前言
秒杀一般出现在商城的促销活动中,指定了一定数量(比如:10个)的商品(比如:手机),以极低的价格(比如:0.1元),让大量用户参与活动,但只有极少数用户能够购买成功。这类活动商家绝大部分是不赚钱的,说白了是找个噱头宣传自己。
秒杀特点是持续时间短,抢购人数多,参与人数远远高于商品数量。抢购开始前后大量用户请求涌入,极易给服务造成巨大压力。如果系统设计不当,还容易造成超卖、少卖、数据丢失、服务雪崩等问题。
本文我们主要讨论在秒杀的高并发场景下,传统订单架构存在的性能瓶颈,如何利用 redis、MQ 等中间件对系统做优化,解决缓存加速、防止重复提交、排队下单、超卖、少卖、削峰、异步下单等核心问题。
瞬时高并发
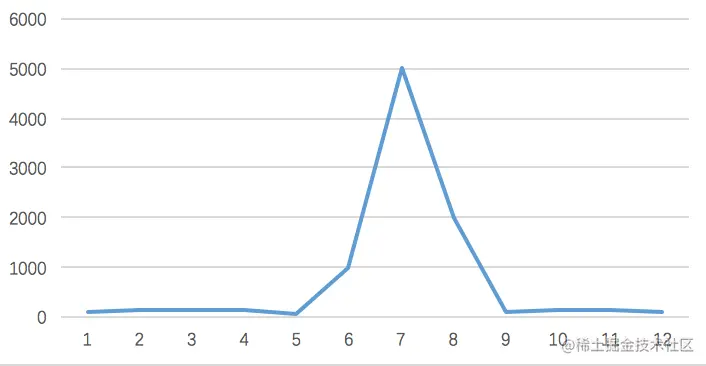
一般秒杀活动都会在12点、0点进行,在秒杀活动开始前几分钟,就会出现大量的用户请求,并发量达到高峰。
正常情况下,都是大量用户抢同一个商品,僧多肉少,大部分的请求都是无效的,只有少部分的请求才能成功。
我们看下图直观了解下流量的变化:
像这种瞬时高并发的场景,传统的系统很难应对,我们需要设计一套全新的系统。可以从以下几个方面入手:
- 页面静态化
- CDN加速
- 负载均衡
- 防重
- 缓存
- 异步
- 熔断、限流
- 分布式锁
总而言之:分层过滤,分而治之。
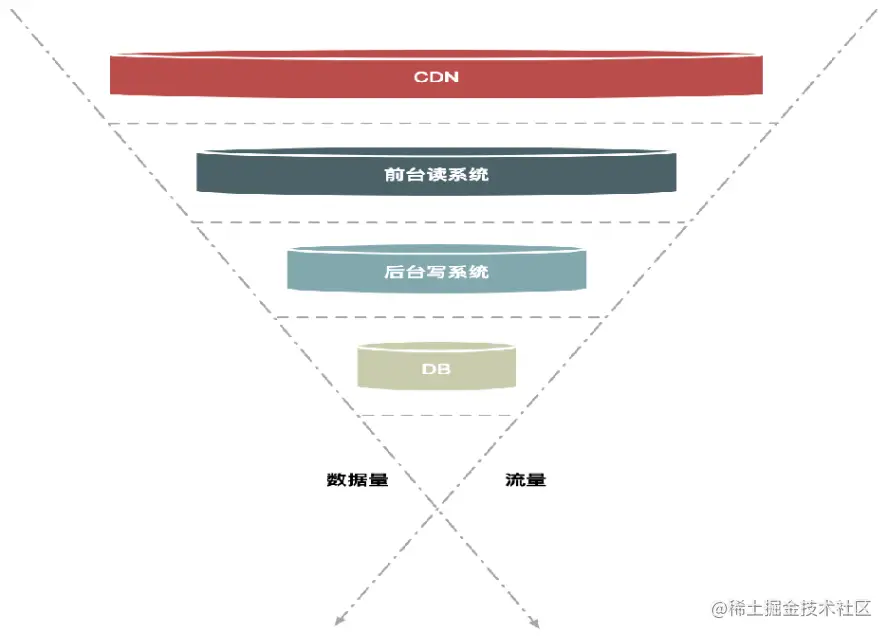
独立部署
秒杀活动只是网站营销的一个附加活动,这个活动具有时间短,并发访问量大的特点,如果和网站原有应用部署在一起,必然会对现有业务造成冲击,稍有不慎可能导致整个网站瘫痪。
那我们可以考虑将秒杀系统独立部署,甚至使用独立域名,使其与网站完全隔离。
页面优化
页面优化之【静态化】
秒杀页面是用户访问的一道关卡,流量进来的第一步,并发量最高。
这些请求肯定不能直接作用于服务器,会导致服务器雪崩、宕机。
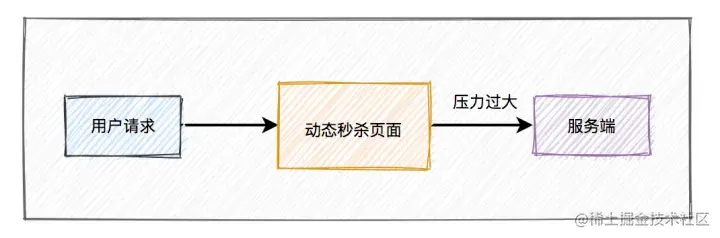
秒杀的商品信息页面其实固定的,包含了商品的基本信息,sku、spu等,比如商品名、商品图片、属性等,为了减少不必要的服务端请求,通常情况下,重新设计秒杀商品页面,不使用网站原来的商品详情页面,对活动页面做静态化????处理。用户浏览商品等常规操作,并不会请求到服务端。只有到了秒杀时间点,并且用户主动点了秒杀按钮才允许访问服务端。
????静态化就是指把原本动态生成的html页面变为静态内容保存,用户客户端请求的时候,直接返回静态页面,不用再经过服务渲染,不用访问数据库,可以大大的减小数据库的压力,显著的提高性能。
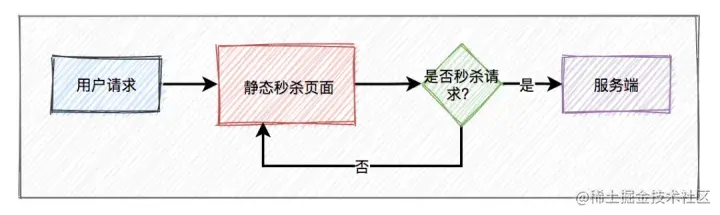
静态化能过滤大部分无效请求。
但只做页面静态化还不够,因为用户分布在全国各地,地域相差甚远,网速各不相同。
如何才能让用户最快访问到活动页面呢?
这就需要使用CDN,它的全称是Content Delivery Network,即内容分发网络。CDN 是依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
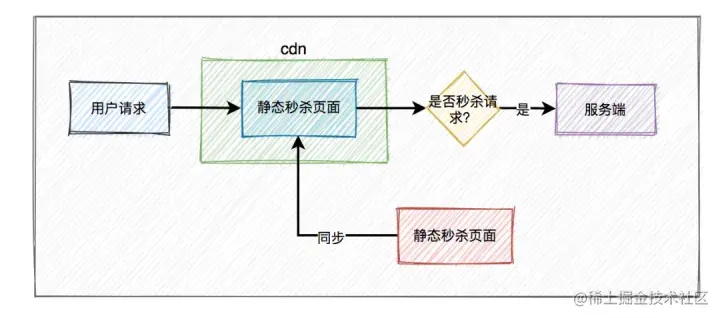
使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
页面优化之【秒杀按钮】
大部分用户都会提前进入活动页面。此时看到的秒杀按钮是置灰的,不可点击的。只有到了秒杀时间点那一时刻,秒杀按钮才会自动点亮,变成可点击状态。
但此时很多用户都会通过不断刷新页面,争取第一时间点击秒杀按钮。
从前面得知,该活动页面是静态的。那么我们在静态页面中如何控制秒杀按钮,只在秒杀时间点时才点亮呢?
没错,使用JavaScript脚本控制。
为了性能考虑,一般会将css、js和图片等静态资源文件提前缓存到CDN上,让用户能够就近访问秒杀页面。
看到这里,有些聪明的小伙伴,可能会问:CDN上的js文件是如何更新的?
在秒杀商品静态页面中加入一个JavaScript文件引用,该JavaScript文件中包含秒杀开始标志为false,还有另外一个随机参数。
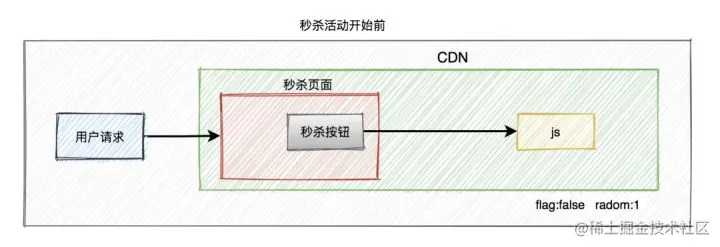
当秒杀开始的时候生成一个新的JavaScript文件(文件名保持不变,只是内容不一样),更新秒杀开始标志为true,加入下单页面的URL及随机数参数(这个随机数只会产生一个,即所有人看到的URL都是同一个,服务器端可以用redis这种分布式缓存服务器来保存随机数),并被用户浏览器加载,控制秒杀商品页面的展示。这个JavaScript文件的加载可以加上随机版本号(例如xx.js?v=32353823),这样就不会被浏览器、CDN和反向代理服务器缓存。
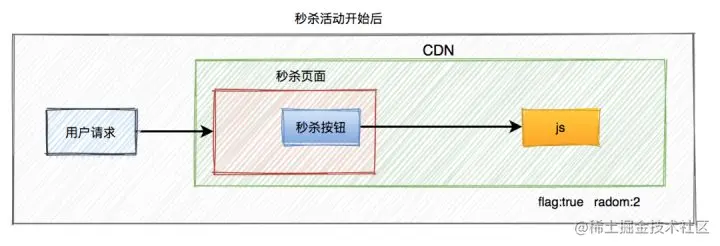
此外,前端还可以加一个定时器,控制比如:10秒之内,只允许发起一次请求。如果用户点击了一次秒杀按钮,则在10秒之内置灰,不允许再次点击,等到过了时间限制,又允许重新点击该按钮。
页面优化之【浏览器层请求拦截】
(1)产品层面,用户点击“查询”或者“秒杀”后,按钮置灰,禁止用户重复提交请求;
(2)JS层面,限制用户在x秒之内只能提交一次请求;
负载均衡
高并发的系统架构都会采用分布式集群部署,服务上层有着层层负载均衡,并提供各种容灾手段(双活机房➊、节点容错、服务器灾备等)保证系统的高可用,流量也会根据不同的负载能力和配置策略均衡到不同的服务器上。下边是一个简单的示意图:
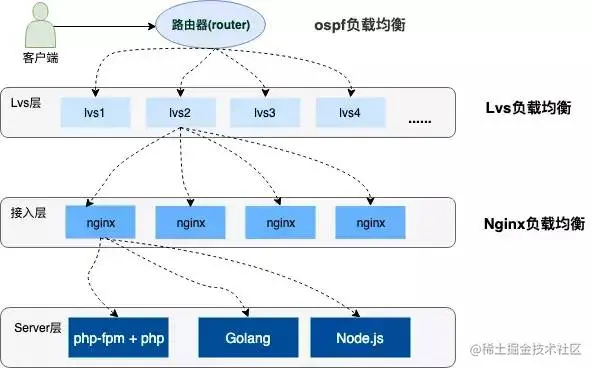
➊双活机房 当下互联网高度发展中为了避免因受到自然灾害、网络瘫痪等灾难性事件影响,互联网企业一般都会采用异地多活(单元化)的部署方式,来预防单机房故障而引发业务中断和资金的损失。简单理解,万一其中一个机房发生不测,还有另外一个机房可以热备。就像购买了一份重症医疗保单,缩短极端场景的业务恢复时间(从8小时缩短到2-3分钟)。
负载均衡之【OSPF】
OSPF(开放式最短链路优先)是一个内部网关协议(Interior Gateway Protocol,简称IGP)。OSPF通过路由器之间通告网络接口的状态来建立链路状态数据库,生成最短路径树,OSPF会自动计算路由接口上的Cost❷值,但也可以通过手工指定该接口的Cost值,手工指定的优先于自动计算的值。OSPF计算的Cost,同样是和接口带宽成反比,带宽越高,Cost值越小。到达目标相同Cost值的路径,可以执行负载均衡,最多6条链路同时执行负载均衡。
❷Cost
- OSPF使用cost(开销)作为路由度量值。
- 每一个激活OSPF的接口都有一个cost值。OSPF接口cost=100M/接口带宽,其中100M为OSPF的参考带宽(reference-bandwidth)。
- 一条OSPF路由的cost由该路由从路由的起源一路到达本地的所有入接口cost值的总和。
由于默认的参考带宽是100M,这意味着更高带宽的传输介质(高于100M)在OSPF协议中将会计算出一个小于1的分数,这在OSPF协议中是不允许的(会被四舍五入为1)。而现今网络设备很多都是大于100M带宽的接口,这时候路由cost的计算其实就不精确了。所以可以使用bandwidth-reference命令修改,但是这条命令要谨慎使用,一旦要配置,则建议全网OSPF路由器都配置。
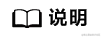
负载均衡之【LVS】
LVS,它的全称是Linux VirtualServer,它是一种集群(Cluster)技术,采用IP负载均衡技术和基于内容请求分发技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。
负载均衡之【Nginx】
Nginx是一款非常高性能的http代理/反向代理服务器,服务开发中也经常使用它来做负载均衡。Nginx实现负载均衡的方式主要有三种:轮询、加权轮询、ip hash轮询。
轮询
轮询策略其实是一个特殊的加权策略,不同的是,服务器组中的各个服务器的权重都是1
upstream backend {
server 120.0.0.1 weight=1;
server 120.0.0.1 weight=1;
server 120.0.0.1 weight=1;
server 120.0.0.1 weight=1;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
复制代码加权轮询
通过加入 weight的值进行加权处理,权重值越大,服务器越容易被访问,因此,性能好的服务器应适当加大权重值
upstream backend {
server 120.0.0.1 weight=1;
server 120.0.0.1:81 weight=2;
server 120.0.0.1:82 weight=3;
server 120.0.0.1:83 weight=4;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
复制代码ip hash轮询
ip_hash 策略能够将某个客户端IP的请求固定到同一台服务器上,例如A用户访问服务器,通过固定算法后,被固定到 192.168.136.136 的web服务器上,那么,用户A下次访问时,依旧会到访问 192.168.136.136 服务器。因此,该策略解决了多台服务器Session不共享的问题[为不同的客户端会被分到不同的服务器,且之后这种对应关系是不变的]
ip_hash 策略类似于url_hash ,一个采用Ip地址进行计算,一个采用URL地址进行计算。
upstream backend {
ip_hash;
server 192.168.136.136 ;
server 192.168.136.136:81;
server 192.168.136.136:82 ;
server 192.168.136.136:83;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
复制代码该算法不能保证服务器的负载均衡,可能存在个别服务器访问量很大,很小的情况.
