该节分享两篇使用GAN的方法来进行图像转换方面的文章,分别是pix2pix GAN 和 Cycle GAN,两篇文章基本上是相同的作者发表的递进式系列,文章不是最新,但也不算旧,出来半年多点,算是比较早的使用GAN的方法进行图像转换的文章吧,该部分将详细解读其实现过程。
图像转换或者图像的风格转换,顾名思义,是指把一副图像A按照另一幅 图像B的模式/风格进行转换的一个操作,例如 “白天->黑夜”,“晴天->雨天”等等;
1. 一些方法
在深度学习的方法广泛应用以后,使用深度学习方法比较早做这件事的就是使用CNN框架来做的,也就是2016cvpr的一篇文章“Image style transfer using convolutional neural networks”基于深度卷积神经网络的方法。当时出来的时候也比较火,也有一些方法在此类方法上的改进。
随着生成对抗网络(GAN)这种在图像生成上具有天生强大能力的网络结构的出现,使用GAN方法做图像生成又成为了一个比较流行的方法。列举几个截止到目前使用GAN为基础的方法:
- pix2pix GAN (1611)
- CycleGAN (1703)
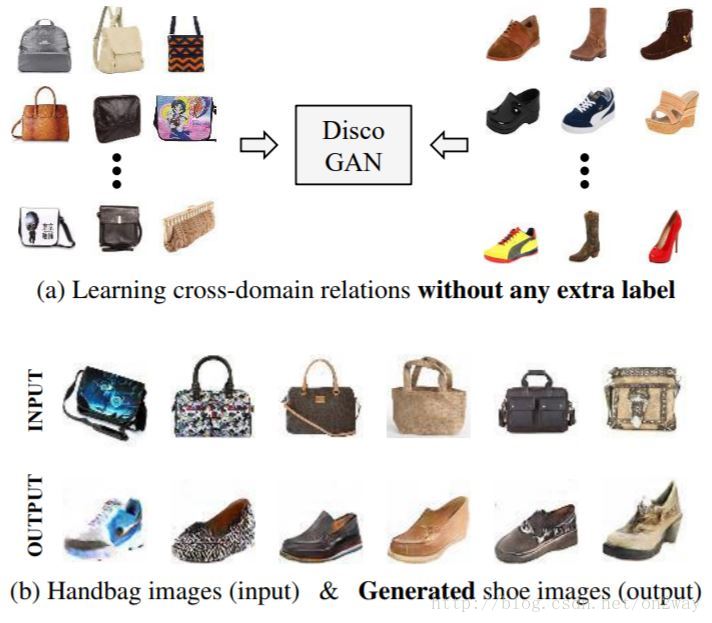
- DiscoGAN (1703)
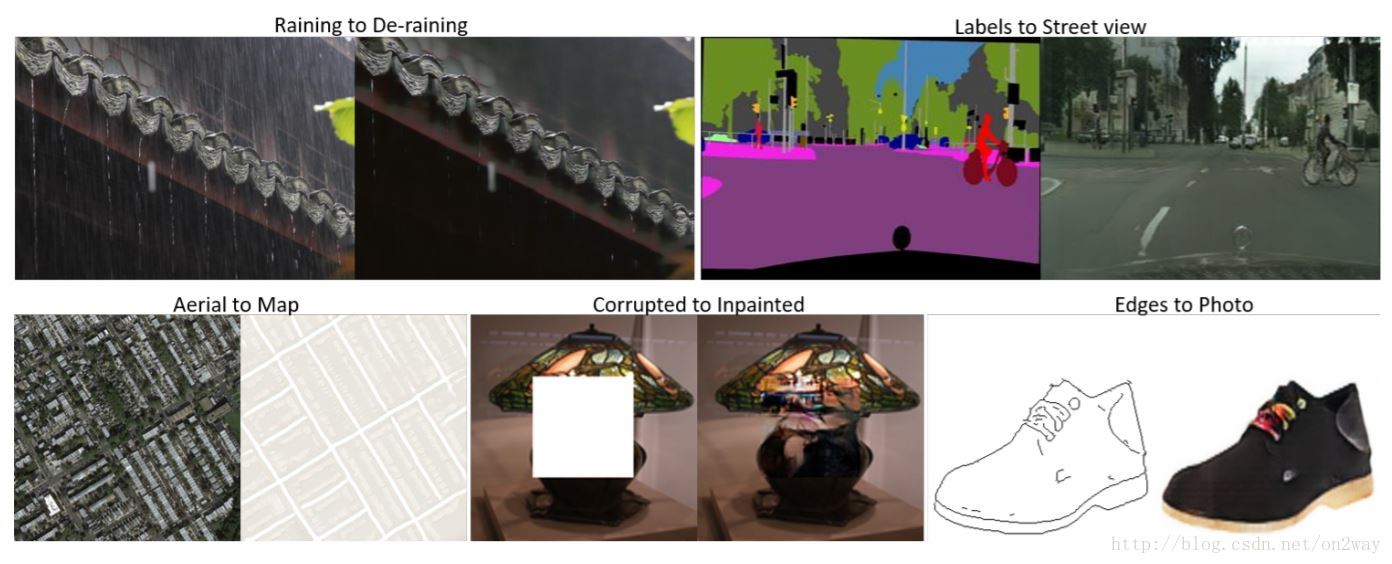
- PAN( Perceptual Adversarial Networks)感知GAN (1706)
- StarGAN (1711)
这些方法的最终效果上可能都是为了进行图像转换,实现的形式不同而已。包括最近出来的StarGAN。
先简单看下各类方法一个效果:
- 基于深度卷积神经网络的方法

