模型压缩之蒸馏算法小结
文章目录
- 模型压缩之蒸馏算法小结
- 输出配准
- Distilling the Knowledge in a Neural Network(NIPS 2014)
- Deep Mutual Learning(CVPR 2018)
- Born Again Neural Networks(ICML 2018)
- 直接配准
- 拟合注意力图
- Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer(ICLR 2017)
- Learning Lightweight Lane Detection CNNs by Self Attention Distillation(ICCV 2019)
- 拟合特征
- FitNets : Hints for Thin Deep Nets(ICLR2015)
- 关系配准
- 拟合特征两两之间的关系
- A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning(CVPR 2017)
- Graph-based Knowledge Distillation by Multi-head Attention Network(BMVC 2019)
- 拟合输出中蕴含的关系
- Similarity-Preserving Knowledge Distillation(ICCV 2019)
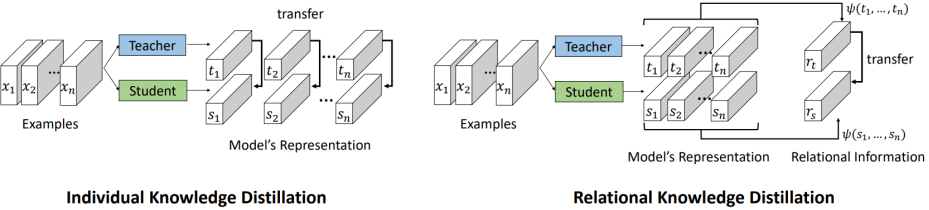
- Relational Knowledge Distillation(CVPR 2019)
- Data Distillation: Towards Omni-Supervised Learning(CVPR2018)
- Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results(NIPS 2017)
- 拟合特征自身内部的关系
- Knowledge Adaptation for Efficient Semantic Segmentation(CVPR 2019)
- Structured Knowledge Distillation for Semantic Segmentation(CVPR 2019)
原始文档:https://www.yuque.com/lart/gw5mta/scisva