另外,实际生产环境不建议使用此算法,如果要解决session共享的问题,我们可以使用第三方中间件 redis 来完成共享问题
缓存
缓存之【读多写少】
秒杀下单后,需要校验是否存在库存(查询库存),存在库存才下单成功,进行库存扣减(更新库存),如果不存在库存会返回秒杀失败。
由于大量用户抢少量商品,只有极少部分用户能够抢成功,所以绝大部分用户在秒杀时,库存其实是不足的,系统会直接返回该商品已经抢完。
这是非常典型的:读多写少 的场景。
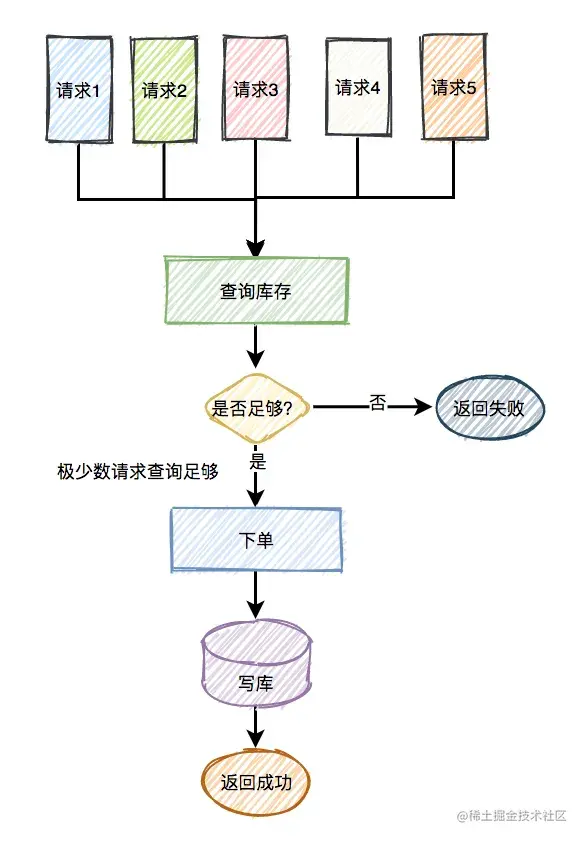
如果千万级别的请求过来,查询数据库可能导致数据库挂掉,并且数据库的连接资源有限,比如:mysql,无法同时支持这么多的连接。同时数据库的成本也比较高。
而应该改用缓存,比如:redis。
即便用了redis,也需要部署多个节点。
缓存之【缓存预热】
将部分业务逻辑写到缓存里,不需要直接读数据库,来减少数据库服务器的压力,这样访问速度会更快。
在秒杀开始前,提前将商品id、商品名称、sku、库存等信息写入Redis中。这同样是一个减少数据库压力的方式。
定时任务缓存预热
(1)定时任务将 状态为已发布且未开始的秒杀活动、秒杀商品写入redis缓存;
(2)扫描已过期的秒杀活动,移除缓存。
定时任务写入商品信息
@Scheduled("*************************")
public void pushSeckillInfoIntoRedis() {
//查询未开始的秒杀活动信息
List<RedisSeckill> seckillList = seckillMapper.selectSeckillOfNotStart();
//查询秒杀商品信息
List<RedisSeckillSku> seckillSkuList = seckillSkuMapper.selectSkuList();
//根据活动分组
Map<Long, List<RedisSeckillSku>> groupSeckillSkuList = seckillSkuList.stream().collect(Collectors.groupingBy(RedisSeckillSku::getSeckillId));
//秒杀活动存储到redis
for (RedisSeckill seckill : seckillList) {
redisTemplate.opsForHash()
.put("hosjoy-seckill-test:seckill-info", seckillId, seckill);
}
//秒杀商品存储到redis
for (Map.Entry<Long, List<RedisSeckillSku>> entry : groupSeckillSkuList.entrySet()) {
Long seckillId = entry.getKey;
List<RedisSeckillSku> skuList = entry.getValue();
for (RedisSeckillSku sku : skuList) {
redisTemplate.opsForHash()
.put("hosjoy-seckill-test:seckill-sku:" + seckillId, sku.getId, sku);
}
}
}
复制代码定时扫描过期数据
扫描已经结束的秒杀活动和秒杀商品缓存,清理无用数据。
//删除已过期活动
List<Long> expireSeckills = new ArrayList<>();
List<RedisSeckill> seckills = redisTemplate.opsForHash().values("hosjoy-seckill-test:seckill-info");
LocalDateTime now = LocalDateTime.now();
seckills.forEach(s -> {
LocalDateTime endTime = s.getEndTime();
if (now.after(endTime)) {
expireSeckills.add(s.getId());
redisTemplate.opsForHash().delete("hosjoy-seckill-test:seckill-info", s.getId());
}
});
//删除已过期sku
expireSeckills.forEach(seckillId -> {
redisTemplate.opsForHash().delete("hosjoy-seckill-test:seckill-sku:" + seckillId);
});
复制代码缓存之【常见问题】
通常情况下,我们需要在redis中保存商品信息,里面包含:商品id、商品名称、sku、库存等信息,同时数据库中也要有相关信息,毕竟缓存并不完全可靠。
用户在点击秒杀按钮,请求秒杀接口的过程中,需要传入的商品id参数,然后服务端需要校验该商品是否合法。
大致流程如下图所示:
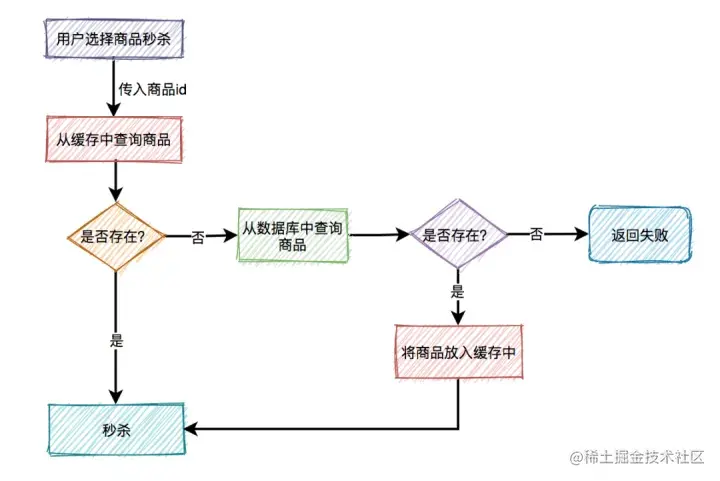
根据商品id,先从缓存中查询商品,如果商品存在,则参与秒杀。如果不存在,则需要从数据库中查询商品,如果存在,则将商品信息放入缓存,然后参与秒杀。如果商品不存在,则直接提示失败。
这个过程表面上看起来是OK的,但是如果深入分析一下会发现一些问题。
缓存击穿
比如商品A第一次秒杀时,缓存中是没有数据的(缓存过期)数据库中有。虽说上面有如果从数据库中查到数据,则放入缓存的逻辑。
然而,在高并发下,同一时刻会有大量的请求,都在秒杀同一件商品,这些请求同时去查缓存中没有数据,然后又同时访问数据库。结果悲剧了,数据库可能扛不住压力,直接挂掉。
如何解决这个问题呢?
这就需要加锁,最好使用分布式锁。
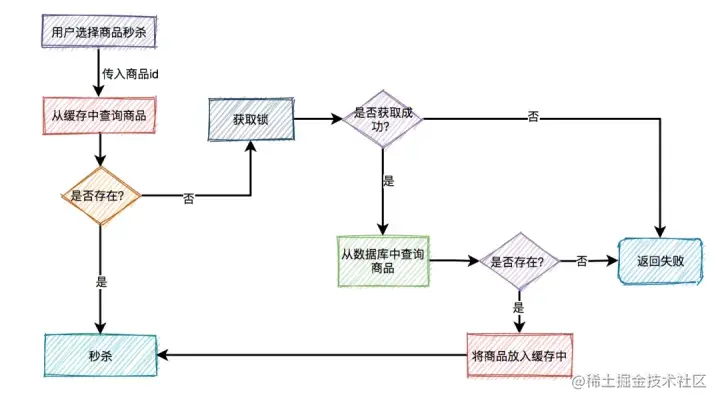
当然,针对这种情况,最好在项目启动之前,先把缓存进行预热。即事先把所有的商品,同步到缓存中,这样商品基本都能直接从缓存中获取到,就不会出现缓存击穿的问题了。
是不是上面加锁这一步可以不需要了?
