本文仅代表大魏的个人观点,生产环境请以红帽实施团队的官方观点为准。
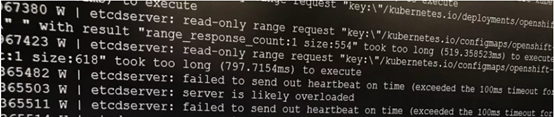
OpenShift Etcd集群每隔100ms会检测心跳。如果OpenShift的环境网络条件差,Master节点之间网络延迟超过100ms,则可能导致群集中的不稳定和频繁的leader change(详见https://access.redhat.com/solutions/4885601)。Etcd Leader的选举,默认必须在1s之内完成,否则OpenShift集群为了保护etcd数据的一致性,将暂停对集群的配置更改类操作。出现如下报错:

查看etcd的日志,可以看到如下内容(网络延迟过大,造成etcd member无法同步)
此外,存储的超时也会对Etcd造成严重影响。要排除磁盘缓慢导致的Etcd警告,可以监视指标backend_commit_duration_seconds(p99持续时间应小于25ms)和wal_fsync_duration_seconds(p99持续时间应小于10ms)以确认存储速度正常(详见https://access.redhat.com/solutions/4770281)。需要注意的是,如果存储已经出现明显的性能问题,就不必再进行测试。Etcd用于保存OpenShift所有的元数据和资源对象,官方建议将Master和Etcd部署在相同的节点,也就是Etcd数据保存在Master节点的本地磁盘,默认在/var/lib/etcd/目录下,该目录最小需要20 GB大小的存储。所以最好master本地使用SSD磁盘。OCP4.8将允许为etcd设置独立的磁盘。
针对OCP上ectd集群的同步时延较小的情况,可以根据环境考虑适当调整。相关的参数主要有两个:
name:ETCD_ELECTION_TIMEOUT
name:ETCD_HEARTBEAT_INTERVAL
第一个参数的默认值:
"name":"ETCD_ELECTION_TIMEOUT","value":"1000"
第二个参数的默认值:
"name":"ETCD_HEARTBEAT_INTERVAL","value":"100"
那么,ETCD_HEARTBEAT_INTERVAL 100ms的这个数值小不小?其实不小!Heartbeat Interval是leader给follower发送心跳的时间间隔,这个时间值应该是两个peer之间的RTT(round-trip time)值,其默认值是100ms。ElectionTimeout则是心跳超时时间,如果这个时间超时后follower还没有收到leader发来的心跳,则follower就认为leader失联,然后发起election,默认值是1000ms。
HeartbeatInterval一般取值集群中两个peer之间RTT最大值,取值范围是[0.5 xRTT, 1.5 x RTT)。如果这个值过大,则会导致很晚才会发现leader失联,影响集群稳定性。Election Timeout则依赖Heartbeat Interval和集群内所有RTT值的平均值,一般取值平均RTT的十倍,这个值的最大值是50,000ms(50s),这个值只有在全球范围内部署的时候才使用。在全美大陆,这个值应该是130ms,而美国和日本之间则应该是350-400ms,全球范围的RTT一般是5s,所以全球范围的Election Timeout取值50s作为上限为宜。
所以是,跨美国大陆的网络延迟,应该是130ms,那在数据中心内部,OCP这个数字设置为100ms,一点也不小。如果大于这个值,说明数据中心内部网络真的不好。对于数据中心,首先应该考虑的是应该如何降低网络延时,而不是调大这个参数,否则业务的性能也会受影响。但如果非要调大这个数字,比如在开发测试环境,网络就是差,短时间就是不想或者不能改善网络。有没有办法?
