

 就这样过了几天,小码哥刷了刷简历.....
就这样过了几天,小码哥刷了刷简历.....

小码收到猎头小姐姐的面试邀约后,认真进行了准备,并在约定时间到达了面试公司....






支付系统数据一致性问题
在支付系统中数据的一致性问题是一个非常重要的问题,因为一旦发生数据不一致就意味着资金的损失,要么是用户支付了钱没有成功购买到商品;要么是平台没有收到用户的钱,却给用户错误地发送了支付成功的消息。无论哪种情况都会造成业务方对支付系统的不信任,因此我们要在整体系统流程上进行设计和考虑。
从系统流程方向上看,支付系统数据不一致的发生主要有两个点:一是支付平台与第三方支付渠道(如支付宝、微信等)之间;二是支付平台与各个业务接入方之间。在支付系统建设中,所有的措施与手段都是围绕确保“业务接入方<->支付平台<->支付渠道”这三者之间的数据一致性而展开的!

分布式事务消息解决方案
在实时流程上我们采用了基于Rocket MQ的分布式事务消息方案。通过MQ+分布式事务消息机制解耦了支付平台与第三方支付渠道之间的回调依赖及支付平台与业务接入方之间的回调依赖。示意图如下:
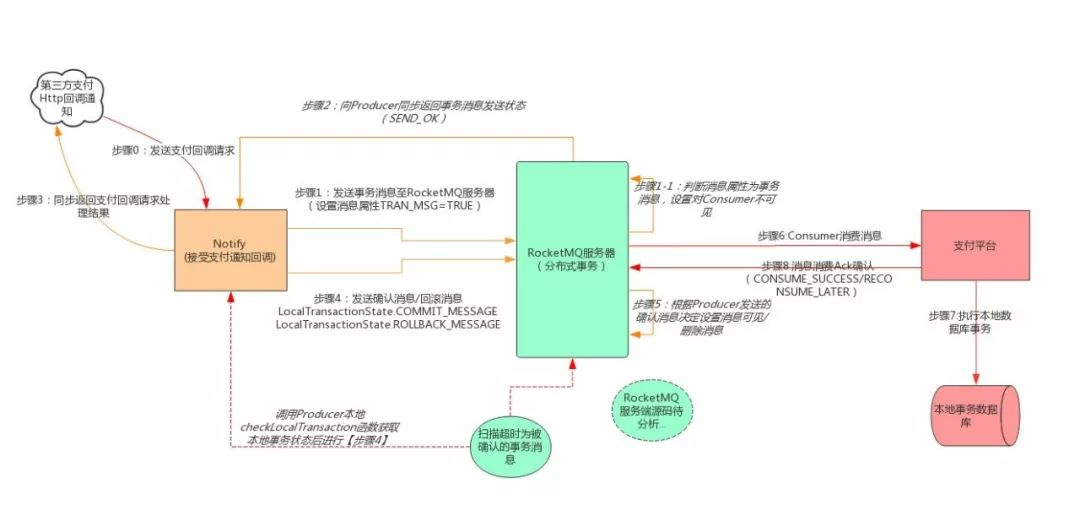
而之所以选择通过MQ+分布式事务消息来解耦,前面提到过支付系统最容易产生数据不一致的地方就是面向第三方渠道以及面向业务接入方,而面向第三方渠道的不一致的风险会更高,因为第三方支付渠道属于上游外部依赖,拥有更多的不确定性。在大多数情况下,第三方支付渠道与支付平台之间依赖于异步支付结果通知机制来保证支付状态的回调,所以支付平台需要率先同步接受第三方支付的回调,并确保在完成支付订单状态更新的事务后同步向第三方支付渠道返回处理结果。

从正常的业务流程上看并没有什么问题,但是由于将接受第三方支付回调及处理支付平台状态逻辑放在同一个事务中,在极端情况下,如支付系统出现故障导致第三方支付渠道无法正常回调、或者由于支付回调量过大而导致支付平台处理回调通知失败的话就会造成数据不一致。
而通过MQ解耦后系统将接收支付回调与处理支付回调逻辑隔离在了两个不同的流程之中,并基于分布式事务消息的机制来保证消息的投递与处理的事务一致性,实践证明这种方案可以较大地提升系统性能并且在一定程度上降低数据不一致的发生几率。基于这样的结论,我们在支付平台与业务接入方的回调方式上也采取了类似的机制。





即将讲到本文的重点,请大家抽根烟、保持耐心...

