个非线性的高斯RBF核空间被学习。使用该方法的两个实验被执行用于图像分类,其中分类准确率被用于性能度量。在这些实验中定义了31类图像。在第一个实验中,源域和目标训练数据样本中包含所有的31个图像类。在第二个实验中,只有16个图像类被表示在目标训练数据中(所有的31个图像类被表示在源域中)。为了测试其他基线方法,需要一种方法将源和目标输入域组合在一起。一个预处理步骤,叫做Kernel Canonical Correlation Analysis(由Shawe-Taylor[104]提出),使用对称变换映射源域和目标域到一个共同域空间。被测试的基线方法包括最近邻算法、SVM、由Davis[23]提出的度量学习方法、由Daumé [22]提出的特征扩增,以及有由Saenko [100]提出的跨域度量学习方法。对于实验一,Kulis的方法比其他测试方法表现的稍微好一些。对于实验二,Kulis的方法比最近邻方法比较好很多(注意其他的方法不能被测试,因为他们需要所有的31类被表示在目标训练数据中)。 Kulis的方法适合于类似实验2的场景(所有的类没有被全部表示在目标训练数据中)。
Harel[46]定义的问题域包括有限带标签的目标数据和多个带标签的数据源域,其中一个非对称变换被用于每个源域中解决特征空间中的不匹配。过程中的第一步是标准化源域和目标域中的特征,然后通过源域和目标域中的类对样本分组。对于每一类,特征被调整到零均值。接下来,每个单独的源域类别组和对应的目标域类别组形成一对,奇异值分解处理被用于给类别分组找到具体的变换矩阵。一旦执行了变换,特征就意味着向后移动以反转前一步骤,最终的目标分类器使用被变换的数据进行训练。使用奇异值分解处理发现变换矩阵在维持数据的结合下,允许类分组内的边缘分布对齐。这种方法被叫做Multiple Outlook MAPping algorithm(MOMAP). 实验使用的数据来自可穿戴传感器针应用于活动分类。实验中有五个不同的活动,其中包括行走、跑步、上楼梯、下楼梯、徘徊。源域包括与目标域类似的传感器读取的数据(但是不同)。Harel [46]提出的方法与使用有限标记目标数据训练分类器的基线方法、使用拥有更大标记目标数据集来训练分类器的上限方法进行比较。一个SVM学习器被用作基本分类器,一个均衡的误差率(由于测试数据的不均衡)被用作性能度量。Harel的方法在每一个测试上表现的都比基线方法好,但是对于均衡误差率来说,表现的比上限边界方法稍微差了一点。
Zhou[145]处理的异构迁移学习场景需要一个丰富的带标签源域数据和有限带标签的目标数据。一个非对称变换函数被提出用于映射源域特征到目标域特征上。为了学习变换矩阵,采用了一个基于Ando[2]的多任务学习方法。这个解决方案被称为sparse heterogeneous feature representation(SHFR),通过为源域和目标域中的每个类分别创建一个二分类器来实现。每个二分类器被分配一个权重项,其中权重项通过组合被加权的分类器输出来进行优化,同时最小化每个域的分类误差。现在权重项被用于发现变换矩阵通过最小化目标域权重和被变换后的源域权重之间的差异。最终的目标分类器使用被变换后的源域数据和初始目标数据进行训练。实验执行在文本文档分类上,其中目标域包括使用一种语言写的文档,源域包括使用不同语言写的文档。基线方法使用通过带标签的目标数据训练的SVM分类器,同时测试了由Wang[121],Kulis[58],Duan[30]提出的方法。由Zhou提出的方法对于分类准确率来说在所有的测试上表现的最好。其他方法的结果作为所使用的数据集的函数混合,其中Duan [30]方法效果为第二或者是第三。
软件模块缺陷预测的应用经常是通过来自感兴趣的软件项目中带标签数据训练一个分类器来解决的。由Nam[77]描述的用来预测软件模块缺陷环境尝试使用来自一个软件项目的源域数据训练一个分类器预测来自另一个项目的不带标签的目标数据。源域和目标软件项目收集不同的度量标准使得源域和目标域特征空间异构。这个被提出的方法被称为heterogeneous defect prediction(HDP), 首先使用特征选取方法选取来自源域的重要特征以减少冗余和不相关的特征。被使用的特征选取方法包括增益率、卡方、relief-F和显著性属性估计(请见Gao[39]和Shivaji[108])。下一步是在统计上使用Kolmogorov-Smirnov测试将被选取的源域特征匹配到目标域上的某个特征。学习器使用那些对应目标域特征有着紧密的统计匹配的源域特征进行训练。通过一个经过训练的分类器测试目标域数据,该分类器使用目标域上相应匹配特征进行训练。尽管由Nam的方法被直接应用到软件权限预测的应用上,但是该方法也可以被用于其他方向。实验使用五个带有异构特征的不同软件缺陷数据集执行。有Name提出的方法使用逻辑回归作为基础学习器。其他被测试的方法包括一个内部项目缺陷预测(WPDP)方法,其中学习器训练在带标签的目标域数据上,和一个跨项目缺陷预测方法,其中源域和目标域代表不同软件项目但是有着同构特征,以及由He提出的一个带有同构特征的跨项目缺陷预测方法。实验结果表明,Nam [77]方法在曲线测量的面积方面明显优于所有其他方法。接下来是WPDP方法,其次是CPDP-CM方法和CPDP-IFS方法。这些结果可能会产生误导,因为Nam [77]方法在37%的测试中只能匹配源域和目标域之间的至少一个或多个输入特性。因此,剩下的63%的情况,Nam的方法不能被使用,并且这63%的情况也没有被统计。WPDP方法代表了一个上界,Nam [77]方法的性能优于WPDP方法,这是一个意想不到的结果。
Zhou [144]的论文称,先前的异构解决方案假设源域和目标域之间的实例对应性具有统计代表性(分布是相同的),然而并不总是这样的情况。这种说法的一个例子是文本情感分类的应用,其中先前讨论的单词偏差问题导致源域和目标域之间的分布差异。Zhou的论文提到了一种叫做hybrid heterogeneous transfer learning(HTTL)方法用来解决一种带有丰富带标签源域数据和丰富的不带标签的目标域数据的异构环境。该想法首先是学习一个从目标域到源域的非对称变换,从而将问题简化为同构域适应问题。下一步是使用经过转换后的数据(从上一步)找到一个共同潜在特征空间来减少经过转换的无标签目标域和带标签的源域之间的分布偏差。最后,同构使用来自带标签的源域数据的共同潜在特征空间训练一个分类器。该解决方法使用一个由Chen提出边缘化堆叠去噪自动编码器的深度学习方法实现以学习到非对称变换并映射到一个共同潜在特征空间。
先前提到的Glorot[41]的论文中阐述了一个深度学习的方法,为均匀源和目标特征集提供了共同的潜在特征空间。实验集中于多语言文本情感分类,其中英语被用于源域中,三个其他的语言分别被用在目标域中。分类准确率被用于性能度量。其他被测试的方法包括由Shi[105]提出的一个异构的谱映射方法,一个有Vinokourov[120]提出的方法和由Ngiam[79]提出的一个多模深度学习方法.一个SVM学习器被用作所有方法的基本分类器。实验的结果从最好到最坏的效率顺序为:Zhou[144],Ngiam[79],Vinokourov[120]和Shi[105].