有。
OCP4上etcd是static pod,我们可以通过修改pod的yaml文件来修改配置。yaml文件位于三个master节点上的/etc/kubernetes/manifests/etcd-pod.yaml中,而且有四处修改的位置。并且三个master节点都需要修改(记住,是三个master节点,每个参数有4处修改的位置!!)。
我们将ETCD_ELECTION_TIMEOUT设置为5s,将ETCD_HEARTBEAT_INTERVAL设置为1s。第一个值至少是第二个值的5倍,否则会报错!(--election-timeoutshould be at least as 5 times as --heartbeat-interval)

配置修改后,etcd static pod会自动重启,让配置生效。
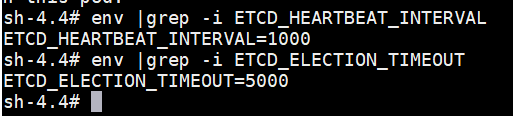
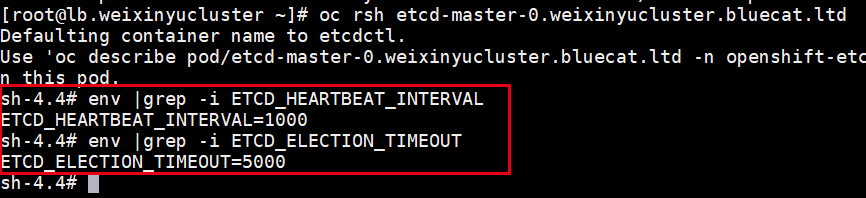
我们确认配置已经生效,首先oc rsh到etcd pod中,查看环境变量(参数以环境变量方式注入):
# oc rsh etcd-master-0.weixinyucluster.bluecat.ltd
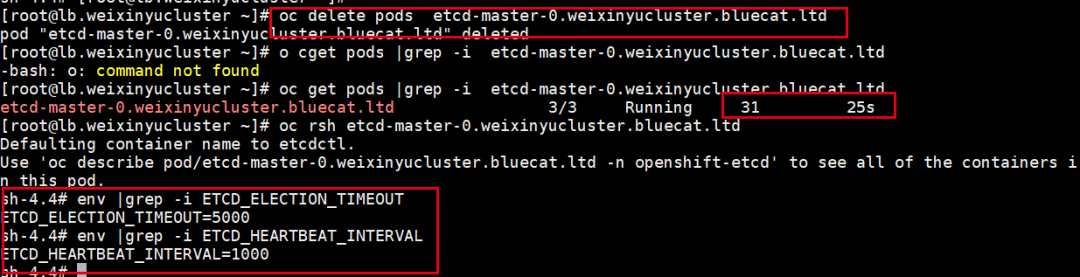
我们验证删除etcd pod看配置是否还有效。
将etcd pod删除,pod自动重建后,配置依然有效。
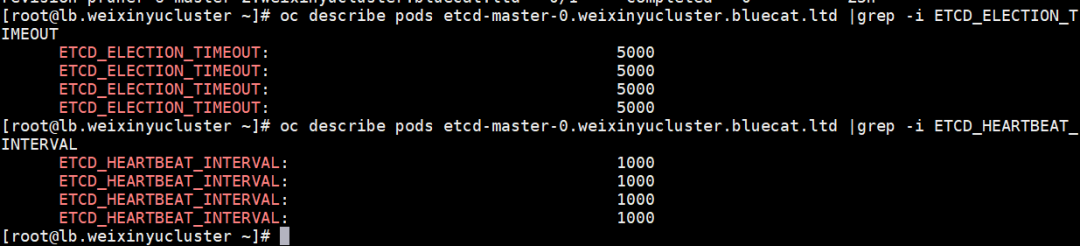
我们通过oc describe也可以验证参数:
接下来,我们验证重启master节点,配置是否有效。重启master0.