Google Slide: https://docs.google.com/presentation/d/e/2PACX-1vSsa5X_zfuJUPgxUL7vu8MHbkj3JnUzIlKbf-eXkYivhwiFZRVx_NqhSxBbYDu-1c2D7ucBX_Rlf9kD/pub?start=false&loop=false&delayms=3000
2019年09月07日制作

脑图的原始文档:http://naotu.baidu.com/file/f60fea22a9ed0ea7236ca9a70ff1b667?token=dab31b70fffa034a(kdxj)
输出配准
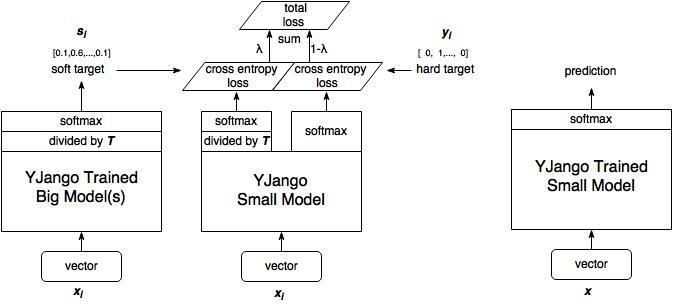
Distilling the Knowledge in a Neural Network(NIPS 2014)
- 使用教师模型的soft-target
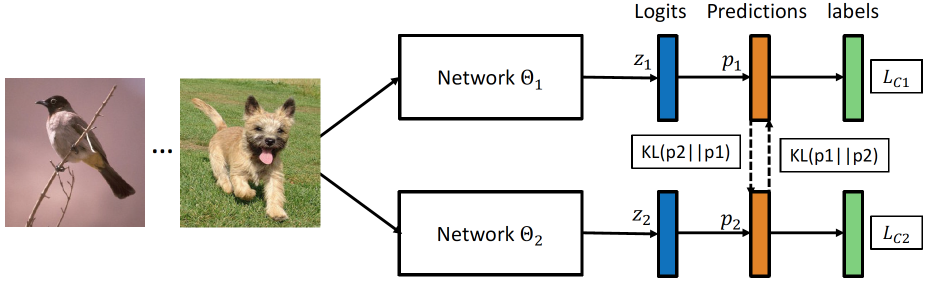
Deep Mutual Learning(CVPR 2018)
- 交替式训练多个学生网络互相促进
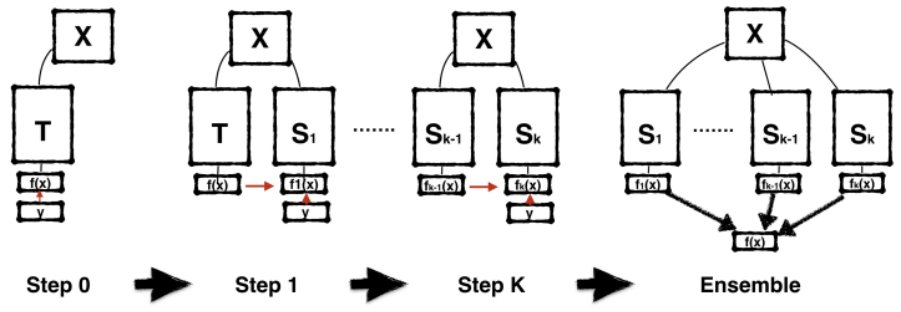
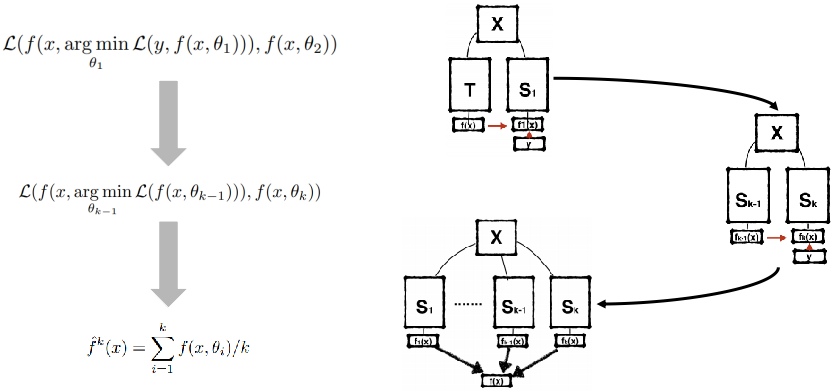