异构解决方案的提升
Yang[136]的论文提出了量化在一个异构迁移学习环境中域之间可以被迁移的知识数量。换句话说,它尝试测量域之间的相关性。首先被完成的是为每一个域建立一个共生矩阵。该共生矩阵包含在每个域中表示的实例集。例如,如果一个特定的文本文档在共生矩阵中是一个示例,那该文本文档需要在每个域中表示。然后,主成分分析被用于选取在每个域中最重要的特征并分配主成分系数给这些特征。主成分系数被用于构成一个定向循环网络(DCN),其中每个节点代表一个域(要么是源域或者是目标域),每个节点连线(边缘权重)为从一个与到另一个域的条件依赖。DCN使用一个蒙特卡洛马尔科夫链的方法建立。边缘权重代表在域之间可以被迁移的知识可能的数量,其中一个高的值表示更高的知识迁移。然后,这些边缘权重被用作在不同异构迁移学习方案中的微调参数,其中包括来自Yang[137],Ng[78]和Zhu146的工作。注意,注意,将边缘权重值集成到特定方法中是特定于解决方案的实现,并不能在普遍的应用。实验是在三种不同的学习解决方案上进行的,将原始解决方案与使用DCN的加权边缘作为调整参数的解决方案进行比较。在这个三个解决方案中,使用DCN微调参数分类准确率得到了提升。该方法一个潜在的问题是共生举证的构建。共生矩阵包含很多事例。然而,每个事例必须在每个域中表示。这也许在很多实际应用中是不现实的约束。
实验结果
在评论之前被调查的论文实验结果中,有些情况下,一种解决方案可以在一系列不同的实验中显示出不同的结果。导致这种情况发生的原因有很多,其中包括不同的测试环境,不同的测试实施,被测试在不同应用上以及使用的不同数据集。未来工作一个有趣的领域是评估所提出的解决方案,以确定作为特定数据集的函数的最佳性能解决方案。为了促进这个目标,包含每篇论文中使用的解决方案的软件实现的开源软件存储库将是非常有益的。
表3列出了“异构转移学习”部分中包含的最常测试解决方案的结果。
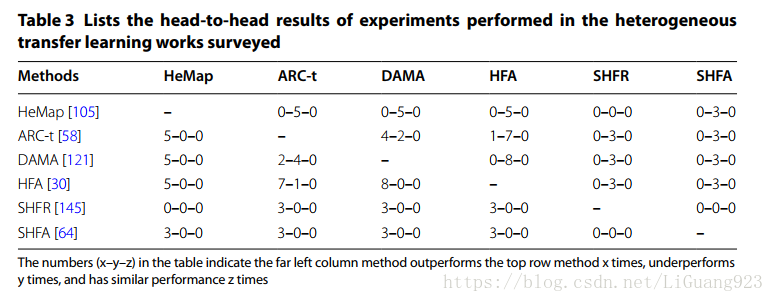
关于异构解决方案的讨论
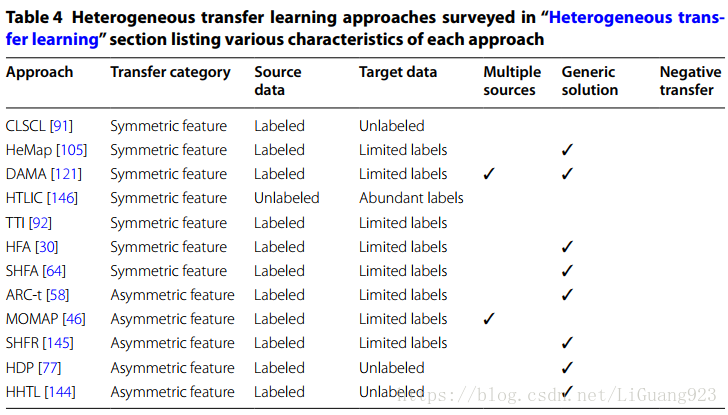
先前被调查的异构迁移学习工作阐述了很多不同的特性和属性。哪一个异构迁移学习方法对一个单独的应用来说是最好的呢?异构迁移学习方法除了使用非对称变换就是对称变换处理作为解决输入特征空间之间差异的尝试(如图1)。非对称变换方法当在源域和目标域中的同类实例可以被转换而没有环境特征偏差时表现的最好。被调查的很多异构迁移学习方法只处理了源域和目标域之间输入空间不同的问题,但是没有解决解决边缘和/或条件分布差异所需的其他域适应步骤。如果在输入特征空间被对齐之后,进一步域适应需要被执行,那么一个合适的同构解决方案就应该被使用。为了进一步帮助决定哪一个解决方案最适合一个被给的迁移学习应用,表4中的信息可以被用于匹配解决方案的特性到想要应用的环境中。
被调查的异构迁移学习解决方案中没有一个有着方法去防止负迁移所带来的影响。然而,Yang[136]的论文中阐述了负迁移防护可以对迁移学习解决方案有好处。似乎可能未来的以后迁移学习工作将集成负迁移保护的方法。很多相同的异构迁移解决方法被测试在被调查的方案实验中。这些头接头的比较被概况在表3中,可以被用来作为一个起点以理解这些解决方案之间的相关性能。可以观察到先前的同构解决方案中的一个趋势,最近由Duan提出的异构解决方案中使用了一个一阶的解决方案,该方案同时执行特征输入空间对齐和学习最终分类器。调查的同构迁移学习工作存在一种情况,即被调查的异构迁移学习工作没有具体应用到大数据解决方案中,然而这并不阻碍将他们应用在大数据环境中。
负迁移
迁移学习的高级概念是通过使用来自相关源域的数据来提升一个目标学习器。但是如果源域和目标域之间并不怎么相关会发生什么呢?在这种情况下,目标分类器会被这种弱联系而产生负影响,也被称作负迁移。在一个大数据环境中,可能存在着一个很大的数据集,其中只有一部分数据和感兴趣的目标域是相关的。在这种情况下,需要将这个数据集切分为多个源域并且在使用迁移学习算法的时候使用负迁移方法。在这样的场景中,其中多个数据集是可用的,并最初看起来是和感兴趣的目标域相关,有期望选取出可以提供最好的信息迁移的数据集,并且避免导致负迁移的数据集。这样可以最好的利用可用的大数据集。那么源域和目标域之间有多相关才能使迁移学习变得具有优势呢?负迁移的领域尚未得到广泛研究,但是以下的论文开始处理这类问题了。
Rosenstein[98]早期的一篇论文讨论了迁移学习中负迁移的概念,并且声称源域需要变得与目标域充分相关。否则,尝试将知识从源域迁移就可能对目标分类器产生消极影响。负迁移的情况通过Rosenstein在实验中使用了一个层次朴素贝叶斯分类器来进行阐述。作者也阐述了负迁移降低的机会,当目标域带标签的训练样本增加的时候。
由Eaton的论文提出的基于多个相关源域中的可迁移性度量来建立一个目标学习器。该方法首先建立一个逻辑回归学习器给每个源域。接下来,一个模型迁移图被构建以表示每个源域学习器之间的迁移性。在这种个情况中,来自第一个学习器到第二个学习器的可迁移性被定义为:使用第一个学习器学习到的第二个学习器的性能减去没有使用第一个学习器学习的第二个学习器的性能。接下来,通过添加目标分类器和所有的源域分类器之间的迁移性度量来修改模型迁移图。在模型迁移图上使用光谱图理论[17],一个迁移函数被推导出来以维持模型迁移图的几何结构并且该函数被使用在最终目标学习器上以决定从每个源域中迁移的层次。实验执行在文档分类的应用和字母表分类的应用上,源域被识别为与目标域相关的或者不相关的。由Eaton提出的方法与一个精心挑选的方法一起被测试,该方法中那些与目标域相关的源域被手动选取,一个平均的方法使用所有可用的源域,以及一个没有使用迁移学习的基线方法。在实验中,分类准确率作为性能度量。源域和目标域通过一个同构特征输入空间表示。实验的结果是混合的。总的来说,Eaton[31]的方法表现最好,然后,其中也存在Eaton的方法表现的比手动挑选的方法、平均方法和基线方法差的情况。在算法的实现中,两个源域之间的可迁移性度量需要是一样的。然而,从源域1到源域2之间的可迁移性并不总是与源域2到源域1之间的可迁移性是相同的。关于未来提升的一个建议是使用有向图来制定两个源域之间的可迁移性度量的双性性质。