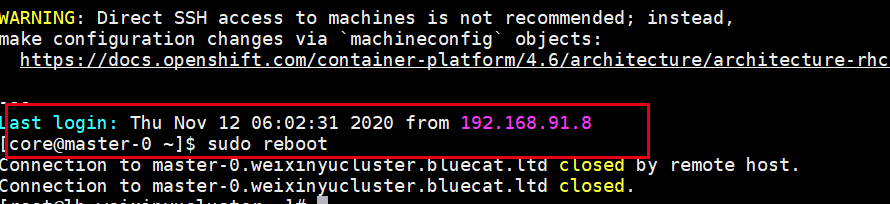
master0重启完毕:
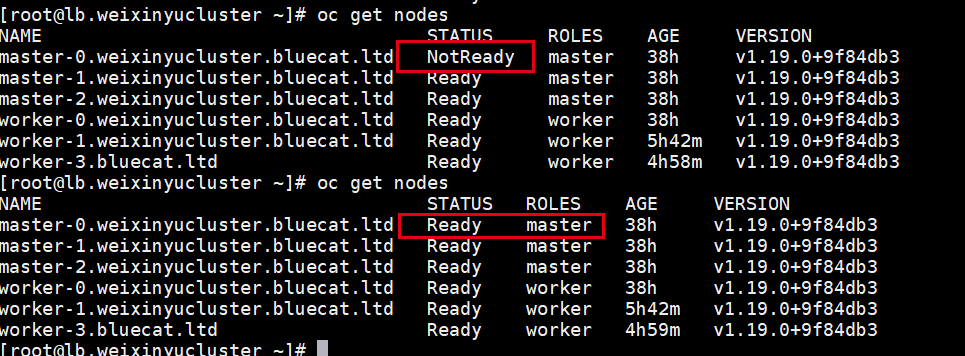 节点重启后,etcd会有初始化的操作:
节点重启后,etcd会有初始化的操作:

很快,初始化成功,etcd pod的三个容器都启动了:
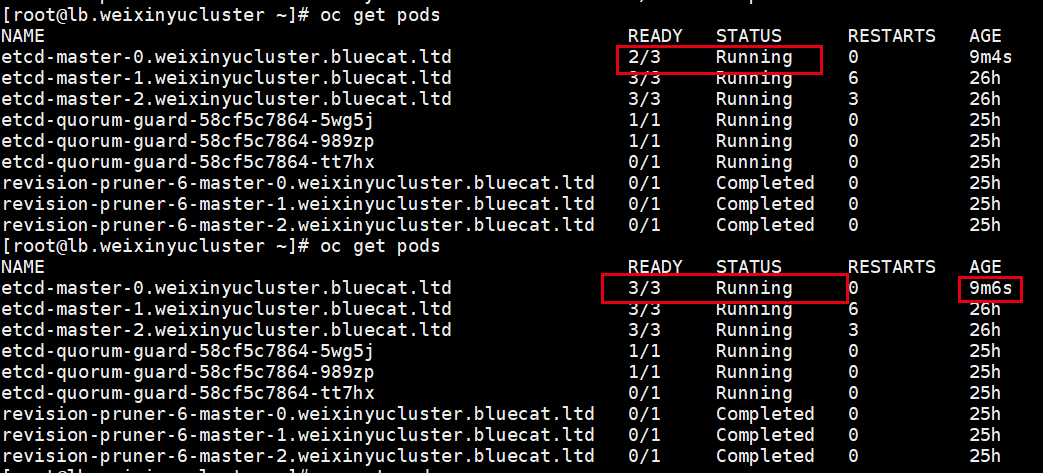
查看我修改的参数,依然有效:
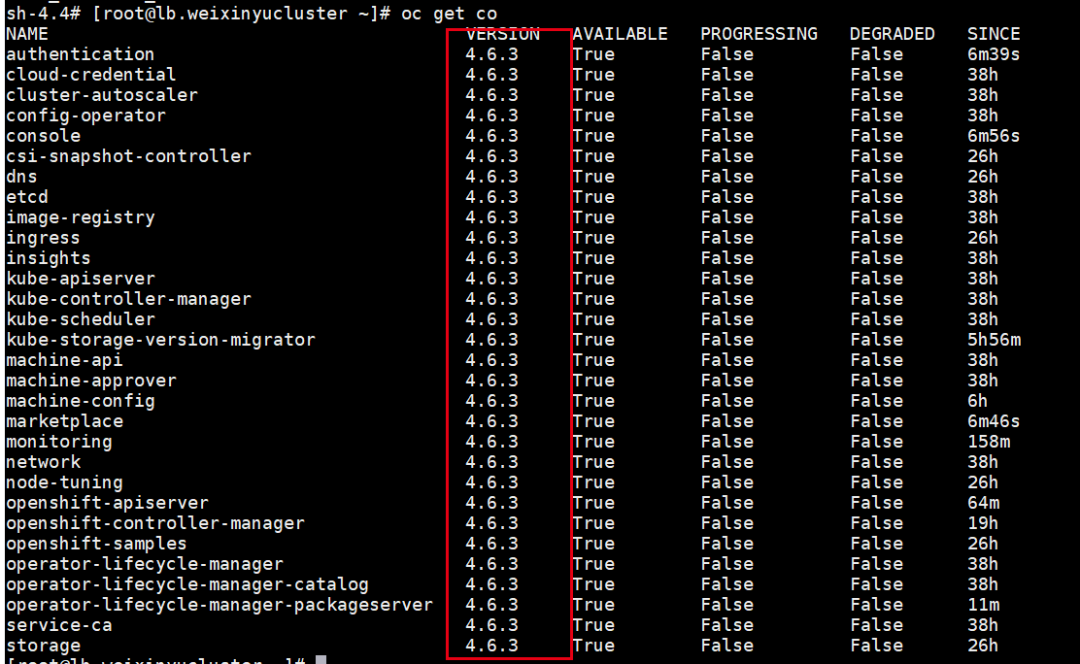
最后,我们验证升级OCP集群,这个参数是否还有效:
升级前:
升级:
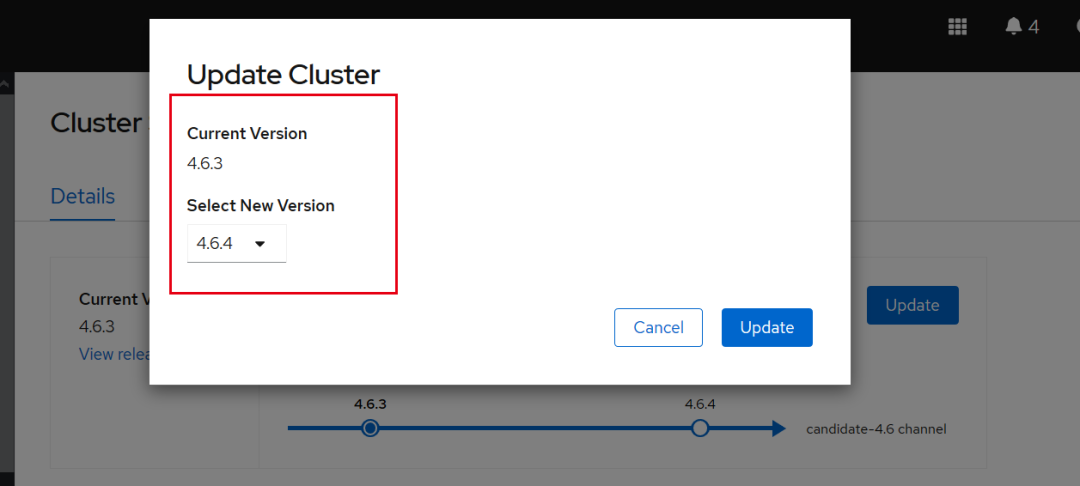