表面上看起来,确实可以不需要。但如果缓存中设置的过期时间不对,缓存提前过期了,或者缓存被不小心删除了,如果不加速同样可能出现缓存击穿。
其实这里加锁,相当于买了一份保险。
缓存穿透
如果有大量的请求传入的商品id,在缓存中和数据库中都不存在,这些请求不就每次都会穿透过缓存,而直接访问数据库了。
由于前面已经加了锁,所以即使这里的并发量很大,也不会导致数据库直接挂掉。
但很显然这些请求的处理性能并不好,有没有更好的解决方案?
这时可以想到布隆过滤器。
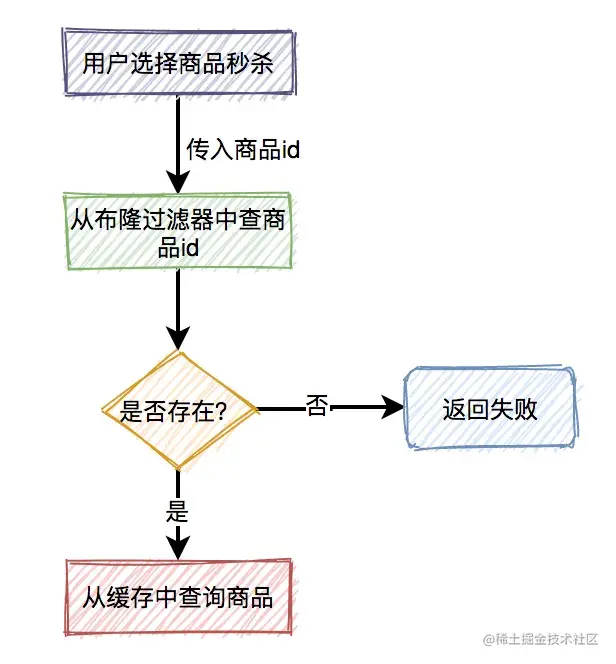
系统根据商品id,先从布隆过滤器中查询该id是否存在,如果存在则允许从缓存中查询数据,如果不存在,则直接返回失败。
虽说该方案可以解决缓存穿透问题,但是又会引出另外一个问题:布隆过滤器中的数据如何更缓存中的数据保持一致?
这就要求,如果缓存中数据有更新,则要及时同步到布隆过滤器中。如果数据同步失败了,还需要增加重试机制,而且跨数据源,能保证数据的实时一致性吗?
显然是不行的。
所以布隆过滤器绝大部分使用在缓存数据更新很少的场景中。
如果缓存数据更新非常频繁,又该如何处理呢?
这时,就需要把不存在的商品id也缓存起来。
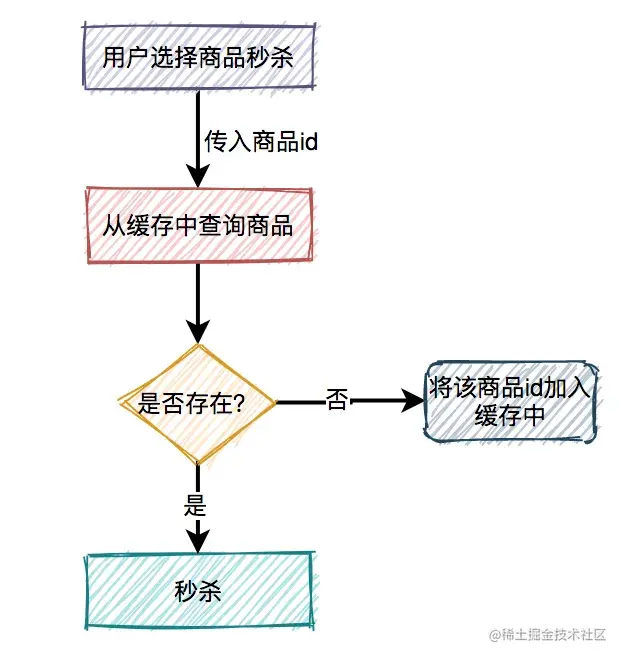
下次,再有该商品id的请求过来,则也能从缓存中查到数据,只不过该数据比较特殊,表示商品不存在。需要特别注意的是,这种特殊缓存设置的超时时间应该尽量短一点。
下单
下单之【重复提交校验】
秒杀和抢购收到了“海量”的请求,实际上里面的水分是很大的。不少用户,为了“抢“到商品,会使用“刷票工具”等类型的辅助工具,帮助他们发送尽可能多的请求到服务器。还有一部分高级用户,制作强大的自动请求脚本。
这种做法的理由也很简单,就是在参与秒杀和抢购的请求中,自己的请求数目占比越多,成功的概率越高。这些都是属于“作弊的手段”,不过,有“进攻”就有“防守”,这是一场没有硝烟的战斗哈。
同一个账号,一次性发出多个请求
部分用户通过浏览器的插件或者其他工具,在秒杀开始的时间里,以自己的账号,一次发送上百甚至更多的请求。
实际上,这样的用户破坏了秒杀和抢购的公平性。这种请求在某些没有做数据安全处理的系统里,也可能造成另外一种破坏,导致某些判断条件被绕过。
例如一个简单的领取逻辑,先判断用户是否有参与记录,如果没有则领取成功,最后写入到参与记录中。这是个非常简单的逻辑,但是,在高并发的场景下,存在深深的漏洞。
多个并发请求通过负载均衡服务器,分配到内网的多台Web服务器,它们首先向存储发送查询请求,然后,在某个请求成功写入参与记录的时间差内,其他的请求获查询到的结果都是“没有参与记录”。这里,就存在逻辑判断被绕过的风险。
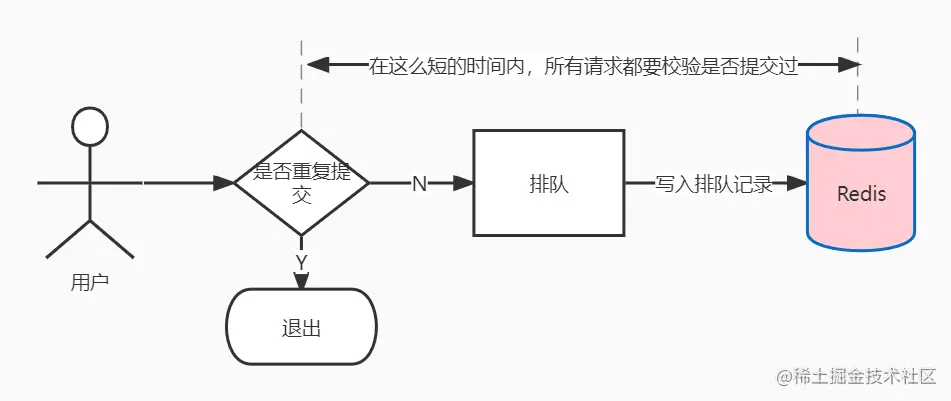
应对方案: 在程序入口处,一个账号只允许接受1个请求,其他请求过滤。不仅解决了同一个账号,发送N个请求的问题,还保证了后续的逻辑流程的安全。
方案一:利用redis的increment操作,记录用户请求提交次数,如果是第一次秒杀请求,increment后的值肯定为1,则允许排队;如果值大于1,说明重复提交。
这里不需要加锁判断,不用担心并发问题,多线程环境下,各个线程获取到的currentUserQueue肯定是准确的(redis单线程操作特性)。
//当前用户提交次数
Long currentUserSubmitNums = redisTemplate.opsForHash().increment("hosjoy-seckill-test:seckill-user-queue-count:" + seckillId + seckillSkuId, userId, 1);
if (currentUserSubmitNums > 1) {
throw new ClientException("您已提交了订单,请勿重复提交");
}
复制代码方案二:内存缓存服务,写入一个标志位(只允许1个请求写成功,结合watch的乐观锁的特性),成功写入的则可以继续参加。
或者,自己实现一个服务,将同一个账号的请求放入一个队列中,处理完一个,再处理下一个。
多个账号,一次性发送多个请求
很多公司的账号注册功能,在发展早期几乎是没有限制的,很容易就可以注册很多个账号。因此,也导致了出现了一些特殊的工作室,通过编写自动注册脚本,积累了一大批“僵尸账号”,数量庞大,几万甚至几十万的账号不等,专门做各种刷的行为(这就是微博中的“僵尸粉“的来源)。
举个例子,例如微博中有转发抽奖的活动,如果我们使用几万个“僵尸号”去混进去转发,这样就可以大大提升我们中奖的概率。这种账号,使用在秒杀和抢购里,也是同一个道理。例如,iPhone官网的抢购,火车票黄牛党。
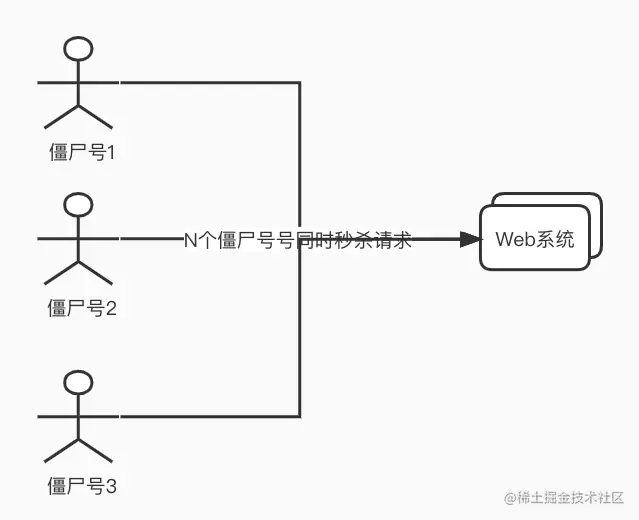
应对方案: 这种场景,可以通过检测指定机器IP请求频率就可以解决,如果发现某个IP请求频率很高,可以给它弹出一个验证码或者直接禁止它的请求:
➑方案一:加验证码的方式可能更精准一些,同样能限制用户的访问频次,但好处是不会存在误杀的情况。
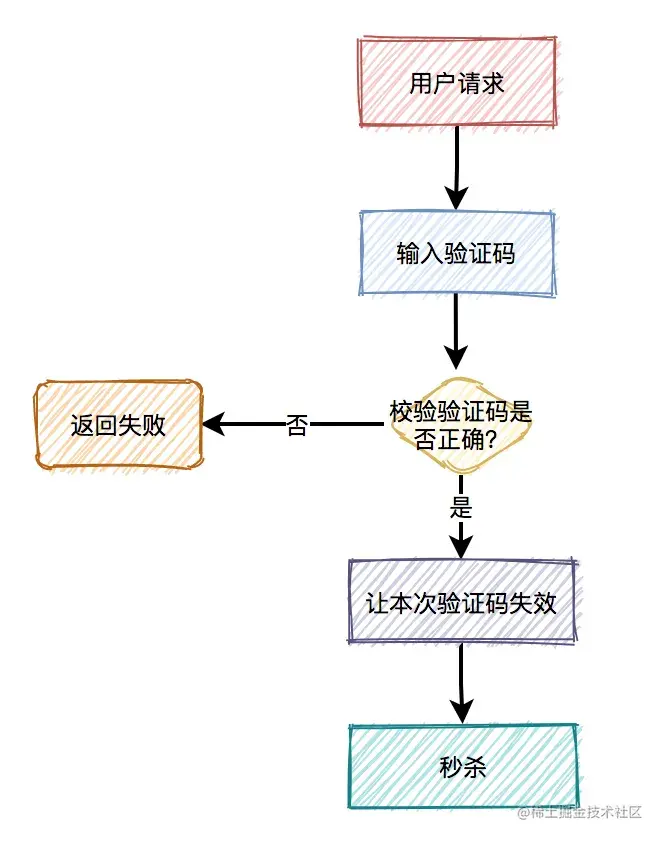
通常情况下,用户在请求之前,需要先输入验证码。用户发起请求之后,服务端会去校验该验证码是否正确。只有正确才允许进行下一步操作,否则直接返回,并且提示验证码错误。
此外,验证码一般是一次性的,同一个验证码只允许使用一次,不允许重复使用。
普通验证码,由于生成的数字或者图案比较简单,可能会被破解。优点是生成速度比较快,缺点是有安全隐患。
还有一个验证码叫做:移动滑块,它生成速度比较慢,但比较安全,是目前各大互联网公司的首选。
方案二:直接禁止IP,实际上是有些粗暴的,因为有些真实用户的网络场景恰好是同一出口IP的,可能会有“误伤“。但是这一个做法简单高效,根据实际场景使用可以获得很好的效果。
多个账号,不同IP发送不同请求
所谓道高一尺,魔高一丈。有进攻,就会有防守,永不休止。这些“工作室”,发现你对单机IP请求频率有控制之后,他们也针对这种场景,想出了他们的“新进攻方案”,就是不断改变IP。
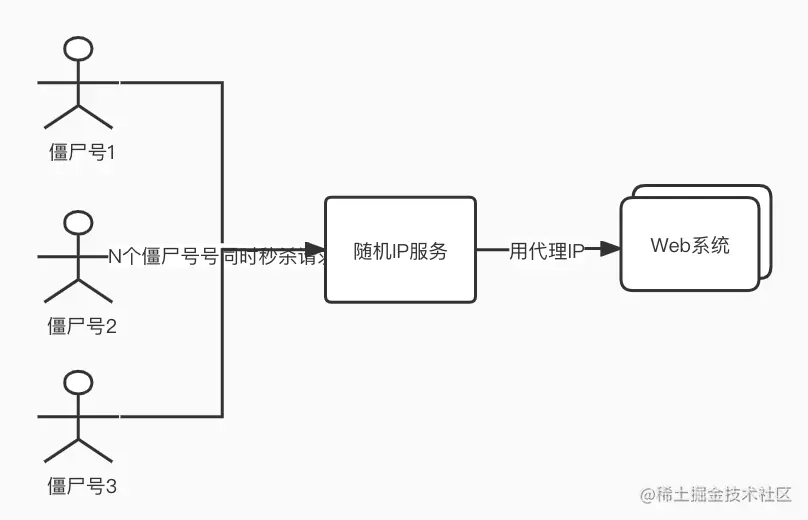
有同学会好奇,这些随机IP服务怎么来的。有一些是某些机构自己占据一批独立IP,然后做成一个随机代理IP的服务,有偿提供给这些“工作室”使用。还有一些更为黑暗一点的,就是通过木马黑掉普通用户的电脑,这个木马也不破坏用户电脑的正常运作,只做一件事情,就是转发IP包,普通用户的电脑被变成了IP代理出口。通过这种做法,黑客就拿到了大量的独立IP,然后搭建为随机IP服务,就是为了挣钱。
应对方案:
说实话,这种场景下的请求,和真实用户的行为,已经基本相同了,想做分辨很困难。再做进一步的限制很容易“误伤“真实用户,这个时候,通常只能通过设置业务门槛高来限制这种请求了,或者通过账号行为的”数据挖掘“来提前清理掉它们。僵尸账号也还是有一些共同特征的,例如账号很可能属于同一个号码段甚至是连号的,活跃度不高,等级低,资料不全等等。根据这些特点,适当设置参与门槛,例如限制参与秒杀的账号等级。通过这些业务手段,也是可以过滤掉一些僵尸号。