Ge的论文提出由于不相关和无关的源域,知识迁移可以被抑制。另外,当前迁移学习解决方案主要集中于从源域到目标域之间的知识迁移,并没有关心不同源域,那些可能不相关并且导致负迁移的源域。由Ge[40]提出的模型中,存在一个单个有限带标签数据的目标域和多个带有标签的源域用来知识迁移。为了减少来自不相关源域的负迁移的影响,每个源域被分配了一个权重(被叫做有监督局部权重),对应于该源域与目标域之间有多相关(越高的权重表示越相关)。首先使用一个谱聚类算法(Chung[17])在无标签的目标域信息上来发现有监督局部权重,并且将标签传播到带标签目标信息的集群中。接下来,每个源域被单独聚类,然后标签被分配到带标签源域的集群上。通过对比源域和目标域集群计算每个源域几圈的有监督局部权重。另外,该解决方案通过在少数目标类别中进行高精度预测的情况下防止高权重类别分配,进一步解决源域中不平衡类分布的问题。最终目标学习器使用有监督局部权重来削弱负迁移的影响。实验被执行在三个应用领域中,包括心脏心律不齐检测、垃圾邮件过滤和侵入检测。测量曲线下的面积作为性能度量。通过一个同构特征输入空间代表源域和目标域。论文中的方法与Luo[71],Gao[38],Chattopadhyay[14],Gao[37]的方法进行比较。Luo和Gao的方法表现的最差,很有可能是因为这些方法并没有尝试去处理负迁移影响导致的。Chattopadhyay和Gao的方法表现第二,这两个方法中使用了一些方法去减少来自源域的负迁移的影响。Chattopadhyay和Gao的方法没有处理负迁移问题,也没有处理分布不平衡问题。Ge的方法在所有方法中表现的最好,因为处理了负迁移和类分布不平衡问题。
Seah的论文中称负迁移的根本原因主要是由于源域之间的条件分布差异PS1(y|x) != PS2(y|x),并且在源域和目标域之间的类分布(类失衡)也不同PS(y) != PT(y)。因为目标域总是包含一小部分带标签的样本,找到目标域的真实类分布是困难的。一个预测性分布匹配框架(PDM)被提出用于对齐源域和目标域的条件分布以最小化负迁移影响。一个正迁移性度量被定义为测量来自源域和目标域中具有同样标签的样本对之间的可迁移性。PDM框架的第一步是给不带标签的目标域数据分配一个伪标签。这通过一个迭代过程被完成,该过程中强制那些相似(通过证迁移性测量定义)的源域和目标样本具有相同的标签。接下来,通过识别每个类带有伪标签的目标域数据条件分布没有对齐的数据来移除不相关的源域数据。所有的逻辑回归和SVM分类器都使用PDM框架来实现。实验执行在使用PDM方法的文档分类中,Daumé [22],Huang[51],Bruzzone[11]的方法也被测试。分类准确率作为性能度量。通过一个同构特征输入空间代表源域和目标域。通过与其他方法比较,这些放阿飞没有尝试处理负迁移的影响,PDM方法表现出了更好的性能。
一部分先前被调查的论文中也包含了处理负样本的解决方案。Yang[136]的论文中处理了负迁移的问题,其被呈现在”Heterogeneous transfer learning”一节中。由Gong[42]提出的同构解决方案中也定义了一个ROD值,其测量了源域和目标域之间的相关性。Chattopadhyay[14]中呈现的工作是一个多源域迁移学习方法,其计算了源域权重作为源域和目标域之间的条件概率差异函数以分配最高的权重给最相关的源域。Duan提出了一个迁移学习方法,其只使用被认为是相关的源域和测试数据,并通过与没有做负迁移保护的方法进行比较论证了该方法拥有更好的性能。
先前的论文尝试度量在迁移学习环境中源域数据域目标数据中间有多相关,然后有选择的迁移那些高度相关的信息。在以上论文中的实验论证了来自源域数据的负迁移影响的核算可以提升目标学习器的性能。然而,大多数迁移学习方法都没有尝试核算负迁移的影响。鲁棒的负迁移测量是很难去定义的。因为目标域大多都只是拥有部分带标签数据,这成为了寻找一个在源域和目标域之间的相关性真实度量的内在困难。另外,通过那些看起来和有限带标签目标域相关的可选性迁移信息目标学习器中过拟合的风险也是一个令人担忧的事情。负迁移的主题也还是进一步研究的沃土。
迁移学习应用
在本文中被调查的工作阐述了迁移学习已经被应用到了很多现实应用中。有着大量关于自然语言处理的应用实例,尤其是在情感分类、文本分类、垃圾邮件检测,以及多语言文本分类领域方面。其他能够很好代表迁移学习应用的包括图像分类和视频概念分类。在先前的论文中更有选择性的应用包括WIFI定位分类,肌肉疲劳分类,药物功效分类,人类活动分类,软件缺陷分类和心律失常分类。
大多数被调查的解决方案都是可泛化的,以为着这些解决方案可以被简单的应用到不只是在论文中实现和测试的那些应用上。在特定应用上的解决方案趋向于图像处理和自然语言处理的相关领域。在学术上,也存在很多特定的推荐系统应用上的迁移学习方法。推荐系统给用户提供建议或者是一个特定领域的评价(比如:电影、书籍等),但是这些是基于历史信息而成的。然而,当系统并没有足够的历史信息的时候(也被Moreno[76]称为数据稀疏问题),然后,这些推荐将不再可靠。在系统没有足够的域数据来给出可靠的预测的情况下(例如,一个电影刚放映的时候),这时就需要使用以前从不同域(例如使用书籍信息)中收集的信息了。上述问题已经被迁移学习方法论直接解决,可以在论文Moreno [76], Cao [12], Li [60], Li [61], Pan [86], Zhang [140], Pan [85], Roy [99], Jiang [54], 以及Zhao [142]中找到。
迁移学习解决方案将持续被应用到多种多样的现实应用中,以及一些相当模糊的应用情况中。关于头部姿势识别的应用通过使用以前被捕获到的带标签头部位置训练一个学习器来预测一个新的头部位置。头部姿势分类被用于确定驾驶员的注意力、分析社会行为和人机交互中。在源域训练数据中的被捕获的头部位置与被那些被预测的目标相比将有着不同的头部倾斜和角度。由Rajagopal [96]提出的论文中通过使用迁移学习方法处理了头部姿势分类问题。