支付状态实时对账解决方案
在实时流程中我们利用分布式事务消息主要针对的问题是在正常流程下,支付平台对第三方支付结果回调处理错误、以及支付平台对业务接入方回调逻辑错误的情况下而产生的支付状态数据不一致问题。
但这并不能100%的解决支付掉单问题,因此还需要设计一套对账机制来确保剩下的漏网异常数据能够被及时补偿。从业务的角度看,对账是支付平台确保数据一致性的重要手段,而对账的方式有日终T+1对账及实时对账两种形式,日终对账主要解决的是T+1资金结算的准确性,而从技术角度看日终对账主要以离线计算为主,是一种事后策略,更多地是满足财务对资金数据的核算需求。
而实时对账则有所不同,它具有在线计算的特点,主要是解决用户流程中的支付掉单痛点,提升用户支付体验。需要说明实时对账并不能完全替代日终对账,它们二者面向的需求场景不一样,但是实时对账能够有效减小日终对账发现差错的几率!



Rocket MQ延迟消息对账
延迟消息对账的主要实现方式就是在向第三方渠道发起支付请求后,向Rocket MQ服务器指定队列发送一条延迟对账消息。例如可以设置30秒的延迟时间,30秒后Rocket MQ就会将消息真正投递到指定Topic中,处理实时对账的Consumer服务此时就会消费到延迟对账消息。
实时对账Consumer服务在处理消息时会遇到以下几种情况:
第三方回调已经完成,支付平台订单状态处于正确状态,此时逻辑不做任何处理,延迟消息被正常消费掉;
第三方回调未发生,支付平台订单状态未知,查询第三方渠道订单接口获取该笔支付的结果状态,如果为成功/失败,则更新支付平台订单状态完成回盘逻辑处理;
第三方回调未发生,支付平台订单状态未知,查询第三方渠道订单接口获取该笔支付结果状态,如果仍然是未支付,则将该延迟对账消息扔回MQ,并设置其延迟时间为2小时,2小时后再核查一次,如果仍然是未支付则表示用户无再次支付意愿,将订单状态置为失效;



比如setDelayTimeLevel(3)表示延迟10s。

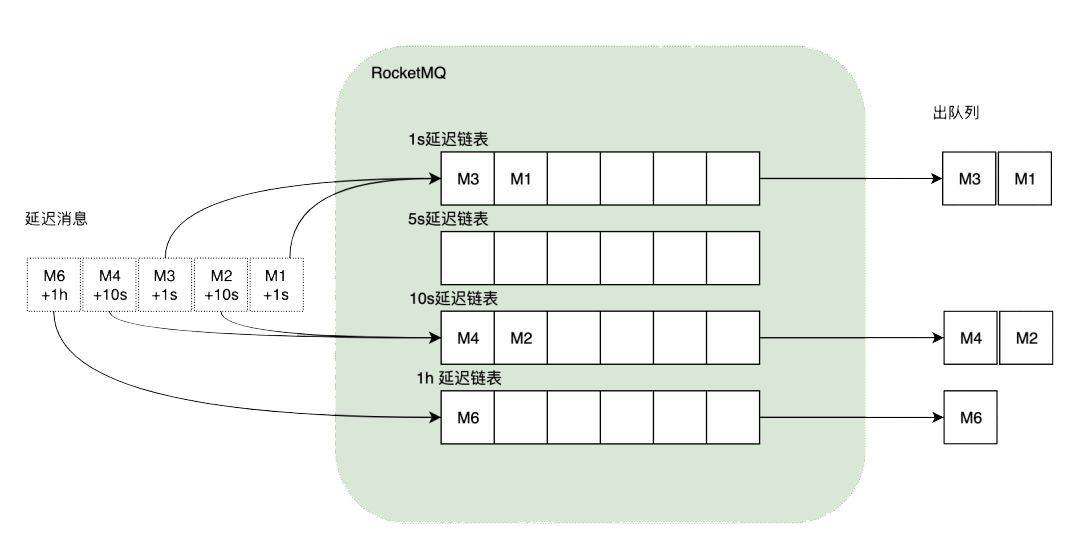
无论是定时任务还是延迟消息,都需要一定的策略和逻辑来进行触发,试想一下如果需要触发的任务量非常巨大的话,需要轮训读取到期数据的耗时将会非常长。而且由于每个任务预设的时间长度不一样,轮训的频次如果都是一样的话,也会造成系统资源的浪费。
正是基于这样的考虑,所以Rocket MQ只支持固定的延迟等级,而在存储结构上Rocket MQ会为每个延迟等级分配一个链表,Broker收到的任何一条延迟消息时都可以根据消息的延迟时间判断其延迟等级,从而将其入到对应的链表里(在Rocket MQ的实现中会将延迟消息的原始Topic、QueueId替换为特定的Topic、QueueId则会替换为延迟级别对应的id),每条链表内承载的延迟消息具有相同的延迟等级,先入的消息一定比后入的消息优先被投递,所以链表成了一个有序的FIFO队列。