下单之【黑名单校验】
用户如果多次提交订单失败,有可能是恶意刷单,也可能是该用户不符合购买条件导致提交订单失败(实际业务校验不通过),可以在提交订单失败后将该用户加入黑名单,在提交订单前校验该用户是否为黑名单用户。
Long failCount = redisTemplate.opsForHash().get("hosjoy-seckill-test:seckill-black-user:" + seckillId + seckillSkuId, userId);
if (failCount > SeckillConstants.MAX_FAIL_TIMES) {
throw new ClientException("您不符合购买条件");
}
复制代码下单之【商品校验】
在秒杀的时候,需要先从缓存中查商品是否存在,如果不存在,则会从数据库中查商品。如果数据库中,则将该商品放入缓存中,然后返回。如果数据库中没有,则直接返回失败。
大家试想一下,如果在高并发下,有大量的请求都去查一个缓存中不存在的商品,这些请求都会直接打到数据库。数据库由于承受不住压力,而直接挂掉。
那么如何解决这个问题呢?
这就需要用redis分布式锁了。
分布式锁
1. setNx加锁
使用redis的分布式锁,首先想到的是setNx命令。
if (jedis.setnx(lockKey, val)) {
jedis.expire(lockKey, timeout);
}
复制代码用该命令其实可以加锁,加锁操作和设置过期操作本身都是原子性的,但两者一起并非原子操作。
假如加锁成功了,但是设置超时时间失败了,该lockKey就变成永不失效的了。在高并发场景中,该问题会导致非常严重的后果。
那么,有没有保证原子性的加锁命令呢?
2. set加锁
使用redis的set命令,它可以指定多个参数。
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
复制代码其中:
- lockKey:锁的标识
- requestId:请求id
- NX:只在键不存在时,才对键进行设置操作。
- PX:设置键的过期时间为 millisecond 毫秒。
- expireTime:过期时间
由于该命令只有一步,所以它是原子操作。
3. 释放锁
接下来,有些朋友可能会问:在加锁时,既然已经有了lockKey锁标识,为什么要需要记录requestId呢?
答:requestId是在释放锁的时候用的。
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
return true;
}
return false;
复制代码在释放锁的时候,只能释放自己加的锁,不允许释放别人加的锁。
这里为什么要用requestId,用userId不行吗?
答:如果用userId的话,假设本次请求流程走完了,准备删除锁。此时,巧合锁到了过期时间失效了。而另外一个请求,巧合使用的相同userId加锁,会成功。而本次请求删除锁的时候,删除的其实是别人的锁了。
当然使用lua脚本也能避免该问题:
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
复制代码它能保证查询锁是否存在和删除锁是原子操作。
4. 自旋锁
上面的加锁方法看起来好像没有问题,但如果你仔细想想,如果有1万的请求同时去竞争那把锁,可能只有一个请求是成功的,其余的9999个请求都会失败。
在秒杀场景下,会有什么问题?
答:每1万个请求,有1个成功。再1万个请求,有1个成功。如此下去,直到库存不足。这就变成均匀分布的秒杀了,跟我们想象中的不一样。
如何解决这个问题呢?
答:使用自旋锁。
try {
Long start = System.currentTimeMillis();
while(true) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
long time = System.currentTimeMillis() - start;
if (time >= timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally{
unlock(lockKey,requestId);
}
return false;
复制代码在规定的时间,比如500毫秒内,自旋不断尝试加锁,如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。
5. redisson
除了上面的问题之外,使用redis分布式锁,还有锁竞争问题、续期问题、锁重入问题、多个redis实例加锁问题等。这些问题使用redisson都可以解决。
库存
对于库存问题看似简单,实则里面还是有些东西。
真正的秒杀商品的场景,不是说扣完库存,就完事了,如果用户在一段时间内,还没完成支付,扣减的库存需要回滚。
➌库存之【库存扣减方案】
1. 下单减库存
当用户并发请求到达服务端时,首先创建订单,然后扣除库存,等待用户支付。这种顺序是我们一般人首先会想到的解决方案,这种情况下也能保证订单不会超卖,因为创建订单之后就会减库存,这是一个原子操作。但是这样也会产生一些问题,第一就是在极限并发情况下,任何一个内存操作的细节都至关影响性能,尤其像创建订单这种逻辑,一般都需要存储到磁盘数据库的,对数据库的压力是可想而知的;第二是如果用户存在恶意下单的情况,只下单不支付这样库存就会变少,会少卖很多订单,虽然服务端可以限制IP和用户的购买订单数量,这也不算是一个好方法。

2 支付减库存
如果等待用户支付了订单在减库存,第一感觉就是不会少卖。但是这是并发架构的大忌,因为在极限并发情况下,用户可能会创建很多订单,当库存减为零的时候很多用户发现抢到的订单支付不了了,这也就是所谓的“超卖”。也不能避免并发操作数据库磁盘IO

3. 预扣库存
从上边两种方案的考虑,我们可以得出结论:只要创建订单,就要频繁操作数据库IO。那么有没有一种不需要直接操作数据库IO的方案呢,这就是预扣库存。先扣除了库存,保证不超卖,然后异步生成用户订单,这样响应给用户的速度就会快很多;那么怎么保证不少卖呢?用户拿到了订单,不支付怎么办?我们都知道现在订单都有有效期,比如说用户五分钟内不支付,订单就失效了,订单一旦失效,就会加入新的库存,这也是现在很多网上零售企业保证商品不少卖采用的方案。订单的生成是异步的,一般都会放到MQ、kafka这样的即时消费队列中处理,订单量比较少的情况下,生成订单非常快,用户几乎不用排队。
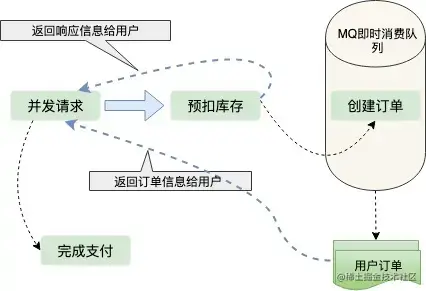
库存之【预扣库存】
预扣库存的主要流程如下:
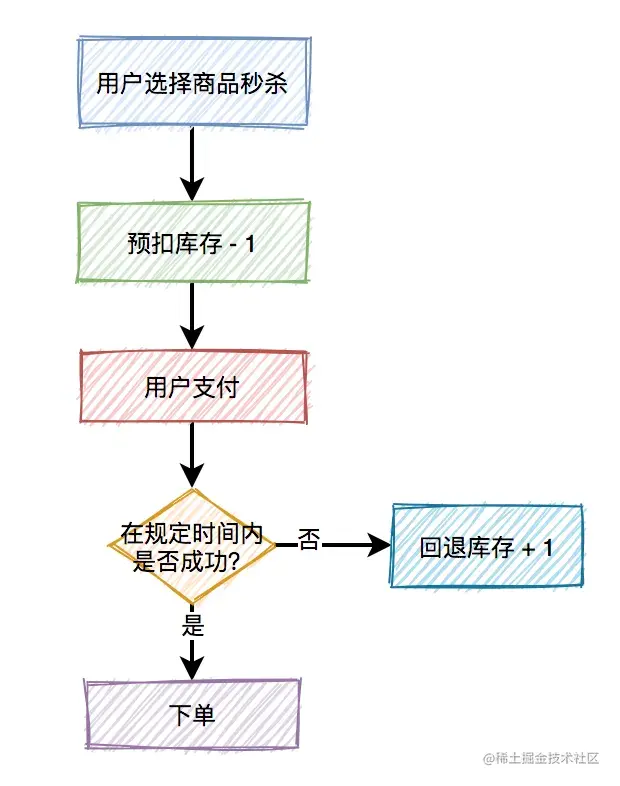
扣减库存中除了上面说到的预扣库存和回退库存之外,还需要特别注意的是库存不足和库存超卖问题。
数据库扣减库存
使用数据库扣减库存,是最简单的实现方案了,假设扣减库存的sql如下:
update product set stock=stock-1 where id=123;
复制代码这种写法对于扣减库存是没有问题的,但如何控制库存不足的情况下,不让用户操作呢?