其他的迁移学习方法包括Ma提出的论文中使用迁移学习对大气尘埃气溶胶粒子进行分类以提升全球气候模型。Dai提出的TrAdaBoost算法被用于连接一个SVM分类器以提升分类效果。确定发展中国家的低收入地区对于赈灾,粮食安全和实现可持续增长至关重要。为了更好的预测贫穷映射,Xie[134]提出了一个与Qquab[81]类似的方法:使用一个卷积神经网络模型。第一个预测模型被训练用于预测来自源域图像数据的晚间灯光密集度。最后的目标预测模型预测从源域晚间灯光密集度数据映射的贫穷程度。由Ogoe提出的论文中[80],迁移学习被用于提升疾病预测。在该解决方案中,一个基于规则的学习方法被表述于使用抽象的源域数据来执行多种基因表达数据的模型。在线展示网页广告是一种日渐成长的产业,其中迁移学习被使用,通过使用被加权的多源域分类器输出来提升一个目标分类器以预测定向的在线展示广告结果。Kan[56]的论文中处理了面部识别领域的问题,并可以使用来自一个民族集群的面部图像信息去提升对一个不同民族种群的分类的学习。Farhadi撰写的论文[35]专注于手语识别的应用,其中模型能够从不同角度的不同人群中学习。在Widmer[127]的论文中迁移学习被用于生物领域。不同之处是,多任务学习方法被用于预测基因组生物学中的剪接位点。Wiens [128]在论文中讨论预测了患者入院时是否患有特定细菌。从不同的医院获取的信息用于预测不同医院的感染率。在Romera-Paredes [97]的论文中,一个多任务迁移学习方法被用于预测一个人的面部表情表示的疼痛程度,通过使用来自其他人的带标签的源域面部图像。Deng的论文中将迁移学习应用到语音情感识别中,其中信息从多个带标签的语音源域进行迁移。Zhang[141]实现了酒类质量分类通过使用一个多任务迁移学习方法。作为参考,Cook的论文中也将迁移学习应用到了活动识别中,Patel[89]和Shao[103]的论文中在图像识别中处理了迁移学习。
总结和讨论
迁移学习的主题是一个很值得研究的领域,在过去的五年中有超过700篇学术论文处理该主题。这篇调查论文呈现了在迁移学习中代表了当前的学术趋势解决方法。同构迁移学习论文从基于样本、基于特征、基于参数和基于关系信息的迁移技术上进行阐述。解决方法对带标签和不带标签的数据有着不同的需求,这也显示出了这个关键属性。论文对异构迁移学习中相关的新领域也进行了调查,显示了关于域适应的两个主要方法,为对称变换和非对称变换。很多迁移学习的现实应用在本文中被提到也讨论了。在某些情况下,被提到的迁移学习方法对于某些潜在的应用具有较大的特异性,并不能被泛化使用到其他应用上。本文中调查的一部分解决方案实现的软件下载列表将呈现在附录中。研究人员的一大好处是可以从以前的解决方案中获得软件,从而可以更有效,更可靠地进行实验。对于出版的迁移学习解决方法的一个开源软件库对研究团体来说也将是一个很大的财富。
在很多迁移学习方案中,域适应处理集中在矫正边缘分布误差或者条件分布误差上。由于缺乏带标签的目标域数据,矫正条件分布误差是一个具有挑战性的问题。为了解决带标签数据缺乏的问题,一些解决方案为目标数据估计了标签(也叫做伪标签),然后,被用于矫正条件分布误差。这种方法是存在问题的,因为条件分布矫正实在伪标签的帮助下完成的。提升这种方法来矫正条件分布误差是未来研究的一个潜在领域。最近也有着大量的工作尝试在域适应过程中既矫正边缘分布误差也对条件分布误差进行矫正。未来工作的一个领域是定量矫正这些误差的优势以及在什么样的场景下是最有效的。此外,Long[68]声明了同时矫正条件分布误差和边缘分布误差在序列对齐上表现的更好,因为他减小了过拟合的风险。未来工作的另一个领域是定量同时解决所有分布误差的性能增益。除了在域适应过程中解决分布误差,使用域特征的启发性只是探索可能的数据预处理步骤也可以被用作提升目标学习器性能的一个方法。启发性知识将表征标准迁移学习方法不能解释的一组复杂规则或者是关系。在大多数情况下,启发性只是对于每个域是具有特异性的,它并不能成为一个泛化性的解决方案。然而,如果这样一个预处理步骤提升了目标学习器的性能,那么这些努力都是值得的。
在迁移学习解决方案的制定中观察到的趋势是实施一阶过程而不是二阶过程。一个二阶过程方案首先执行域适应性处理,然后独立的学习最终分类器。一个一阶过程当学习最终分类器的时候同时执行域适应处理。最近使用一阶解决方法的包括Long [68], Duan [27], Shi [106], Xia [132], 和Duan [30].针对于一阶解决方法,Long提出同时处理域适应性和建立分类器,这之间建立了相互增强,从而提升了性能。未来的一个工作领域是更好地定量一个一阶方法在一个二阶方法之上的效果。
本文中也调查了很多处理负迁移主题的工作。负迁移的课题仍然是一个被轻视研究领域。在未来的研究中将负迁移技术的扩展集成到迁移学习方案中是很自然的。支持多个源域的解决方案能够将更大的源域分成更小的域,以更容易地区分不相关的源数据,这是继续研究的一个逻辑领域。另外,优化迁移也是未来研究另一个肥沃的领域。负迁移被定义为:源域对目标学习器具有消极影响。优化迁移的概念是当从源域中选取信息的时候,通过迁移使得目标学习器达到可能的最好的效果。负迁移和优化迁移是有重叠性的。然而,优化迁移尝试去发现目标学习器最好的效果,这远远超出了负面转移概念。
随着手机、自行车、建筑物、路面和计算机上传感器的扩增,巨大并且不同的信息被采集到。在数据采集上的不同是的异构迁移学习方案将变得更重要。更大的数据采集大小提高了大数据解决方案与当前迁移学习方案并行的潜在可能性。需要多少传感器数据的种类和大小集成到迁移学习方案中也是未来研究感兴趣的一个主题。未来的另外一个研究属于这样的场景,即在域之间,输出标签空间是不同的。随着新数据集被捕获和利用,这项主题可能是未来集中并且也是被需要的一个领域。最后,文献中很少有解决无标签源域和无标签目标域场景的方案,这完全是一个需要被扩展的研究。
附录
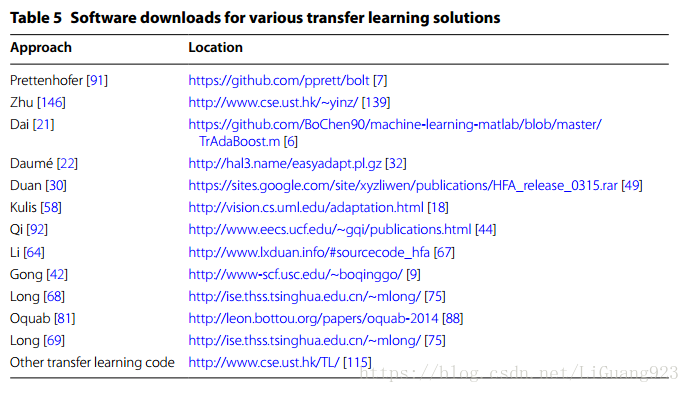
大多数调查的转移学习解决方案都很复杂,并且使用并不普通的软件实施。对于研究人员来说,获得转移学习解决方案的软件实现是一个很大的优势,因此可以更快速,更公平地促进与竞争解决方案的比较。表5提供了本文调查的许多解决方案的可用软件下载列表。 表6提供了有用链接的资源,指向转移学习教程和关于转移学习主题的其他有趣文章。

参考文献
- A literature survey on domain adaptation of statistical classifers. http://sifaka.cs.uiuc.edu/jiang4/domain_adaptation/survey/da_survey.html. Accessed 4 Mar 2016.