pix2pix GAN
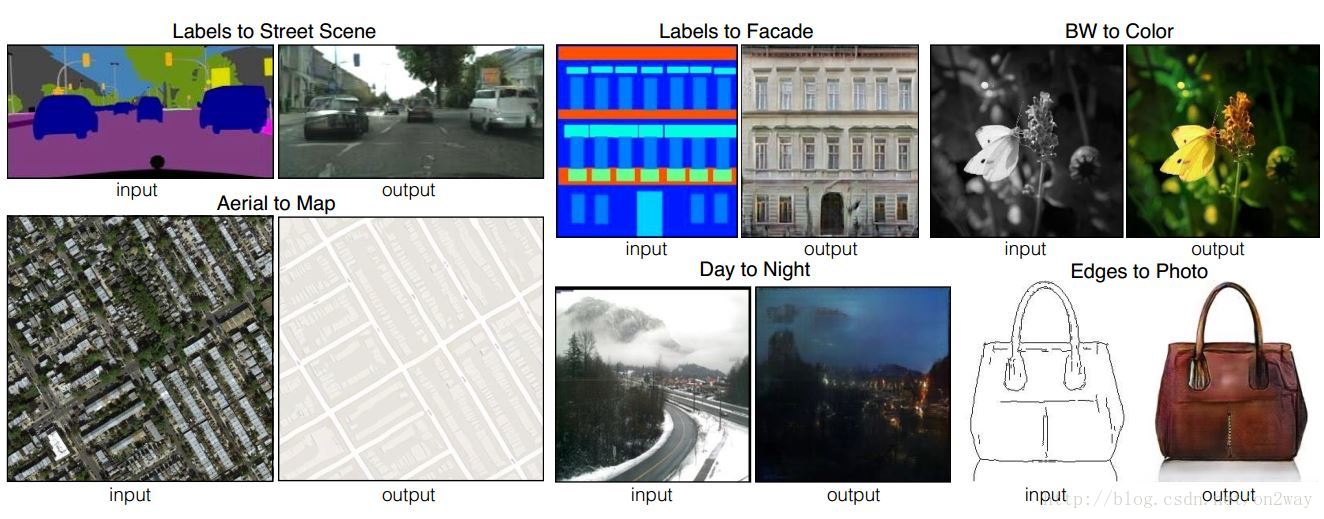
CycleGAN

DiscoGAN
PAN
StarGAN

2. 关于GAN与cGAN基础理论
研究基于GAN的图像转换方法首先需要对GAN的基本原理有一定了解,关于GAN的原理部分可以参考以前的一篇博客:
简单理解与实验生成对抗网络GAN
这里简略说下,GAN我们知道,其思想就是一个二人零和博弈思想,由两个部分构成:生成器G + 判别器D,其中生成器就是生成真实的假样本;
判别器就是用来判别样本的真假;一般的GAN可以用下图表示:
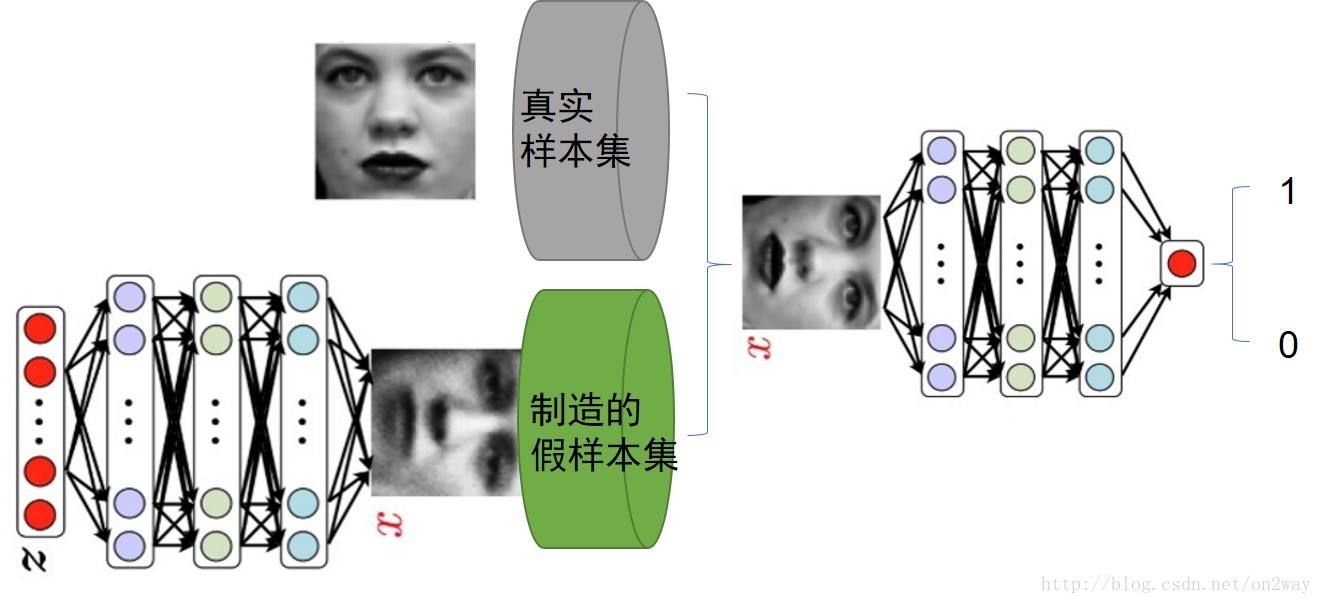
关于GAN如何工作如何训练的请看上面的那篇文章。
训练好的GAN的生成器就可以产生逼真的样本了。
但是这种传统的GAN有一个问题是每次训练后,所有的随机噪声很有可能产生相同的样本,为了可以产生不同的样本,条件GAN就出来了,也就是cGAN。cGAN其实和GAN在训练过程上完全一样,所不同的是对于输入的样本,除了样本外,还要加上一个条件,这个条件可以是label,也可以是其他的广义的东西(广义的label)。cGAN可以用下图表示:

基于此我们就可以根据条件来产生不同的图像了。
3. pix2pix GAN
先来看看第一篇文章pix2pix GAN,文章全名“Image-to-Image Translation with Conditional Adversarial Networks”
文章的框架如图所示:

来看一下这个框架,整个框架依托cGAN的思想,判别网络的输入是一个两张图组成给的数据结构,可以认为是图+label,可能有人会奇怪,这里的label为什么是一张图,这怎么是cGAN呢,我们前面说过,条件GAN接受的条件并不一定都是低维度的数值,也可以是广义的label,这里就可以认为右边的那个白色的图就是label,如果我们常见的GAN的判别器的输入是一个rgb三通道的图像的话,这里就好比输入的是一个6通道的两个图叠加的图。那么为什么要这么做呢?主要的原因应该还是为了满足生产器,其次是为了使得网络可以有效的训练。
可以看一下上述的判别器部分,此时我们白色的图像充当着噪声的功能,也就是可以把白色图像经过生成器变成黑色的图,同时黑色的图和白色的图叠加作为假样本来训练。这样我们可以发现,对于这一次的真假样本,因为白色的图(好比是label)是一样的,要想使得判别器无法判别真假,那么生成的黑色的图必须尽可能的与真样本的黑色的图像相似才满足条件吧,这也是为什么要把黑白两者叠加在一起作为样本输入的原因。
试想一下,假如只把黑色的当做真假判断条件而没有白色的,那么当把白色A图像送入生成器后,可能生成了黑色B图像,这个时候,黑色A与黑色B对于判别器来说都是真样本,所以判别器很容易没有误差了而生成器也是错的,达不到把白A生成白B的目的。
基于此可以看到这篇文章使用cGAN来实现图像转换的合理性,那么整个的目标函数可以表示如下:

注意的是目标函数包含两项,第一项就是一个一般条件GAN的常规优化函数,至于这个式子怎么理解,为什么要这么写依然可以参考上述的那篇文章。这里重点看一下第二项的一个loss,这可以理解为一个重建误差项,也就是上面白色通过生成器生成的图像(G(x,z))与原始的黑色图像y之间的误差。(这里的黑白其实可以互换生成)
这个优化目标就是这样,这里的最终目的就是为了得到一个比较好的G,可以将白色转换为黑色,有了这个G也就达到了图像转换的目的了。
G的构造
下面来看一下这个G是如何构造的,文章中展示了两种图像生成图像的典型结构,一个是自编码结构,一个是改进的U-Net结构:
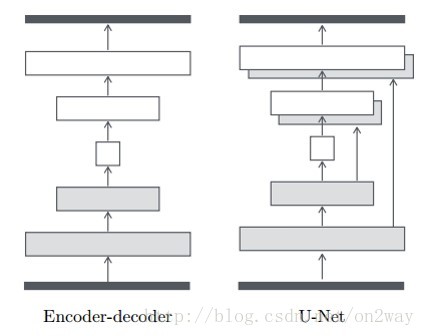
很显然,从结构上也知道第二种结构要好,实验也会对比。
图像的patch实验
这篇文章中另一个小的结构点是实验了PatchGAN的方式,也就是对于生成器或者判别器,不是以整个图像整个图像的当做输入,而是以小的patch来进行的。把一副图像划分为N*N个patch后,对于每一块进行上述的那个操作。可以发现当N=1的时候,相当于逐像素进行了,当N=256(图像大小为256的话),就是一幅图像一幅图像的操作。当然文章的实验发现当N=70的时候,效果最好。
其实当N是某一个固定块的一个最大的好处是,可以由小的图像生成大的图像,因为反正你都是对块进行操作的。比如你的原始图像都是256*256的,每70*70一个块进行的。训练的模型,假如有一个1000*1000的图像需要转换,是不是也可以转换,只需要把1000转成多个70的块,每个块单独转换即可。
文章的实验
文章列举了encoder-decoder与U-Net的不同导致的生成结果的不同的实验。同时也列举了不同的loss导致的结果的不同,可以参考原文。
看几个最终的生成结果的实验:


4. cycle GAN
下面重点来看一下cycle GAN这篇文章,这篇文章的实用性更强。原论文“Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”
首先来想想这篇文章的出发点,这篇文章和上面那篇基本上是一组作者,上面那篇我们已经看到,数据集的一个非常重要的要求就是你的图像必须是成对的,这一点其实是非常苛刻的,现实中很难找到,就好比同一个场景下的白天和黑夜的两幅图,很难找到这样一个大的数据集里面包含完全相同的同一个场景下的白天与黑夜图。那么这篇文章就是为了解决这样一个问题,就是训练集不在需要同一组完全配对的图,只需要两个模式不同的图即可,如下:

首先我们来看一下框架:
这里有两个模式不同的数据集X和Y,整个网络的构建就是后面的那个样子,这几个图不太好理解,首先先明白这里有四个东西:G,F,Dx,Dy。其中的G,F是两个不同的生成器,Dx,Dy是两个不同的判别器,可能有人会说为什么会各有两个呢,没错就是两个,至于为什么,看后面。那么G专门负责把X转换为Y的模式下的图,F则相反。Dx则专门判别X这一类模式图的真假,Dy则专门判别y这一类模式的真假。整个的loss可以表示为:
下面来详细探讨下这三类loss,首先是前两个一般情况下的GAN的loss。这里把这两个简化一下如下:
这样应该好理解了,首先是第一类GAN的loss,这里认为Y是真的样本集,而把X作为生成样本集的输入,这样就会产生一类Y模式下的X了,通过Dy来判断真的Y和X生成的假的Y来实现训练的目的。同理把X和Y换个位置就变成了上图下面的情况了。可以说这一过程是非常的巧妙,巧妙在于X与Y都是真样本集,同时又可以实现生成的假样本集,并且并不要求X与Y是同一个物体,只要他们的潜在模式一样即可。
接下来是第三类重建误差loss了,依然用一个图表示下:
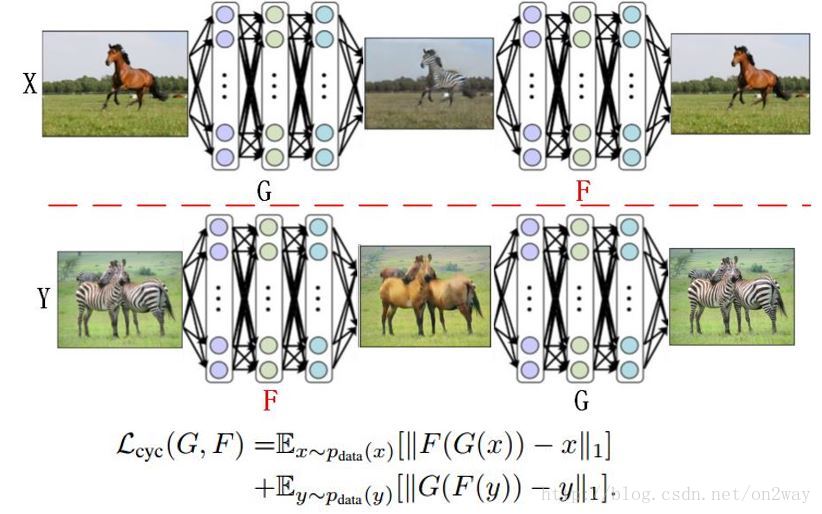
这里可以看到,存在着两种重建误差了吧,首先是X的,X经过G可以变成假Y,假Y进F又可以还原会假X,我们的目的就是让真X与假X足够相似,公式表示就是这种重建误差了。这是对于X是这样,同理对于Y也是如此。
看到这里,同样一声惊叹这种设计方法的巧妙。这就是整个loss的构成,基于此,网络可以得到很好的训练了。最终也可以训练得到想要的G,F,Dx,Dy。而G,F才是最好可以用来作为图像转换使用的。
来看几个最终的实验结果吧:


5. 总结
这就是两篇关于图像转换应用文章,第一章需要配对的图像,要求比较苛刻,第二中则完全没有这个要求,适用范围更广了。附上作者的两个项目地址:
(1)
https://github.com/yenchenlin/pix2pix-tensorflow
https://github.com/wuhuikai/chainer-pix2pix
(2)
https://github.com/junyanz/CycleGAN
现实其他任务中,很多问题就是两种不同模式之间的转换问题,巧妙的应用也许会带来不一样的效果,发挥想象吧~…~
点击进入视频版地址
笔记首次发表于公众号:“AInewworld”,欢迎关注了解更多~
最后
以上就是落后蓝天最近收集整理的关于【论文】GAN图像转换之从pix2pix到cycle GAN的全部内容,更多相关【论文】GAN图像转换之从pix2pix到cycle内容请搜索靠谱客的其他文章。








发表评论 取消回复