这就需要在update之前,先查一下库存是否足够了。
伪代码如下:
int stock = mapper.getStockById(123);
if(stock > 0) {
int count = mapper.updateStock(123);
if(count > 0) {
addOrder(123);
}
}
复制代码大家有没有发现这段代码的问题?
没错,查询操作和更新操作不是原子性的,会导致在并发的场景下,出现库存超卖的情况。
有人可能会说,这样好办,加把锁,不就搞定了,比如使用synchronized关键字。
确实,可以,但是性能不够好。
还有更优雅的处理方案,即基于数据库的乐观锁,这样会少一次数据库查询,而且能够天然的保证数据操作的原子性。
只需将上面的sql稍微调整一下:
update product set stock=stock-1 where id=product and stock > 0;
复制代码在sql最后加上:stock > 0,就能保证不会出现超卖的情况。
但需要频繁访问数据库,我们都知道数据库连接是非常昂贵的资源。在高并发的场景下,可能会造成系统雪崩。而且,容易出现多个请求,同时竞争行锁的情况,造成相互等待,从而出现死锁的问题。
➍redis扣减库存
redis的incr方法是原子性的,可以用该方法扣减库存。伪代码如下:
boolean exist = redisClient.query(productId, userId);
// 1. 先判断该用户有没有秒杀过该商品,如果已经秒杀过,则直接返回-1。
if(exist) {
return -1;
}
int stock = redisClient.queryStock(productId);
// 2. 查询库存,如果库存小于等于0,则直接返回0,表示库存不足。
if(stock <= 0) {
return 0;
}
// 3. 如果库存充足,则扣减库存,然后将本次秒杀记录保存起来。然后返回1,表示成功。
redisClient.incrby(productId, -1);
redisClient.add(productId, userId);
return 1;
复制代码估计很多小伙伴,一开始都会按这样的思路写代码。但如果仔细想想会发现,这段代码有问题。
有什么问题呢?
如果在高并发下,有多个请求同时查询库存,当时都大于0。由于查询库存和更新库存非原则操作,则会出现库存为负数的情况,即库存超卖➎。
➎库存之【库存超卖】
引起超卖的原因很可能是代码逻辑进行 取库存->判断库存是否充足->业务操作->扣减库存->库存入库 类似的操作。
并发情况下,多线程同时取库存,假设2个线程,库存只有1个,两个线程取出的库存都为1,库存校验均通过,然后进行减库存、入库等操作,然后都下单成功了,造成超卖现象,1个商品卖给了2个人。
事务
我们可以使用使用redis的 watch + multi 指令,去监听秒杀商品库存,如果库存数发生改变,则后续无法进行修改库存操作。
缺点: (1)由于watch采用乐观锁机制,没有对其它线程修改操作作限制,因此事务有可能频繁失败;需要用while循环去重复尝试;
(2)增加服务器压力
结论:不可行
分布式锁
利用分布式锁,保证同一时刻只有一个线程进行 读库存->修改库存 操作。
缺点:同一个商品多用户同时下单的时候,会基于分布式锁串行化处理,导致没法同时处理同一个商品的大量下单的请求,并发处理能力较弱。
结论:不可行
redis队列
将库存缓存到redis队列,队列里面放sku_id,例如库存为5个,就放5个id。
// 库存入缓存
for (RedisSeckillSku sku : seckillSkuList) {
Integer inventory = sku.getInventory();
List<Long> skuIds = new ArrayList<>(inventory);
for (int i = 0; i < inventory; i++) {
skuIds.add(sku.getId());
}
redisTemplate.opsForList().leftPushAll("hosjoy-seckill-test:seckill-sku-inventory:" + seckillId + seckillSkuId, skuIds);
}
复制代码通过rightPop操作取出商品,预扣减库存,如果pop出来的元素为空,说明售罄 。
String skuId = redisTemplate.opsForList().rightPop("hosjoy-seckill-test:seckill-sku-inventory:" + seckillId + seckillSkuId);
//pop出来空,说明已售罄
//此处不需要加锁判断,不会产生并发问题
if (skuId == null) {
//删除排队信息
redisTemplate.opsForHash().delete("hosjoy-seckill-test:seckill-user-queue-count:" + seckillId + seckillSkuId, userId);
throw new ClientException("商品已售空");
}
复制代码这里利用了redis单线程操作特性,队列取id即扣减库存,相当于原子操作,高并发场景下不需要开事务,也不用加锁同步,性能、数据一致性均好于以上两种方案。
结论:可行
synchronized加锁
当然有人可能会说,加个synchronized不就解决问题?
调整redis库存扣减➍后代码如下:
boolean exist = redisClient.query(productId, userId);
if(exist) {
return -1;
}
synchronized(this) {
int stock = redisClient.queryStock(productId);
if(stock <=0) {
return 0;
}
redisClient.incrby(productId, -1);
redisClient.add(productId,userId);
}
return 1;
复制代码加synchronized确实能解决库存为负数问题,但是这样会导致接口性能急剧下降,每次查询都需要竞争同一把锁,显然不太合理。
结论:不可行
直接扣减库存
为了解决上面的问题,代码优化如下:
boolean exist = redisClient.query(productId,userId);
// 1. 先判断该用户有没有秒杀过该商品,如果已经秒杀过,则直接返回-1。
if(exist) {
return -1;
}
// 2. 扣减库存,判断返回值是否小于0,如果小于0,则直接返回0,表示库存不足。
if(redisClient.incrby(productId, -1)<0) {
return 0;
}
// 3. 如果扣减库存后,返回值大于或等于0,则将本次秒杀记录保存起来。然后返回1,表示成功。
redisClient.add(productId,userId);
return 1;
复制代码该方案咋一看,好像没问题。
但如果在高并发场景中,有多个请求同时扣减库存,大多数请求的incrby操作之后,结果都会小于0。
虽说,库存出现负数,不会出现超卖的问题。但由于这里是预减库存,如果负数值负的太多的话,后面万一要回退库存时,就会导致库存不准,也就是库存少卖➏。
结论:不可行
lua脚本扣减库存
我们都知道lua脚本,是能够保证原子性的,它跟redis一起配合使用,能够完美解决上面的问题。
lua脚本有段非常经典的代码:
StringBuilder lua = new StringBuilder();
lua.append("if (redis.call('exists', KEYS[1]) == 1) then");
lua.append(" local stock = tonumber(redis.call('get', KEYS[1]));");
lua.append(" if (stock == -1) then");
lua.append(" return 1;");
lua.append(" end;");
lua.append(" if (stock > 0) then");
lua.append(" redis.call('incrby', KEYS[1], -1);");
lua.append(" return stock;");
lua.append(" end;");
lua.append(" return 0;");
lua.append("end;");
lua.append("return -1;");
复制代码该代码的主要流程如下:
- 先判断商品id是否存在,如果不存在则直接返回。
- 获取该商品id的库存,判断库存如果是-1,则直接返回,表示不限制库存。
- 如果库存大于0,则扣减库存。
- 如果库存等于0,是直接返回,表示库存不足。
结论:可行
预扣库存之艺术
从上面的分析可知,显然预扣库存的方案最合理。我们进一步分析扣库存的细节,这里还有很大的优化空间,库存存在哪里?怎样保证高并发下,正确的扣库存,还能快速的响应用户请求?
在单机低并发情况下,我们实现扣库存通常是这样的:
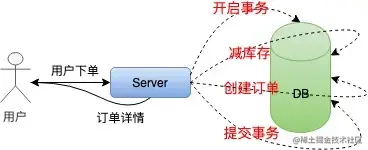
为了保证扣库存和生成订单的原子性,需要采用事务处理,然后取库存判断、减库存,最后提交事务,整个流程有很多IO,对数据库的操作又是阻塞的。这种方式根本不适合高并发的秒杀系统。
接下来我们对单机扣库存的方案做优化:本地扣库存。我们把一定的库存量分配到本地机器,直接在内存中减库存,然后按照之前的逻辑异步创建订单。改进过之后的单机系统是这样的:
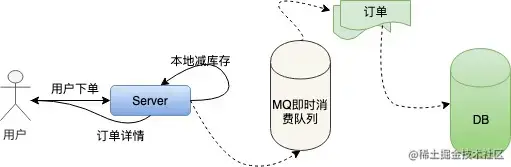
这样就避免了对数据库频繁的IO操作,只在内存中做运算,极大的提高了单机抗并发的能力。
但是百万的用户请求量单机是无论如何也抗不住的,虽然nginx处理网络请求使用epoll模型,c10k的问题在业界早已得到了解决。
但是linux系统下,一切资源皆文件,网络请求也是这样,大量的文件描述符会使操作系统瞬间失去响应。
上面我们提到了nginx的加权均衡策略,我们不妨假设将100W的用户请求量平均均衡到100台服务器上,这样单机所承受的并发量就小了很多。
然后我们每台机器本地库存100个商品,100台服务器上的总库存还是1万,这样保证了库存订单不超卖,下面是我们描述的集群架构:
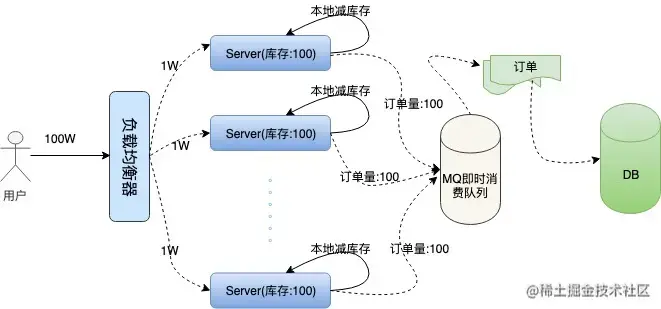
问题接踵而至,在高并发情况下,现在我们还无法保证系统的高可用,假如这100台服务器上有两三台机器因为扛不住并发的流量或者其他的原因宕机了。
那么这些服务器上的订单就卖不出去了,这就造成了订单的少卖。
要解决这个问题,我们需要对总订单量做统一的管理,这就是接下来的容错方案。
服务器不仅要在本地减库存,另外要远程统一减库存。
有了远程统一减库存的操作,我们就可以根据机器负载情况,为每台机器分配一些多余的“buffer库存”用来防止机器中有机器宕机的情况。我们结合下面架构图具体分析一下:
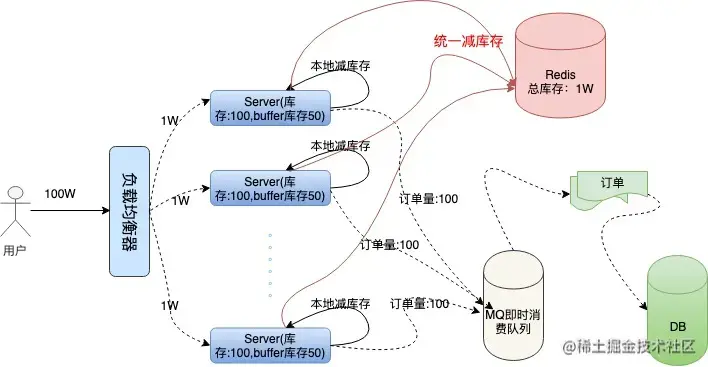
我们采用Redis存储统一库存,因为Redis的性能非常高,号称单机QPS能抗10W的并发。
在本地减库存以后,如果本地有订单,我们再去请求redis远程减库存,本地减库存和远程减库存都成功了,才返回给用户抢票成功的提示,这样也能有效的保证订单不会超卖。
当机器中有机器宕机时,因为每个机器上有预留的buffer剩余商品,所以宕机机器上的剩余商品依然能够在其他机器上得到弥补,保证了不少卖。
buffer剩余商品设置多少合适呢?