- Ando RK, Zhang T. A framework for learning predictive structures from multiple tasks and unlabeled data. J Mach Learn Res. 2005;6:1817–53.
- Bay H, Tuytelaars T, Gool LV. Surf: speeded up robust features. Comput Vis Image Underst. 2006;110(3):346–59.
- Belkin M, Niyogi P, Sindhwani V. Manifold regularization: a geometric framework for learning from examples. J Mach Learn Res Arch. 2006;7:2399–434.
- Blitzer, J, McDonald R, Pereira F. Domain adaptation with structural correspondence learning. In: Proceedings of the 2006 conference on empirical methods in natural language processing. 2006;120–8.
- BoChen90 Update TrAdaBoost.m. https://github.com/BoChen90/machine-learning-matlab/blob/master/TrAdaBoost.m. Accessed 4 Mar 2016.
- Bolt online learning toolbox. http://pprett.github.com/bolt/. Accessed 4 Mar 2016.
- Bonilla E, Chai KM, Williams C. Multi-task Gaussian process prediction. In: Proceedings of the 20th annual conference of neural information processing systems. 2008. 153–60.
- Gong B. http://www-scf.usc.edu/~boqinggo/. Accessed 4 Mar 2016.
- Borgwardt KM, Gretton A, Rasch MJ, Kriegel HP, Schölkopf B, Smola AJ. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics. 2006;22(4):49–57.
- Bruzzone L, Marconcini M. Domain adaptation problems: a DASVM classifcation technique and a circular validation strategy. IEEE Trans Pattern Anal Mach Intell. 2010;32(5):770–87.
- Cao B, Liu N, Yang Q. Transfer learning for collective link prediction in multiple heterogeneous domains. In: Proceedings of the 27th international conference on machine learning. 2010. p. 159–66.
- Cawley G. Leave-one-out cross-validation based model selection criteria for weighted LS-SVMs. In: IEEE 2006 international joint conference on neural network proceedings 2006. p. 1661–68.
- Chattopadhyay R, Ye J, Panchanathan S, Fan W, Davidson I. Multi-source domain adaptation and its application to early detection of fatigue. ACM Trans Knowl Dis Data (Best of SIGKDD 2011 TKDD Homepage archive) 2011; 6(4) (Article 18).
- Chelba C, Acero A. Adaptation of maximum entropy classifer: little data can help a lot. Comput Speech Lang. 2004;20(4):382–99.
- Chen M, Xu ZE, Weinberger KQ, Sha F (2012) Marginalized denoising autoencoders for domain adaptation. ICML. arXiv preprintarXiv:1206.4683.
- Chung FRK. Spectral graph theory. In: CBMS regional conference series in mathematics, no. 92. Providence: American Mathematical Society; 1994.
- Computer Vision and Learning Group. http://vision.cs.uml.edu/adaptation.html. Accessed 4 Mar 2016.
- Cook DJ, Feuz KD, Krishnan NC. Transfer learning for activity recognition: a survey. Knowl Inf Syst. 2012;36(3):537–56.
- Dai W, Chen Y, Xue GR, Yang Q, Yu Y. Translated learning: transfer learning across different feature spaces. Adv Neural Inform Process Syst. 2008;21:353–60.
- Dai W, Yang Q, Xue GR, Yu Y (2007) Boosting for transfer learning. In: Proceedings of the 24th international conference on machine learning. p. 193–200.
- Daumé H III. Frustratingly easy domain adaptation. In: Proceedings of ACL. 2007. p. 256–63.
- Davis J, Kulis B, Jain P, Sra S, Dhillon I. Information theoretic metric learning. In: Proceedings of the 24th international conference on machine learning. 2007. p. 209–16.
- Deerwester S, Dumais ST, Furnas GW, Landauer TK, Harshman R. Indexing by latent semantic analysis. J Am Soc Inf
Sci. 1990;41:391–407. - Deng J, Zhang Z, Marchi E, Schuller B. Sparse autoencoder based feature transfer learning for speech emotion recognition. In: Humaine association conference on affective computing and intelligent interaction. 2013. p. 511–6.
- Domain adaptation project. https://www.eecs.berkeley.edu/~jhoffman/domainadapt/. Accessed 4 Mar 2016.
- Duan L, Tsang IW, Xu D. Domain transfer multiple kernel learning. IEEE Trans Pattern Anal Mach Intell.
2012;34(3):465–79. - Duan L, Xu D, Chang SF. Exploiting web images for event recognition in consumer videos: a multiple source domain adaptation approach. In: IEEE 2012 conference on computer vision and pattern recognition. 2012. p. 1338–45.
- Duan L, Xu D, Tsang IW. Domain adaptation from multiple sources: a domain-dependent regularization approach. IEEE Trans Neural Netw Learn Syst. 2012;23(3):504–18.
- Duan L, Xu D, Tsang IW. Learning with augmented features for heterogeneous domain adaptation. IEEE Trans Pattern Anal Mach Intell. 2012;36(6):1134–48.
- Eaton E, des Jardins M, Lane T. Modeling transfer relationships between learning tasks for improved inductive transfer. Proc Mach Learn Knowl Disc Database. 2008;5211:317–32.
- EasyAdapt.pl.gz (Download). http://hal3.name/easyadapt.pl.gz Accessed 4 Mar 2016.
- Evgeniou T, Pontil M (2004) Regularized multi-task learning. In: Proceedings of the 10th ACM SIGKDD international conference on knowledge discovery and data mining. p. 109–17.
