读《Hands-On Transfer Learning with Python》初体验
最近由于工作原因及个人兴趣,对迁移学习兴趣盎然,很想深入了解该领域知识,偶得该领域最新力作,现分享阅读的一些心得和要点。
本书秉承一贯的传道授业顺序,从机器学习到深度学习再到迁移学习,建议对机器学习和深度学习有一定基础的同仁忽略前3章节。这里简要概括一下前3章的重点。
要了解迁移学习,首先要明白迁移学习在整个AI领域的技术位置。所以我们先了解机器学习的基础知识。
机器学习和深度学习基础
ML是人工智能的一个受欢迎的子领域,涵盖了非常广泛的范围。这种流行的原因之一是其局面下的复杂算法,技术和方法的综合工具箱。多年来,该工具箱得到了开发和改进,并且正在不断研究新工具箱。要明智地理解和使用ML工具箱,请考虑以下几种方法对其进行分类。基于人工监督量的分类:
l 监督学习:这类学习涉及高度的人工监管。监督学习下的算法利用训练数据和相关输出来学习两者之间的映射并将其应用于看不见的数据。分类和回归是监督学习算法的两种主要类型。
l 无监督学习:这类算法试图学习输入数据中固有的潜在结构,模式和关系,没有任何相关的输出/标签(人工监督)。聚类,降维,关联规则挖掘等几种主要类型的无监督学习算法。
l 半监督学习:这类算法是混合的有监督和无监督的学习。在这种情况下,算法使用少量标记的训练数据和更多未标记的数据。因此,创造性地使用有监督和无监督解决给定任务的方法。
l 强化学习:这类算法与有监督和无监督的学习方法略有不同。这里的中央实体是Agent,在与环境互动的同时训练一段时间以最大化一些奖励/酬劳。代理根据与环境交互的奖励/惩罚,迭代地学习和改变策略/策略。
基于数据可用性的分类:
l 批量学习:这也称为离线学习。这类当所需的训练数据可用时使用学习,并且模型可以在部署之前进行训练和微然后到生产/现实世界。
l 在线学习:顾名思义,在这种情况下,学习不是数据可用后停止。相反,在这种情况下,数据以小批量馈送到系统中,并且训练过程继续进行新批量的数据。
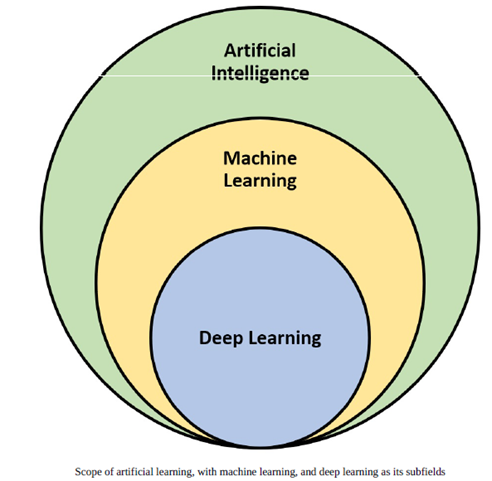
而迁移学习是深度学习的一个子领域。
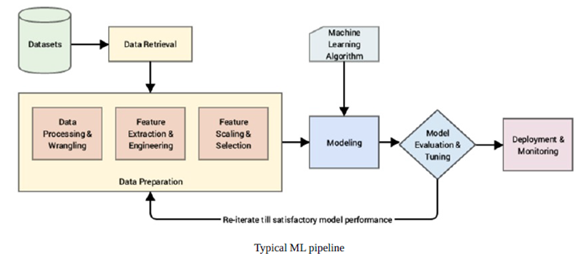
接下来让我们对整个ML pipeline有了一个感性的认识,其中深有体会的是特征工程,我们实际工作中特征工程的好坏很大程度上影响了最终项目的成败。虽然现如今AutoML、AutoDL的技术层出不穷,但真正做到不需要人工介入的特征工程,还有待时间的检验。这里有兴趣的伙伴可以阅读一下Alice Zheng 和 Amanda Casari 2018年所写的《面向机器学习的特征工程》,比较系统的讲解了特征工程方面的基础知识。
在第2-3章节,介绍了常见的深度学习的框架以及各种环境的搭建安装等等,并介绍了神经网络的一些基础知识,对于上过CS231n的同学可以忽略。秉承迁移学习需要的基础知识,简要介绍了深度学习的网络框架,如CNN、RNN、GAN、Attention模型等等,一方面可以帮我们快速回顾和巩固这些知识,另一方面为后面的主要内容打好基础。
迁移学习基础
人类具有跨任务传递知识的固有能力。 我们在学习一项任务的同时获取知识,我们在同一时期利用相同的方法解决相关任务。任务越相关,我们就越容易转移或交叉利用知识。 迄今为止机器学习和深度学习所讨论的算法传统上都是为了孤立的工作而设计的。这些算法被训练用以解决特定任务。 模型必须在特征空间分布发生变化后从头开始重建。
迁移学习是克服孤立学习范式并利用为一项任务获得的知识来解决相关问题的一种概念。
传统意义上,学习算法旨在孤立的解决任务或问题。 根据用例和手头数据的要求,应用算法来训练给定特定任务的模型。传统机器学习(ML)根据具体情况单独训练每个模型域,数据和任务如下图所示:
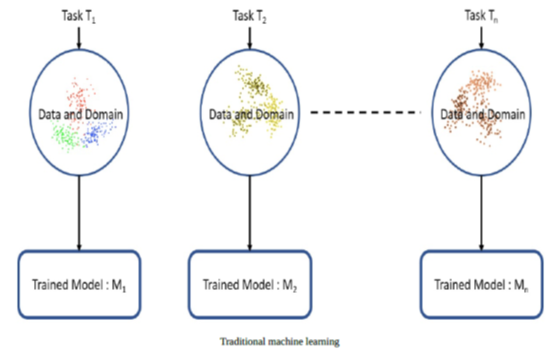
迁移学习使学习过程更进一步,更加符合人类如何跨任务利用知识的习惯。 因此,迁移学习是一种将模型或知识重用于另一相关任务的方法。迁移学习有时也被认为是现有ML算法的扩展。 在迁移学习和理解如何在任务之间转移知识的背景下,正在进行广泛的研究和工作。
那么迁移学习的策略是怎样的呢?
What to transfer: 那一部分知识可以在多个领域或任务之间迁移,即多个领域或任务知识的共同部分,通过从源领域学习这部分共同的知识,提升目标领域任务的效果。
关注迁移什么知识时,需要注意negative transfer问题:当源领域和目标领域之间没有关系,却要在之间强制迁移知识是不可能成功的。极端情况下,反倒会影响目标领域任务学习的效果,这种情况称为负迁移(negative transfer),需要尽力避免。