Born Again Neural Networks(ICML 2018)
- 从教师训练学生1,以此由学生i训练学生i+1,最后集成所有的学生模型
直接配准
拟合注意力图
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer(ICLR 2017)
- 配准各阶段特征通经过道融合后得到的单通道注意力图
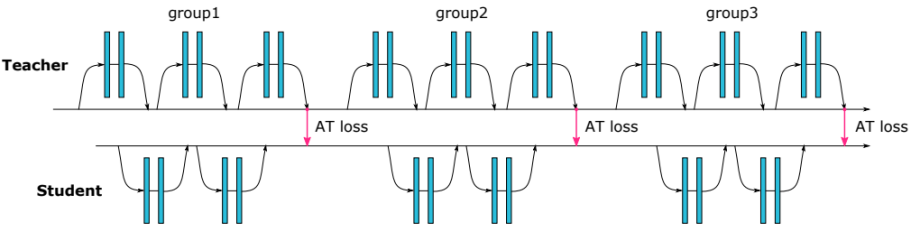

Learning Lightweight Lane Detection CNNs by Self Attention Distillation(ICCV 2019)
- 使网络各阶段的特征通过通道融合计算注意力图,配准早期的输出注意力图
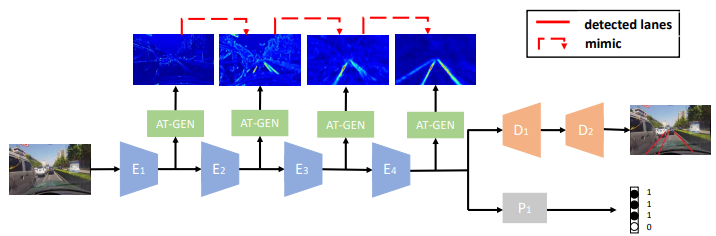

拟合特征
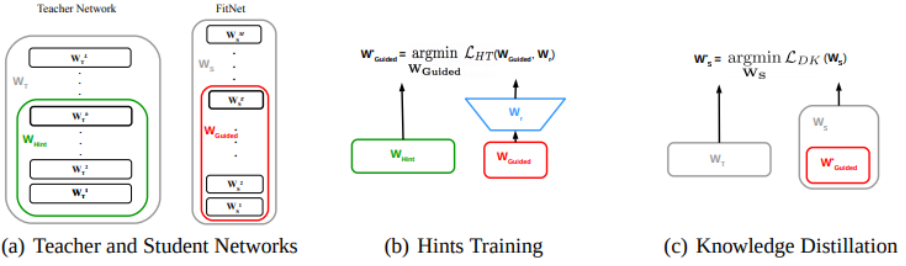
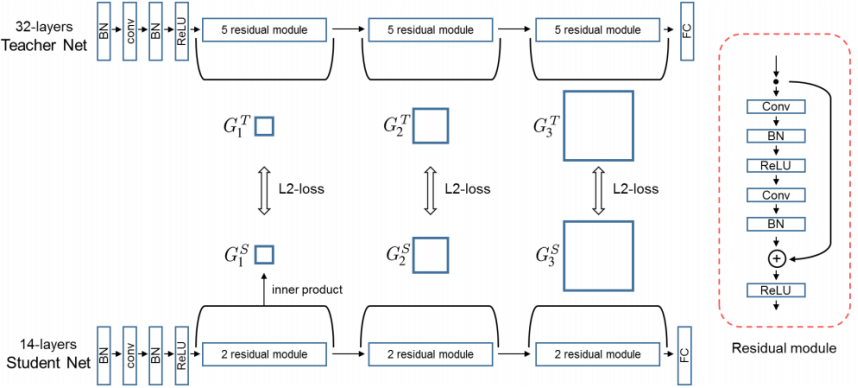
FitNets : Hints for Thin Deep Nets(ICLR2015)