- Exploiting web images for event recognition in consumer videos: a multiple source domain adaptation approach. http://lxduan.info/papers/DuanCVPR2012_poster.pdf. Accessed 4 Mar 2016.
- Farhadi A, Forsyth D, White R. Transfer learning in sign language. In: IEEE 2007 conference on computer vision and pattern recognition. 2007. p. 1–8.
- Feuz KD, Cook DJ. Transfer learning across feature-rich heterogeneous feature spaces via feature-space remapping
(FSR). J ACM Trans Intell Syst Technol. 2014;6(1):1–27 (Article 3). - Gao J, Fan W, Jiang J, Han J (2008) Knowledge transfer via multiple model local structure mapping. In: Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining. p. 283–91.
- Gao J, Liang F, Fan W, Sun Y, Han J. Graph based consensus maximization among multiple supervised and unsupervised models. Adv Neural Inf Process Syst. 2009;22:1–9.
- Gao K, Khoshgoftaar TM, Wang H, Seliya N. Choosing software metrics for defect prediction: an investigation on feature selection techniques. J Softw Pract Exp. 2011;41(5):579–606.
- Ge L, Gao J, Ngo H, Li K, Zhang A. On handling negative transfer and imbalanced distributions in multiple source transfer learning. In: Proceedings of the 2013 SIAM international conference on data mining. 2013. p. 254–71.
- Glorot X, Bordes A, Bengio Y. Domain adaptation for large-scale sentiment classifcation: A deep learning approach. In: Proceedings of the twenty-eight international conference on machine learning, vol. 27. 2011. p. 97–110.
- Gong B, Shi Y, Sha F, Grauman K. Geodesic flow kernel for unsupervised domain adaptation. In: Proceedings of the 2012 IEEE conference on computer vision and pattern recognition. 2012. p. 2066–73.
- Gopalan R, Li R, Chellappa R. Domain adaptation for object recognition: an unsupervised approach. In: 2011 international conference on computer vision. 2011. p. 999–1006.
- Guo-Jun Qi’s publication list. http://www.eecs.ucf.edu/~gqi/publications.html. Accessed 4 Mar 2016.
- Ham JH, Lee DD, Saul LK. Learning high dimensional correspondences from low dimensional manifolds. In: Proceedings of the twentieth international conference on machine learning. 2003. p. 1–8.
- Harel M, Mannor S. Learning from multiple outlooks. In: Proceedings of the 28th international conference on
machine learning. 2011. p. 401–8. - He P, Li B, Ma Y (2014) Towards cross-project defect prediction with imbalanced feature sets. http://arxiv.org/
abs/1411.4228. - Heterogeneous defect prediction. http://www.slideshare.net/hunkim/heterogeneous-defect-predictionesecfse-2015. Accessed 4 Mar 2016.
- HFA_release_0315.rar (Download). https://sites.google.com/site/xyzliwen/publications/HFA_release_0315.rar. Accessed 4 Mar 2016.
- Hu M, Liu B. Mining and summarizing customer reviews. In: Proceedings of the 10th ACM SIGKDD international conference on Knowledge discovery and data mining. 2004. p. 168–77.
- Huang J, Smola A, Gretton A, Borgwardt KM, Schölkopf B. Correcting sample selection bias by unlabeled data. In: Proceedings of the 2006 conference. Adv Neural Inf Process Syst. 2006. p. 601–8.
- Jakob N, Gurevych I. Extracting opinion targets in a single and cross-domain setting with conditional random felds. In: Proceedings of the 2010 conference on empirical methods in NLP. 2010. p. 1035–45.
- Jiang J, Zhai C. Instance weighting for domain adaptation in NLP. In: Proceedings of the 45th annual meeting of the association of computational linguistics. 2007. p. 264–71.
- Jiang M, Cui P, Wang F, Yang Q, Zhu W, Yang S. Social recommendation across multiple relational domains. In: Proceedings of the 21st ACM international conference on information and knowledge management. 2012. p. 1422–31.
- Jiang W, Zavesky E, Chang SF, Loui A. Cross-domain learning methods for high-level visual concept classifcation. In: IEEE 2008 15th international conference on image processing. 2008. p. 161–4.
- Kan M, Wu J, Shan S, Chen X. Domain adaptation for face recognition: targetize source domain bridged by common subspace. Int J Comput Vis. 2014;109(1–2):94–109.
- Kloft M, Brefeld U, Sonnenburg S, Zien A. Lp-norm multiple kernel learning. J Mach Learn Res. 2011;12:953–97.
- Kulis B, Saenko K, Darrell T. What you saw is not what you get: domain adaptation using asymmetric kernel transforms. In: IEEE 2011 conference on computer vision and pattern recognition. 2011. p. 1785–92.
- LeCun Y, Bottou L, HuangFu J. Learning methods for generic object recognition with invariance to pose and lighting. In: Proceedings of the 2004 IEEE computer society conference on computer vision and pattern recognition, vol. 2. 2004. p. 97–104.
- Li B, Yang Q, Xue X. Can movies and books collaborate? Cross-domain collaborative fltering for sparsity reduction. In: Proceedings of the 21st international joint conference on artifcial intelligence. 2009. p. 2052–57.
- Li B, Yang Q, Xue X. Transfer learning for collaborative fltering via a rating-matrix generative model. In: Proceedings of the 26th annual international conference on machine learning. 2009. p. 617–24.
- Li F, Pan SJ, Jin O, Yang Q, Zhu X. Cross-domain co-extraction of sentiment and topic lexicons. In: Proceedings of the 50th annual meeting of the association for computational linguistics long papers, vol. 1. 2012. p. 410–19.
- Li S, Zong C. Multi-domain adaptation for sentiment classifcation: Using multiple classifer combining methods. In: Proceedings of the conference on natural language processing and knowledge engineering. 2008. p. 1–8.
- Li W, Duan L, Xu D, Tsang IW. Learning with augmented features for supervised and semi-supervised heterogeneous domain adaptation. IEEE Trans Pattern Anal Mach Intell. 2014;36(6):1134–48.
- LIBSVM (2016) A library for support vector machines. http://www.csie.ntu.edu.tw/~cjlin/libsvm. Accessed 4 Mar 2016.
- Ling X, Dai W, Xue GR, Yang Q, Yu Y. Spectral domain-transfer learning. In: Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 2008. p. 488–96.
- Lixin Duan. http://www.lxduan.info/#sourcecode_hfa. Accessed 4 Mar 2016.
- Long M, Wang J, Ding G, Pan SJ, Yu PS. Adaptation regularization: a general framework for transfer learning. IEEE Trans Knowl Data Eng. 2014;26(5):1076–89.
- Long M, Wang J, Ding G, Sun J, Yu PS. Transfer feature learning with joint distribution adaptation. In: Proceedings of the 2013 IEEE international conference on computer vision. 2013. p. 2200–07.
- Lowe DG. Distinctive image features from scale-invariant keypoints. Int Comput Vis. 2004;60(2):91–110.
- Luo P, Zhuang F, Xiong H, Xiong Y, He Q. Transfer learning from multiple source domains via consensus regularization. In: Proceedings of the 17th ACM conference on information and knowledge management. 2008. p. 103–12.