理论上buffer设置的越多,系统容忍宕机的机器数量就越多,但是buffer设置的太大也会对redis造成一定的影响。
虽然redis内存数据库抗并发能力非常高,请求依然会走一次网络IO,其实秒杀过程中对redis的请求次数是本地库存和buffer库存的总量。
因为当本地库存不足时,系统直接返回用户“秒杀失败”的信息提示,就不会再走统一扣库存的逻辑,这在一定程度上也避免了巨大的网络请求量把redis压跨,所以buffer值设置多少,需要架构师对系统的负载能力做认真的考量。
➏库存之【库存少卖】
少卖可能出现的原因有
(1)redis预扣减库存成功,但是执行真正的下单逻辑失败了,且库存没有回滚;
(2)用户订单提交成功了,但是超时没有支付,且超时后活动已结束或者超时后没有回滚库存;
(3)用户排队成功了,但是排队下单请求消息发送到MQ失败了,或者MQ消息丢了,或者消费者弄丢了数据。 (4)➏标记处少卖场景在配置lua脚本或者库存入队的方案不会出现少卖
解决方案
(1)异步下单失败后,要即时回滚redis中的sku库存;
(2)缩短支付时间,或者修改秒杀流程:先支付再确认订单;超时未支付后即时回滚redis中的sku库存;
(3)解决MQ消息丢失问题(下文会提到)。
订单
订单之【MQ异步处理】
我们都知道在真实的秒杀场景中,有三个核心流程:

而这三个核心流程中,真正并发量大的是秒杀功能,下单和支付功能实际并发量很小。所以,我们在设计秒杀系统时,有必要把下单和支付功能从秒杀的主流程中拆分出来,特别是下单功能要做成mq异步处理的。而支付功能,比如支付宝支付,是业务场景本身保证的异步。
于是,秒杀后下单的流程变成如下:
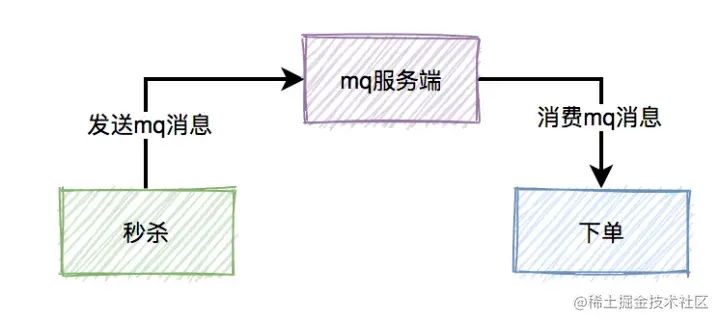
如果使用mq,需要关注以下几个问题:
订单之【消息丢失问题】
秒杀成功了,往mq发送下单消息的时候,有可能会失败。原因有很多,比如:网络问题、broker挂了、mq服务端磁盘问题等。这些情况,都可能会造成消息丢失。
那么,如何防止消息丢失呢?
答:加一张消息发送表。
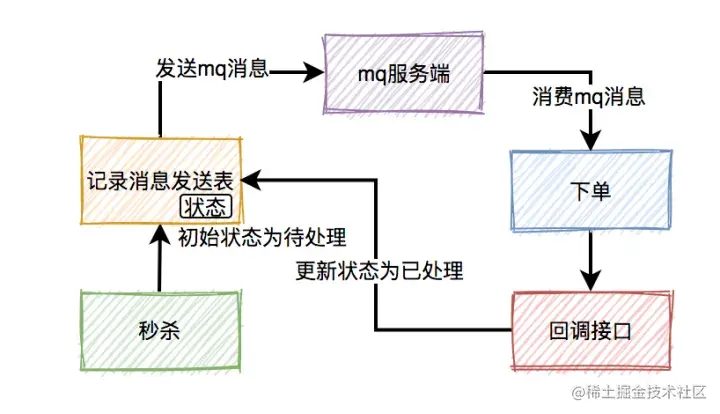
在生产者发送mq消息之前,先把该条消息写入消息发送表,初始状态是待处理,然后再发送mq消息。消费者消费消息时,处理完业务逻辑之后,再回调生产者的一个接口,修改消息状态为已处理。
如果生产者把消息写入消息发送表之后,再发送mq消息到mq服务端的过程中失败了,造成了消息丢失。
这时候,要如何处理呢?
答:使用job,增加重试机制。
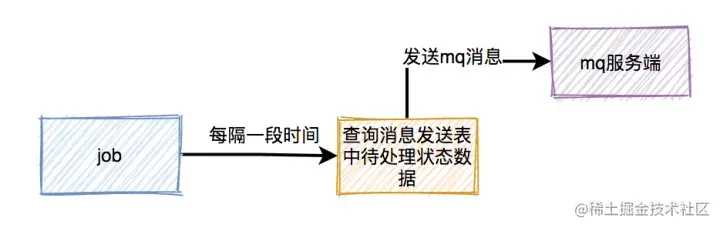
用job每隔一段时间去查询消息发送表中状态为待处理的数据,然后重新发送mq消息。
订单之【重复消费问题】
本来消费者消费消息时,在ack应答的时候,如果网络超时,本身就可能会消费重复的消息。但由于消息发送者增加了重试机制,会导致消费者重复消息的概率增大。
那么,如何解决重复消息问题呢?
答:加一张消息处理表。
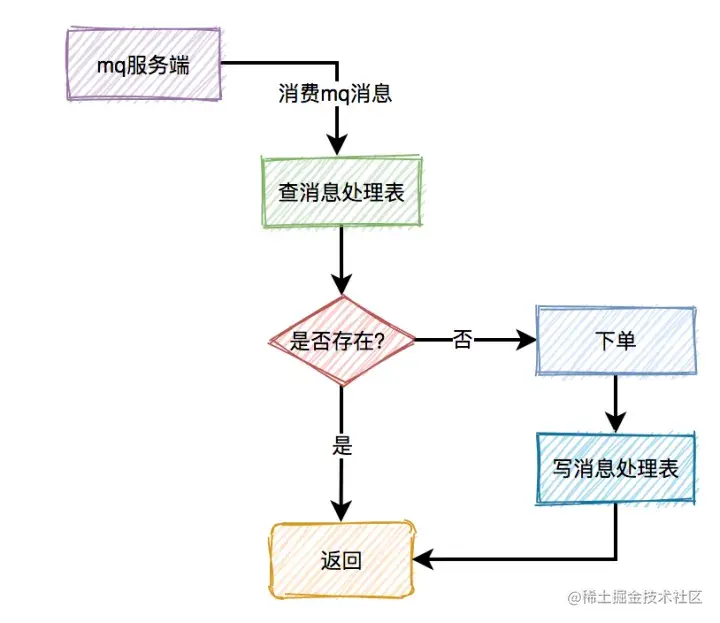
消费者读到消息之后,先判断一下消息处理表,是否存在该消息,如果存在,表示是重复消费,则直接返回。如果不存在,则进行下单操作,接着将该消息写入消息处理表中,再返回。
有个比较关键的点是:下单和写消息处理表,要放在同一个事务中,保证原子操作。
订单之【垃圾消息问题】
这套方案表面上看起来没有问题,但如果出现了消息消费失败的情况。比如:由于某些原因,消息消费者下单一直失败,一直不能回调状态变更接口,这样job会不停的重试发消息。最后,会产生大量的垃圾消息。
那么,如何解决这个问题呢?
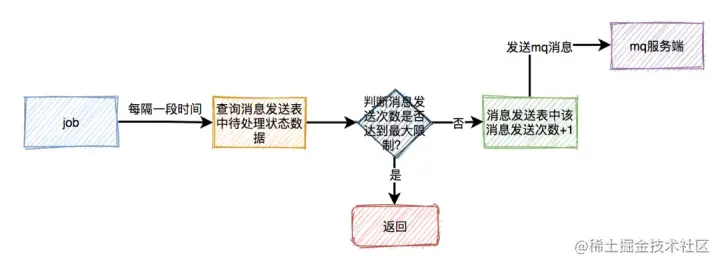
每次在job重试时,需要先判断一下消息发送表中该消息的发送次数是否达到最大限制,如果达到了,则直接返回。如果没有达到,则将次数加1,然后发送消息。
这样如果出现异常,只会产生少量的垃圾消息,不会影响到正常的业务。
订单之【超时未支付】
通常情况下,如果用户秒杀成功了,下单之后,在15分钟之内还未完成支付的话,该订单会被自动取消,回退库存,同时删除缓存中排队信息、下单状态。
那么,在15分钟内未完成支付,订单被自动取消的功能,要如何实现呢?
我们首先想到的可能是job,因为它比较简单。
但job有个问题,需要每隔一段时间处理一次,实时性不太好。
还有更好的方案?
答:使用延迟队列。
我们都知道rocketmq,自带了延迟队列的功能。
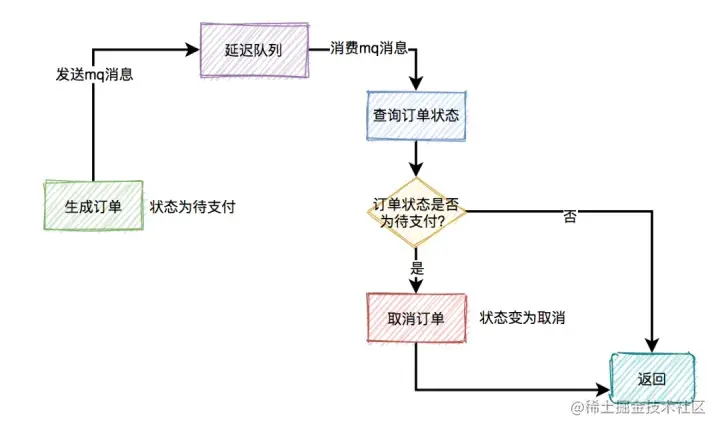
下单时消息生产者会先生成订单,此时状态为待支付,然后会向延迟队列中发一条消息。达到了延迟时间,消息消费者读取消息之后,会查询该订单的状态是否为待支付。如果是待支付状态,则会更新订单状态为取消状态。如果不是待支付状态,说明该订单已经支付过了,则直接返回。
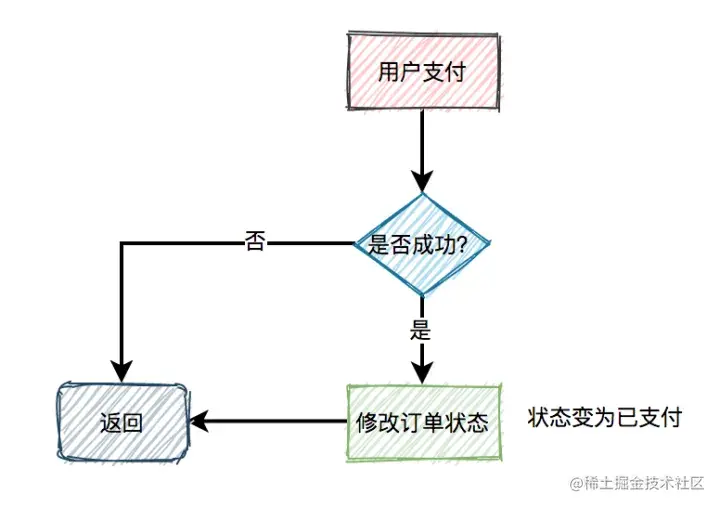
订单之【支付回调】
用户完成支付之后,会修改订单状态为已支付,同时删除缓存中排队信息、下单状态。
熔断
熔断之【雪崩效应】
那么,在微服务体系中,雪崩效应又指的是什么呢?