When to transfer: 应该致力于利用迁移学习来改善目标任务性能/结果,而不是降低它们。 同时需要关注何时应用迁移学习以及何时不需要。
How to transfer: 这涉及到现有的不同的算法技术细节。
分类
根据传统的机器学习算法进行分类:
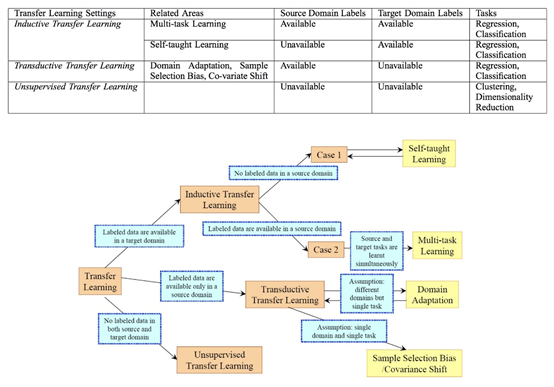
Inductive transfer: 需要先用一些样本(training set)建立一个模型,再基于建立好的模型去去预测新的样本(testing set)的类型。以分类为例,推导学习就是一个经典的贝叶斯决策,通过贝叶斯共识:P(Y|X)=P(X|Y)*P(Y)/ P(X),建立后验概率分布P(Y|X),进而预测测试样本类别。缺点就是必须先建立一个模型,很多时候建立效果好的模型并不容易,特别是当带标记的训练样本少、无标记的测试样本非常多时。
Unsupervised transfer: 和推导学习类似,重点关注于目标域中的无监督任务。 源域和目标域类似,但任务不同。 在这种长江下,源域和目标域标都没有可用的记数据。
Transductive transfer:不需要建立后验概率模型,直接从无标记的测试样本X出发,构建P(X)的分布,对测试样本分类。与推导学习相比,Transductive transfer学习也有它的缺点:因为是直接基于P(X)处理,Transductive transfer学习的测试样本必须预先已知。
根据迁移的内容,迁移学习可以分为四类:
基于实例的迁移学习(instance-based transfer learning):源领域(source domain)中的数据(data)的某一部分可以通过reweighting的方法重用,用于target domain的学习。
基于特征表示的迁移学习(feature-representation transfer learning):通过source domain学习一个好的(good)的特征表示,把知识通过特征的形式进行编码,并从suorce domain传递到target domain,提升target domain任务效果。
基于参数的迁移学习(parameter-transfer learning):target domain和source domian的任务之间共享相同的模型参数(model parameters)或者是服从相同的先验分布(prior distribution)。
基于关系知识迁移学习(relational-knowledge transfer learning):相关领域之间的知识迁移,假设source domain和target domain中,数据(data)之间联系关系是相同的。
前三类迁移学习方式都要求数据(data)独立同分布假设。同时,四类迁移学习方式都要求选择的source domain与target domain相关,表1给出了迁移内容的迁移学习分类:
迁移学习的类型
Domain adaptation
Domain adaption is usually referred to in scenarios where the marginal probabilities between the source and target domains are different, such as P(Xs) ≠ P (Xt). There is an inherent shift or drift in the data distribution of the source and target domains that requires tweaks to transfer the learning. For instance, a corpus of movie reviews labeled as positive or negative would be different from a corpus of product-review sentiments. A classifier trained on movie-review sentiment would see a different distribution if utilized to classify product reviews. Thus, domain adaptation techniques are utilized in transfer learning in these scenarios.