- Ma Y, Gong W, Mao F. Transfer learning used to analyze the dynamic evolution of the dust aerosol. J Quant Spectrosc Radiat Transf. 2015;153:119–30.
- Marszalek M, Schmid C, Harzallah H, Van de Weijer J. Learning object representations for visual object class recognition. In: Visual recognition challenge workshop ICCV. 2007. p. 1–10.
- Mihalkova L, Mooney RJ. Transfer learning by mapping with minimal target data. In: Proc. assoc. for the advancement of artifcial intelligence workshop transfer learning for complex tasks. 2008. p. 31–6.
- Long M. http://ise.thss.tsinghua.edu.cn/~mlong/. Accessed 4 Mar 2016.
- Moreno O, Shapira B, Rokach L, Shani G (2012) TALMUD—transfer learning for multiple domains. In: Proceedings of the 21st ACM international conference on information and knowledge management. 2012. p. 425–34.
- Nam J, Kim S (2015) Heterogeneous defect prediction. In: Proceedings of the 2015 10th joint meeting on foundations of software engineering. 2015. p. 508–19.
- Ng MK, Wu Q, Ye Y. Co-transfer learning via joint transition probability graph based method. In: Proceedings of the 1st international workshop on cross domain knowledge discovery in web and social network mining. 2012. p. 1–9.
- Ngiam J, Khosla A, Kim M, Nam J, Lee H, Ng AY. Multimodal deep learning. In: The 28th international conference on machine learning. 2011. p. 689–96.
- Ogoe HA, Visweswaran S, Lu X, Gopalakrishnan V. Knowledge transfer via classifcation rules using functional mapping for integrative modeling of gene expression data. BMC Bioinform. 2015. p. 1–15.
- Oquab M, Bottou L, Laptev I, Sivic J. Learning and transferring mid-level image representations using convolutional neural networks. In: Proceedings of the 2014 IEEE conference on computer vision and pattern recognition. 2013. p. 1717–24.
- Pan SJ, Kwok JT, Yang Q. Transfer learning via dimensionality reduction. In: Proceedings of the 23rd national conference on artifcial intelligence, vol. 2. 2008. p. 677–82.
- Pan SJ, Ni X, Sun JT, Yang Q, Chen Z. Cross-domain sentiment classifcation via spectral feature alignment. In: Proceedings of the 19th international conference on world wide web. 2010. p. 751–60.
- Pan SJ, Yang Q. A survey on transfer learning. IEEE Trans Knowl Data Eng. 2010;22(10):1345–59.
- Pan W, Liu NN, Xiang EW, Yang Q. Transfer learning to predict missing ratings via heterogeneous user feedbacks. In:
Proceedings of the 22nd international joint conference on artifcial intelligence. 2011. p. 2318–23. - Pan W. Xiang EW, Liu NN, Yang Q. Transfer learning in collaborative fltering for sparsity reduction. In: Twenty-fourth AAAI conference on artifcial intelligence, vol. 1. 2010. p. 230–235.
- Pan SJ, Tsang IW, Kwok JT, Yang Q. Domain adaptation via transfer component analysis. IEEE Trans Neural Netw. 2009;22(2):199–210.
- Papers:oquab-2014. http://leon.bottou.org/papers/oquab-2014. Accessed 4 Mar 2016.
- Patel VM, Gopalan R, Li R, Chellappa R. Visual domain adaptation: a survey of recent advances. IEEE Signal Process Mag. 2014;32(3):53–69.
- Perlich C, Dalessandro B, Raeder T, Stitelman O, Provost F. Machine learning for targeted display advertising: transfer learning in action. Mach Learn. 2014;95:103–27.
- Prettenhofer P, Stein B. (2010) Cross-language text classifcation using structural correspondence learning. In: Proceedings of the 48th annual meeting of the association for computational linguistics. 2010. p. 1118–27.
- Qi GJ, Aggarwal C, Huang T. Towards semantic knowledge propagation from text corpus to Web images. In: Proceedings of the 20th international conference on world wide web. p. 297–306.
- Qiu G, Liu B, Bu J, Chen C. Expanding domain sentiment lexicon through double propagation. In: Proceedings of the 21st international joint conference on artifcial intelligence. p. 1199–204.
- Quanz B, Huan J. Large margin transductive transfer learning. In: Proceedings of the 18th ACM conference on information and knowledge management. 2009. p. 1327–36.
- Raina R, Battle A, Lee H, Packer B, Ng AY. Self-taught learning: transfer learning from unlabeled data. In: Proceedings of the 24th international conference on machine learning. 2007. p. 759–66.
- Rajagopal AN, Subramanian R, Ricci E, Vieriu RL, Lanz O, Ramakrishnan KR, Sebe N. Exploring transfer learning approaches for head pose classifcation from multi-view surveillance images. Int J Comput Vis. 2014;109(1–2):146–67.
- Romera-Paredes B, Aung MSH, Pontil M, Bianchi-Berthouze N, Williams AC de C, Watson P. Transfer learning to account for idiosyncrasy in face and body expressions. In: Proceedings of the 10th international conference on automatic face and gesture recognition (FG). 2013. p. 1–6.
- Rosenstein MT, Marx Z, Kaelbling LP, Dietterich TG. To transfer or not to transfer. In: Proceedings NIPS’05 workshop, inductive transfer. 10 years later. 2005. p. 1–4.
- Roy S.D., Mei T., Zeng W., Li S. Social transfer: cross-domain transfer learning from social streams for media applications. In: Proceedings of the 20th ACM international conference on multimedia. p. 649–58.
- Saenko K, Kulis B, Fritz M, Darrell T. Adapting visual category models to new domains. Comput Vision ECCV. 2010;6314:213–26.
- Schweikert G, Widmer C, Schölkopf B, Rätsch G. An empirical analysis of domain adaptation algorithms for genomic sequence analysis. Adv Neural Inf Process Syst. 2009;21:1433–40.
- Seah CW, Ong YS, Tsang IW. Combating negative transfer from predictive distribution differences. IEEE Trans Cybern. 2013;43(4):1153–65.
- Shao L, Zhu F, Li X. Transfer learning for visual categorization: a survey. IEEE Trans Neural Netw Learn Syst. 2014;26(5):1019–34.
- Shawe-Taylor J, Cristianini N. Kernel methods for pattern analysis. Cambridge: Cambridge University Press; 2004.
- Shi X, Liu Q, Fan W, Yu PS, Zhu R. Transfer learning on heterogeneous feature spaces via spectral transformation. In: 2010 IEEE international conference on data mining. 2010. p. 1049–1054.
- Shi Y, Sha F. Information-theoretical learning of discriminative clusters for unsupervised domain adaptation. In: Proceedings of the 29th international conference on machine learning. 2012. p. 1–8.
- Shimodaira H. Improving predictive inference under covariate shift by weighting the log-likelihood function. J Stat Plan Inf. 2000;90(2):227–44.
- Shivaji S, Whitehead EJ, Akella R, Kim S. Reducing features to improve code change-based bug prediction. IEEE Trans Softw Eng. 2013;39(4):552–69.