在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程。
如果下图所示:A 作为服务提供者,B 为 A 的服务消费者,C 和 D 是 B 的服务消费者。A 不可用引起了 B 的不可用,并将不可用像滚雪球一样放大到 C 和 D 时,雪崩效应就形成了。
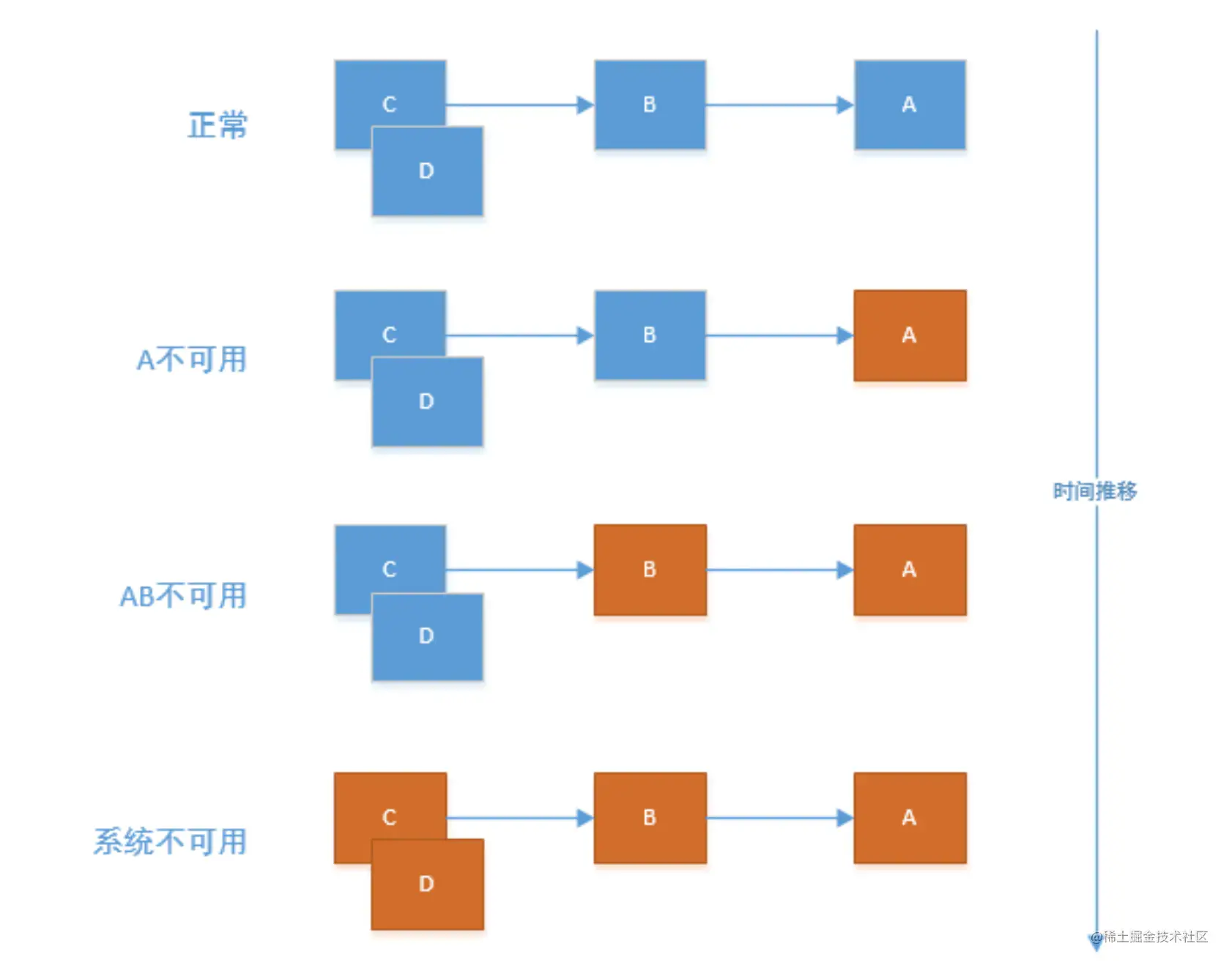
常见的原因如下:
- 流量突增 节假日访问量变大,常见于工具类APP,如美图秀秀 活动原因导致访问量变大
- 程序bug 内存泄漏 线程池中的线程使用之后未释放等
- 硬件或者网络异常 机器硬盘故障 所在的网段发生异常
- 同步等待 因为程序设计原因,整个请求都在同步进行,后面的请求只有在前面的请求完成之后,才能被执行
- 缓存击穿 常见于秒杀系统或者热门事件,短时间内大量缓存失效时大量的缓存不命中,使请求直击后端,造成服务提供者超负荷运行,引起服务不可用。
熔断之【熔断器】
隔离模式
(1)线程池隔离模式:HystrixCommand将在单独的线程上执行,并发请求受到线程池中的线程数量限制
(2)信号量隔离模式:HystrixCommand将在调用线程上执行,开销相对较小,并发请求受到信号量数量限制
熔断器模式
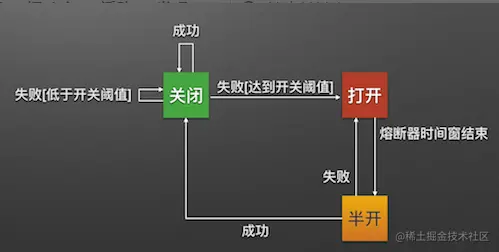
服务的健康状况 = 请求失败数 / 请求总数.
熔断器开关由关闭到打开的状态转换是通过当前服务健康状况和设定阈值比较决定的.
- 当熔断器开关关闭时, 请求被允许通过熔断器. 如果当前健康状况高于设定阈值, 开关继续保持关闭. 如果当前健康状况低于设定阈值, 开关则切换为打开状态.
- 当熔断器开关打开时, 请求被禁止通过.
- 当熔断器开关处于打开状态, 经过一段时间后, 熔断器会自动进入半开状态, 这时熔断器只允许一个请求通过. 当该请求调用成功时, 熔断器恢复到关闭状态. 若该请求失败, 熔断器继续保持打开状态, 接下来的请求被禁止通过.
熔断器的开关能保证服务调用者在调用异常服务时, 快速返回结果, 避免大量的同步等待. 并且熔断器能在一段时间后继续侦测请求执行结果, 提供恢复服务调用的可能.
命令模式
Hystrix使用命令模式(继承HystrixCommand类)来包裹具体的服务调用逻辑(run方法), 并在命令模式中添加了服务调用失败后的降级逻辑(getFallback).
在使用了Command模式构建了服务对象之后, 服务便拥有了熔断器和线程池的功能.
Hystrix的内部处理逻辑
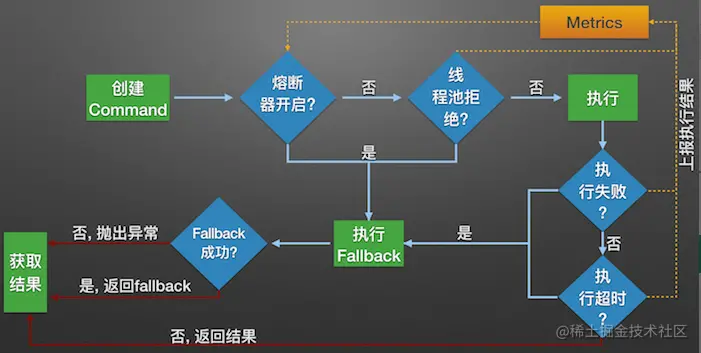
- 构建Hystrix的Command对象, 调用执行方法.
- Hystrix检查当前服务的熔断器开关是否开启, 若开启, 则执行降级服务getFallback方法.
- 若熔断器开关关闭, 则Hystrix检查当前服务的线程池是否能接收新的请求, 若超过线程池已满, 则执行降级服务getFallback方法.
- 若线程池接受请求, 则Hystrix开始执行服务调用具体逻辑run方法.
- 若服务执行失败, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务健康状况.
- 若服务执行超时, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务健康状况.
- 若服务执行成功, 返回正常结果.
- 若服务降级方法getFallback执行成功, 则返回降级结果.
- 若服务降级方法getFallback执行失败, 则抛出异常.
Metrics
Hystrix的Metrics中保存了当前服务的健康状况, 包括服务调用总次数和服务调用失败次数等. 根据Metrics的计数, 熔断器从而能计算出当前服务的调用失败率, 用来和设定的阈值比较从而决定熔断器的状态切换逻辑.
Hystrix在这些版本中开始使用RxJava的Observable.window()实现滑动窗口.
RxJava的window使用后台线程创建新桶, 避免了并发创建桶的问题.
同时RxJava的单线程无锁特性也保证了计数变更时的线程安全. 从而使代码更加简洁.
以下为我使用RxJava的window方法实现的一个简易滑动窗口Metrics, 短短几行代码便能完成统计功能,足以证明RxJava的强大:
Hystrix 工作流程图
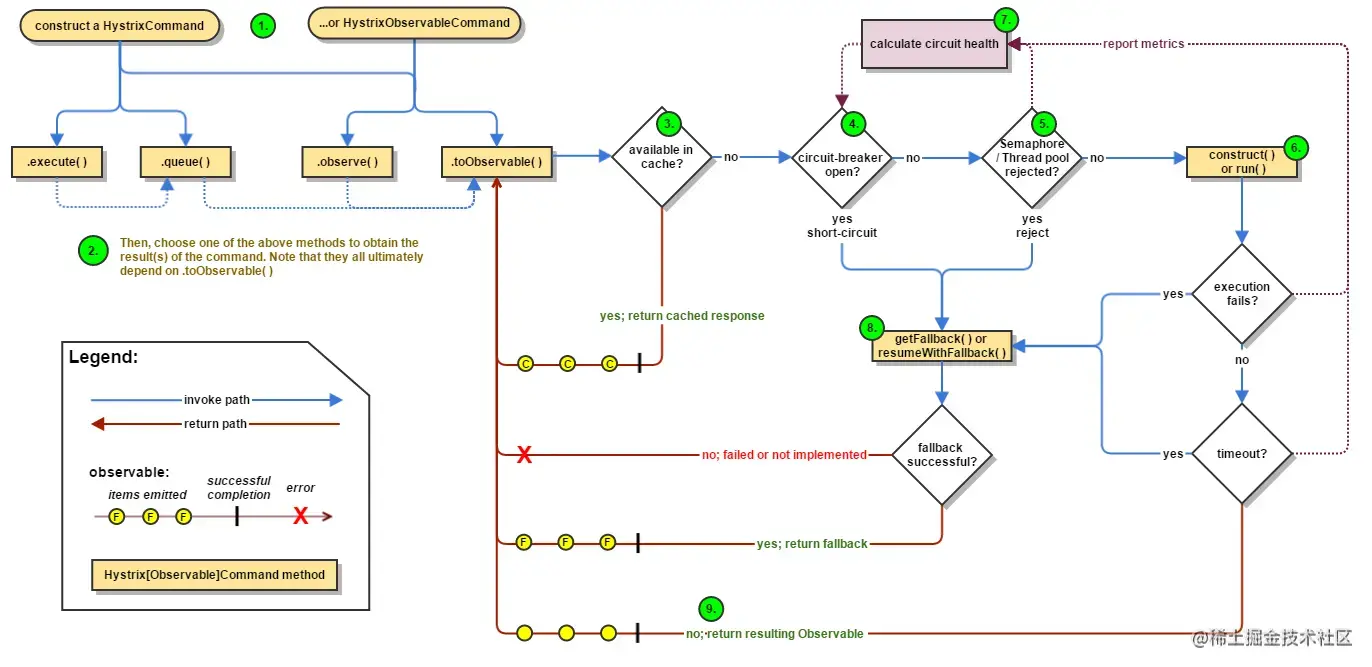
- 创建HystrixCommand 或者 HystrixObservableCommand 对象
- 执行命令execute()、queue()、observe()、toObservable()
- 如果请求结果缓存这个特性被启用,并且缓存命中,则缓存的回应会立即通过一个Observable对象的形式返回
- 检查熔断器状态,确定请求线路是否是开路,如果请求线路是开路,Hystrix将不会执行这个命令,而是直接执行getFallback
- 如果和当前需要执行的命令相关联的线程池和请求队列,Hystrix将不会执行这个命令,而是直接执行getFallback
- 执行HystrixCommand.run()或HystrixObservableCommand.construct(),如果这两个方法执行超时或者执行失败,则执行getFallback()
- Hystrix 会将请求成功,失败,被拒绝或超时信息报告给熔断器,熔断器维护一些用于统计数据用的计数器。这些计数器产生的统计数据使得熔断器在特定的时刻,能短路某个依赖服务的后续请求,直到恢复期结束,若恢复期结束根据统计数据熔断器判定线路仍然未恢复健康,熔断器会再次关闭线路。
- 依赖隔离Hystrix采用舱壁隔离模式隔离相互之间的依赖关系,并限制对其中任何一个的并发访问。
限流
通过秒杀活动,如果我们运气爆棚,可能会用非常低的价格买到不错的商品(这种概率堪比买福利彩票中大奖)。
但有些高手,并不会像我们一样老老实实,通过秒杀页面点击秒杀按钮,抢购商品。他们可能在自己的服务器上,模拟正常用户登录系统,跳过秒杀页面,直接调用秒杀接口。
如果是我们手动操作,一般情况下,一秒钟只能点击一次秒杀按钮。
但是如果是服务器,一秒钟可以请求成上千接口。
这种差距实在太明显了,如果不做任何限制,绝大部分商品可能是被机器抢到,而非正常的用户,有点不太公平。
所以,我们有必要识别这些非法请求,做一些限制。那么,我们该如何现在这些非法请求呢?