- 第一阶段使用一个回归模块来配准部分学生网络和部分教师网络的输出特征,第二阶段使用soft targets


关系配准
拟合特征两两之间的关系
A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning(CVPR 2017)
- 计算相邻阶段特征个通道之间的关系进行配准
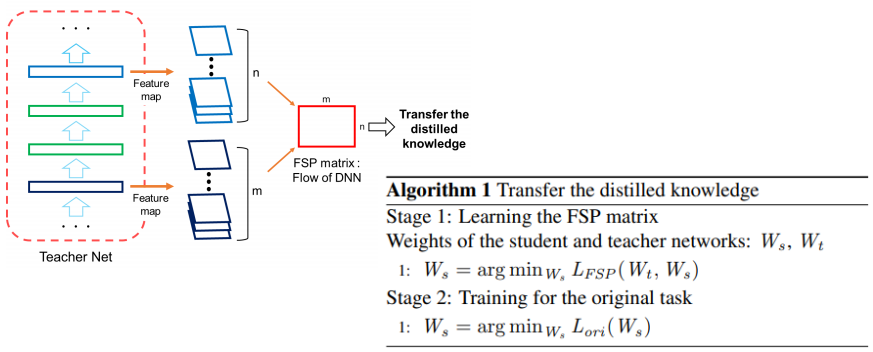
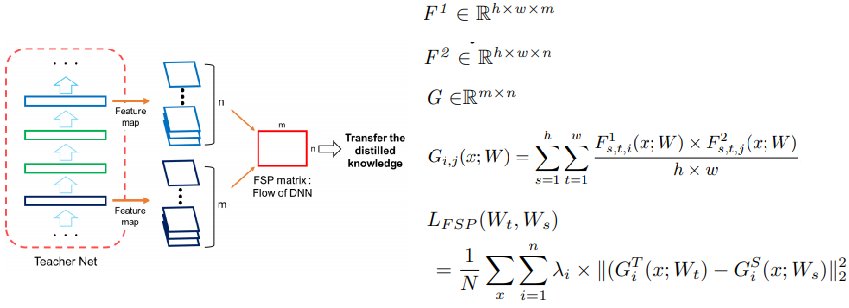
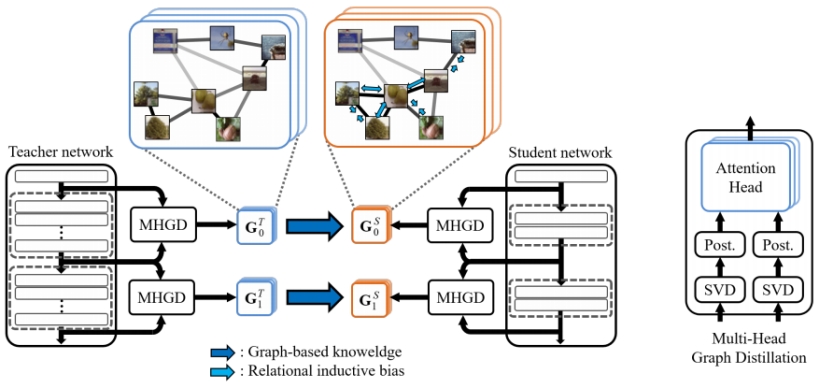
Graph-based Knowledge Distillation by Multi-head Attention Network(BMVC 2019)
- 使用non-local挖掘相邻阶段特征奇异值分解处理后的特征之间的关系
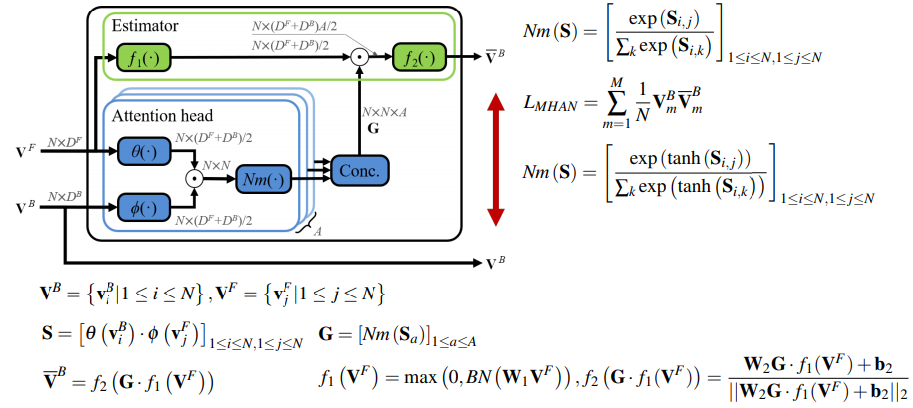
拟合输出中蕴含的关系
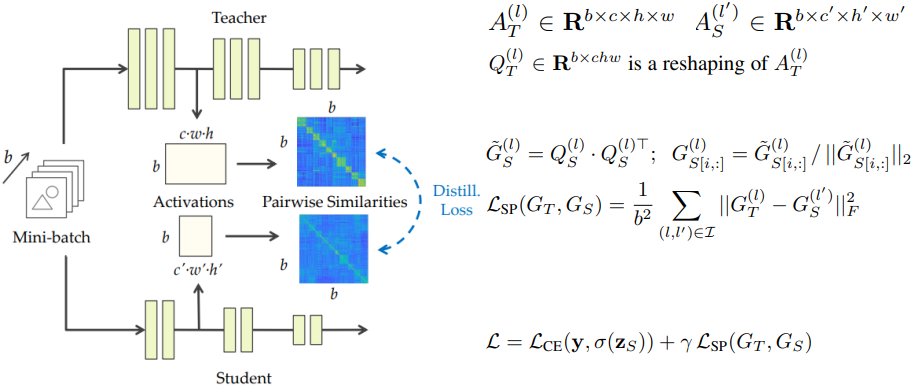
Similarity-Preserving Knowledge Distillation(ICCV 2019)