- Si S, Tao D, Geng B. Bregman divergence-based regularization for transfer subspace learning. IEEE Trans Knowl Data Eng. 2010;22(7):929–42.
- Song Z, Chen Q, Huang Z, Hua Y, Yan S. Contextualizing object detection and classifcation. IEEE Trans Pattern Anal Mach Intell. 2011;37(1):13–27. 111. Steinwart I. On the influence of the kernel on the consistency of support vector machines. JMLR. 2001;2:67–93.
- Taylor ME, Stone P. Transfer learning for reinforcement learning domains: a survey. JMLR. 2009;10:1633–85.
- Tommasi T, Caputo B. The more you know, the less you learn: from knowledge transfer to one-shot learning of object categories. BMVC. 2009;1–11.
- Tommasi T, Orabona F, Caputo B. Safety in numbers: learning categories from few examples with multi model knowledge transfer. IEEE Conf Comput Vision Pattern Recog. 2010;2010:3081–8.
- Transfer learning resources. http://www.cse.ust.hk/TL/. Accessed 4 Mar 2016.
- Tutorial on domain adaptation and transfer learning. http://tommasit.wix.com/datl14tutorial. Accessed 4 Mar 2016.
- Vapnik V. Principles of risk minimization for learning theory. Adv Neural Inf Process Syst. 1992;4:831–8.
- Vedaldi A, Gulshan V, Varma M, Zisserman A. Multiple kernels for object detection. In: 2009 IEEE 12th international conference on computer vision. 2009. p. 606–13.
- Vincent P, Larochelle H, Bengio Y, Manzagol PA. Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th international conference on machine learning. 2008. p. 1096–103.
- Vinokourov A, Shawe-Taylor J, Cristianini N. Inferring a semantic representation of text via crosslanguage correlation analysis. Adv Neural Inf Proces Syst. 2002;15:1473–80.
- Wang C, Mahadevan S. Heterogeneous domain adaptation using manifold alignment. In: Proceedings of the 22nd international joint conference on artifcial intelligence, vol. 2. 2011. p. 541–46.
- Wang G, Hoiem D, Forsyth DA. Building text Features for object image classifcation. In: 2009 IEEE conference on computer vision and pattern recognition. 2009. p. 1367–74.
- Wang H, Klaser A, Schmid C, Liu CL (2011) Action recognition by dense trajectories. In: IEEE 2011 conference on computer vision and pattern recognition. 2011. p. 3169–76.
- Wei B, Pal C (2010) Cross-lingual adaptation: an experiment on sentiment classifcations. In: Proceedings of the ACL 2010 conference short papers. 2010. p. 258–62.
- Wei B, Pal C (2011) Heterogeneous transfer learning with RBMs. In: Proceedings of the twenty-ffth AAAI conference on artifcial intelligence. 2011. p. 531–36.
- Weinberger KQ, Saul LK. Distance metric learning for large margin nearest neighbor classifcation. JMLR. 2009;10:207–44.
- Widmer C, Ratsch G. Multitask learning in computational biology. JMLR. 2012;27:207–16.
- Wiens J, Guttag J, Horvitz EJ. A study in transfer learning: leveraging data from multiple hospitals to enhance hospital-specifc predictions. J Am Med Inform Assoc. 2013;21(4):699–706.
- Witten IH, Frank E. Data mining, practical machine learning tools and techniques. 3rd ed. San Francisco: Morgan Kaufmann Publishers; 2011.
- Wu X, Xu D, Duan L, Luo J (2011) Action recognition using context and appearance distribution features. In: IEEE 2011 conference on computer vision and pattern recognition. 2011. p. 489–96.
- Xia R, Zong C. A POS-based ensemble model for cross-domain sentiment classifcation. In: Proceedings of the 5th international joint conference on natural language processing. 2011. p. 614–22.
- Xia R, Zong C, Hu X, Cambria E. Feature ensemble plus sample selection: domain adaptation for sentiment classifcation. IEEE Intell Syst. 2013;28(3):10–8.
- Xiao M, Guo Y. Semi-supervised kernel matching for domain adaptation. In: Proceedings of the twenty-sixth AAAI conference on artifcial intelligence. 2012. p. 1183–89.
- Xie M, Jean N, Burke M, Lobell D, Ermon S. Transfer learning from deep features for remote sensing and poverty mapping. In: Proceedings 30th AAAI conference on artifcial intelligence. 2015. p. 1–10.
- Yang J, Yan R, Hauptmann AG. Cross-domain video concept detection using adaptive SVMs. In: Proceedings of the 15th ACM international conference on multimedia. 2007. p. 188–97.
- Yang L, Jing L, Yu J, Ng MK. Learning transferred weights from co-occurrence data for heterogeneous transfer learning. IEEE Trans Neural Netw Learn Syst. 2015;PP(99):1–14.
- Yang Q, Chen Y, Xue GR, Dai W, Yu Y. Heterogeneous transfer learning for image clustering via the social web. In: Proceedings of the joint conference of the 47th annual meeting of the ACL, vol. 1. 2009. p. 1–9.
- Yao Y, Doretto G. Boosting for transfer learning with multiple sources. In: Proceedings of the IEEE computer society conference on computer vision and pattern recognition. 2010. p. 1855–62.
- Yin Z. http://www.cse.ust.hk/~yinz/. Accessed 4 Mar 2016.
- Zhang Y, Cao B, Yeung D. Multi-domain collaborative fltering. In: Proceedings of the 26th conference on uncertainty in artifcial intelligence. 2010. p. 725–32.
- Zhang Y, Yeung DY. Transfer metric learning by learning task relationships. In: Proceedings of the 16th ACM SIGKDD international conference on knowledge discovery and data mining. 2010. p. 1199–208.
- Zhao L, Pan SJ, Xiang EW, Zhong E, Lu Z, Yang Q. Active transfer learning for cross-system recommendation. In: Proceedings of the 27th AAAI conference on artifcial intelligence. 2013. p. 1205–11.
- Zhong E, Fan W, Peng J, Zhang K, Ren J, Turaga D, Verscheure O. Cross domain distribution adaptation via kernel
mapping. In: Proceedings of the 15th ACM SIGKDD. 2009. p. 1027–36. - Zhou JT, Pan S, Tsang IW, Yan Y. Hybrid heterogeneous transfer learning through deep learning. In: Proceedings of the national conference on artifcial intelligence, vol. 3. 2014. p. 2213–20.
- Zhou JT, Tsang IW, Pan SJ Tan M. Heterogeneous domain adaptation for multiple classes. In: International conference on artifcial intelligence and statistics. 2014. p. 1095–103.
- Zhu Y, Chen Y, Lu Z, Pan S, Xue G, Yu Y, Yang Q. Heterogeneous transfer learning for image classifcation. In: Proceedings of the national conference on artifcial intelligence, vol. 2. 2011. p. 1304–9.
最后
以上就是平常乐曲最近收集整理的关于2016《A survey of transfer learning》迁移学习笔记的全部内容,更多相关2016《A内容请搜索靠谱客的其他文章。








发表评论 取消回复