Domain confusion
特别是,我们讨论了如何表征特征传输可以是非常有用的。值得重申的是不同层的深度学习网络捕获不同的特征集。我们可以利用这一点来学习域不变特征并改善他们的跨域迁移能力。并不是让该模型学习任何表征,我们而是微调这两个域的表征,以尽可能地相似。
这可以通过应用某些预处理步骤直接实现表征自己。(https://arxiv.org/abs/1511.05547).。神经网络的域名对抗性训练(https://arxiv.org/abs/1505.07818)。
The basic idea behind this technique is to add another objective to the source model to encourage similarity by confusing the domain itself, hence domain confusion。
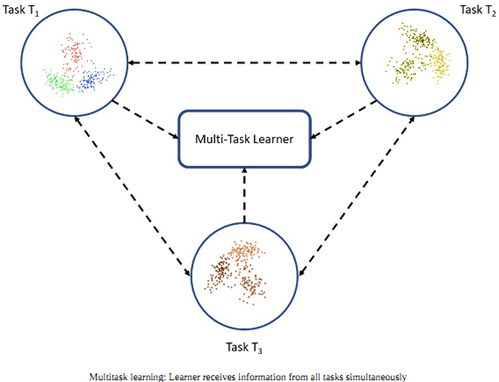
Multitask learning
Several tasks are learned simultaneously without distinction between the source and targets.
In this case, the learner receives information about multiple tasks at once, as compared to transfer learning, where the learner initially has no idea about the target task.
One-shot learning
深度学习系统本质上是数据饥饿的,因此它们需要很多学习样本来学习权重。这是限制深度神经网络的一个方面,尽管人类学习并非如此。例如,一旦孩子看到苹果看起来像什么,他们就可以很容易识别不同种类的苹果(有一个或几个训练样例); ML和深度学习算法不是这种情况。One-shot学习是一个迁移学习的变体,我们试图基于仅有的一个或几个训练样例推断出所需的输出。这在现实世界中基本上是有用的,现实中不太可能为每个可能的类别标记数据的情况(如果是分类任务)以及经常在新场景中添加新的类别。
Li FeiFei和他的联合作者https://ieeexplore.ieee.org/document/1597116写的一篇具有里程碑意义的论文,据称是创造了one-shot学习和该子领域的研究。这个论文提出了贝叶斯表示学习框架的变体在对象分类领域的新方法。此方法已得到了改进,并应用到了深度学习系统中。
Zero-shot learning
Zero-shot学习是迁移学习的另一种极端变体,它依赖没有标记的样本来学习任务。 这听起来令人难以置信,特别是大多数监督学习算法需要使用样本的情况。 Zero-shot学习方法在训练阶段,利用额外的理解看不见的数据的信息进行一些巧妙的调整。 在关于深度学习的书中,Goodfellow和他的合著者将Zero-shot学习作为这样的一个场景,有三个变量需要学习,比如传统的输入变量x,传统的输出变量y和附加的随机变量来描述任务T。因此模型训练就是用来学习条件P(y | x,T)的概率分布。 Zero-shot学习可以在机器翻译等场景派上用场,因为我们甚至可能没有目标语言的标签。
第5章节通过猫狗分类的案例讲解如何利用迁移学习来完成这个简单CNN分类模型案例,麻雀虽小,五脏俱全。
后面的章节分别对图像、文本、语音、风格迁移等垂直领域和应用结合具体程序案例展开了深入的探讨,让我不仅从理论上学习,也通过程序实践深刻体会迁移学习的应用方法。
小结
通过阅读本书,使我们对迁移学习有了一个基础感性的认识,对一些垂直领域的应用有了初步的应用实践基础,但真正的工程项目实践中还会碰到诸多问题和挑战:例如负迁移场景如何侦测、如何避免,迁移学习的成效如何来度量,这些问题不仅需要扎实的理论知识去探索,也需要更多的实践去验证。
最后
以上就是陶醉狗最近收集整理的关于读《Hands-On Transfer Learning with Python》初体验读《Hands-On Transfer Learning with Python》初体验的全部内容,更多相关读《Hands-On内容请搜索靠谱客的其他文章。








发表评论 取消回复