升级后,我们再查看设置的参数,发现已经被重置。
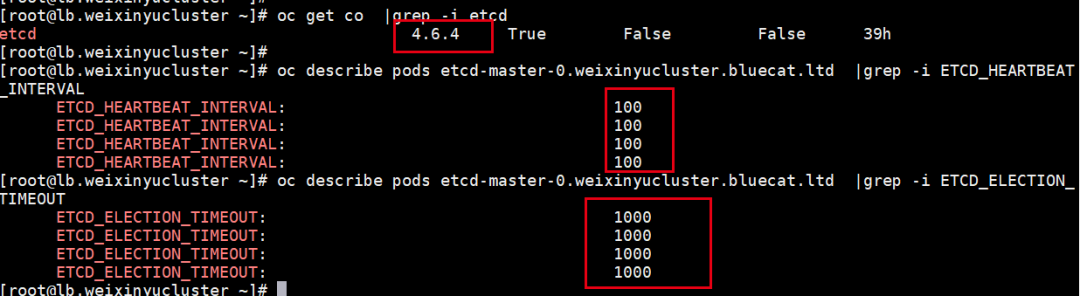
结论:两个参数的设置,对于OCP重启、etcd pod删除仍然有效。但对于升级,配置会失效。如果需要对应的数值,需要重新设置。但生产上,还是先把网络优化好,再安装OCP!
最后
以上就是清爽吐司最近收集整理的关于心跳超时时间设置_OpenShift 4中etcd同步时间的调整的全部内容,更多相关心跳超时时间设置_OpenShift内容请搜索靠谱客的其他文章。
![[转] 解决socket端口被占用的问题](https://www.shuijiaxian.com/files_image/reation/bcimg3.png)







发表评论 取消回复