目前有两种常用的限流方式:
-
基于nginx限流
-
基于redis限流
限流之【nginx限流】
此处不赘述,直接看别人博文吧
限流之【redis限流】
在高并发中我们往往会使用限流减轻服务器的压力。常用的是Redis方式限流,Redis限流的方式有许多种,常用的方式有三种,这三种可以简单的实现限流。
基于Redis的setnx的操作
在使用Redis分布式锁的时候,我们都知道它是依靠setnx指令,在CAS的操作时同时给指定的key设置了过期时间,我们限流的主要目的就是为了在单位时间内有且仅有N个数量的请求能够访问我们的程序。因此依靠setnx可以做到这方面。例如我们需要在5秒内限定10个请求,那么我们在setnx的时候可以设置过期时间为5,当请求的setnx数量达到10个的时候就达到了限流效果。这种做法的弊端是很多的,例如当统计1到5秒的时候,但无法统计2到6秒之内,如果需要统计N秒内的M个请求,那么在Redis中需要保持N个key问题。
基于Redis的数据结构zset
限流涉及的最主要的是滑动窗口,上面提到1到5怎么变成2到6。其实就是起始值和末端值都各+1即可。用Redis的list数据结构可以轻而易举的实现该功能。我们可以将请求打造成一个zset数组,当每一次请求进来时为了value保持唯一性,可以用GUID生成,而score可以用当前时间戳来表示,这是因为score可以用来计算当前时间戳之内有多少的请求数量。同时zset数据结构也提供了range方法让我们可以很轻易的获取到2个时间戳内有多少请求。代码如下:
public Response limitFlow() {
Long currentTime = new Date().getTime();
System.out.println(currentTime);
if (redisTemplate.hasKey("limit")) {
Integer count = redisTemplate.opsForZSet().rangeByScore("limit", currentTime - intervalTime, currentTime).size();
System.out.println(count);
if (count != null && count > 5) {
return Response.ok("每分钟最多只能访问5次");
}
}
redisTemplate.opsForZSet().add("limit", UUID.randomUUID().toString(), currentTime);
return Response.ok("访问成功");
}
复制代码通过上述代码可以做到滑动窗口的效果,并且能保证每N秒内至多M个请求,缺点就是zset的数据结构会越来越大。实现方式相对也是比较简单的。
基于Redis的令牌桶算法
提到限流就不得不提到令牌桶算法了。令牌桶算法提及到输入速率和输出速率,当输出速率大于输入速率,那么就是超出流量限制了。也就是说我们每访问一次请求的时候,可以从Redis中获取一个令牌,如果拿到令牌了,那就说明没超出限制,而如果拿不到,则结果相反。依靠上述的思想,可以结合Redis的List数据结构很轻易的做到这样的代码,只是简单实现。依靠List的leftPop来获取令牌,代码如下:
public Response limitFlow2(Long id){
Object result = redisTemplate.opsForList().leftPop("limit_list");
if(result == null){
return Response.ok("当前令牌桶中无令牌");
}
return Response.ok(articleDescription2);
}
复制代码再依靠Java的定时任务,定时往List中rightPush令牌,当然令牌也需要唯一性,所以我这里还是用UUID进行了生成
// 10S的速率往令牌桶中添加UUID,只为保证唯一性
@Scheduled(fixedDelay = 10_000,initialDelay = 0)
public void setIntervalTimeTask(){
redisTemplate.opsForList().rightPush("limit_list",UUID.randomUUID().toString());
}
复制代码代码实现起始都不是很难,针对这些限流方式我们可以在AOP或者filter中加入以上代码,用来做到接口的限流,最终保护你的网站。
限流之【对同一用户限流】
为了防止某个用户,请求接口次数过于频繁,可以只针对该用户做限制。
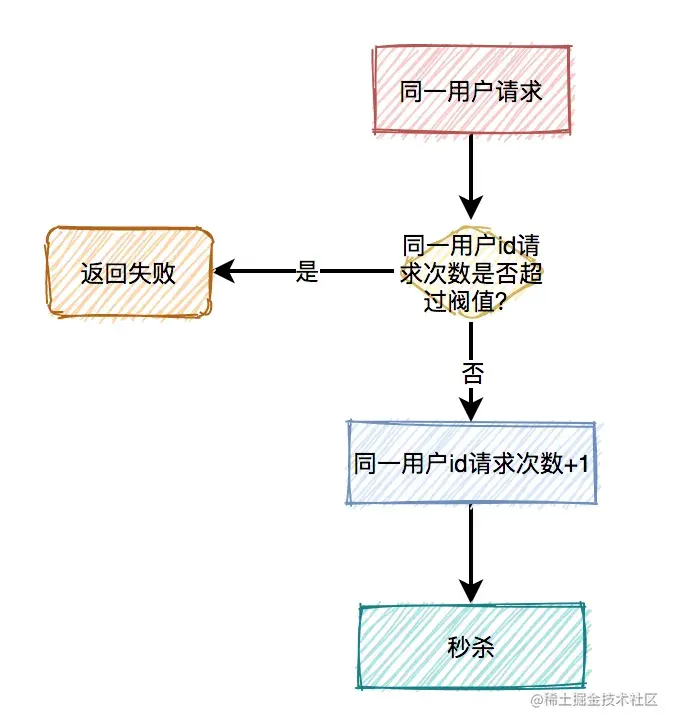
限制同一个用户id,比如每分钟只能请求5次接口。
限流之【对同一ip限流】
有时候只对某个用户限流是不够的,有些高手可以模拟多个用户请求,这种nginx就没法识别了。
这时需要加同一ip限流功能。
数据链路层:交换机设备本身便具有限制同一IP访问速率的功能(这其实属于网管应该干的事情)
网关层限流:nginx配置limit_conn_zone限制同一ip的访问速率:
limit_conn_zone $binary_remote_address zone=addr:10m;
复制代码web服务器限流:MQ、限流算法(如RateLimiter)等,代码实现。
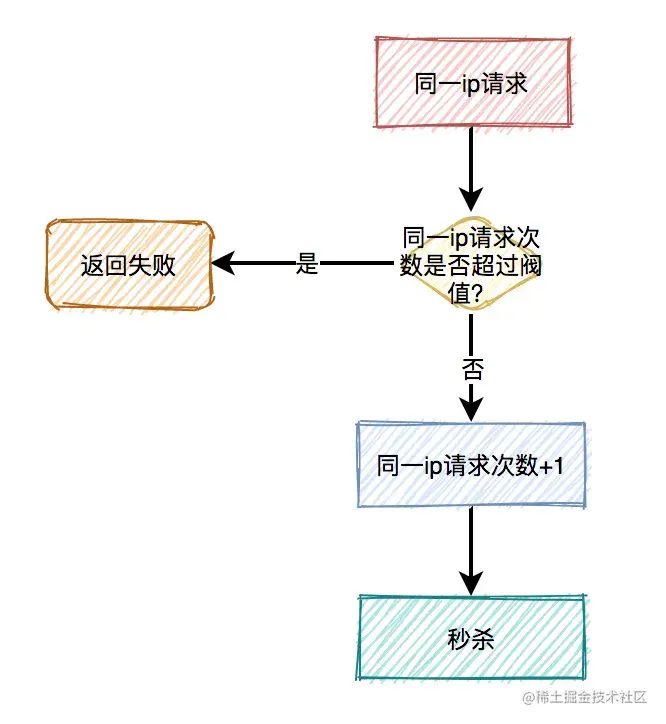
限制同一个ip,比如每分钟只能请求5次接口。
但这种限流方式可能会有误杀的情况,比如同一个公司或网吧的出口ip是相同的,如果里面有多个正常用户同时发起请求,有些用户可能会被限制住。
限流之【对接口限流】
别以为限制了用户和ip就万事大吉,有些高手甚至可以使用代理,每次都请求都换一个ip。
这时可以限制请求的接口总次数。
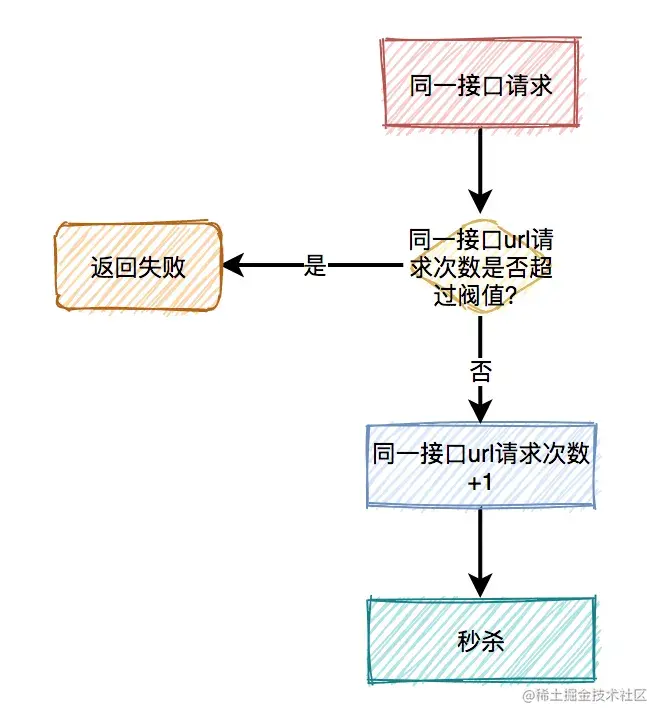
在高并发场景下,这种限制对于系统的稳定性是非常有必要的。但可能由于有些非法请求次数太多,达到了该接口的请求上限,而影响其他的正常用户访问该接口。看起来有点得不偿失。
最后
以上就是魔幻楼房最近收集整理的关于实现真正的高性能高并发的上亿级别秒杀系统!前言瞬时高并发独立部署页面优化负载均衡缓存下单库存订单熔断限流的全部内容,更多相关实现真正内容请搜索靠谱客的其他文章。


![Redisson类报错:ClusterConnectionManager [ERROR] Can't connect to master: redis://127.0.0.1:7000](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)





发表评论 取消回复