在Rocket MQ的延迟消息机制中由于不同等级的延迟会分属于不同的定时队列,加上延迟等级的数目是固定的每个延迟等级都会有自己独立的定时器,所以相对来说开销就会降低很多!




哈希轮算法
哈希轮又称“哈希时间轮”(Hash TimingWheel),在面临大量定时任务并且定时时长非常离散的任务系统中,哈希时间轮拥有非常强大的性能。从结构上看,哈希时间轮是一个存储定时任务的环形队列。如下图所示:
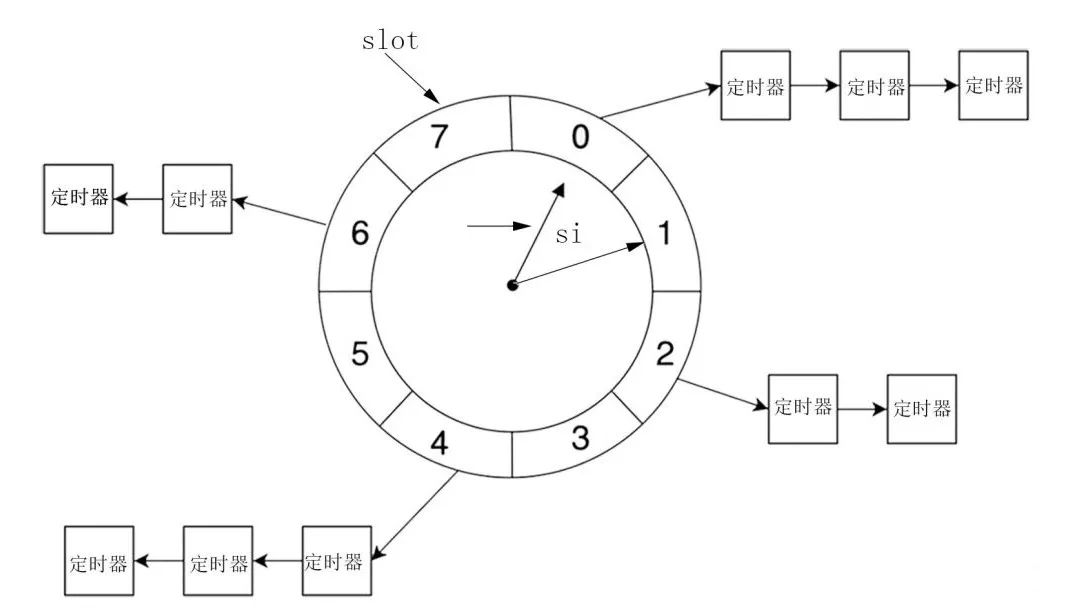
从结构上来一个哈希轮会被划分成多个不同的槽(slot),每个槽指向一条双向链表结构的定时器链表,每条链表上的定时器时长具有相同的特征。例如,假设现在哈希轮的指针指向槽cs,指针转动的时间间隔为si,那么如果此时我们要增加一个定时时间为ti的定时器,那么该定时器会被插入槽ts所在的链表中,公式如下:
ts = (cs+(ti/si))%N

可以看出,哈希轮实际上是使用了哈希表的思想来将定时器散列到不同的双向链表中。在哈希轮中,如果要提高定时精度那么指针转动的频率si值要足够小;而如果要提高执行效率,则要求时间轮槽的数量足够大,因为这样每个链表上的任务数量就少了,每次需要处理的定时器就不多!