- 整个batch内部样本对应输出特征之间的关系
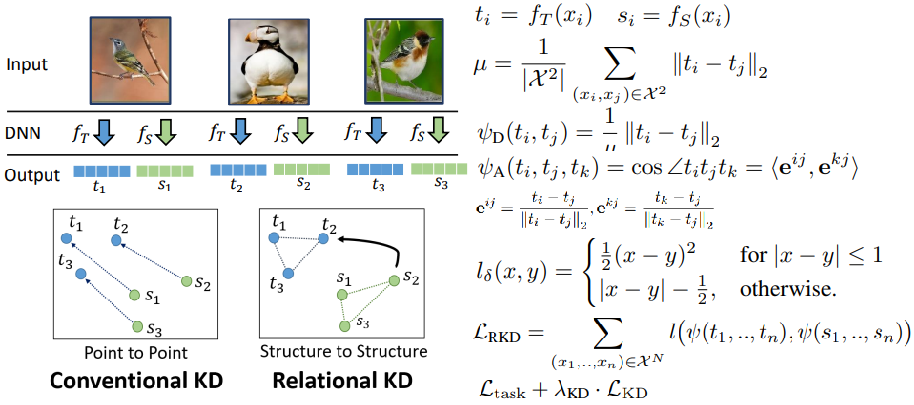
Relational Knowledge Distillation(CVPR 2019)
- batch中任意二元数据对应输出的距离关系和三元组输出对应角度关系
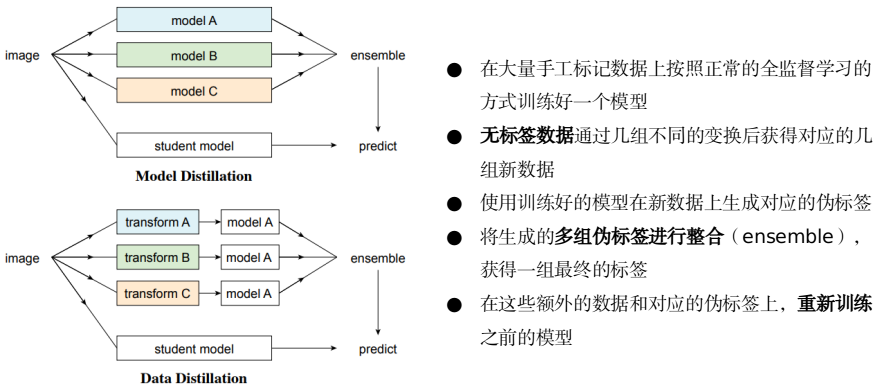
Data Distillation: Towards Omni-Supervised Learning(CVPR2018)
- 教师模型与学生模型结构可同可不同,会集成不同变换后的样本对应的教师网络的输出
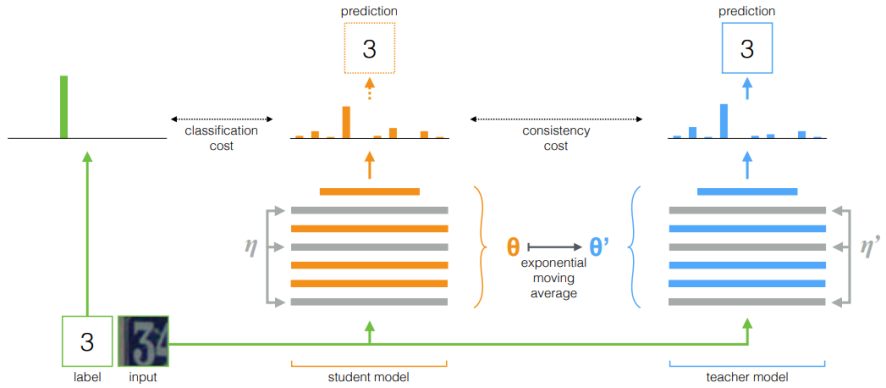
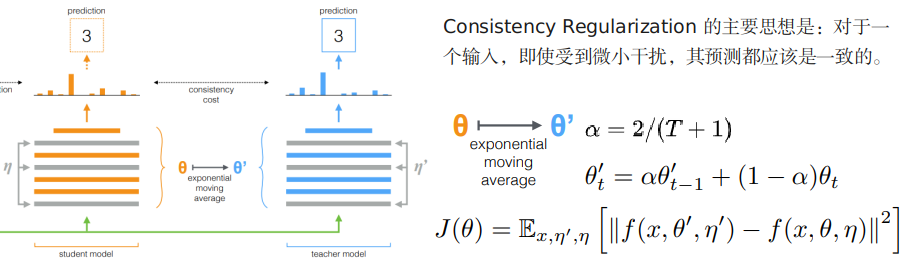
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results(NIPS 2017)
- 半监督方法,教师模型使用当前学生模型的权重参数和上一周期的权重参数计算指数移动平均,一致性约束
拟合特征自身内部的关系
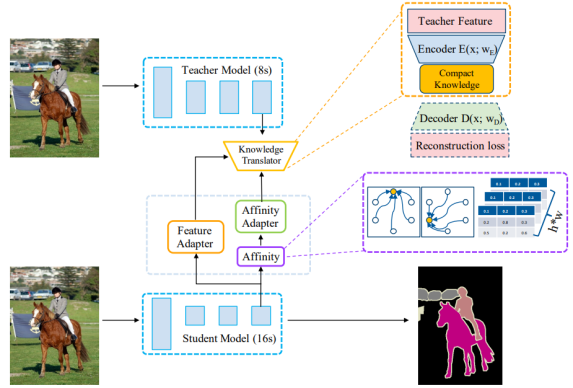