以上介绍的只是简单的哈希时间轮,在大多数实现中(例如Kafka)为了支持更多的场景还会使用多级时间轮的结构,不同的轮子可以采取不同的粒度,例如精度高的转一圈,精度低的仅往前移动一个槽!在具体实现哈希轮算法时可以根据实际应用场景设计不同的策略!



任意时长延迟消息
延迟消息在投递后延迟一段时间才对用户可见,如果要支持任意时长的延迟消息,假如支持30天,精度为1秒,按照之前的延迟等级划分,时间轮需要被分割成30*24*60*60=2,592,000个槽,如果支持的延迟时长天数更多,那么时间轮需要被分割的槽的个数还会增加,但是时间轮是需要被加载到内存中操作的,而这显然是不能被接受的。
所以单个时间轮的方案是无法实现任意时长的延迟消息,因此需要构建支持时、分、秒的多级时间轮来解决。
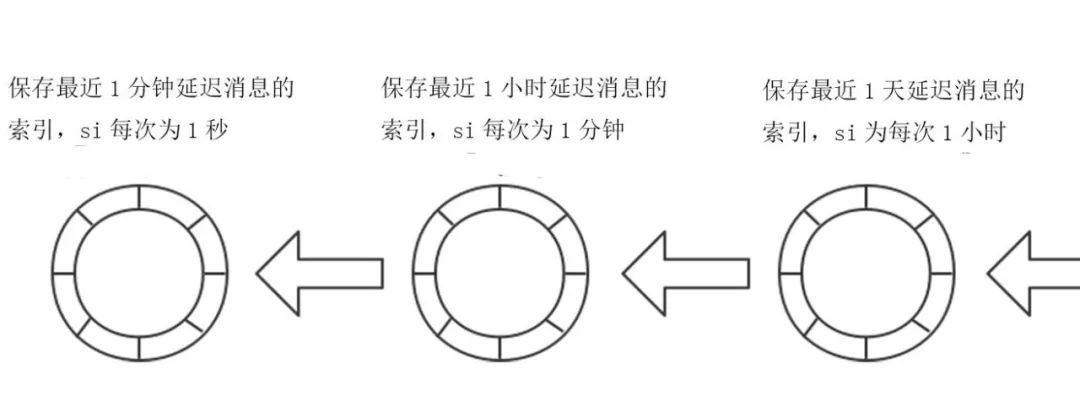
但是在多级时间轮方案中,需要加载大量的数据到内存,这会造成比较大的内存开销,所以对于未来1小时或者未来一天的数据是可以不加载到内存的,通过延迟加载的方式只加载延迟时间临近的消息!

另外一个问题是在Rocket MQ中CommitLog是有时效性的,例如一般只会保存最近7天的数据,过期的数据将被删除。而对于延迟消息,可能需要在30天之后被投递,而这显然是不能被删除的数据,因此如果要在Rocket MQ中实现任意时长的延迟消息,还需要将延迟消息的存储从CommitLog剥离出来单独进行存储!


就这样小码哥进入了谈薪阶段,最后的结果是....

参考资料:
https://www.cnblogs.com/hzmark/p/mq-delay-msg.html
https://www.jianshu.com/p/0f0fec47a0ad
http://www.cs.columbia.edu/~nahum/w6998/papers/sosp87-timing-wheels.pdf

最后
以上就是酷酷音响最近收集整理的关于漫画:架构师是吧?什么是哈希轮?的全部内容,更多相关漫画:架构师是吧内容请搜索靠谱客的其他文章。






![Redisson类报错:ClusterConnectionManager [ERROR] Can't connect to master: redis://127.0.0.1:7000](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)

发表评论 取消回复