Knowledge Adaptation for Efficient Semantic Segmentation(CVPR 2019)
- 对教师模型使用自编码器转换特征,对学生模型使用适配单元来适配教师模型的特征
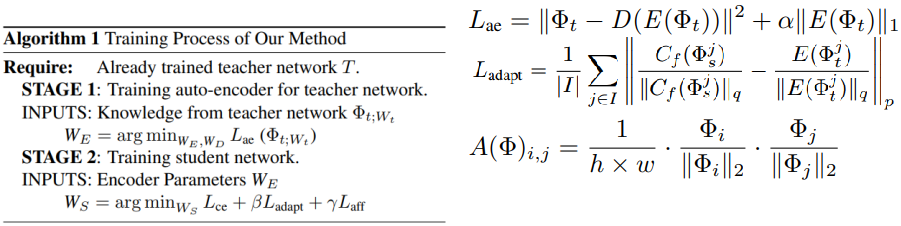
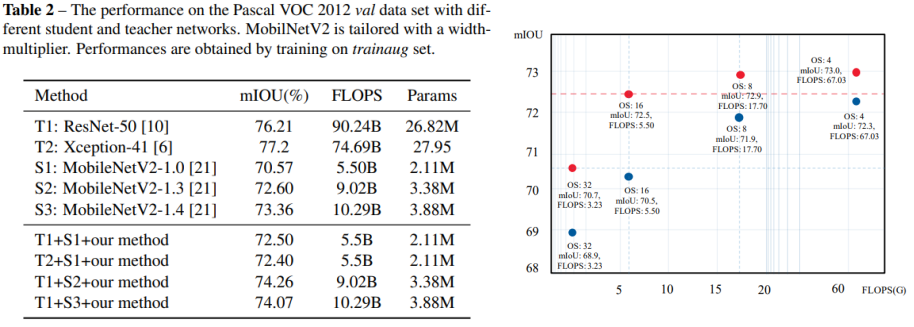
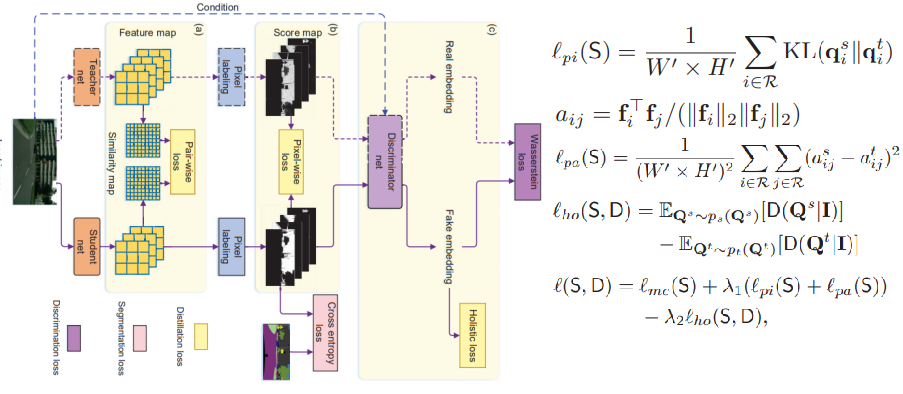
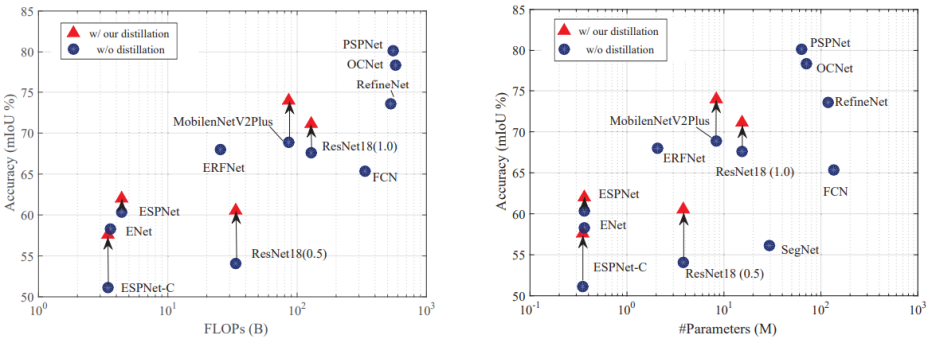
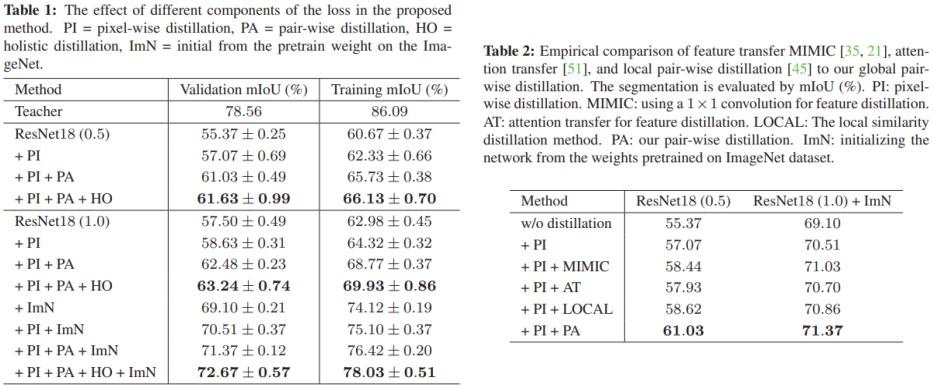
Structured Knowledge Distillation for Semantic Segmentation(CVPR 2019)
- 同时结合了soft targets,以及使用gan做的更高级的信息的拟合

最后
以上就是冷静御姐最近收集整理的关于模型压缩之蒸馏算法小结模型压缩之蒸馏算法小结的全部内容,更多相关模型压缩之蒸馏算法小结模型压缩之蒸馏算法小结内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复